실습은 유튜브 영상인 https://youtu.be/hWwAFNmPZFQ?si=DNju5kDTKPVwm515 이것을 참고한 뒤에 클로드로 한번 더 실습해볼 예정!
시~작!~~₩하겠씁니다!
먼저 dicom 파일을 다운 받아보겠다.
FUMPE dataset이라는걸 Figshare에서 받을 수 있다 오픈소스인듯
근데 다운 받는 과정이 이전이랑 다른지 다운 받는 페이지로 넘어가는 게 꽤나 힘들었다.
하지만 내가 누구냐 이정도의 근성은 있는 남자.
무사히 다운 받았다.
https://figshare.com/articles/dataset/Patient34/6265679?backTo=%2Fcollections%2FFUMPE%2F4107803&file=11450006
만약 따라할 생각이라면 여기 주소로 들어가서 다운 받으시면 될 것이다.
엎친데 덮친 격으로 다운받은 파일인 PAt034.rar 집파일을 압축해제 해야하는데 반디집 무료사용기간이 끝났단다.. 다른 압축해제 프로그램을 찾아보자..오픈 소스인 7zip으로 가볼까?
아니 온라인으로 그냥 압축해제 해주는 사이트가 있다니 좋구만(https://extract.me/ko/)
무사히 데이터셋 데려오기 성공! 총 189개의 dcm 파일 있다.
먼저 데이터를 읽어보기 위해 터미널을 열어서 python -m venv test_env를 치는걸 보아 가상환경 서버를 만드는 것 같다. 그 이후에 .\test_env\Scripts\activate라고 치시는데 저건 Windows PowerShell / CMD용 문법이다. 나는 맥을 사용하고 있기 때문에 source test_env/bin/activate 라고 쳐야 올바르게 test_env 가상환경을 활성화 할 수 있다.
이후 test_read.py 파일을 새로 만들어주고
import numpy as np
import matplotlib as plt
from pydicom import dcmread
path = "/Users/admin/Downloads/dicom/PAT034/D0001.dcm"
print("Reading DICOM file from path: ", path)
x = dcmread(path) ### ' FileDataset'
print(x)코드 쳐준뒤에 터미널에서 python test_read.py

이게 dicom파일?? 일단 경로가 나오는 걸 볼 수 있네요? 그리고 헤더 정보!
파일 저장, 전송구문, 메타데이터, CT,저장 이미지인지, 이동성, 제조업체등의 정보가 있다.
그럼 이제 픽셀 데이터를 찾아볼까요? 그전에 픽셀데이터 속성들이 어떤 게 있는지 알기위해
print(dir(x))로 불러본뒤에 픽셀 사이의 간격 즉 볼류를 알아보기 위해 print(x.PixelSpacing)으로 수정 후 실행 시켜보면 [0.708984, 0.708984] 라는 값을 알 수 있고
그 이후 원시데이터를 출력해보자
[[ 25 28 33 ... 25 25 25][ 14 27 30 ... 25 25 25]
[ 4 16 30 ... 25 25 25]
...
[ 648 868 1064 ... 25 25 25][ 377 554 765 ... 25 25 25]
[ 173 287 479 ... 25 25 25]]
위 데이터가 실제로는 어떻게 보이는지 출력을 해보자
Dicom_file = x
plt.imshow(Dicom_file.pixel_array, cmap=plt.cm.gray)
plt.show()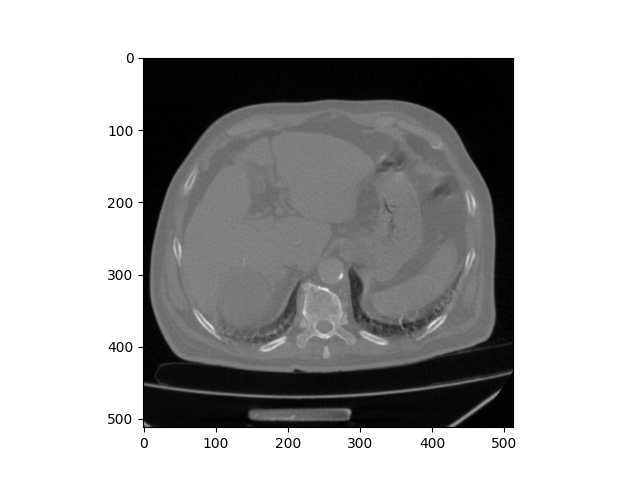
횡격막 부분인 거 같은데? 흉통을 찍은 이미지인 거 같네요.
그다음 HU값을 추출하는 새로 파일을 만들어보자. 이전에 Kaggle에 올라온 코드가 있다는데 시간이 지나면서 지금 강사님이 보여주는 코드랑 조금 구조가 달라진 거 같다. 하지만 걱정마라 우리에게 AI가 있으니 강사님 코드화면을 보고 조금만 쳐도 같은 기능을 가진 코드를 만들어주니까! 하지만 코드의 구조나 어떤 함수가 어떤 기능을 해서 코드가 작동되는지는 확인 할 수 있어야한다.
import os
import numpy as np
from pydicom import dcmread
## kagle
def load_scan(path):
print("Loading scan", path)
slices = [dcmread(path + '/' + s) for s in os.listdir(path)]
slices.sort(key = lambda x: float(x.ImagePositionPatient[2]))
if slices[0].ImagePositionPatient[2] == slices[1].ImagePositionPatient[2]:
sec_num = 2;
while slices[0].ImagePositionPatient[2] == slices[sec_num].ImagePositionPatient[2]:
sec_num += 1
slice_num = int(len(slices) / sec_num)
slices.sort(key = lambda x: float(x.InstanceNumber))
slices = slices[0:slice_num]
slices.sort(key = lambda x: float(x.ImagePositionPatient[2]))
try:
slice_thickness = np.abs(slices[0].ImagePositionPatient[2] - slices[1].ImagePositionPatient[2])
except:
slice_thickness = np.abs(slices[0].SliceLocation - slices[1].SliceLocation)
for s in slices:
s.SliceThickness = slice_thickness
return slices
path = "/Users/admin/Downloads/dicom/PAT034"
patient = load_scan(path)
print(patient)이 코드는 기본적으로 .dcm 파일을 읽어서 각 슬라이스를 읽어오고, 이제는 여러 슬라이스를 한번에 읽어옵니다. 슬라이스 189개를 전부 불러올 수 있다.
print(patient[48].pixel_array) 맨 밑 코드를 이렇게 하면 원하는 번호의 슬라이스를 불러올 수 있다.
기본적으로 이렇게 하는 이유는 모든 환자 데이터에서 모든 픽셀 데이터를 추출하기 위해서이다.
픽셀데이터를 하나씩 불러오는 대신 for 루프를 사용해 모든 데이터를 가져온다.
여기엔 메타데이터나 위치등 자세도 나오며 인스턴스 번호가 0부터 시작해 스택을 정렬해서 순서를 유지한다. 뒤죽박죽 섞여있지않는다. for s in slices: 코드를 통해 2D 이미지가 아닌 3D에서도 가능한 Z 축도 확인 가능하다.
다음으로 진짜 HU값에 대해 알아보자
방사선 밀도를 측정하고 설명하는 정량적 단위이다. 방사선 전문의는 픽셀을 설명하기위해 HU값을 사용한다.
픽셀은 검색은 픽셀 255, 흰색픽셀은 0으로 표현 HU값은 이러한 픽셀 값을 정규화된 데이터 스케일로 변환한다.
path = "/Users/admin/Downloads/dicom/PAT034"
patient = load_scan(path)
pixel_ds = []
for files in patient:
pixel_numpy = files.pixel_array
pixel_ds.append(pixel_numpy)코드 밑부분을 이렇게 수정한 뒤에 다시 실행시켜보자.
위 코드를 작동시키면 각 파일의 데이터를 입력하여 추가합니다.
이걸 출력 시켜보자면 print(pixel_ds) 추가후 실행시켜보면 모든 픽셀 데이터가 3차원 배열에 저장된다. 마지막 부분은 2차원 배열에 정리된다.
이제 변환이 필요하므로 get_pixel_hu 함수를 불러와야하는데 역시나 기존 영상의 코드와 지금 캐글에 있는 코드는 다르다. 근데 꼭 기존 영상 코드를 따라할 이유는 없으니까 캐글에 있는 코드를 한번 써보자!
def get_pixels_hu(slices):
image = np.stack([s.pixel_array for s in slices])
# Convert to int16 (from sometimes int16),
# should be possible as values should always be low enough (<32k)
image = image.astype(np.int16)
# Set outside-of-scan pixels to 0
# The intercept is usually -1024, so air is approximately 0
image[image == -2000] = 0
# Convert to Hounsfield units (HU)
for slice_number in range(len(slices)):
intercept = slices[slice_number].RescaleIntercept
slope = slices[slice_number].RescaleSlope
if slope != 1:
image[slice_number] = slope * image[slice_number].astype(np.float64)
image[slice_number] = image[slice_number].astype(np.int16)
image[slice_number] += np.int16(intercept)
return np.array(image, dtype=np.int16)이 코드를 불러왔구 우리가 할 건 get_pixels_hu(patient) 코드를 불러오는것뿐이다. patient만 넣어서
(test_env) (bmo) admin@admins-MacBook-Pro dicom % python test_read2.py
Loading scan /Users/admin/Downloads/dicom/PAT034
Traceback (most recent call last):
File "/Users/admin/Downloads/dicom/test_read2.py", line 57, in <module>
case_pixels, spacing = get_pixels_hu(patient)
ValueError: too many values to unpack (expected 2)
(test_env) (bmo) admin@admins-MacBook-Pro dicom % 밸류가 너무 많아서 에러가 떠버리네요..강사님꺼는 괜찮던데 어쨋든 나오는 값들을 보면 음수값을 볼 수 있는데 -900, -99 이런건 patient신체가 아닌 외부의 모든 공기 데이터이다. 모든 데이터가 표현되는 것이 아니라 시각화를 위해 축약된 것이라 데이터들이 제각각이다 또한 3차원 배열에 저장된 것도 알 수 있다.
이제 저 데이터들을 정규화한다. 이번 껀 그래프를 보여주는건데 HU값이 아래에 나온느 거라 그런지 역시 밸류에러가 뜬다.
