관계데이터모델
관계 데이터 모델 개념
- 릴레이션(relation) : 행과 열로 구성된 테이블, 관계가 아님
- 관계(relationship) : 릴레이션에서 생성되는 관계
- 릴레이션 스키마 : 릴레이션에 어떤 정보가 담길지 정의, 내포, 정적
- ex) 고객(이름, 주소, 전화번호, 포인트, 등급)
- 릴레이션 인스턴스 : 릴레이션 스키마에 실제로 저장된 데이터, 외연, 동적
- 속성(Attribute) : Entity의 특성이나 속성, 릴레이션의 Column
- 속성은 서로 다른 이름의 단일값을 가진다
- 한 속성의 값은 모두 같은 도메인값을 갖는다
- 튜플(Tuple) : 인스턴스 중 하나, 릴레이션의 Row
- 릴레이션 내 순서 상관없이 중복된 튜플은 허용 안됨
실습. Relation, Attribute, Relationship 예시 찾기
- 마트에서 Relation - 상품, 고객, 직원
- 고객 Relation은 이름, 주소, 전화번호, 포인트, 등급의 Attribute를 갖는다.
- 상품 Relation과 직원 Relation 사이에는 “어떤 직원이 담당하는 상품” Relationship을 맺을 수 있다.
키 (Key)
- 특정 튜플을 식별할 때 사용하는 속성, 속성의 집합
- 복합키(Composite Key) : 두 개 이상의 속성으로 이루어진 키
- 릴레이션간 관계를 맺는 데도 사용
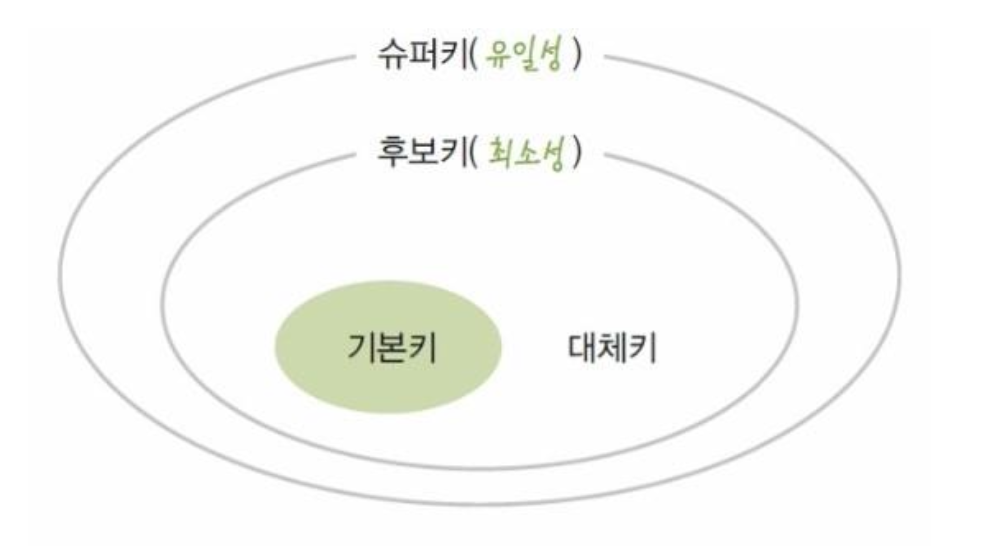
- 슈퍼키(Super Key)
- 튜플을 유일하게 식별할 수 있는 하나의 속성, 속성의 집합
- 유일성 만족
- 후보키(Candidate Key)
- 튜플을 유일하게 식별할 수 있는 속성의 최소 집합
- 효율성 향상
- 유일성, 최소성 만족
- 기본키 (Primary Key, PK)
- 후보키 중 하나를 선택하여 릴레이션을 대표하는 속성
- 대리키/인조키 (Artificial Key)
- 마땅한 기본키가 없는 경우 일련번호 속성을 만들어 기본키로
- DBMS나 소프트웨어에서 임의로 생성
- 기본키로 복합키를 사용하는 경우 효율성이 감소하기 때문에 새로운 속성을 추가해 기본키로 사용
- 대체키 (Alternate Key)
- 기본키로 선정되지 않은 후보키
- 외래키 (Foreign Key, FK)
- 다른 릴레이션의 기본키를 참조하는 속성
- 양쪽 릴레이션 도메인은 서로 같아야 한다
- 참조되는 기본키 값이 변경되면 참조하는 외래키 값도 변경된다
- NULL값과 중복값 허용
- 자기 자신의 기본키를 참조하는 외래키 가능
무결성 제약조건
데이터 무결성(Integrity)
- 데이터베이스에 저장된 데이터의 정확성과 일관성을 유지하는 것
- 관계 데이터 모델을 만들 때 지켜야 하는 제약조건
- 도메인 무결성 제약조건 : 하나의 컬럼에 나타나는 모든 값들은 같은 도메인
- 개체 무결성 제약조건 : 기본키로 선언된 속성은 NULL이 될 수 없으며 한 릴레이션 내에 기본키는 하나만 존재
- 참조 무결성 제약조건 : 외래키는 다른 릴레이션의 기본키를 참조해야하며 도메인이 동일해야 한다
- 고유 무결성 제약조건 : 특정 속성에 고유한 값을 갖도록 조건이 주어진 경우 릴레이션의 각 튜플이 갖는 속성값들은 서로 달라야 한다
- NULL 무결성 제약조건 : 릴레이션의 특정 속성 값은 NULL이 될 수 없다
ER Model을 관게 데이터 모델로 사상
- 사상(Mapping) : ER Model → 관계 데이터 모델
2진 관계 (binary relationship)
- 이진 1:1 관계
- 둘 중 하나의 기본키를 외래키로 참조
- 이진 1:N 관계
- N쪽 릴레이션에 1쪽 기본키를 외래키로 사용
- 이진 N:M 관계
- 교차 릴레이션을 생성하고 관계에 참여하는 두 릴레이션의 기본키를 각각 참조하는 외래키로 속성 구성
MySQL
- 가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템(RDBMS)
데이터 베이스 구축 단계
- 데이터베이스 만들기
- 테이블 만들기
- 데이터 입력/수정/삭제
- 데이터 조회
MySQL Workbench 설치
- mysql.server start
- mysql.server stop
