0. 이 글을 쓰는 이유
이전에 우아한형제들 기술블로그에서 신입 백엔드 개발자 파일럿 프로젝트 글을 보던 중
CQS 패턴을 적용한 걸 보게 되었다. 글을 읽으면서 어떤 장점이 있을까 생각하면서 적용해보면 괜찮겠는 생각이 들었다.
그래서 YAPP 프로젝트를 진행하면서 CQS 패턴을 적용해 보았고, 느낀점들은 아래에서 이야기 하겠다.
그리고 마침 다른 개발자분들의 AWS Aurora를 통해 Read/Write DB를 분리하는 관련 대화와 블로그를 보면서 관심이 생겼다.
CQS 패턴을 적용한김에 Read/Write DB까지 분리하여 조금 더 견고한 서비스를 지향하면 좋겠다는 생각이 들어서 AWS Aurora를 통해 Read/Write DB를 분리해보고자 한다.
1. CQS 개념 및 적용
1-1. CQS란?
Command-Query Separation의 약자로, Command와 Query를 분리하는 것을 의미한다.
CQS는 Command and Query Separation으로 Command와 Query를 분리하는 패턴, 원리를 의미한다.
보통 CQS 패턴 , CQS 원리 라고 이야기 한다.
- Command는 상태를 변경하고, 결과값을 반환하지 않는다.
- Query는 상태를 변경하지 않고, 결과값을 반환한다.
상태 변경 여부에 따라 비즈니스 로직 메서드를 나누는건 명확하게 할 수 있을 듯 하지만,
”Command는 결과값을 반환하지 않는다” 라는 조건은 지키기 힘들다.
김영한님 말씀에 따르면 insert는 id만 반환하도록 하는것을 권장한다고 한다.
1-2. CQRS란
-
CQRS는 Command and Query Responsibility Segregation으로 Command와 Query의 책임을 분리하는 패턴이다.
-
CQS 패턴으로부터 나온 패턴이며, 차이점이라고 하면 CQS는 연산 레벨에서 Command와 Query를 분리하지만 CQRS는 객체 또는 시스템 레벨에서 Command와 Query를 분리한다.
-
JPA를 예로들면, User라는 엔티티를 조회하는 엔티티(모델)와, User라는 엔티티를 저장, 수정, 삭제할 때 사용하는 엔티티(모델)를 서로 다른 객체로 분리하는 것으로 이해했다.
1-3. CQS vs CQRS?
-
CQRS는 CQS패턴을 포함하고 있어서, 커맨드와 쿼리를 분리하는 것은 같은 개념이다.
-
굳이 두 패턴을 구분하자면 아래 두가지 조건을 만족여부에 따라, CQS와 CQRS를 구분할 수 있을듯하다.
- 굳이라고 표현한 이유는 둘을 구분하는게 중요하지 않다고 생각해서이다. 핵심은 커맨드와 쿼리를 분리한다는 것이다.
-
저장소 분리
-
커맨드를 위한 저장소와, 쿼리을 위한 저장소를 분리하는 것
-
즉 커맨드 전용 DB와, 쿼리 전용 DB를 분리하는 것
-
-
모델 분리
-
커맨드를 위한 모델(객체)와, 명령을 위한 모델(객체)을 분리하는 것
-
JPA를 예로들면, User라는 엔티티를 조회하는 엔티티(모델)와, User라는 엔티티를 저장, 수정, 삭제할 때 사용하는 엔티티(모델)를 서로 다른 객체로 분리하는 것을 의미한다.
-
처음엔 같은 모델을 사용하고, 연산(쿼리) 레벨에서만 분리했으므로
CQS 패턴을 적용했다고 생각했었는데, 물리적인 저장소는 분리했으니까 CQRS 패턴을 적용
했다고도 말할 수 있을 것 같다. 꼭 어떤 패턴을 적용했다가 중요한건 아니니 넘어가자.
1-4. Spring + JPA 애플리케이션에서의 적용 예시
-
내부에서 변경(사이드 이펙트)가 발생하는 메서드와
사이드 이펙트가 발생하지 않는 메서드를 명확히 분리 -
레이어 아키텍처에서는 Service 클래스를 두 개의 클래스로 분리하여 적용
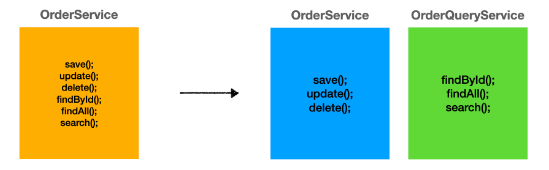
1-4-1. 적용
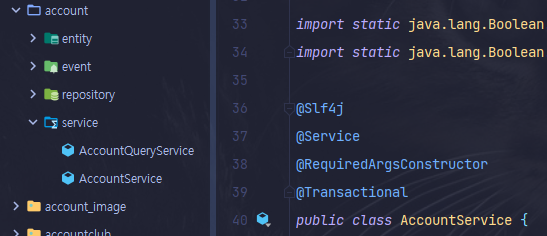
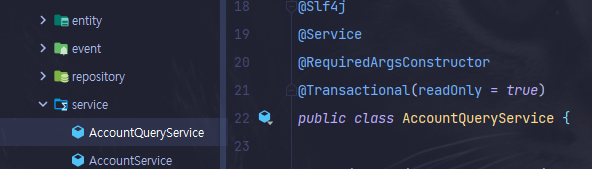
-
간단하게
xxxService와xxxQueryService로 클래스를 분리하고, 클레스 레벨에 @Transactional을 적용했다. -
xxxCommandService,xxxQueryService로 네이밍을 해도 된다. 취향 차이인듯 하다.
1-5. CQS 패턴 적용 후 느낀점
1-5-1. 코드레벨에서
-
가독성 향상
- 커맨드와 쿼리 메서드가 서로 다른 클래스로 분리되면서, 한 클래스의 코드양 감소
-
유지보수 용이
- 커맨드에 문제가 있는지, 쿼리(조회)에 문제가 있는지 파악 후, 해당 부분만 보면 됨
1-5-2. 아키텍처 관점에서 ( == DB Replication의 장점)
-
성능 향상
- 조회 요청과, 명령 요청이 분산되므로 더 많은 트래픽을 처리할 수 있다.
