
동적 배열 (Dynamic Array)
파이썬의 리스트 : 임의의 데이터 타입을 담을 수 있는 가변적 연속열형이다. 즉, 동적 배열이다.
C언어에서는 배열의 크기를 미리 정해놓아야 한다. 배열 변수를 만들 때 처음에 원소가 몇 개 들어갈거다~ 라고 정해야 한다는 것.
List
element 사이에 다른 타입의 자료형이 허용된다.
숫자로만 이루어진 리스트에 문자열 element를 추가할 수 있다.
Array
그러나 array는 처음부터 element 유형을 지정해서 생성해야 한다. 다른 타입의 element 추가가 허용되지 않는다.
이러한 array의 특성은umPy에도 동일하게 적용된다.
pip
"package installer for python"
파이썬 전용 패키지 설치 소프트웨어
Numpy
NumPy :numerical python
과학계산용 고성능 컴퓨팅과 데이터 분석에 필요한 파이썬 패키지
즉,
pip install numpy
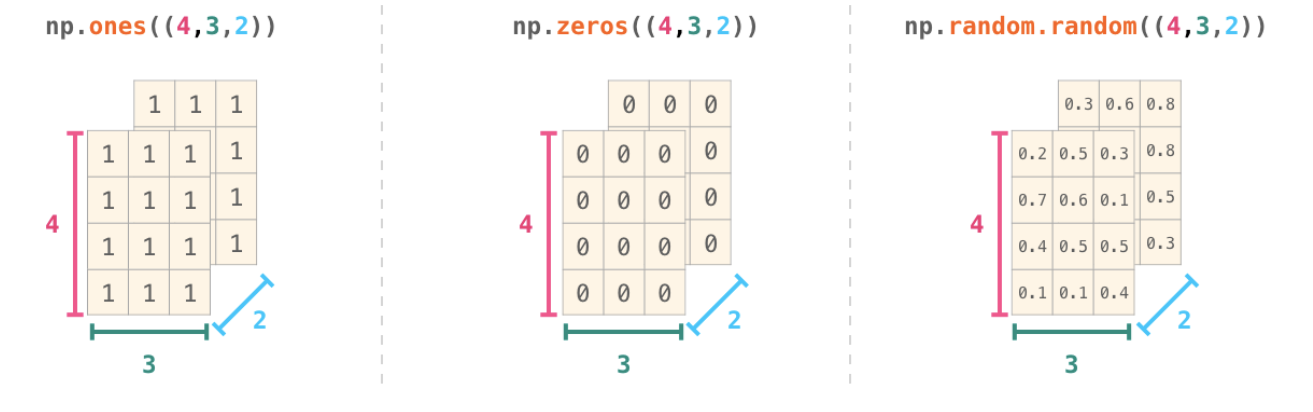
NumPy를 사용하기 위해서는 ndarray 객체를 만들어야 한다. ndarray 객체를 이용하면 대규모 데이터 집합을 n차원 배열로 담을 수 있다.
ndarray를 그냥 array라고 부르기도 한다.
* ndarray만들기
arange()
array([])
numpy.ndarray도 역시 array
모든 element의 type이 동일해야 한다.
브로드캐스팅
ndarray와 상수, 또는 서로 크기가 다른 ndarray끼리 산술연산이 가능한 기능
http://jalammar.github.io/visual-numpy/
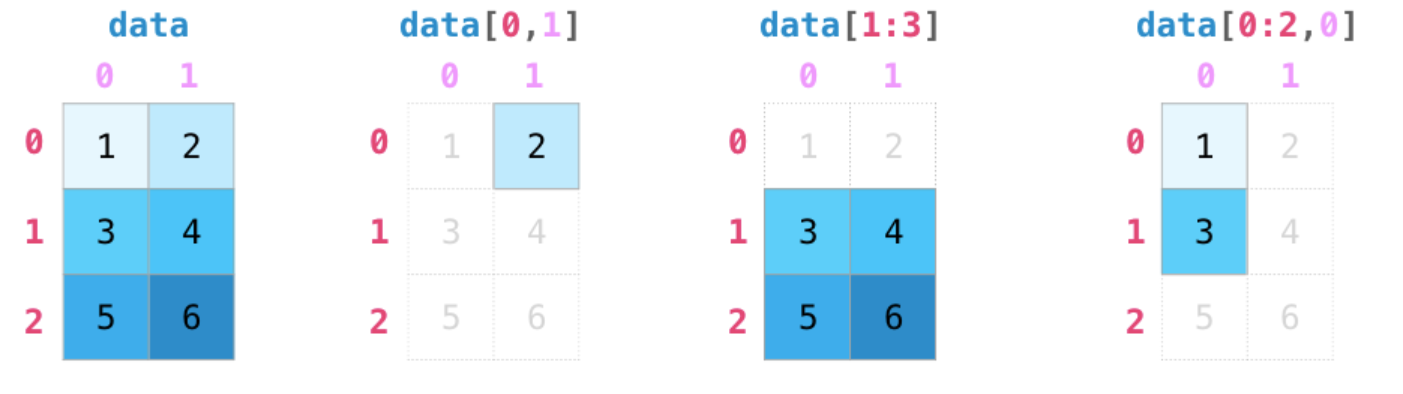
이미지
이미지는 수많은 점(픽셀)들로 구성되어 있다.