- Workbench 버전 8.0.25로 낮춰서 다운받기
SQL
- 구조적 쿼리 언어 (Structured Query Language)
- 관계형 데이터베이스에 정보를 저장하고 처리하기 위한 프로그래밍 언어
- 비절차적인 언어(실행순서가 없다)
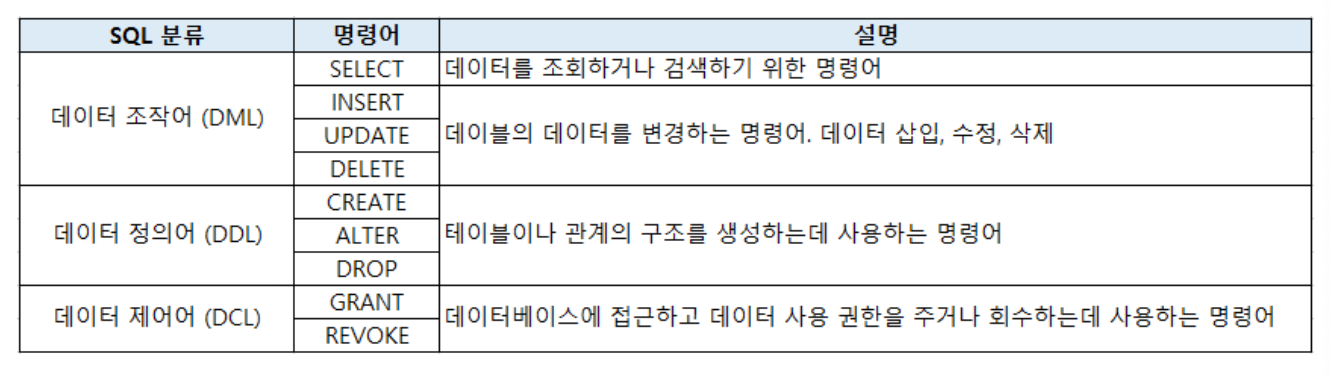
데이터 정의어(DDL, Data Definition Language)
CREATE
- 데이터베이스와 테이블을 생성
- 데이터베이스 생성 + 한글 인코딩
CREATE DATABASE 이름 DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE TABLE 테이블명 (
속성이름1 데이터타입 PRIMARY KEY,
속성이름2 데이터타입,
[FOREIGN KEY 속성이름 REFERENCES 테이블이름(속성이름)]
);
| 타입 | 바이트 수 | 설명 |
|---|
| DATE | 3 | 날짜 저장 (YYYY-MM-DD 형식) |
| TIME | 3 | 시간 저장 (HH:MM:SS 형식) |
| DATETIME | 8 | 날짜와 시간 저장 (YYYY-MM-DD HH:MM:SS 형식) |
| 타입 | 바이트 수 | 범위 | 설명 |
|---|
| TINYINT | 1 | -128 ~ 127 | 정수 |
| SMALLINT | 2 | -32768 ~ 32767 | 정수 |
| INT | 4 | 약 -21억 ~ 21억 | 정수 |
| BIGINT | 8 | 약 -900경 ~ 900경 | 정수 |
| FLOAT | 4 | -3.40E+38 ~ -1.17E-38 | 소수점 아래 7자리까지 표현 |
| 타입 | 바이트 수 | 설명 |
|---|
| CHAR(N) | 1 ~ 255 | 고정길이 문자형 / n을 1부터 255까지 지정 |
| VARCHAR(N) | 1 ~ 65535 | 가변길이 문자형 / n을 1부터 65535까지 지정 |
| TEXT | 1 ~ 65535 | 255 크기의 TEXT 데이터 값 |
| MEDIUMTEXT | 1 ~ 16777215 | 16777215 크기의 TEXT 데이터 값 |
CREATE TABLE user(
id VARCHAR(10) NOT NULL PRIMARY KEY,
pw VARCHAR(20) NOT NULL,
name VARCHAR(5) NOT NULL,
gender CHAR(1),
birthday DATE NOT NULL,
age INT NOT NULL
);
CREATE TABLE customer
( custid VARCHAR(10) NOT NULL PRIMARY KEY,
custname VARCHAR(10) NOT NULL,
addr VARCHAR(10) NOT NULL,
phone CHAR(11),
birth DATE
);
ALTER문
- 생성된 테이블의 속성과 속성에 대한 제약 및 기본키, 외래키를 변경
ALTER TABLE 테이블명 ADD 속성이름 데이터타입;
ALTER TABLE 테이블명 DROP COLUMN 속성이름;
ALTER TABLE 테이블명 MODIFY 속성이름 데이터타입;
ALTER TABLE 테이블명 RENAME COLUMN 속성이름 TO 변경속성이름;
DROP문
- 생성된 테이블 삭제
- 테이블 구조와 데이터 모두 삭제
DROP TABLE 테이블이름;
데이터 조작어 (DML, Data Manipulation Language)
- 데이터베이스 내부 데이터를 관리하기 위한 언어
CRUD
- 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 처리 기능
- Create(생성) - INSERT
- Read(읽기) - SELECT
- Update(갱신) - UPDATE
- Delete(삭제) - DELETE
INSERT문
- 테이블에 새로운 튜플을 추가
- 필드를 명시하지 않는 경우 테이블의 모든 컬럼에 값을 순서대로 추가해야 함
INSERT INTO 테이블명(필드1, 필드2, 필드3 ...) VALUES(값1, 값2, 값3 ...);
INSERT INTO 테이블명 VALUES(값1, 값2, 값3, ...);