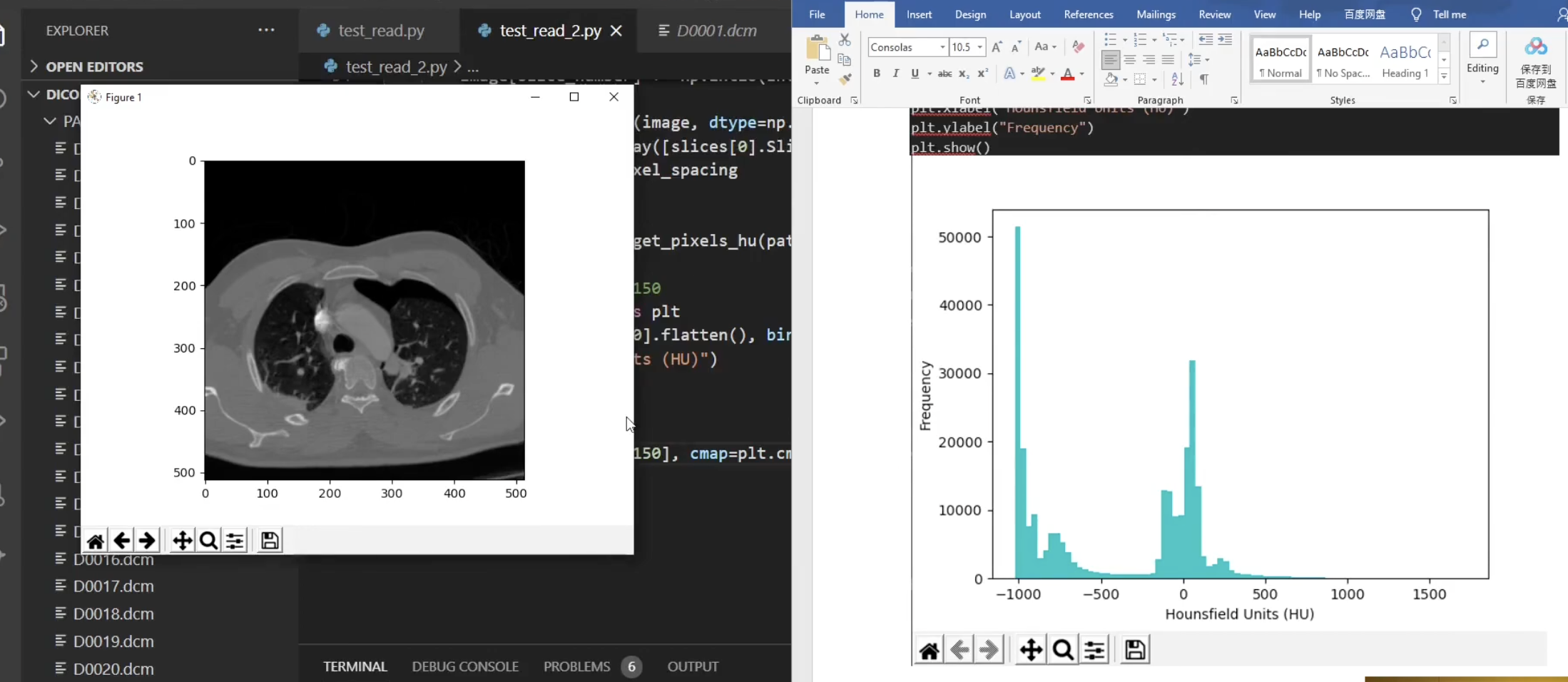
실제 코드가 정상작동시 저런 그래프와 이미지가 떠서 그래프를 보면서 이미지에 대한 HU값을 알 수 있다.
여기까지가 Leslie Wubbel강사님과 하는 How to read DICOM files 강의였다.
클로드 실습
이제는 클로드가 내주는 DICOM 실습을 해보자.
import pydicom
import matplotlib.pyplot as plt
import numpy as np
# ── 1단계: 샘플 파일 목록 확인 후 로드 ──────────────────────────
files = pydicom.data.get_testdata_files()
print("=== 사용 가능한 샘플 파일 ===")
for f in files:
print(f)
# CT 파일 로드
path = pydicom.data.get_testdata_file("CT_small.dcm")
ds = pydicom.dcmread(path)
# ── 2단계: Transfer Syntax & UID 확인 ───────────────────────────
print("\n=== Transfer Syntax ===")
print(ds.file_meta.TransferSyntaxUID)
print("\n=== UID 계층 구조 ===")
print("StudyInstanceUID :", ds.StudyInstanceUID)
print("SeriesInstanceUID:", ds.SeriesInstanceUID)
print("SOPInstanceUID :", ds.SOPInstanceUID)
# ── 3단계: 주요 메타데이터 출력 ─────────────────────────────────
print("\n=== 메타데이터 ===")
print("환자 이름 :", ds.get("PatientName", "없음"))
print("Modality :", ds.get("Modality", "없음"))
print("픽셀 간격 :", ds.get("PixelSpacing", "없음"))
print("슬라이스 두께:", ds.get("SliceThickness", "없음"))
print("Window Center:", ds.get("WindowCenter", "없음"))
print("Window Width :", ds.get("WindowWidth", "없음"))
# ── 4단계: 픽셀 데이터 + HU값 변환 ─────────────────────────────
print("\n=== 픽셀 데이터 ===")
pixel_array = ds.pixel_array
print("shape:", pixel_array.shape)
print("픽셀 최솟값/최댓값:", pixel_array.min(), "/", pixel_array.max())
# HU 변환
rescale_slope = float(ds.get("RescaleSlope", 1))
rescale_intercept = float(ds.get("RescaleIntercept", 0))
hu_image = pixel_array * rescale_slope + rescale_intercept
print("HU 범위:", hu_image.min(), "/", hu_image.max())
# ── 5단계: Windowing 함수 ────────────────────────────────────────
def apply_window(image, center, width):
low = center - width / 2
high = center + width / 2
windowed = np.clip(image, low, high)
windowed = (windowed - low) / (high - low)
return windowed
lung = apply_window(hu_image, center=-600, width=1500)
bone = apply_window(hu_image, center=400, width=1800)
# ── 6단계: 시각화 ────────────────────────────────────────────────
fig, axes = plt.subplots(1, 4, figsize=(18, 5))
axes[0].set_title("Raw Pixel")
axes[0].imshow(pixel_array, cmap="gray")
axes[1].set_title("HU Image")
axes[1].imshow(hu_image, cmap="gray", vmin=-1000, vmax=1000)
axes[2].set_title("Lung Window\n(C:-600 W:1500)")
axes[2].imshow(lung, cmap="gray")
axes[3].set_title("Bone Window\n(C:400 W:1800)")
axes[3].imshow(bone, cmap="gray")
for ax in axes:
ax.axis("off")
plt.tight_layout()
plt.savefig("dicom_result.png", dpi=150)
plt.show()
print("\n=== dicom_result.png 저장 완료 ===")=== Transfer Syntax ===
1.2.840.10008.1.2.1
=== UID 계층 구조 ===
StudyInstanceUID : 1.3.6.1.4.1.5962.1.2.1.20040119072730.12322
SeriesInstanceUID: 1.3.6.1.4.1.5962.1.3.1.1.20040119072730.12322
SOPInstanceUID : 1.3.6.1.4.1.5962.1.1.1.1.1.20040119072730.12322
=== 메타데이터 ===
환자 이름 : CompressedSamples^CT1
Modality : CT
픽셀 간격 : [0.661468, 0.661468]
슬라이스 두께: 5.000000
Window Center: 없음
Window Width : 없음
=== 픽셀 데이터 ===
shape: (128, 128)
픽셀 최솟값/최댓값: 128 / 2191
HU 범위: -896.0 / 1167.0
지금 출력된 결과로 배울 수 있는 것들
Transfer Syntax가 1.2.840.10008.1.2.1로 나왔는데 이게 Explicit VR Little Endian이에요. 앞서 말한 가장 기본적인 인코딩 방식이 맞게 나온 걸 알 수 있다.
UID 계층 보면 숫자 구조가 재밌다.
StudyInstanceUID : 1.3.6.1.4.1.5962.1.2.1.20040119...
SeriesInstanceUID: 1.3.6.1.4.1.5962.1.3.1.1.20040119...
SOPInstanceUID : 1.3.6.1.4.1.5962.1.1.1.1.1.20040119...
날짜가 20040119로 박혀있죠? 2004년 1월 19일 촬영된 샘플 데이터예요. 이렇게 UID 안에 타임스탬프가 들어가는 게 전 세계 고유성을 보장하는 방식입니다.
Window Center/Width가 "없음"으로 나온 것도 중요한 포인트예요. 이 샘플 파일엔 Window 태그가 없어서 직접 windowing을 적용해야 하는 상황인 거거든요. 실제 임상 데이터에서도 이런 경우가 있어서 대비가 필요합니다.
HU 범위가 -896 ~ 1167로 나왔는데, 공부하신 HU 테이블이랑 맞춰보면 -896은 폐/공기 영역, 1167은 뼈 영역이라는 게 딱 맞아 떨어지죠.
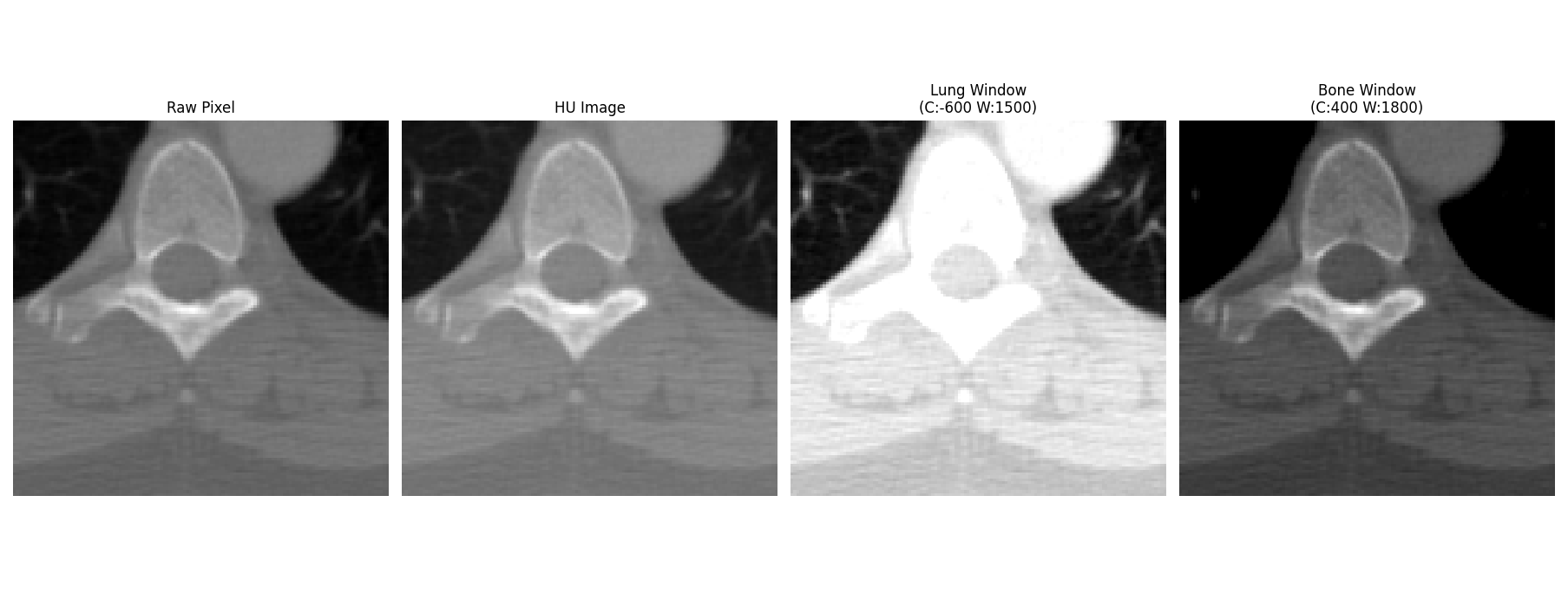
이제 Windowing 값을 바꿔가면서 차이를 직접 눈으로 확인해봅시다.
Windowing이란?
CT 이미지는 HU값이 -1000 ~ +3000 정도로 매우 넓은 범위를 가지고 있어요. 근데 사람 눈은 이 전체를 한 번에 구분 못해요. 그래서 "내가 보고 싶은 HU 범위만 잘라서" 밝기로 표현하는 게 Windowing이에요.
쉽게 말하면 돋보기로 특정 HU 구간만 확대해서 보는 것이라고 생각하면 돼요.
C와 W의 의미
C (Center) = 내가 보고 싶은 HU 범위의 중심값
W (Width) = 얼마나 넓은 범위를 볼 건지
그래서 실제로 보이는 HU 범위는 이렇게 됩니다.