-
Failover
- Primary DB에 장애가 발생해도, 조회 기능에는 문제가 없다.
- Secondary DB를 Primary DB로 승격시켜서 해결 할 수 있다.
- AWS Aurora는 이를 자동으로 수행해준다.
1-5-3. 무조건 좋은가? (단점은?)
-
비교적 복잡한 구조로 인해, 모든 팀원이 이를 이해하고 있어야함
-
모른다면 개발 복잡도 증가 및 유지보수 비용 증가
-
대부분의 크리티컬한 장애 포인트는 데이터의 변경이 발생할 때 이므로,
Command에만 집중하여 유지보수를 용이하게 한다. -
조회시 필요한 데이터가 변경되더라도, 핵심 비즈니스 로직에는 영향을 미치지 않는다.
-
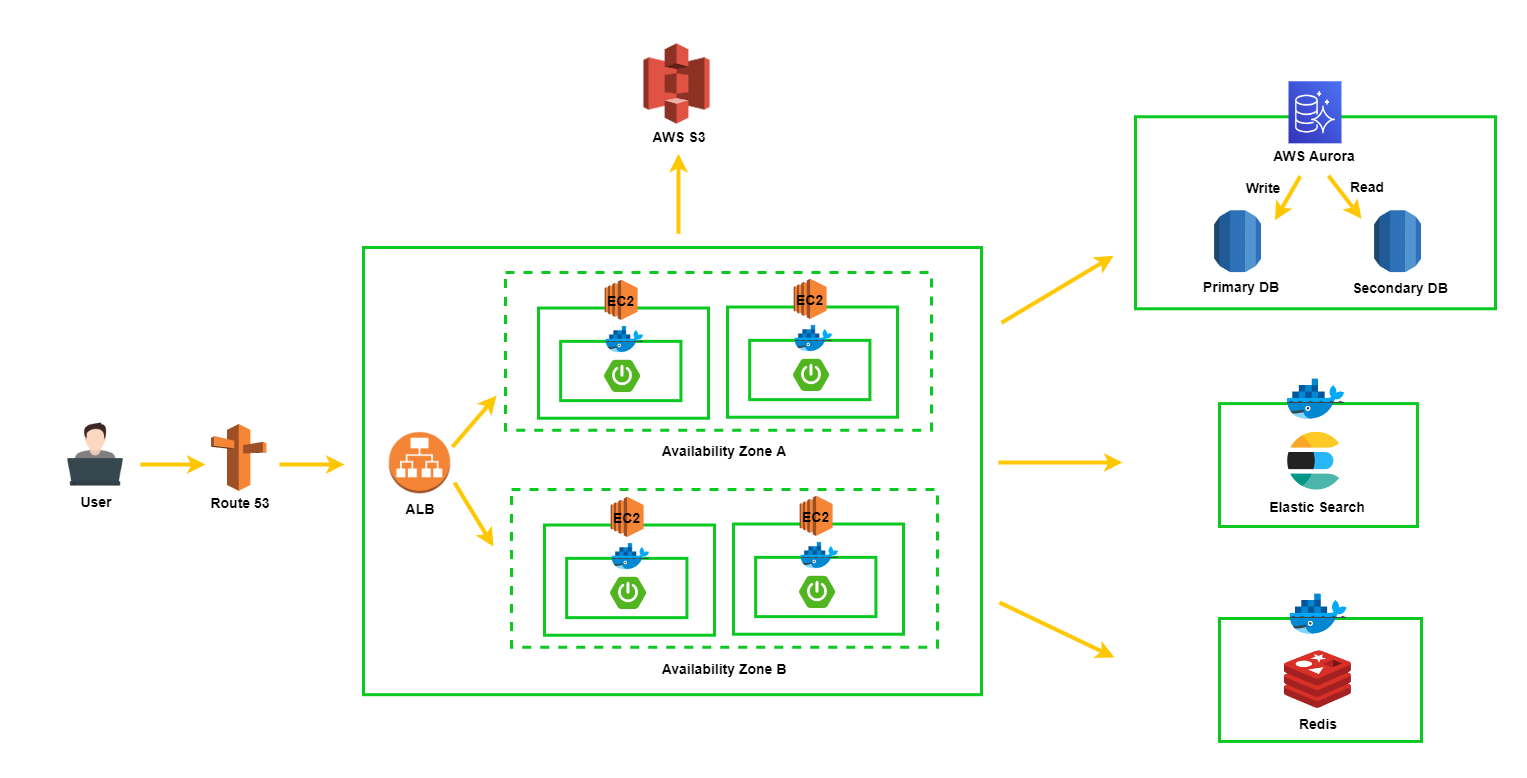