각각의 픽셀은 R, G, B 값 3개 요소의 튜플로 색상이 표시된다
텍스트이미지와 관련된 파이썬 라이브러리
• matplotlib
• PIL
딕셔너리
어떤 데이터의 값을 찾을 때 인덱스가 아닌 "한국", "미국" 등 키(key)를 사용해 데이터에 접근하는 데이터 구조를 hash
Hash란 Key와 Value로 구성되어 있는 자료 구조로 두 개의 열만 갖지만 수많은 행을 가지는 구조체
해시는 파이썬에서는 "딕셔너리(dictionary)" 또는 dict로 부른다.
파이썬 딕셔너리는 중괄호{}를 이용하고
키 : 값의 형태
Pandas
구조화된 데이터를 키(key)와 값(value)으로만 나타내기에는 제한적일 때가 있다.
그리고 표 형태로 나타내는 것이 보기에도 편하다.
pandas라는 파이썬 라이브러리는 Series와 DataFrame이라는 자료 구조를 제공한다.구조화된 데이터를 더 쉽게 다룰 수 있다.
pandas는 NumPy기반에서 개발되어 NumPy를 사용하는 어플리케이션에서 쉽게 사용 가능
Series
Series는 일련의 객체를 담을 수 있는, 1차원 배열과 비슷한 자료 구조.
따라서 배열형태인 리스트, 튜플을 통해서 만들거나 NumPy 자료형으로도 만들 수 있다.
pandas의 Series에는 index와 value가 있다.
Series 객체와 Series 인덱스는 모두 name 속성이 있다.
Series는 기본적으로 인덱스외 한 개의 값 칼럼만을 가질 수 있고 그 칼럼의 데이터가 많더라도 이는 배열 형태로 표현된다. 반면에 DataFrame은 인덱스 칼럼 외에 여러 개의 칼럼을 가질 수 있다. 따라서 Index와 Column Index도 설정할 수 있다.
EDA
데이터 훓어보기, EDA(Exploratory Data Analysis)
- .columns
데이터셋에 존재하는 컬럼명
- .describe()
기본적 통계 데이터(평균, 표준편차 등)를 pandas에서 손쉽게 보고 싶으면 .describe()을 이용
각 컬럼별로 기본 통계데이터를 보여주는 메소드에요. 개수(Count), 평균(mean), 표준편차(std), 최솟값(min), 4분위수(25%, 50% 75%), 최댓값(max)를 보여 준다.
- .isnull().sum()
결측값(Missing value) 확인
pandas에서 missing 데이터를 isnull()로 확인하고, sum()메소드를 활용해서 missing 데이터 개수의 총합을 구할 수 있다.
- .value_counts()
범주형 데이터로 기재되는 컬럼에 대해서는 value_counts() 메소드를 사용해 각 범주(Case, Category)별로 값이 몇 개 있는지 구할 수 있다.
- .drop()
칼럼 삭제
data.drop(['Latitude','Longitude')
pandas 통계 관련 메소드
이상으로 pandas에서 제공하는 통계 관련 메소드를 정리했으니 한번 확인해 보세요.
• count(): NA를 제외한 수를 반환합니다.
• describe(): 요약통계를 계산합니다.
• min(), max(): 최소, 최댓값을 계산합니다.
• sum(): 합을 계산합니다.
• mean(): 평균을 계산합니다.
• median(): 중앙값을 계산합니다.
• var(): 분산을 계산합니다.
• std(): 표준편차를 계산합니다.
• argmin(), argmax(): 최소, 최댓값을 가지고 있는 값을 반환 합니다.
• idxmin(), idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환합니다.
• cumsum(): 누적 합을 계산합니다.
• pct_change(): 퍼센트 변화율을 계산합니다.
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