보이는 범위 = C - W/2 ~ C + W/2
예) 폐 윈도우 C:-600, W:1500
→ -600 - 750 = -1350 (완전 검정)
→ -600 + 750 = +150 (완전 흰색)
이 사이만 회색조로 표현
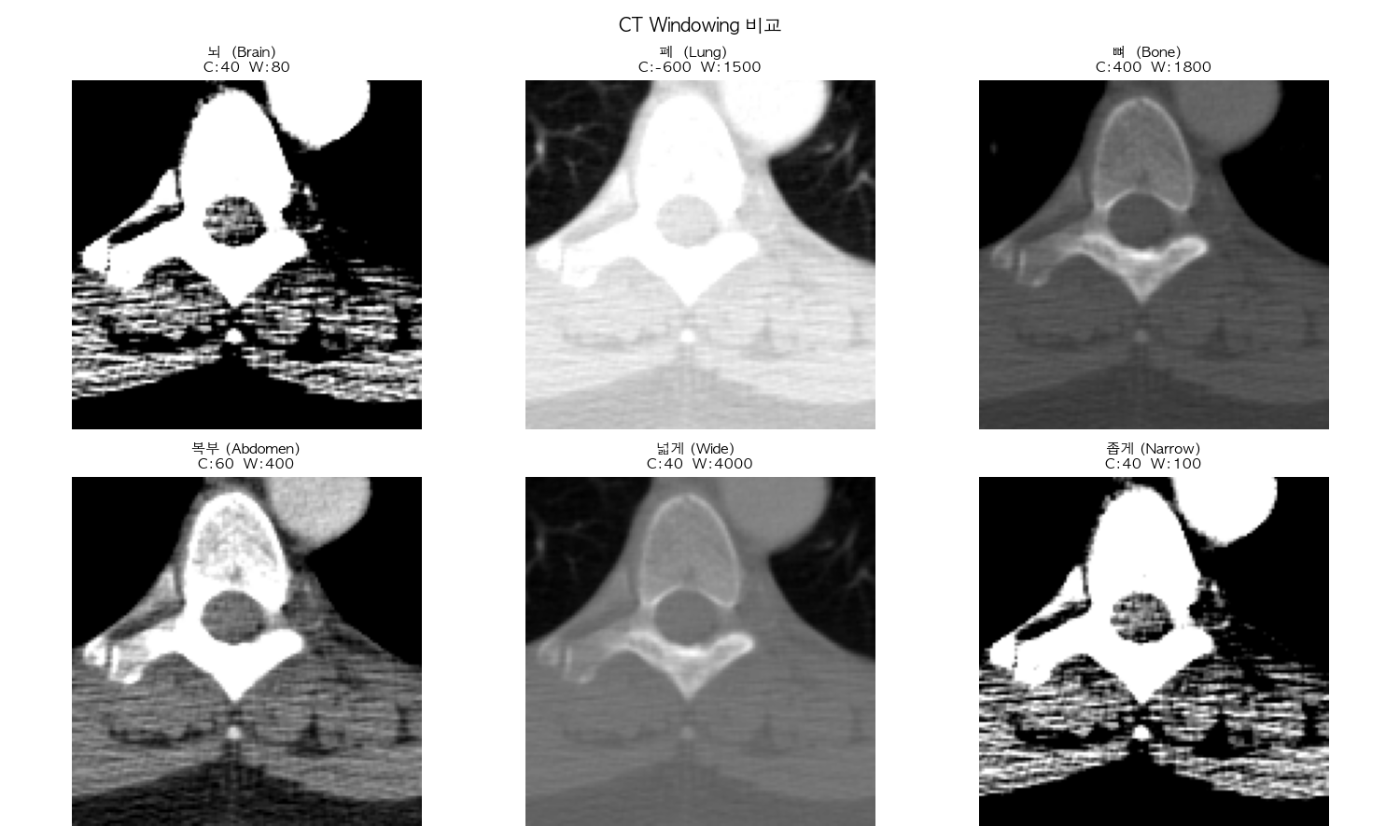
지금 결과 이미지로 비교해보면
뇌 (C:40, W:80) → 범위가 0~80으로 매우 좁아요. 그래서 뼈(HU 400+)는 완전 흰색으로 날아가버리고, 뇌 조직 내 미세한 차이만 보이는 거예요.
폐 (C:-600, W:1500) → 범위가 -1350~+150으로 넓어요. 공기(검정)와 폐 조직(회색) 혈관(흰색)이 선명하게 구분되죠.
뼈 (C:400, W:1800) → 뼈 주변 HU 범위에 맞춰서 뼈 구조가 가장 선명하게 보여요.
넓게 (C:40, W:4000) → 범위가 너무 넓어서 모든 게 뭉개져 대비가 없어 보이는 거예요.
좁게 (C:40, W:100) → 범위가 -10~90으로 극단적으로 좁아서 조금만 벗어나면 완전 흰색/검정으로 날아가버려요.
즉, 같은 CT 이미지라도 C와 W를 어떻게 설정하냐에 따라 완전히 다른 정보가 보이는 거예요. 의사들이 CT 볼 때 폐 보다가 뼈 보다가 윈도우를 계속 바꾸는 게 바로 이 이유입니다.
그렇군요
이제는 실전으로 들어갈 수 있는 실습을 해보자.
공개 의료 데이터셋(아까 받은 PAT034)으로 DICOM → 전처리 → UNet 학습 → 결과 시각화 파이프라인을 만들어보자!
단계별로 이렇게 진행할 계획이다.
1단계는 189개 슬라이스를 불러와서 3D 볼륨으로 쌓기
2단계는 PyTorch DataLoader 연결
3단계는 시각화까지
일단 1단계 시작해보자.
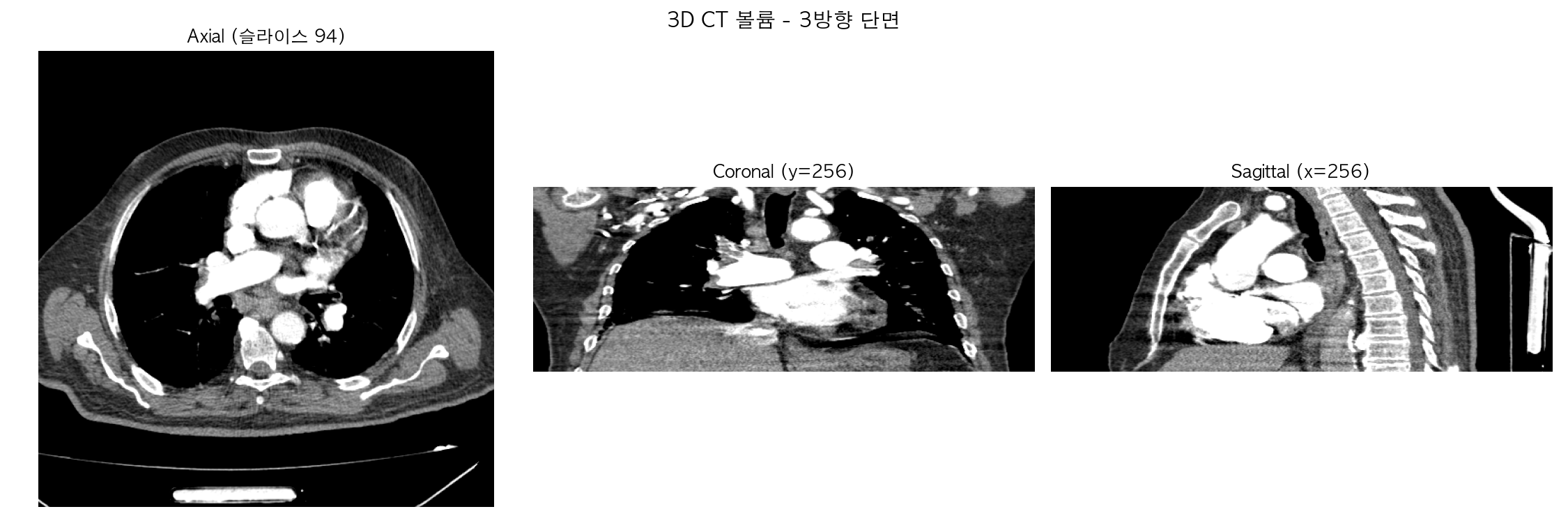
(bmo) admin@admins-MacBook-Pro dicom % python 3d_dataload.py
총 슬라이스 수: 189
SliceLocation 기준 정렬 완료
3D 볼륨 shape: (189, 512, 512)
HU 범위: -1024.0 ~ 3071.0
2026-03-03 10:05:47.282 python[20049:1924673] The class 'NSSavePanel' overrides the method identifier. This method is implemented by class 'NSWindow'결과 해석
(189, 512, 512) = 슬라이스 189장 × 가로 512 × 세로 512픽셀로 3D 볼륨이 완성됐어요.
HU 범위 -1024 ~ 3071은 실제 임상 CT 데이터 범위 그대로예요. 아까 샘플 파일보다 훨씬 풍부한 데이터죠.
이미지도 보면 Axial은 흉부 단면, Coronal은 앞에서 본 단면, Sagittal은 옆에서 본 단면이 정확하게 나왔어요. 3D 볼륨이 공간적으로 올바르게 쌓였다는 걸 보여준다.
다음 단계인 PyTorch DataLoader 연결
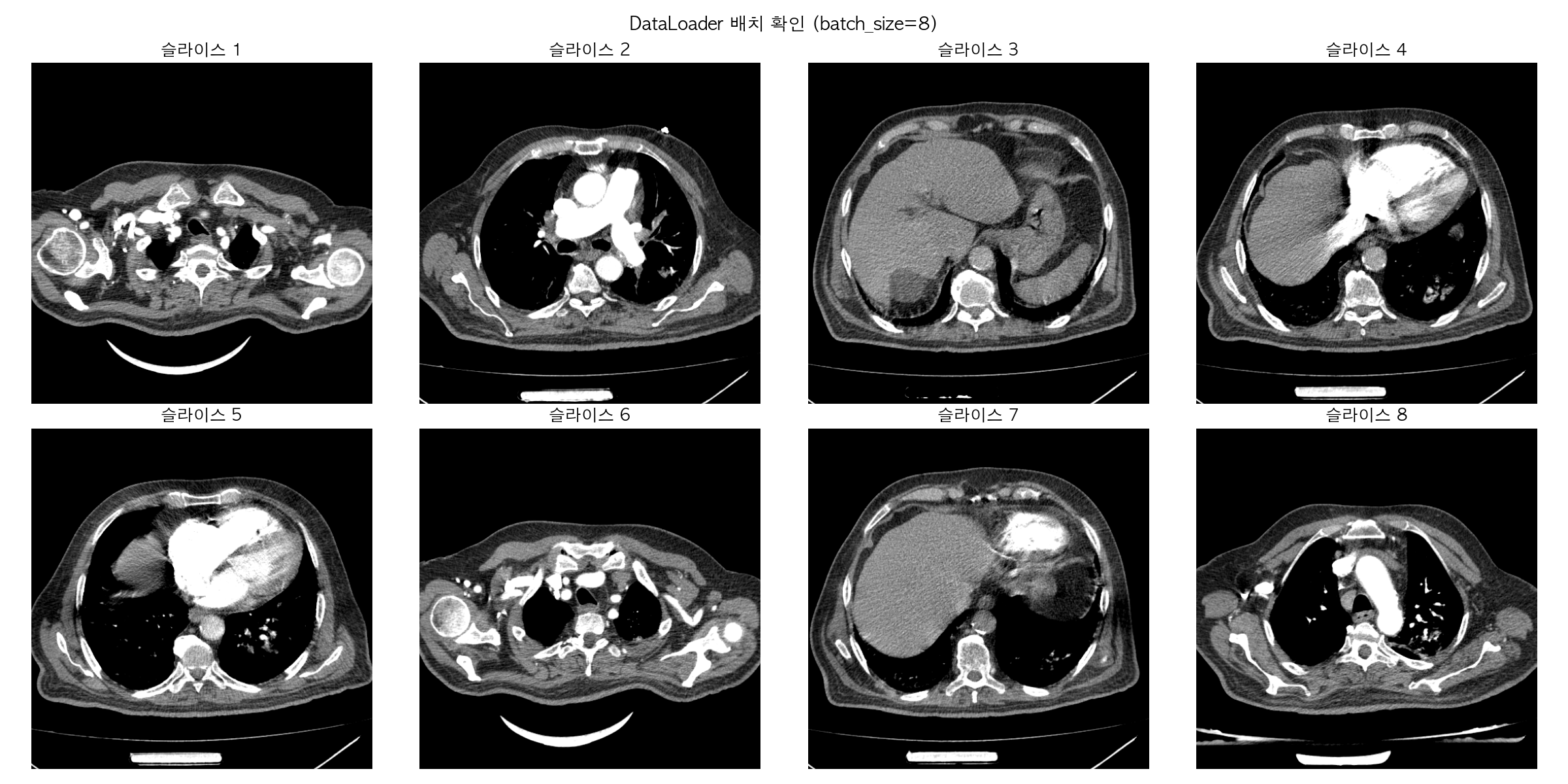
(bmo) admin@admins-MacBook-Pro dicom % python pytorch_dataloader.py
볼륨 로드 완료: (189, 512, 512)
Dataset 크기: 189장
총 배치 수 : 24개 (batch_size=8 기준)
배치 shape : torch.Size([8, 1, 512, 512])
값 범위 : 0.000 ~ 1.000
dtype : torch.float32(8, 1, 512, 512) shape, 값 범위 0~1, dtype float32 전부 UNet 입력으로 바로 쓸 수 있는 형태
그다음은 Unet 모델 테스트 코드를 만들고 실행시켜보자.