2. 서버 아키텍처
2-1. AS-IS
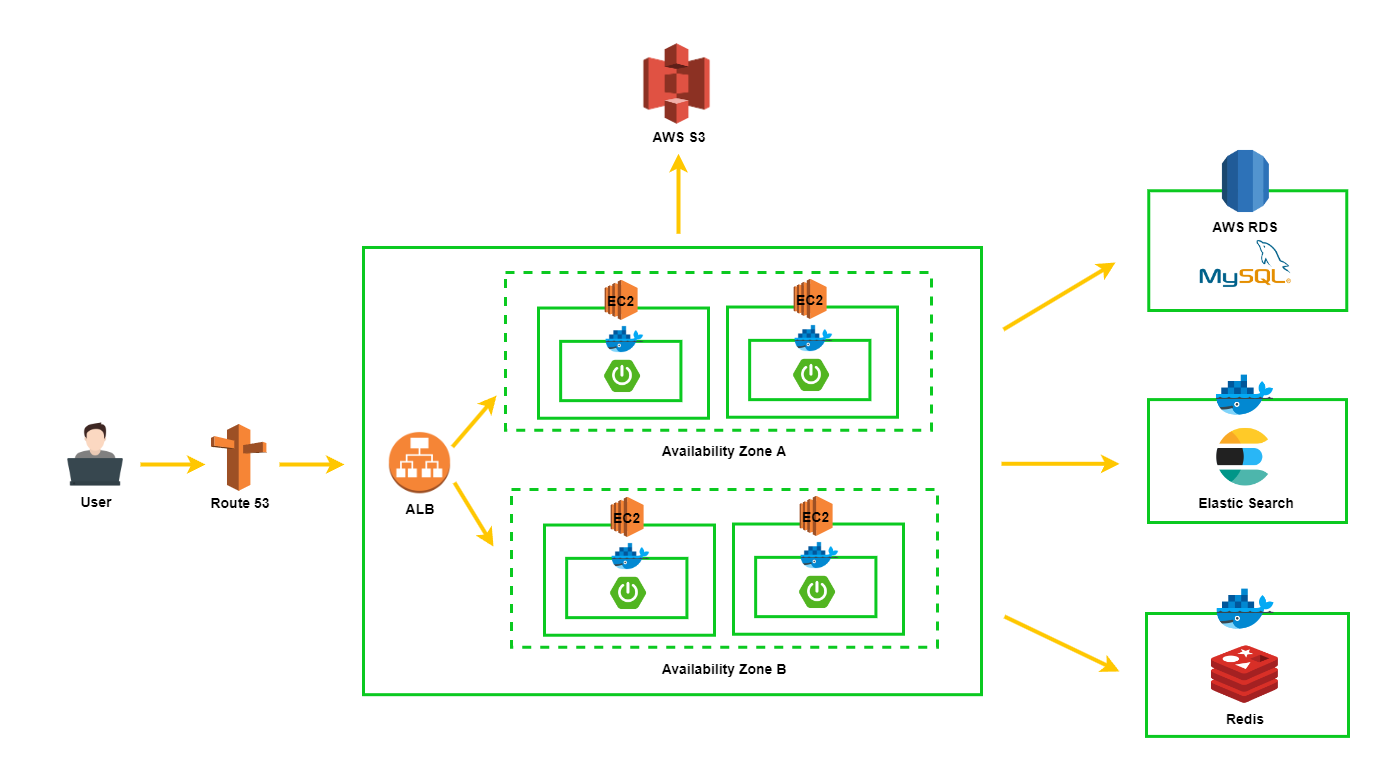
2-2. TO-BE
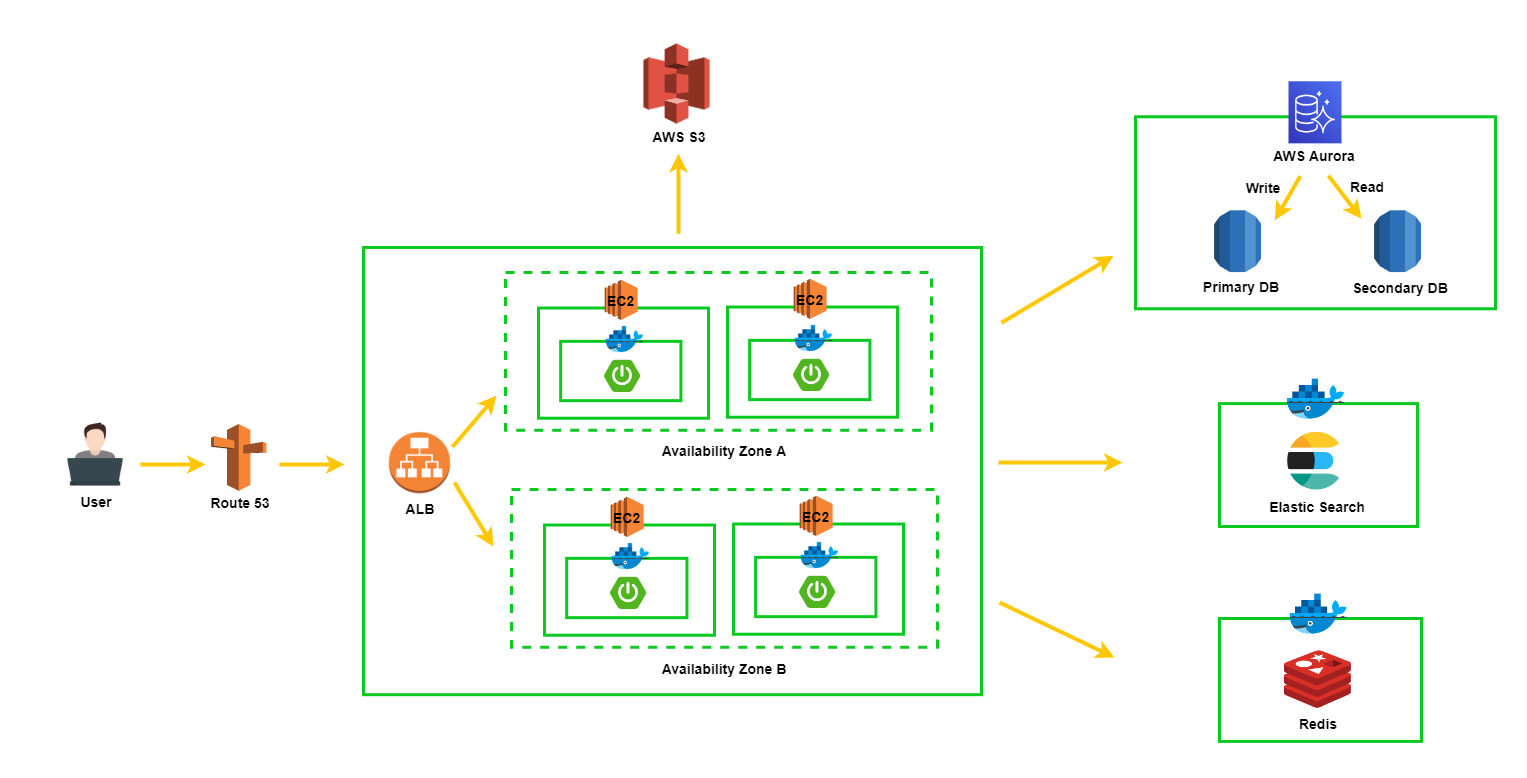
- DB를 Replication 하는 방법은 여러가지가 있겠지만, AWS의 Aurora 서비스를 사용해보려고 한다
3. Amazon Aurora
AWS에서 Amazon Aurora(Aurora)는 MySQL 및 PostgreSQL과 호환되는 완전 관리형 관계형 데이터베이스 엔진이라고 설명한다. 일부 워크로드의 경우 Aurora는 기존 애플리케이션을 거의 변경하지 않고도 MySQL의 처리량을 최대 5배, PostgreSQL의 처리량을 최대 3배 제공할 수 있다.