INSERT INTO customer (custid, custname, addr, phone, birth)
values ('bunny', '강해린', '대한민국 서울', '01012341234', '2000-02-23');
INSERT INTO customer
values ('hello', '이지민', '대한민국 포항', '01022221234', '1999-08-08');
INSERT INTO user (id, pw, name, gender, birthday, age)
values
('dvadva', 'k3f3ah', '송하나', 'F', '1994-06-03', 22),
('hanjo', 'jk48fn4', '한조', 'M', '1984-10-18', 39),
('hong1234','8o4bkg', '홍길동', 'M', '1990-01-31', 33),
('jungkrat', '4ifha7f', '정크랫', 'M', '1975-11-11', 24),
('power70', 'qxur8sda', '변사또', 'M', '1970-05-02', 53),
('sexysung', '87awjkdf', '성춘향', 'F', '1992-03-31', 31),
('widowmaker', '38ewifh3', '위도우', NULL, '1986-06-27', 47);
UPDATE문
UPDATE 테이블명 SET 필드1=값1 WHERE 필드2=조건2;
update customer set custname='강해란' where custid='bunny';
DELETE문
DELETE FROM 테이블명 WHERE 필드1=값1;
delete from customer where custid='bunny1';
DROP vs TRUNCATE

truncate table customer;
데이터 조작어(DML, Data Manipulation Language)
SELECT문
- 데이터를 검색
- 질의어(query)라고도 한다
- select 속성이름 from 테이블이름 where 검색조건
WHERE조건
- BETWEEN a AND b : a와 b의 값 사이에 있으면 참 (경계포함)
- IN (list) : 리스트에 있는 값 중 하나라도 일치하면 참
- LIKE ‘비교문자열’ : 비교문자열과 형태가 일치하면 참
- 와일드 문자 종류
- % : 0개 이상의 문자열과 일치
- _ : 특정 위치의 1개의 문자
- IS NULL : NULL값인 경우 참
- ORDER BY : 결과가 출력되는 순서 조절
- ASC : 오름차순(기본값)
- DESC : 내림차순
- DISTINCT : 중복된 데이터 제거
- LIMIT : 출력 개수 제한
실습 - user 테이블 조회하기

select * from user order by birthday asc;
select * from user where gender="M" order by name desc;
select id, name from user where birthday like "199%";
select * from user where birthday like "____-06%" order by birthday asc;
select * from user where gender="M" and birthday like "197%";
select * from user order by age desc limit 3;
select * from user where age between 25 and 50;
update user set pw='12345678' where id='hong1234';
delete from user where id='jungkrat';
select * from user;
집계함수
- sum() : 합계
- avg() : 평균
- max() : 최대값
- min() : 최소값
- count() : 행 개수
- count(distinct) : 중복 제외한 행 개수
GROUP BY
- group by : 속성 이름끼리 그룹으로 묶는 역할
- having : group by 절의 결과를 나타내는 그룹을 제한
실습 - Select 실습
-- 1. 모든 직원을 직원 테이블에 나열합니다.
select * from employees;