# ── 모델 테스트 ──────────────────────────────────────────────────
model = UNet(in_channels=1, out_channels=1)
# 파라미터 수 확인
total_params = sum(p.numel() for p in model.parameters())
print(f"총 파라미터 수: {total_params:,}")
# 더미 입력으로 forward pass 테스트
dummy = torch.randn(2, 1, 512, 512) # batch=2, channel=1, 512x512
output = model(dummy)
print(f"입력 shape : {dummy.shape}")
print(f"출력 shape : {output.shape}") # (2, 1, 512, 512) 나오면 성공
print(f"출력 값 범위: {output.min():.3f} ~ {output.max():.3f}") # 0~1 사이여야 정상(bmo) admin@admins-MacBook-Pro dicom % python unet.py
총 파라미터 수: 31,042,369
입력 shape : torch.Size([2, 1, 512, 512])
출력 shape : torch.Size([2, 1, 512, 512])
출력 값 범위: 0.194 ~ 0.884정상적인 Unet 파라미터수와 동일한 입출력 shape, segmentation을 하려면 입출력 shape가 같아야함. 출력값 범위가 0~1사이 인건 Sigmoid가 정상 작동중
이제 DataLoader + UNet을 연결해서 실제로 학습 루프를 돌려보겠습니다.
지금은 라벨(마스크) 데이터가 없으니까 노이즈 제거(Denoising) 태스크로 학습해볼게요.
(bmo) admin@admins-MacBook-Pro dicom % python unet.py
총 파라미터 수: 31,042,369
입력 shape : torch.Size([2, 1, 512, 512])
출력 shape : torch.Size([2, 1, 512, 512])
출력 값 범위: 0.194 ~ 0.884
(bmo) admin@admins-MacBook-Pro dicom % python denoising.py
사용 디바이스: mps
볼륨 로드 완료: (189, 512, 512)
Epoch [1/5] Batch [0/48] Loss: 0.176776
Epoch [1/5] Batch [10/48] Loss: 0.052521
Epoch [1/5] Batch [20/48] Loss: 0.034586
Epoch [1/5] Batch [30/48] Loss: 0.029881
Epoch [1/5] Batch [40/48] Loss: 0.023622
▶ Epoch 1 평균 Loss: 0.043266
Epoch [2/5] Batch [0/48] Loss: 0.017703
Epoch [2/5] Batch [10/48] Loss: 0.013795
Epoch [2/5] Batch [20/48] Loss: 0.015462
Epoch [2/5] Batch [30/48] Loss: 0.014746
Epoch [2/5] Batch [40/48] Loss: 0.017192
▶ Epoch 2 평균 Loss: 0.016364
Epoch [3/5] Batch [0/48] Loss: 0.012206
Epoch [3/5] Batch [10/48] Loss: 0.014071
Epoch [3/5] Batch [20/48] Loss: 0.013253
Epoch [3/5] Batch [30/48] Loss: 0.009944
Epoch [3/5] Batch [40/48] Loss: 0.011301
▶ Epoch 3 평균 Loss: 0.012760
Epoch [4/5] Batch [0/48] Loss: 0.011338
Epoch [4/5] Batch [10/48] Loss: 0.009292
Epoch [4/5] Batch [20/48] Loss: 0.011518
Epoch [4/5] Batch [30/48] Loss: 0.010143
Epoch [4/5] Batch [40/48] Loss: 0.009825
▶ Epoch 4 평균 Loss: 0.010583
Epoch [5/5] Batch [0/48] Loss: 0.008357
Epoch [5/5] Batch [10/48] Loss: 0.009911
Epoch [5/5] Batch [20/48] Loss: 0.008895
Epoch [5/5] Batch [30/48] Loss: 0.010166
Epoch [5/5] Batch [40/48] Loss: 0.008308
▶ Epoch 5 평균 Loss: 0.009024
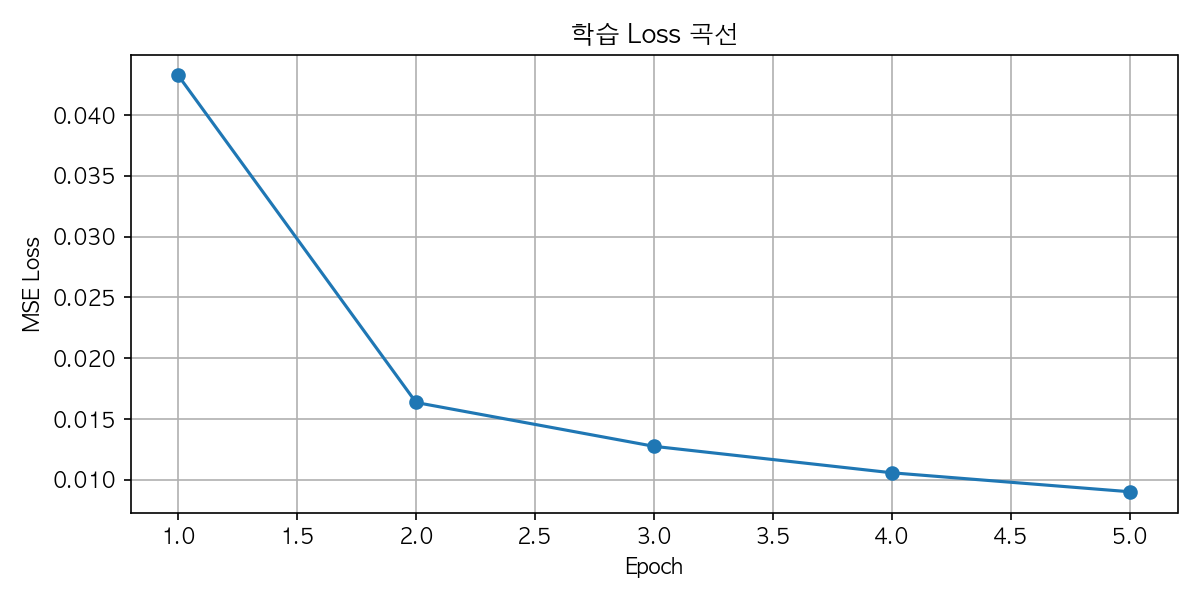
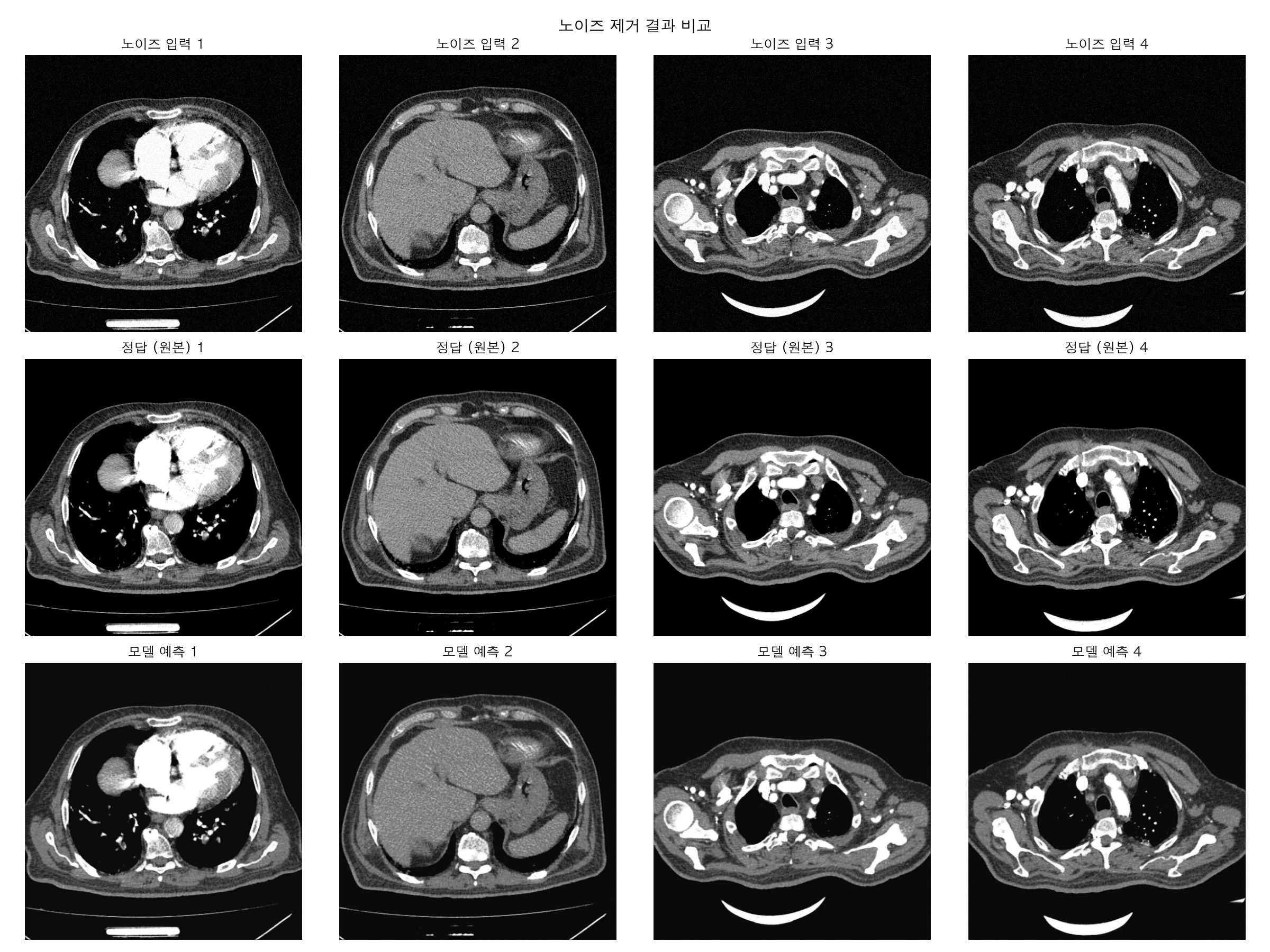
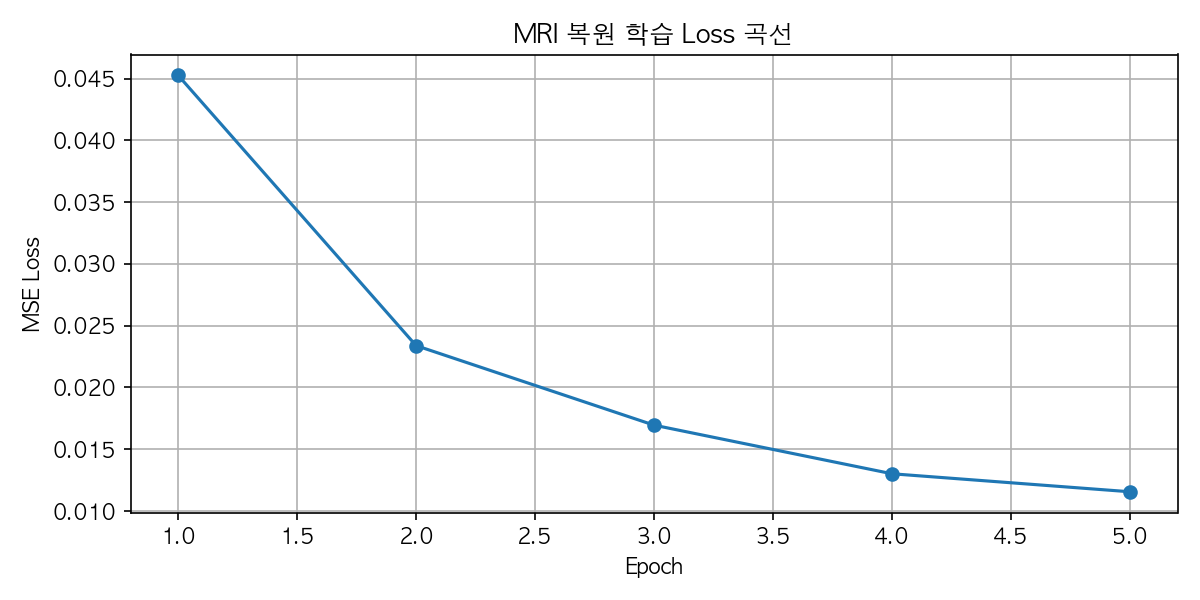
Loss 곡선이 0.043 → 0.009로 깔끔하게 수렴하고 있고. 발산 없이 안정적으로 내려가는 이상적인 형태네요.