3-1. Amazon Aurora DB 클러스터
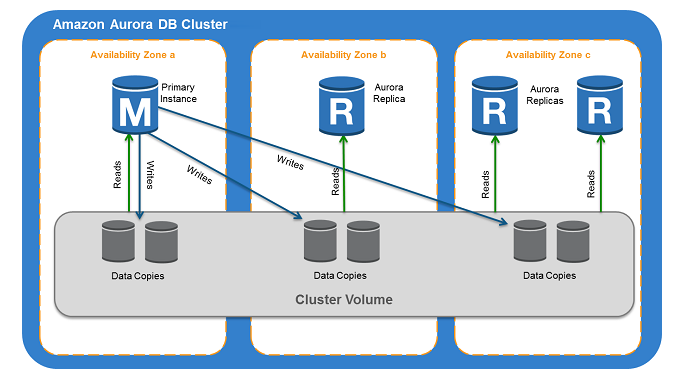
-
기본적으로 하나의 클러스터는 여러 가용영역으로 나뉘고, 하나의 기본 DB 인스턴스(Primary DB)가 있으며 여러 복제 DB 인스턴스(Secondary DB)들이 존재한다.
-
Primary DB
- read, write 모두 가능
- 클러스터당 하나씩만 존재
-
Secondary DB
-
read만 가능
-
최대 15개까지 지원하고, 하나의 엔드포인트만 애플리케이션에서 연결해도 여러 Secondary DB들로 로드밸런싱을 해준다.
-
Secondary DB들은 별도의 가용영역에 위치하므로, 고가용성을 유지한다.
-
Primary DB가 죽어도 자동으로 Secondary DB가 승격되는 failover 기능을 가지고 있다.
-
3-2. 데이터 동기화
- AWS Aurora를 보고 처음 든 생각은 Primary DB에 write한 데이터들을, Replication DB들 (Secondary DB)에 데이터를 어떻게 동기화 해주는거지? 였다. 간단히 살펴보자.

-
그림에서 볼 수 있듯이, 한 클러스터에 존재하는 모든 db들은 하나의 클러스터 볼륨을 공유한다.
-
Secondary로 보내는 데이터는 frm파일, Redo log여서 용량 자체가 적으므로 네트워크 대역폭을 적게 사용하고, write한 데이터들을 빠르게 전송 및 저장될 수 있는 구조라고 한다.
-
AWS는 데이터가 비동기로 100ms 이내로 데이터 동기화가 이루어진다고 설명한다.
-
그래도 wirte한 데이터가 동기화 되기전에 read 요청이 오는경우가 있다면 어떻게 될까 궁금하다면
delayed replication키워드로 더 찾아보면 될듯하다.
3-3. 리전 및 가용영역
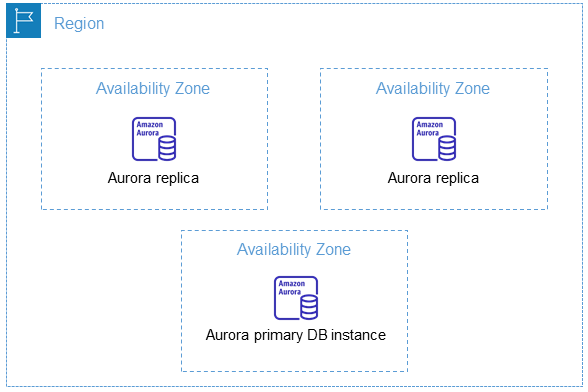
-
AWS Region은 개별 지리 영역으로, 각 Region에는 격리된 여러 Availability Zone(AZ)을 가지고있다.
-
여기서 특정 AZ에 장애가 발생해도, 다른 AZ에 있는 인스턴스가 살아 있기 때문에 위에서 이야기 했듯이 고가용성을 유지한다.
3-4. End-point
-
클러스터 엔드포인트 (라이터 인스턴스 엔드포인트)
-
Primary DB에 연결되는 엔드포인트이다.
-
유일하게 DDL, write 작업을 수행할 수 있는 엔드포인트
-
ex) mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com:3306
-
-
리더 엔드포인트
- Secondary DB들에 연결되는 엔드포인트이다.
- 여러 Secondary DB들이 존재할 수 있지만, 사용하는 우리는 하나의 리더 엔드포인트에 연결하면 알아서 각 DB 인스턴스들로 로드밸런싱을 해준다.
-
이외에도 사용자 지정 엔드포인트, 인스턴스 엔드포인트가 존재하는데
자세한 설명은 문서를 참고하자.
AWS Aurora에 대해 정말 간단히 알아봤고 자세한 설명은 해당 블로그에 매우 잘 정리되어 있으니 참고하면 좋을 듯 하다.