-- 2. 나이순으로 직원 테이블에 있는 모든 직원을 나이순(내림차순)으로 나열합니다.
select * from employees order by age desc;
-- 3. 직원 테이블에 30세 이상인 직원의 이름과 나이를 나열합니다.
select name, age from employees where age >= 30;
-- 4. 영업부에서 근무하는 직원의 이름과 부서 ID를 직원 표에 나열합니다.
select name, department_id from employees where department_id = 1;
-- 5. 엔지니어링 부서에 근무하고 30세 미만인 직원의 이름과 나이를 직원 테이블에 나열합니다.
select name, age from employees where department_id = 3 and age < 30;
-- 6. 직원 테이블에서 직원 수를 계산합니다.
select name, age from employees where department_id = 3 and age < 30;
-- 7. 직원 테이블에서 각 부서의 직원 수를 계산합니다.
select department_id, count(*) as count from employees
group by department_id;
-- 8. 직원 평균 나이를 계산합니다.
select avg(age) as avg_age from employees;
-- 9. 부서별 평균 나이를 계산합니다.
select department_id, avg(age) as avg_age from employees
group by department_id;
-- 10. 부서 테이블에서 지역 컬럼의 두번째 글자가 e인 부서를 조회합니다.
select * from departments where location like '_e%';
-- 11. 부서 테이블에서 지역 컬럼에 공백이 들어가는 부서를 조회합니다.
select * from departments where location like '% %';
-- 12. 직원 테이블에서 이름 컬럼에서 마지막 글자가 n인 사원을 조회합니다.
select * from employees where name like '%n';
실습 - Sub Query
-- 0. 엔지니어링 부서에 근무하고 30세 미만인 직원의 이름과 나이를 직원 테이블에 나열합니다.
select name, age from employees
where department_id = 3
and age < 30;
select id from departments where name='Engineering';
select * from employees where department_id in (select id from departments where name='Engineering')
and age < 30;
-- 1. 전체 직원 중에서 부서가 'Sales' 이거나 'Marketing' 인 직원의 정보를 조회하세요.
select id from departments where name in ('Sales', 'Marketing');
select * from employees where department_id in (select id from departments where name in ('Sales', 'Marketing'));
-- 2. New York에서 근무하고 있는 직원을 조회하세요
select id from departments where location='New York';
select * from employees where department_id in (select id from departments where location='New York');
-- 3. Sales 부서에서 근무하고 있으며, 나이가 30 이상인 직원을 조회하세요
select id from departments where name='Sales';
select * from employees where department_id in (select id from departments where name='Sales')
and age >= 30;