노이즈 제거 결과 보면 1행(노이즈 입력)이랑 3행(모델 예측)을 비교하면 노이즈가 제거되면서 2행(정답 원본)에 가까워진 게 눈으로 보이죠? 에폭 5번만에 이 정도면 모델이 제대로 학습한걸 알 수 있다.
지금까지의 과정을 보면
DICOM 이론 학습
↓
pydicom 파일 탐색 & 메타데이터 출력
↓
HU 변환 & Windowing 시각화
↓
189장 → 3D 볼륨 (189, 512, 512)
↓
PyTorch DataLoader 구성
↓
UNet 구현 (31M 파라미터)
↓
실제 CT 데이터로 노이즈 제거 학습
까지 해봤고 그다음은 마지막 MRI단계인 fastMRI를 다뤄보겠습니다.
MRI자료는 https://fastmri.med.nyu.edu/ 페이지 맨 밑에서 이름과 이메일을 제출할 시 이메일로 다운로드 링크들을 보내준다. (신기하네)
꽤 많은 데이터셋들이 있었는데 그중에 나는 knee_singlecoil_val (~14.9 GB) 이걸 다운받았다. 이유는 첫째로 용량이 적당하다. train은 72.7GB라 맥북에서 부담되는데, val은 14.9GB로 실습하기 딱 좋은 용량.
둘째로 singlecoil이 구조가 단순하다는 점. multicoil은 코일 여러 개 데이터가 합쳐져 있어서 처음엔 복잡한 편인데 singlecoil은 CT처럼 이미지 하나라서 지금까지 한 파이프라인이랑 바로 연결됩니다.
셋째로 fastMRI의 핵심 태스크가 무릎 MRI라는 점
그래도 용량이 15GB정도 되기때문에 50분정도는 소요될 예정.
다운 받는 동안에 CT와 MRI의 차이에 대해 알아보자.
- CT는 HU값이라는 물리적 단위가 있었는데, MRI는 그게 없어요. 대신 T1, T2 같은 시퀀스마다 밝기 의미가 달라요.
CT → HU값 (-1024 ~ 3071), 절대적 수치
MRI → 상대적 강도값, 장비/시퀀스마다 범위가 다름
→ 그래서 정규화가 훨씬 중요- CT는 슬라이스마다 .dcm 파일이 따로 있었는데, fastMRI는 한 환자의 전체 k-space 데이터를 .h5 파일 하나에 담는다..
# CT 때는 이랬는데
ds = pydicom.dcmread("D0001.dcm")
# fastMRI는 이렇게 읽어요
import h5py
with h5py.File("file1000000.h5", "r") as f:
print(list(f.keys())) # kspace, reconstruction_esc 등
```
---
**k-space가 뭔지 미리 알아두기**
MRI는 이미지를 직접 찍는 게 아니라 **주파수 공간(k-space)** 에서 데이터를 수집한 다음 푸리에 변환으로 이미지로 변환해요.
```
k-space (주파수 데이터)
↓ 역 푸리에 변환 (IFFT)
MRI 이미지처음 보는 용어들이 많네요. 차근차근 알아봅시다.
1️⃣ k-space가 뭐냐
📌 한 줄 정의
MRI가 실제로 측정하는 원시(raw) 신호가 저장되는 주파수 공간
MRI는 카메라처럼 픽셀을 직접 찍지 않는다.
자기장 + RF 신호를 이용해서
몸에서 나오는 진동 신호(주파수 성분) 를 수집한다.
그 신호를 2D 격자에 저장한 게 → k-space
직관적으로 보면

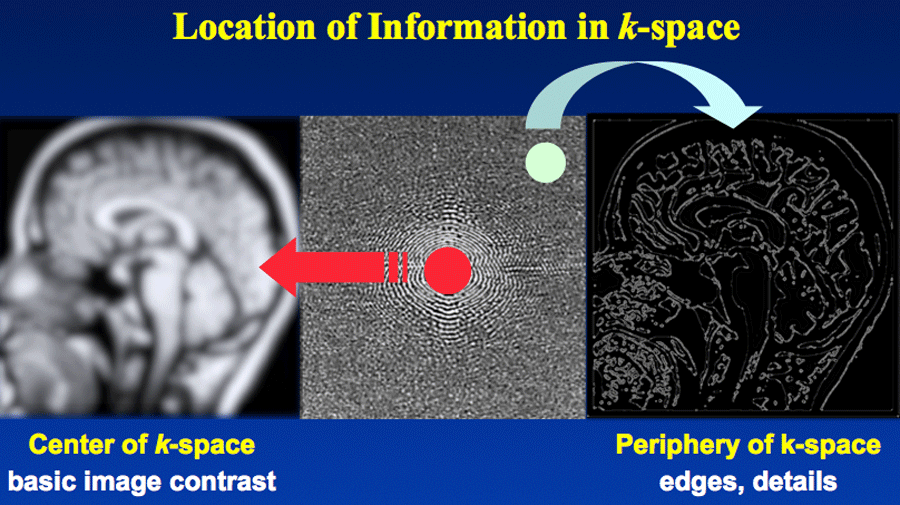
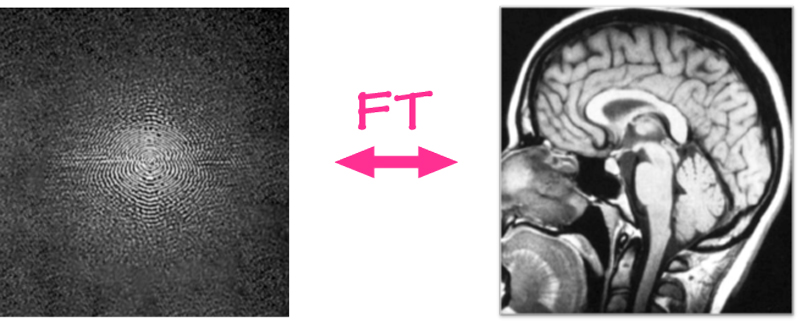
가운데 밝은 부분 → 저주파 (전체 윤곽)
바깥쪽 → 고주파 (경계, 디테일)
2️⃣ 왜 주파수로 저장하냐?
이미지는 이렇게 생각할 수 있다:
하나의 이미지는 여러 개의 사인파가 겹쳐진 결과, 수학적으로는: Image(x,y)=∑A⋅ei(kxx+kyy)
MRI는 이 A 값을 직접 측정한다. 그 좌표계가 바로 k-space.
3️⃣ 역 푸리에 변환(IFFT)이 뭐냐
푸리에 변환:
공간 → 주파수
역 푸리에 변환:
주파수 → 공간(이미지)
k-space 데이터
↓ IFFT
MRI 이미지
MRI reconstruction은 본질적으로:
부분적으로 비어 있는 k-space를
어떻게 복원해서
더 좋은 이미지를 만드느냐
이 문제다.
Incomplete k-space
↓
Neural Network
↓
Full-resolution MRI image
5️⃣ 왜 이게 어려우냐
k-space는:
complex number (실수+허수)
coil 정보 포함
phase 정보 중요
CT처럼 그냥 float 이미지가 아니다.
위에 처럼 말해도 모르는 용어들이 많아서 더 알아보자.
1️⃣ Complex Number (복소수)
📌 왜 MRI는 실수가 아니라 복소수냐?
MRI는 파동 신호를 측정한다.
파동은 크기(amplitude)만 있는 게 아니다.
→ 위상(phase) 도 있다. (위상에 대한 설명은 밑에서 나옴)
그래서 한 픽셀 값이 이렇게 생긴다 => a+bi
a = real part
b = imaginary part
i = √(-1)
🔎 왜 굳이 허수가 필요하냐?
파동은 이렇게 표현된다 => Aeiθ
A = 세기
θ = 위상
이걸 계산하려면 복소수 표현이 가장 자연스럽다.
코드에서 보면
kspace.dtype
# complex64IFFT 하면:
img = np.fft.ifft2(kspace)여전히 복소수다. (complex64라는 게 복소수라는 뜻이더라구요 numpy에서 쓰는 표현)
우리가 화면에 보여줄 때만:
np.abs(img)를 쓴다.
→ magnitude 이미지
2️⃣ Coil 정보
MRI 기계는 안테나(coil) 로 신호를 받는다.
요즘 MRI는:
8채널
16채널
32채널 coil
을 동시에 사용한다.
즉:
한 장의 MRI 이미지 = 여러 개의 coil 이미지 합성 결과
fastMRI 구조 예시
kspace shape:
(num_slices, num_coils, height, width)예:
(20, 15, 640, 372)→ 15개 코일에서 동시에 수집
왜 여러 개 쓰냐?
신호 감도 향상
촬영 속도 증가 (Parallel Imaging)
coil 정보를 제대로 활용해야 한다.
3️⃣ Phase (위상)
이게 제일 중요하다.
이미지는 단순 밝기만 있는 게 아니다.
파동은:
크기 (밝기)
위상 (공간 정보)
둘 다 있어야 정확하다.
직관적으로 보면
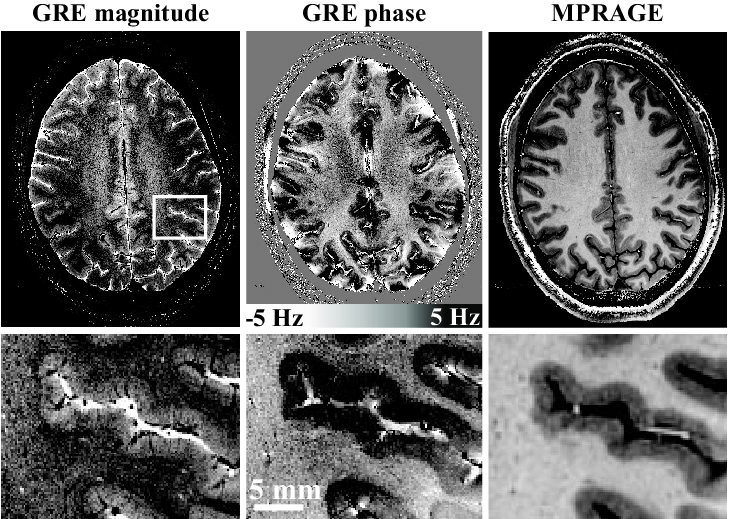
magnitude → 우리가 보는 MRI
phase → 숨겨진 구조 정보
왜 phase가 중요하냐?
coil sensitivity 보정
motion correction
flow imaging
artifact 제거
Phase 날리면
reconstruction 품질 떨어진다.
| 개념 | 의미 |
|---|---|
| k-space | MRI가 측정한 주파수 데이터 |
| FFT | 이미지 → 주파수 |
| IFFT | 주파수 → 이미지 |
| Undersampling | 일부만 찍어서 빠르게 촬영 |
| Reconstruction | 딥러닝으로 복원 |
| Complex | 파동 표현 |
| Coil | 다중 수신 → 고속 촬영 |
| Phase | 공간 정합 + 정확한 복원 |
깊게 들어가니까 한도 끝도 없이 깊게 들어가버릴 거 같은 느낌이네..