4. AWS Aurora 생성
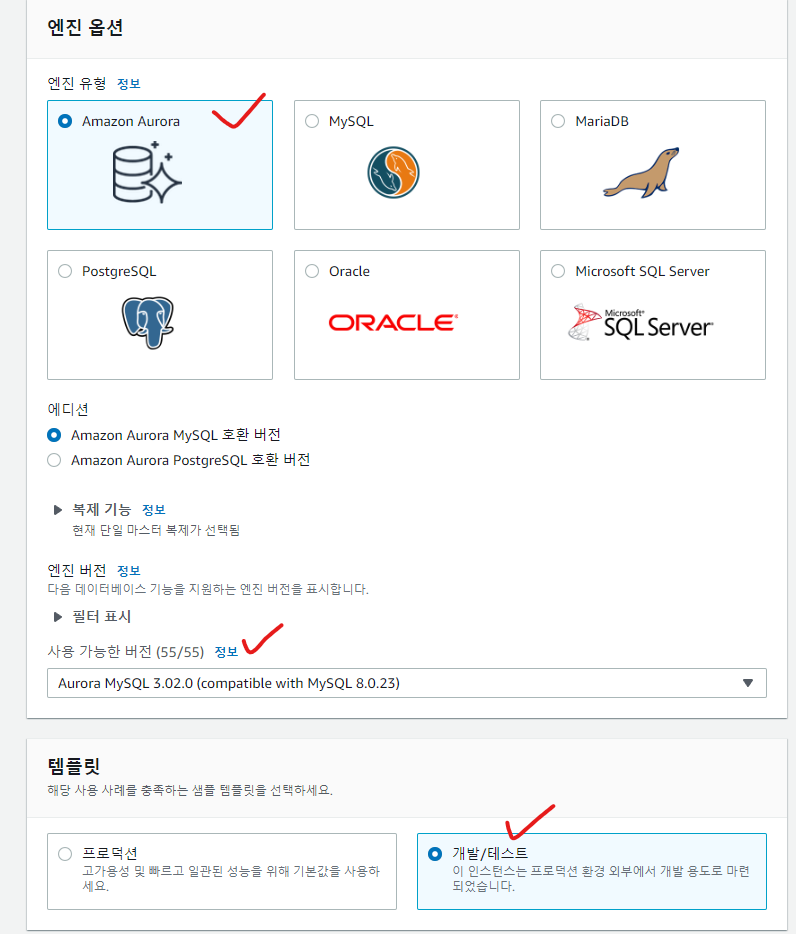
4-1. 버전 및 템플릿
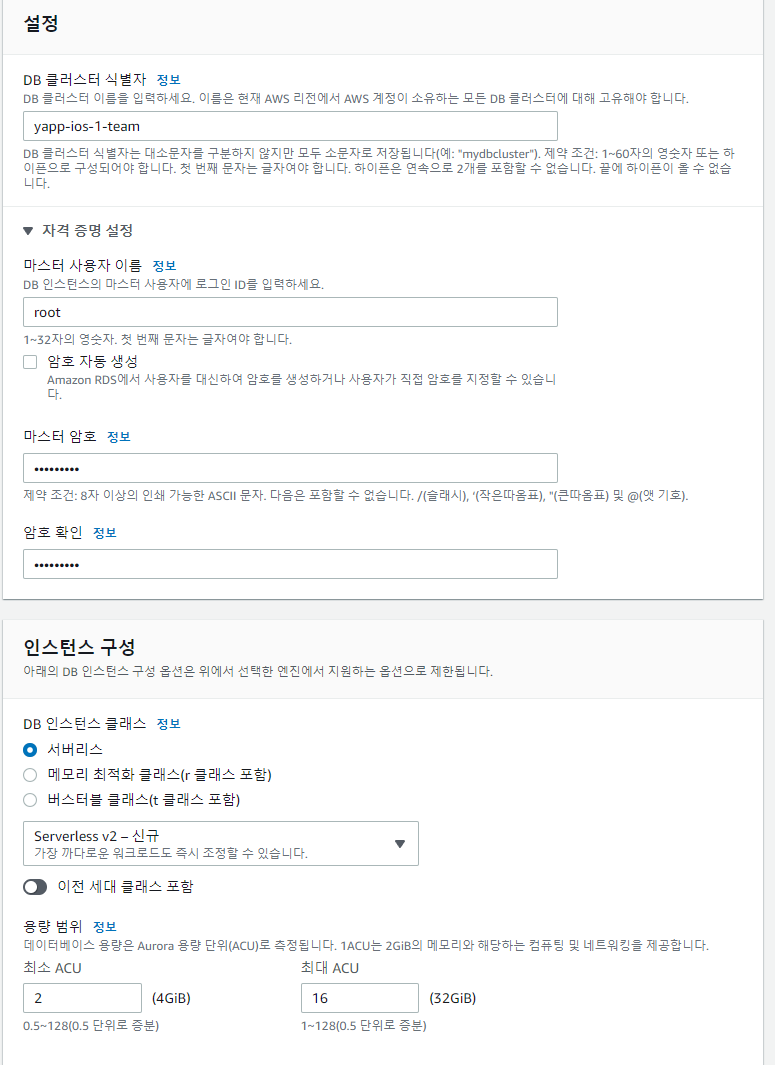
4-2. 설정 및 인스턴스
-
인스턴스는 서버리스를 선택했다.
-
가장 큰 특징은 오토 스케일링 기능 + 쓴만큼 비용지불이다.
-
앱을 출시하긴 했지만, 사용자는 거의 없을거라서 Aurora 적용 후 제거하려 했는데, 쓴 만큼만 비용지불한다고 하니 비용을 보고 계속 유지해도 될듯 싶다.
-
-
AWS Aurora serverless에 대한 자세한 내용은 aws 한국 블로그를 참고하자.