다시 돌아와서 MRI 실습해보자. 압축파일이 커서 기존 사이트로는 안되어서 터미널에서 직접 압축해제하였다. tar -xvf [knee_singlecoil_val.tar]
h5 파일 구조부터 탐색해볼게요.
첫째로 h5 파일 안에 어떤 데이터가 들어있는지 구조가 출력되고, 둘째로 k-space를 역 푸리에 변환해서 MRI 이미지로 복원한 전체 슬라이스가 나올 것이다.
(bmo) admin@admins-MacBook-Pro dicom % python h5_read.py
=== 파일 내부 키 ===
['ismrmrd_header', 'kspace', 'reconstruction_esc', 'reconstruction_rss']
=== 메타데이터 (attrs) ===
acquisition: CORPDFS_FBK
max: 0.00017707173297391214
norm: 0.058663394182755665
patient_id: b2a82c7521fe2d4aebb627bbaae92a1916bf06e75cb374fc4187b0909e5c0e36
=== 각 데이터 shape ===
ismrmrd_header: (), dtype: object
kspace: (35, 640, 368), dtype: complex64
reconstruction_esc: (35, 320, 320), dtype: float32
reconstruction_rss: (35, 320, 320), dtype: float32
k-space shape : (35, 640, 368)
k-space dtype : complex64
MRI 이미지 shape: (640, 368)
값 범위: 0.00 ~ 0.00
mri_slices.png 저장 완료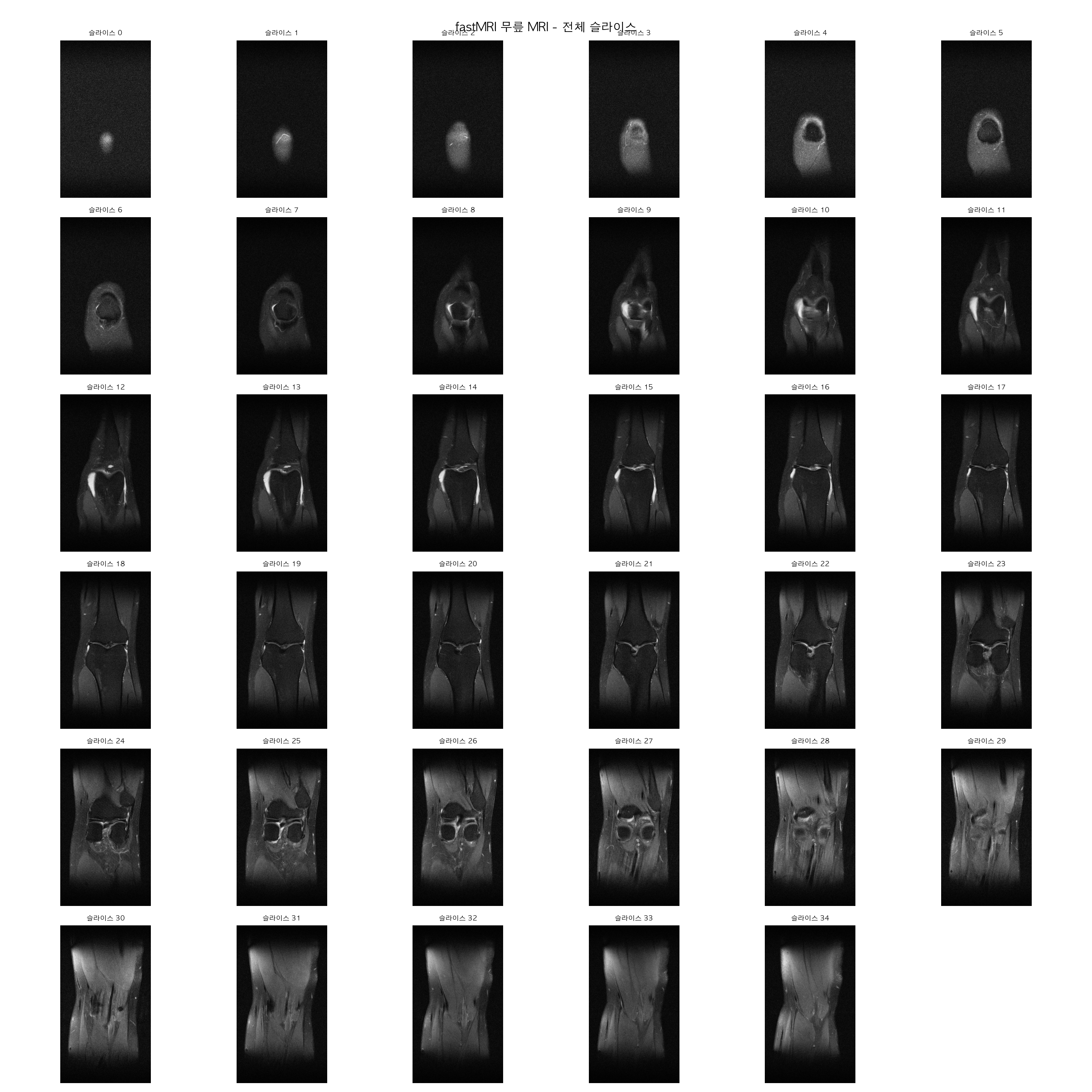
자주 보던 무릎 MRI slice네요.
결과 해석
acquisition: CORPDFS_FBK → Coronal PD Fat Suppressed 시퀀스예요. 무릎 연골/인대 보는 데 쓰는 시퀀스예요.
kspace: (35, 640, 368), complex64 → 35개 슬라이스, 복소수 데이터예요. CT의 픽셀값과 다르게 실수+허수로 구성돼 있어요.
reconstruction_esc / reconstruction_rss → fastMRI가 이미 복원해둔 정답 이미지예요. 이게 있다는 게 핵심이에요. 즉 k-space를 언더샘플링해서 노이즈 입력 만들고, 이 복원 이미지를 정답으로 학습하면 됩니다.
값 범위: 0.00 ~ 0.00 → 이건 역 FFT 방식이 살짝 달라서 에러가 난 거 같다.
k-space 변환 방식을 수정하고 언더샘플링까지 추가한 코드로 다시 실행시켜보겠다.
k-space shape : (35, 640, 368)
reconstruction shape: (35, 320, 320)
전체 샘플링 이미지 shape : (640, 368)
언더샘플링 이미지 shape : (640, 368)
마스크 샘플링 비율 : 25.5%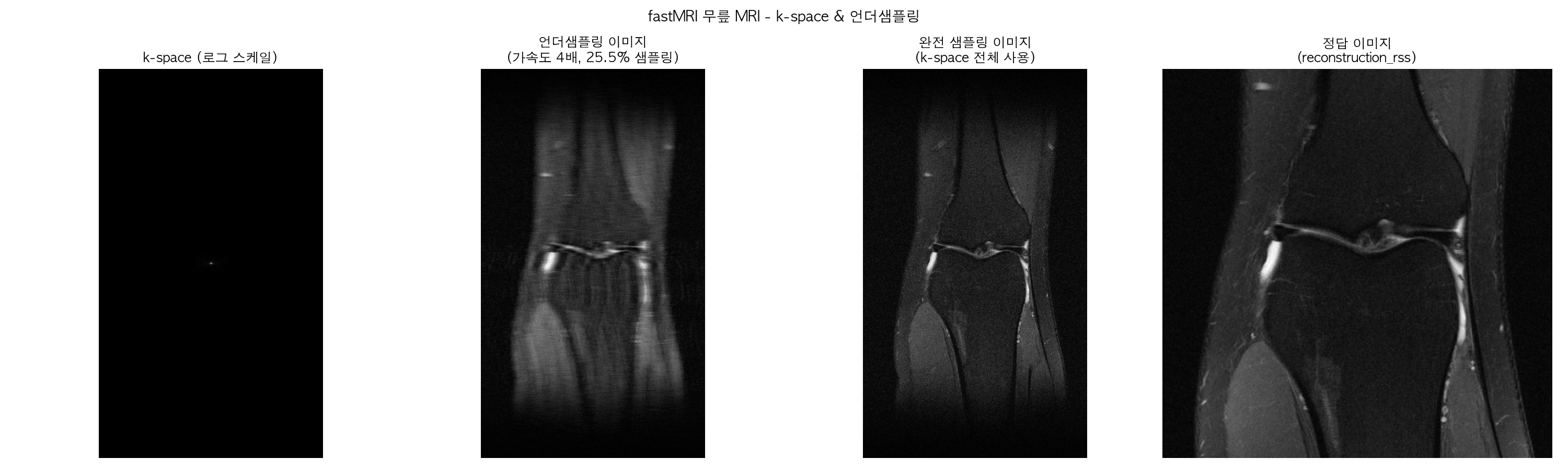
k-space가 거의 검정으로 보이는 건 정상이에요. 에너지가 중심부에 극단적으로 집중돼 있어서 로그 스케일로 봐도 주변부가 안 보이는 거예요.
언더샘플링 이미지를 보면 25.5%만 샘플링했는데도 무릎 구조가 보이죠? 이게 MRI의 특성이에요. k-space 중심부(저주파)만 있어도 전체적인 형태는 나와요. 대신 세로 방향으로 줄무늬 아티팩트가 생긴 게 보이는데 이게 언더샘플링 노이즈예요.
완전 샘플링 이미지는 줄무늬가 없어지고 훨씬 선명해졌고, 정답 이미지(reconstruction_rss)는 fastMRI 팀이 최적화한 복원 결과예요.
언더샘플링 이미지 (25% 샘플링, 촬영 4배 빠름)
↓
UNet
↓
정답 이미지 (완전 복원)
촬영 시간을 4분의 1로 줄이면서 화질을 유지하는 게 목표
다음 단계로 이 데이터로 UNet 학습 파이프라인 연결하는 걸 해보자.
CT 때 만든 파이프라인이랑 구조는 같고 데이터만 MRI로 바뀐 코드
노이즈를 인위적으로 추가하는 게 아니라 k-space 언더샘플링으로 입력을 만들고, 정답이 reconstruction_rss로 이미 존재한다는 거
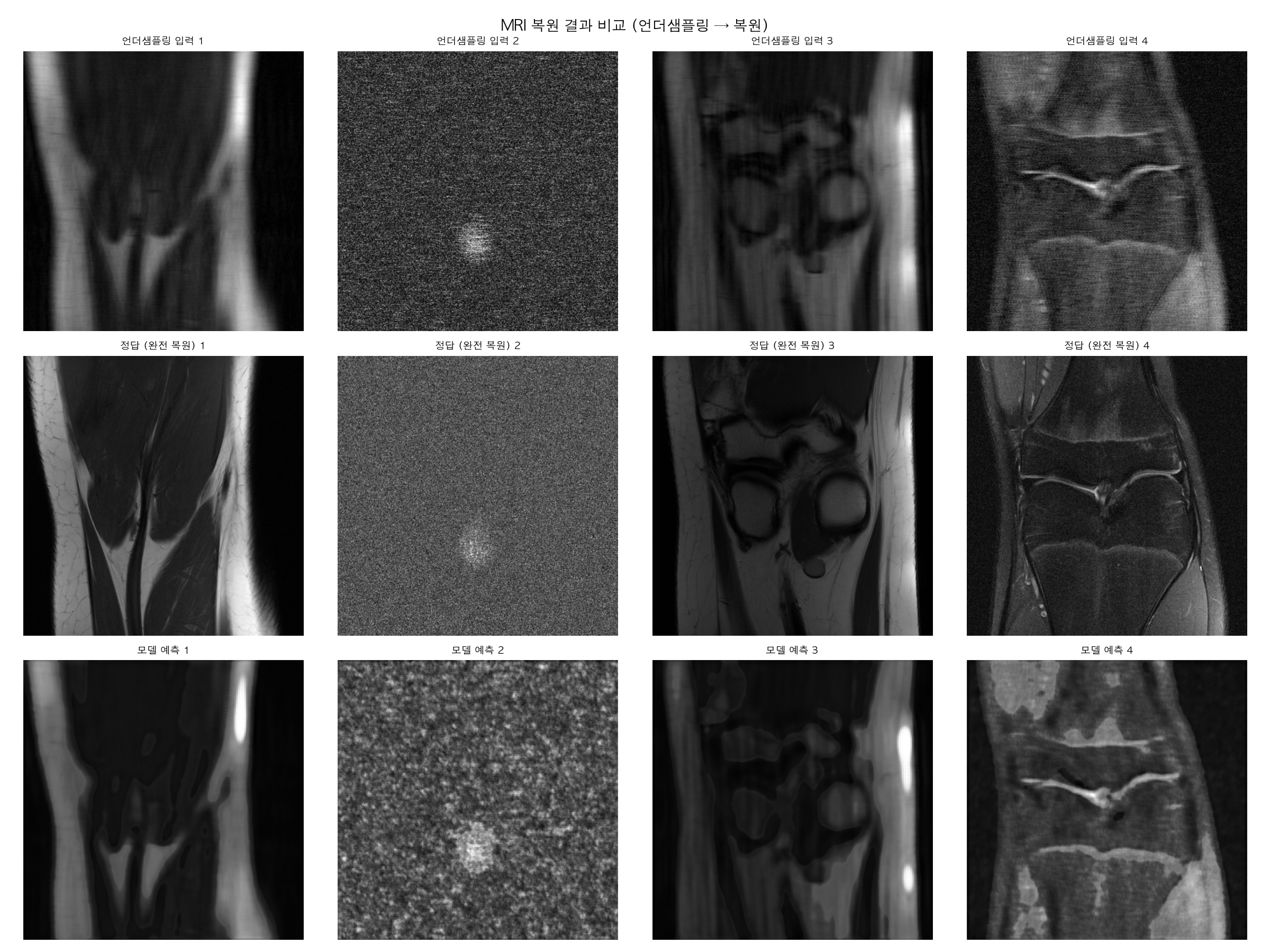
Loss가 0.045 → 0.011로 수렴하고 있어요.
근데 결과 이미지 보면 2번 슬라이스가 완전 노이즈로 나왔죠? 이건 버그가 아니라 데이터 문제예요. 일부 h5 파일에 비정상적인 슬라이스가 섞여 있어서 그래요. 실제 연구에서도 자주 만나는 상황이에요.
두 가지 개선해볼게요
첫째로 비정상 슬라이스 필터링, 둘째로 정량 평가 지표(PSNR, SSIM) 추가예요. 면접에서 "모델 성능을 어떻게 평가했나요?"라고 물어보면 MSE만 쓰면 약해요. PSNR/SSIM을 같이 쓰면 훨씬 설득력 있어요.
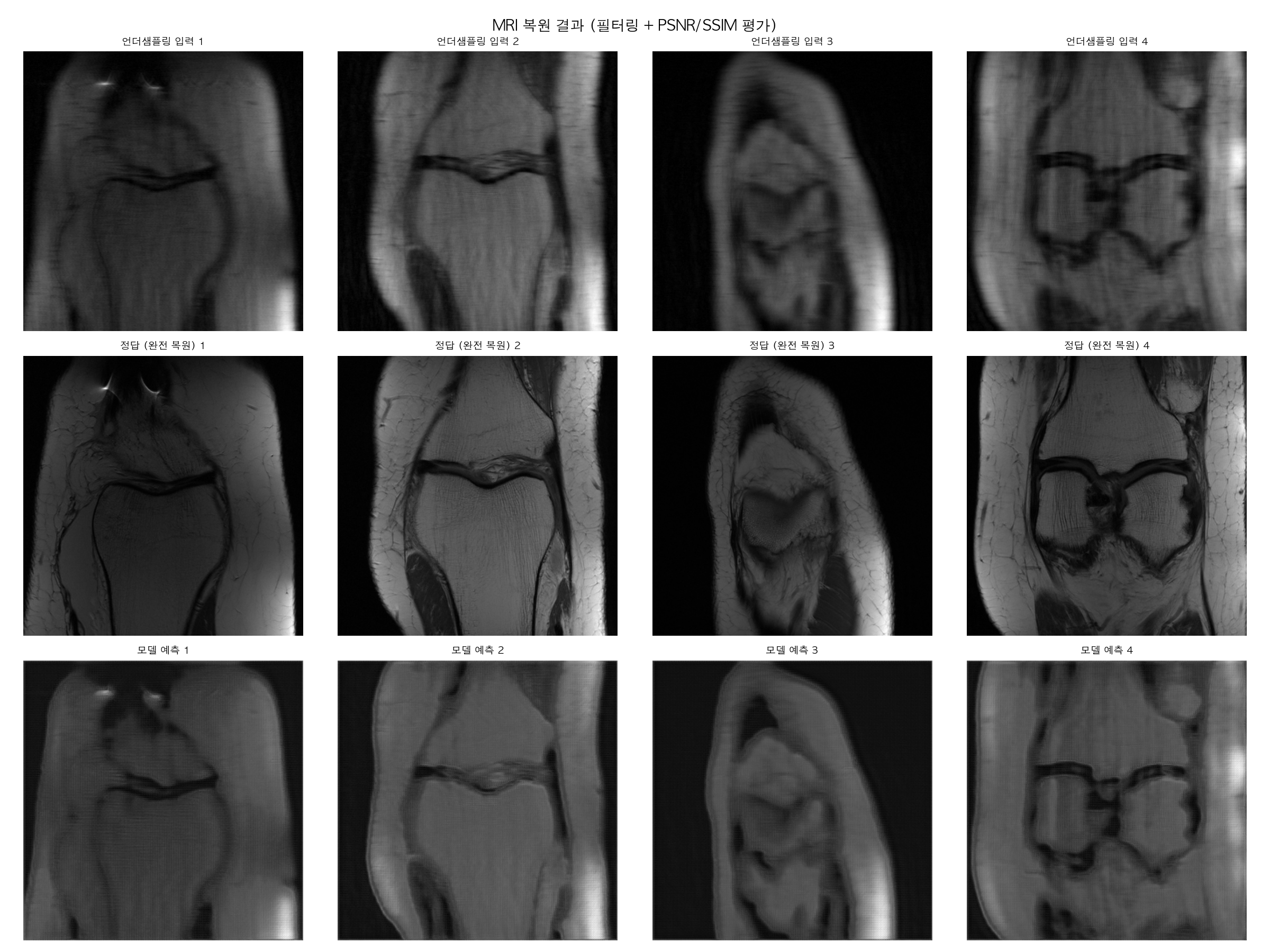
(bmo) admin@admins-MacBook-Pro dicom % python revision_pipeline.py
디바이스: mps
로드할 파일 수: 20
총 슬라이스 수: 41 (필터링: 664개 제거)
Epoch [1/5] Batch [0/11] Loss: 0.144299
▶ Epoch 1 평균 Loss: 0.122549
Epoch [2/5] Batch [0/11] Loss: 0.104677
▶ Epoch 2 평균 Loss: 0.085556
Epoch [3/5] Batch [0/11] Loss: 0.083384
▶ Epoch 3 평균 Loss: 0.076886
Epoch [4/5] Batch [0/11] Loss: 0.057444
▶ Epoch 4 평균 Loss: 0.057313
Epoch [5/5] Batch [0/11] Loss: 0.040402
▶ Epoch 5 평균 Loss: 0.049187
=== 정량 평가 결과 ===
PSNR 언더샘플링 입력: 26.41 dB
PSNR 모델 예측 : 12.93 dB ← 높을수록 좋음
SSIM 언더샘플링 입력: 0.7627
SSIM 모델 예측 : 0.3701 ← 1에 가까울수록 좋음
완료! unet_mri_v2.pth 저장됨
생각보다 PSMR 낮은데? 예측 그림도 좀 흐리고
결과 보니까 문제가 두 가지예요.
첫째, 필터링이 너무 공격적이에요.
705개 중 664개가 제거돼서 41개만 남았어요. 1e-6 기준이 너무 엄격해서 정상 슬라이스까지 날린 거예요. 데이터가 너무 적으니 모델이 제대로 학습을 못한 거고요.
둘째, PSNR이 입력보다 낮은 이유
언더샘플링 입력이 이미 26dB인데 모델이 12dB로 낮춰버렸어요. 이건 데이터 41개로 학습하기엔 너무 부족해서 모델이 오히려 이미지를 망가뜨리고 있는 거예요.
두 가지 고칠게요
필터링 기준을 완화하고, 크기 불일치 문제도 같이 잡을게요.
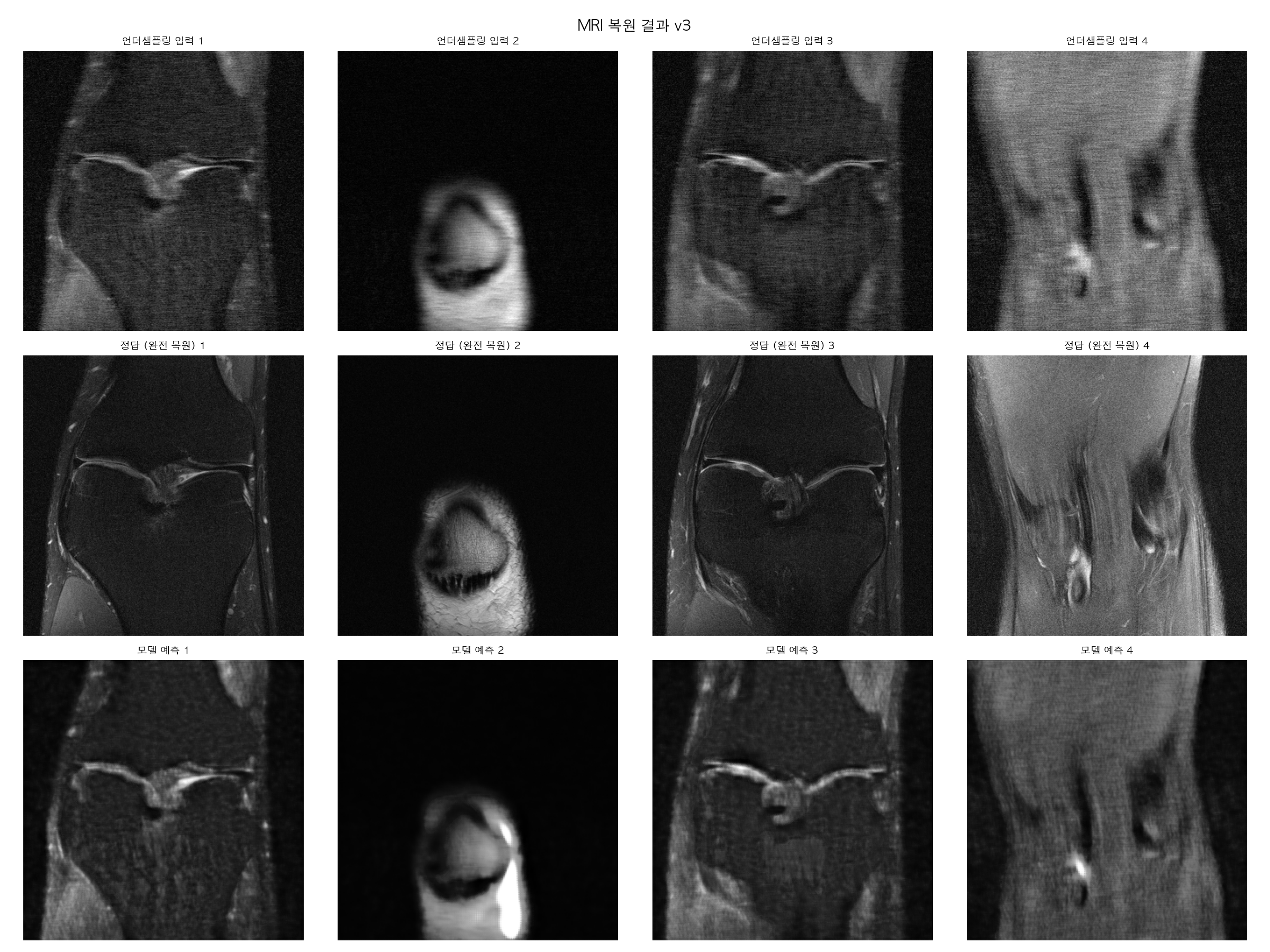
▶ Epoch 10 평균 Loss: 0.005826
=== 정량 평가 결과 ===
PSNR 언더샘플링 입력: 22.52 dB
PSNR 모델 예측 : 22.64 dB
SSIM 언더샘플링 입력: 0.5560
SSIM 모델 예측 : 0.5657
완료!