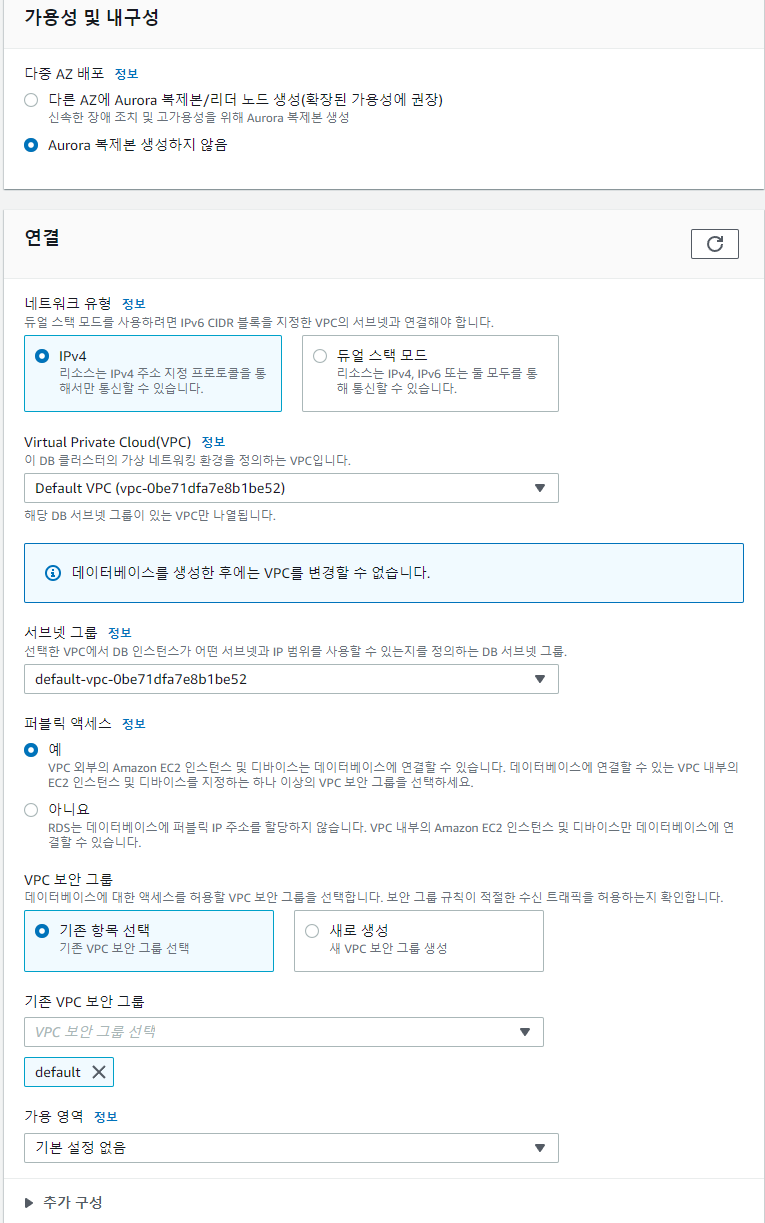
4-3. 연결 설정
-
다 기본값을 선택했다.
-
ALB도 default VPC를 사용하고 있기 때문에, 같은 default VPC를 선택하고
퍼블릭 IP 주소를 할당받지 않아도 되지만, 로컬에서 접속하기 위해서 할당 받았다
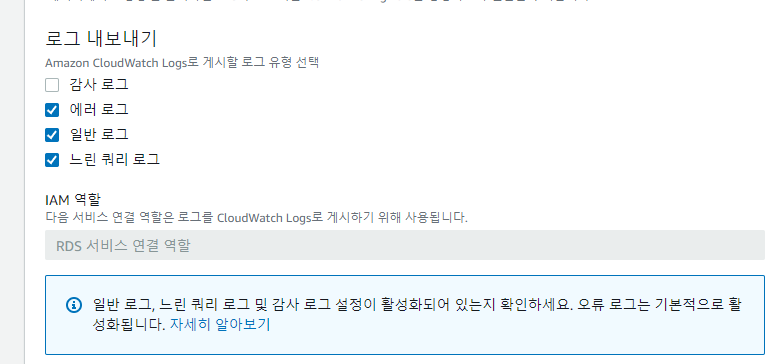
4-4. 추가 구성
-
추가 구성에서 로그 내보내기를 설정한다.
-
아래에 기본적으로 활성화 된다고는 하는데 일단 선택했다.
CloudWatch도 프리티어로 사용할 수 있다.
- 나중에 설정이 끝나면 여기서 로그를 확인할 수 있다.
4-5. 생성

- 생성 직후 보면 리전 클러스터, 리더 인스턴스가 보인다.

-
시간이 지나면 리더 인스턴스가 사라지고, 라이터 인스턴스가 생긴다.
-
이제 라이터 인스턴스를 Replication해서 리더 인스턴스를 만들어보자.
4-6. 리더 인스턴스 생성
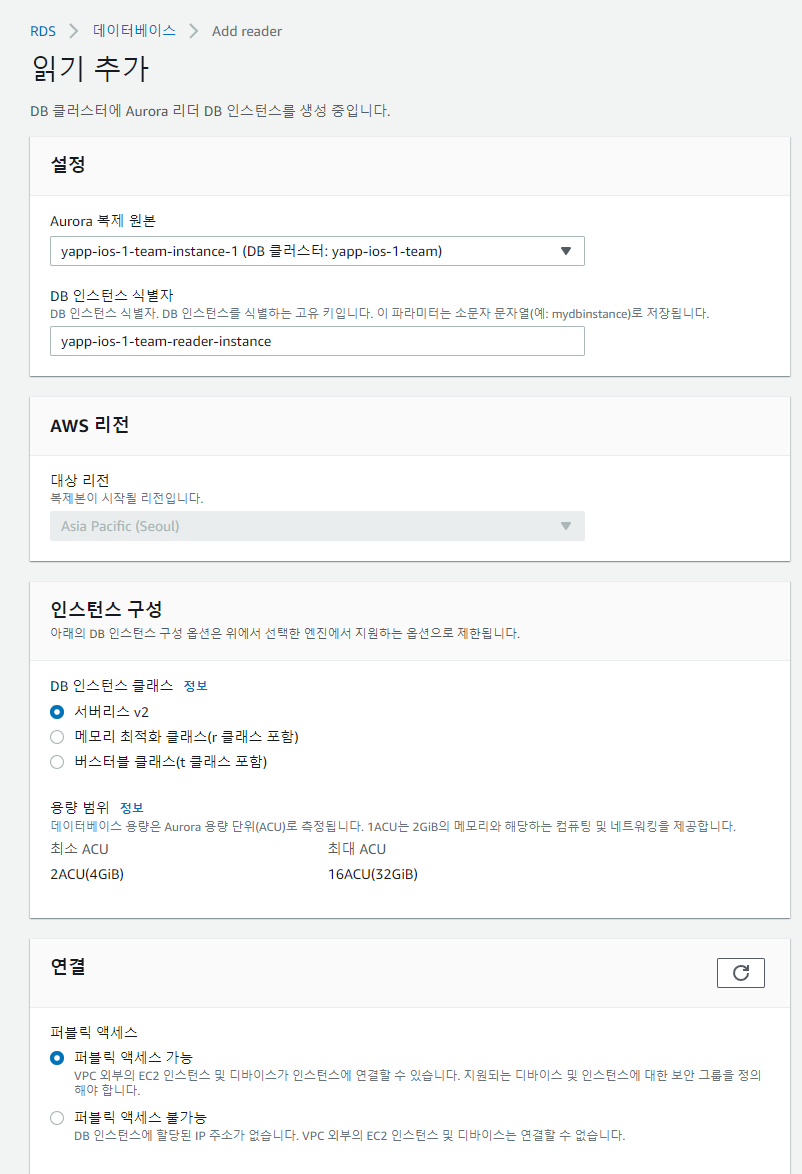
- 복제할 인스턴스를 선택, 마찬가지로 서버리스 인스턴스, 퍼블릭 액세스 설정

- 그러면 리더 인스턴스가 생긴다.