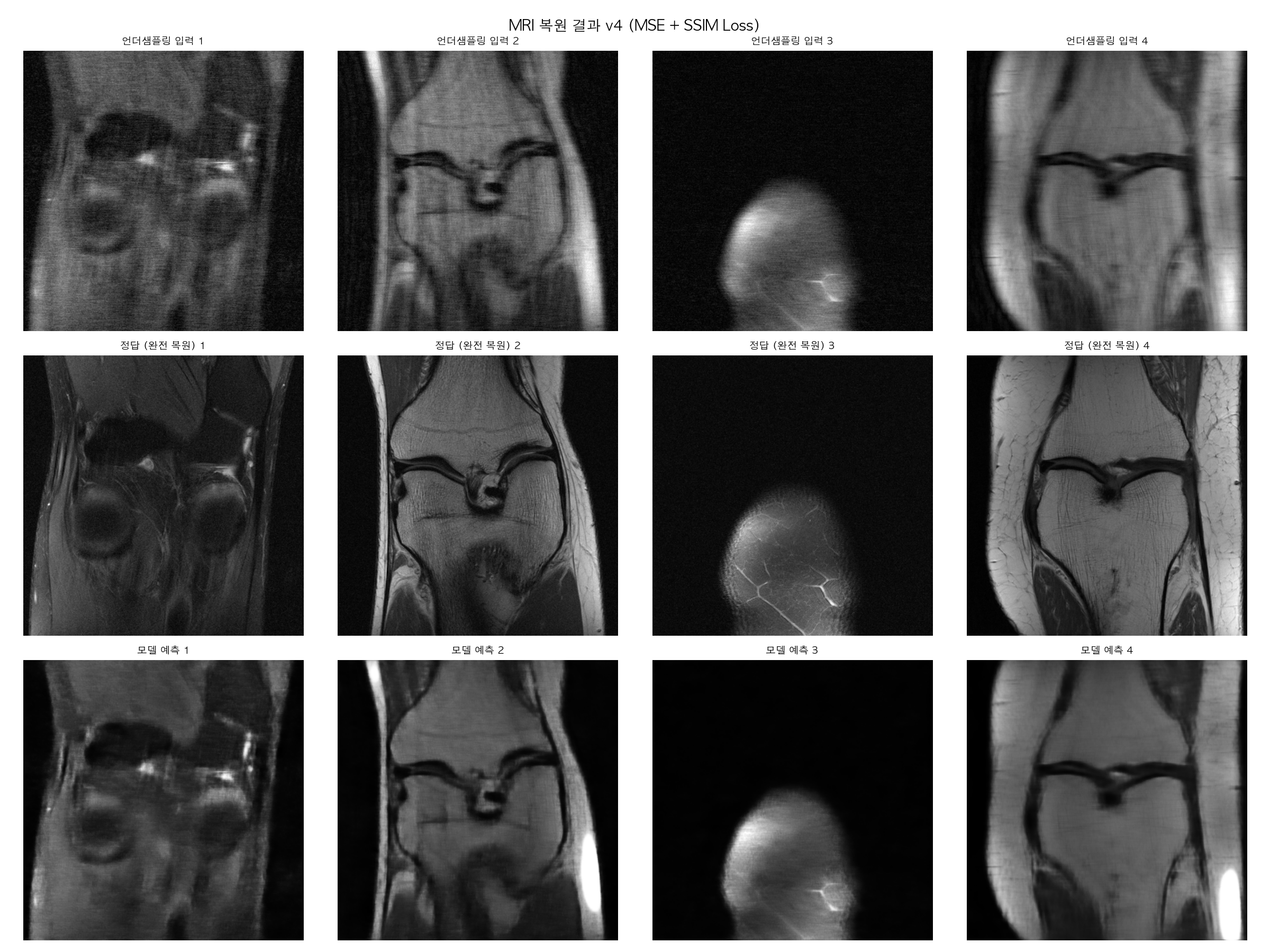
PSMR값이랑 SSIM 값 둘다 많이 올라오긴했는데 사진은 여전히 정답사진보다는 흐린 느낌이네요. "흐린 느낌"은 MSE Loss의 근본적인 한계인가봅니다.
왜 MSE Loss면 흐려지나요?
MSE는 픽셀값 평균 오차를 최소화하는데, 불확실한 영역에서 모델이 "평균값"을 출력하는 게 Loss를 낮추는 가장 쉬운 방법이에요. 그래서 선명한 엣지보다 뭉개진 중간값을 선택하게 됩니다.
MSE만 쓰면 → 흐릿하지만 Loss는 낮음 ✅
엣지 살리면 → 선명하지만 MSE Loss는 높음 ❌
Loss 함수만 교체하면 어떻게 되는지 한번 봐볼까요?
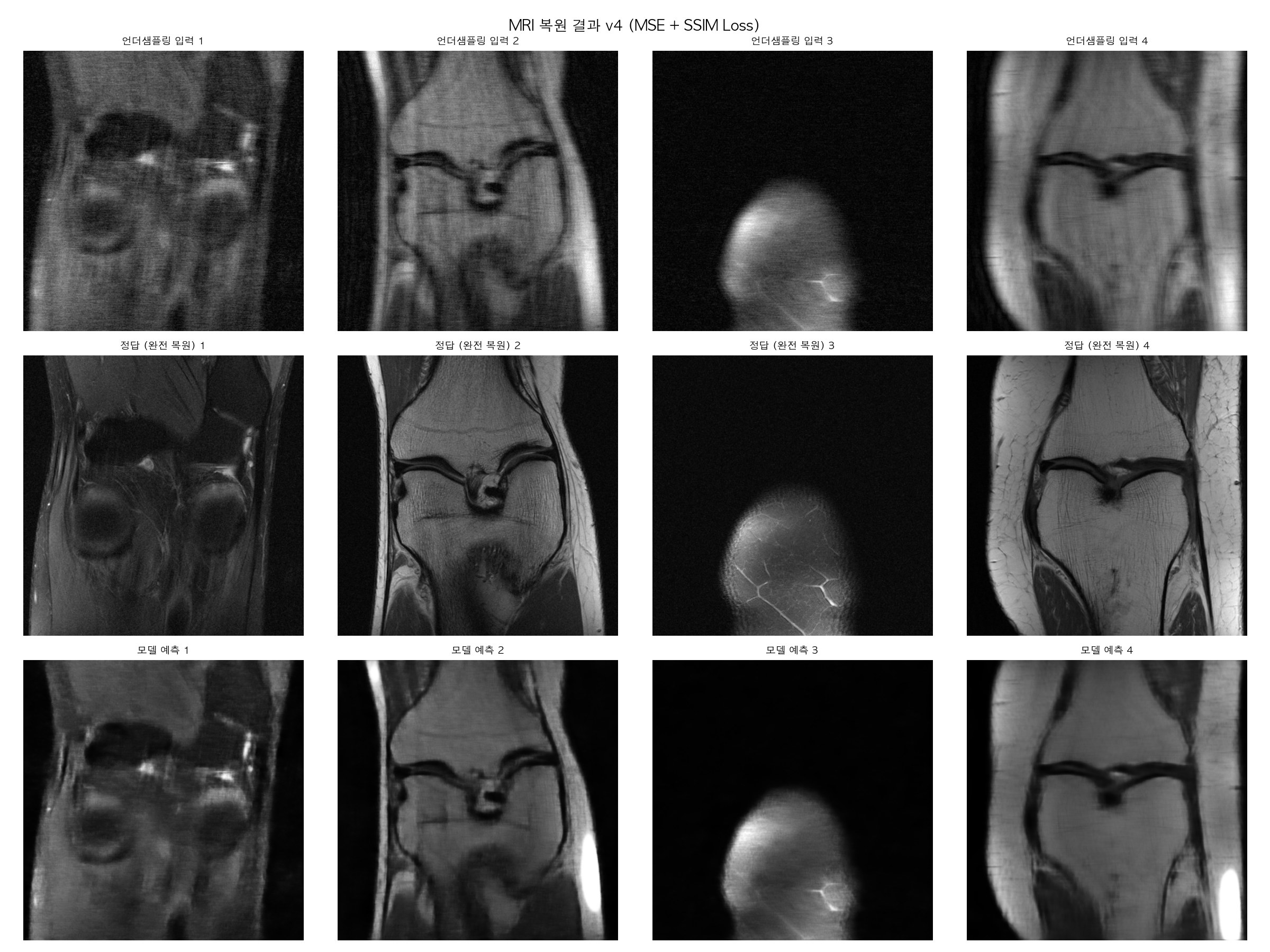
=== 정량 평가 결과 ===
PSNR 언더샘플링 입력: 22.54 dB
PSNR 모델 예측 : 24.58 dB
SSIM 언더샘플링 입력: 0.5563
SSIM 모델 예측 : 0.6751
그전꺼랑 비교해보면 PSNR 2dB 상승, SSIM 0.12 상승이면 Loss 함수 하나 바꾼 것치고 꽤 큰 개선이네요. 이미지도 보면 2번, 4번 슬라이스에서 엣지가 훨씬 선명해진 게 눈에 띄네요.
이전에 일하면서 많이 봐왔던 MRI와 CT 사진들이 어떤 원리로 촬영되었는지 알게되고 실제로 DICOM, PyTorch, UNet, 3D 처리 기술들을 사용해서 파이프라인을 만들어보았다.
이 실습의 핵심 목표
DICOM → HU → Windowing → 3D 볼륨 이해
k-space → IFFT → Undersampling → Reconstruction
CT 기반 복원과 MRI 기반 복원의 차이 체득
MSE 한계 확인 후 Loss 설계 개선
단순 구현이 아니라, 의료영상 복원의 본질을 이해하는 과정이었다.
fastMRI의 reconstruction_rss를 정답으로 학습했지만 실제 임상 환경에서는 fully-sampled ground truth가 존재하지 않는 경우가 많다.
Self-supervised reconstruction (e.g., data consistency 기반 학습) 방향도 추가로 탐구해보고 싶다.