4-7. 엔드포인트

-
리전 클러스터에 들어가보면 3-3에서 이야기한 엔드포인트를 볼 수 있다.
-
리더 인스턴스가 여러개여도 하나의 엔드포인트만 연결하면, 자동으로 로드밸런싱을 수행해준다.
5. 애플리케이션 설정
5-1. application-dev.yaml
spring:
datasource:
primary:
hikari:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: ENC(k9HvXvq0ejpgRDN8hTCAbw==)
password: ENC(v4QCGkCugrZgtG5jCtpv1FeOliW7aPk7)
jdbc-url: ENC(kl+In8I7PIjG/DCtzDCoHwTqqTCUkI93MJY1KZ4pLoHMqLI2w9j6UCgbITRHPY2NnqpRwZ3tje4pHyXAQDOTuKSLOvccr8Aqi40VXsMQWud6ZgPFhThta516MbVxdVFQpF7BDnPPi0Y6/m5yKeMu9CvQxx92AYngwWBdDWTsqAolemNQv27Ol2FbIlAKgQFi)
secondary:
hikari:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: ENC(k9HvXvq0ejpgRDN8hTCAbw==)
password: ENC(v4QCGkCugrZgtG5jCtpv1FeOliW7aPk7)
jdbc-url: ENC(jn/yj4U8HpOKeZfZtrUGdseTZ3h/u9o5FTRyQ9DEqzL7hd+xWQO8UUJCwtPNlV4ka1/E5by+cwUfN8jxss+kQgDq6DYioNoSa+us5uyGe26GSzqjuIbsTCWssudhyA3QWQKHXF8+5PZAb3/+v7f7QXvzmEBoTRVv1ILpqdLe88RcvgWa7YFWeRWJCa3b6azZcnf26dtRKQM=)
hikari:
pool-name: Hikari
auto-commit: false-
hikari는 auto-commit default가 true이므로 유의하자.
-
중요 정보는 Jasypt를 통해 암호화했다.
5-2. @Transactional readOnly 옵션에 따른 커넥션 설정
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.transaction.support.TransactionSynchronizationManager;
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager.isCurrentTransactionReadOnly()
? "secondary"
: "primary";
}
}-
Spring에서는
AbstractRoutingDataSource클래스를 통해@TransactionalreadOnly 옵션에 따라 서로 다른 DB 커네션을 획득할 수 있도록 지원해준다. -
determineCurrentLookupKey메서드를 오버라이딩해서@TransactionalreadOnly 옵션이 적용된 경우, secondary 커넥션을, 아닌 경우에는 primary 커넥션을 얻도록 설정했다.
5-3. DataSource 설정
import com.zaxxer.hikari.HikariDataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.DependsOn;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.LazyConnectionDataSourceProxy;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfiguration {
public static final String PRIMARY_DATASOURCE = "primaryDataSource";
public static final String SECONDARY_DATASOURCE = "secondaryDataSource";
@Bean(PRIMARY_DATASOURCE)
@ConfigurationProperties(prefix = "spring.datasource.primary.hikari")
public DataSource primaryDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean(SECONDARY_DATASOURCE)
@ConfigurationProperties(prefix = "spring.datasource.secondary.hikari")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean
@Primary
@DependsOn({PRIMARY_DATASOURCE, SECONDARY_DATASOURCE})
public DataSource routingDataSource(@Qualifier(PRIMARY_DATASOURCE) DataSource primaryDataSource,
@Qualifier(SECONDARY_DATASOURCE) DataSource secondaryDataSource) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("primary", primaryDataSource);
dataSourceMap.put("secondary", secondaryDataSource);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(primaryDataSource);
return routingDataSource;
}
@Bean
@DependsOn("routingDataSource")
public LazyConnectionDataSourceProxy dataSource(DataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}
}-
PRIMARY_DATASOURCE,SECONDARY_DATASOURCE두 빈을 등록해준다.-
@ConfigurationProperties어노테이션을 통해 primary, secondary 설정 값들을 가져와서 빈으로 등록해준다. -
빈으로 등록하지 않고 프로퍼티 클래스를 만들어서 사용해도 된다. 자유!
-
-
RoutingDataSource빈 등록-
@Primary를 통해 직접 등록한 빈을 사용하도록 한다. -
@DependsOn을 통해PRIMARY_DATASOURCE, SECONDARY_DATASOURCE빈이 등록된 이후에 빈을 등록하도록 한다. -
1번에서 등록한 빈을 받아서, Map에 넣어준다.
- 여기서 설정하는 키가 5-2에서
@Transactional readOnly옵션에 따라 가져오는 커넥션의 키가 된다.
- 여기서 설정하는 키가 5-2에서
-
디폴트 DataSource는 primary를 세팅한다.
-
-
LazyConnectionDataSourceProxy빈 등록- 스프링은 트랜잭션을 시작하면 일단 커넥션을 획득한다. 때문에 커넥션이 필요없는 상황에서도 계속 커넥션을 가지고 있게되어, 커넥션이 부족해지는 현상이 발생할 수 있다.
LazyConnectionDataSourceProxy는 트랜잭션이 시작되도 커넥션을 획득하지 않고
실제로 커넥션이 필요할 때 커넥션을 획득한다.
6. 테스트
@Slf4j
@Service
@RequiredArgsConstructor
public class TestService {
private final DataSource dataSource;
@Transactional
public void primary() throws SQLException {
Connection connection = dataSource.getConnection();
log.info("primary url : {}", connection.getMetaData().getURL());
}
@Transactional(readOnly = true)
public void secondary() throws SQLException {
Connection connection = dataSource.getConnection();
log.info("secondary url : {}", connection.getMetaData().getURL());
}
}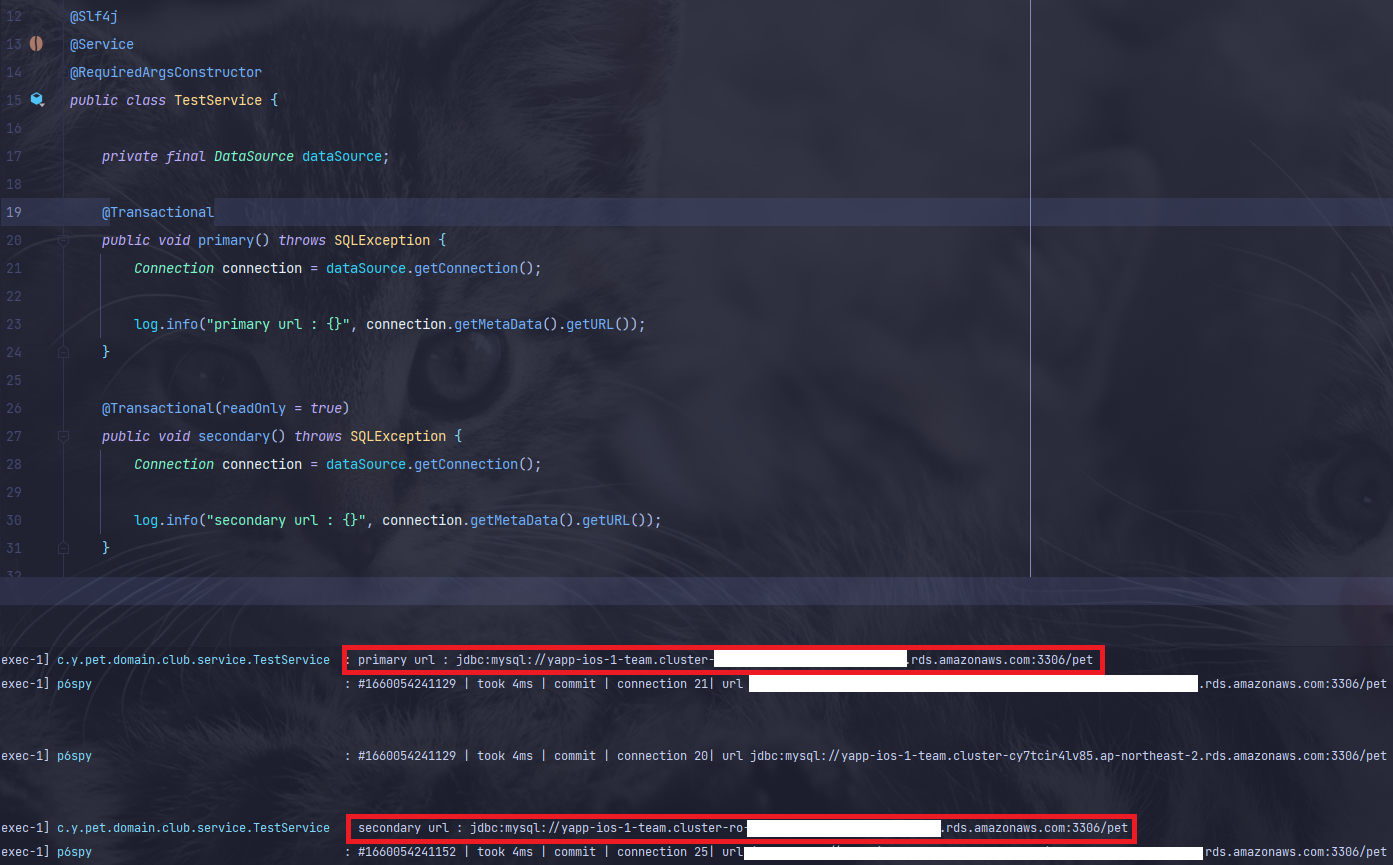
- secondary url을 보면 cluster 뒤에 ro가 붙은걸 볼 수 있다.
- 여기서 ro는 read only를 뜻한다.
@Transactional readOnly옵션에 따라 primary, secondary DB 커넥션을 가져오는걸 확인할 수 있다.
7. 마치며
대부분의 서비스는 데이터를 write하는 요청보다, read하는 요청이 더 많다. 흔한 주제인 게시판, 쇼핑몰 같은 경우를 생각하면 와닿을 것 같다.(당연히 write가 더 많은 서비스도 있을것이다.)
하나의 DB에서 모든 요청을 받는것 보다, write 요청과 read 요청이 분리된다면 당연히 더 많은 트래픽을 견딜 수 있을 것이다.
또한 데이터를 write하게 되면 조회 트랜잭션은 해당 데이터에 접근을 하지 못하게 되므로 기다려야 하는데, 이런 일이 많아질수록 조회 성능도 떨어진다. 하지만 Replication을 통해 read/write DB가 분리된다면 조회 트랜잭션이 대기할일이 없으니 성능도 향상 된다! 라고 말하려 했는데 생각해보니 Primary에 write된 데이터들이 결국 Secondary에 데이터가 동기화 되는 시점이 있을텐데 똑같은거 아닌가? 라는 생각이 들긴한다.
아무튼.. 프리티어라서 부하테스트를 못해보는점이 조금 아쉽지만 이러한 전체적인 아키텍처를 구성해봤다는 점에서 만족한다.
지난 주말에 YAPP 성과공유회를 마지막으로 공식일정이 끝났다. 남은 버그들을 처리는 계속 하겠지만 YAPP 관련된 블로깅은 이번이 마지막이 될 것 같다.
