
자료구조와 알고리즘 중에서 자주 사용되는 것들은 어떤 것이 있나요?
1. 배열(Array)
- 정해진 크기
- 입력과 삭제가 비효율적
- 무작위 접근 가능 (ex: array[4] 이런식으로)
- 메모리 낭비가 심할 수 있음
- 각 요소의 메모리 위치가 순차적으로 있어서 순차 접근이 더 빠름
2. 링크드리스트(Linked list)
- 크기가 동적임
- 입력과 삭제가 효율적
- 전체 데이터 구조를 재구성하지 않고, 노드를 링크된 목록에서 쉽게 제거하거나 추가할 수 있음.
- 무작위 접근 안됨
- 메모리 낭비 없음
- 각 요소의 메모리 위치가 순차적으로 있지 않아서 배열과 반대로 순차 접근은 느림
- 연결된 목록에서 검색 작업이 느림. 배열과 달리 데이터 요소의 임의 액세스는 허용되지 않음. 노드는 첫 번째 노드부터 순차적으로 액세스.
- 포인터의 저장 때문에 어레이보다 더 많은 메모리를 사용함.
singly(단일) linked list

- head 노드가 존재
- 각 노드는 데이터와 다음 노드에 대한 포인터를 갖고 있다.
- 일렬
doubly(이중) linked list

- head 노드가 존재
- 각 노드는 데이터와 다음, 이전 노드에 대한 포인터를 갖고 있다.
circular(환형) linked list
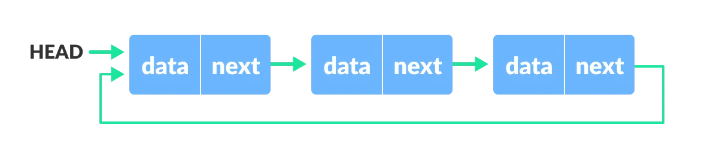
- head 노드가 존재
- 각 노드는 데이터와 다음 노드에 대한 포인터를 갖고 있다.
- 마지막 노드는 head node와 연결된다.
3. 이진트리(Binary Tree)
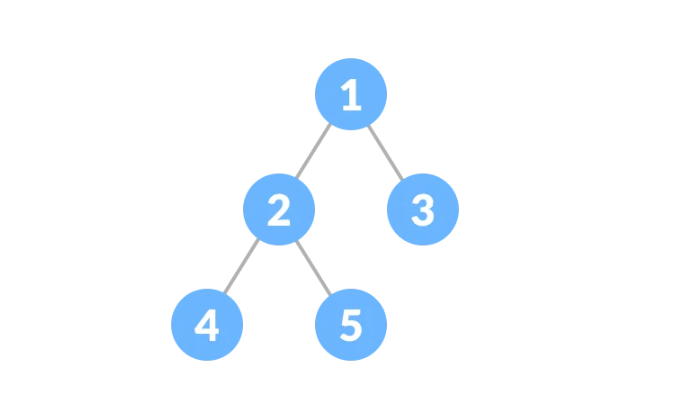
- tree structure 중에 가장 유명
- tree : 계층적 관계를 나타내는 비선형 데이터 구조
- 면접 중에 가장 많이 물어볼 유형
- root가 있으며 각 노드는 최대 2개의 자식(left, right)이 있다.
4. 스택(stack)
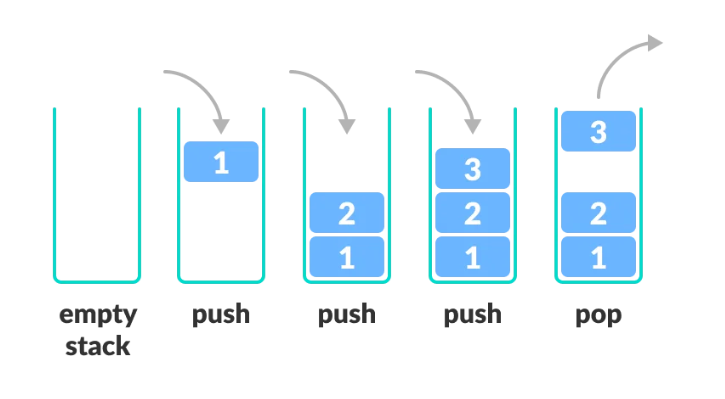
- 나중에 들어온 데이터가 가장 먼저 나가는 후입선출(LIFO) 구조
- 한쪽으로 삽입과 삭제 연산 수행
- push()를 이용한 데이터 입력, pop()을 이용한 데이터 출력
5. 큐(queue)
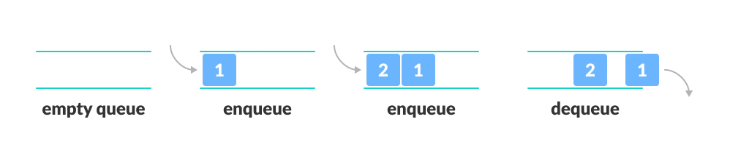
- 먼저 들어온 데이터가 가장 먼저 나가는 선입선출(FIFO) 구조
- 한쪽에서는 데이터가 들어오고
- 한쪽에서는 데이터가 삭제되는 연산을 각각 수행
데이터베이스 (Database)와 ORM(Object Relational Mapping)에 대해 설명해보세요.
데이터베이스 (DataBase, DB)
데이터의 저장소
DBMS(Database Management System)
데이터베이스를 관리하고 운영하는 소프트웨어를 DBMS
ORM(Object Relational Mapping, 객체-관계-매핑)
ORM은 객체와 데이터베이스의 관계를 매핑해주는 도구
객체지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용하기 때문에 객체 모델과 관계형 모델 간에 불일치가 존재.
따라서
ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결
즉, 객체를 통해 간접적으로 데이터 베이스 데이터를 다룬다.
Frameworks
JPA/Hibernate
JPA(Java Persistence API)는 자바의 ORM 기술 표준으로 인터페이스의 모음이다. 이러한 JPA 표준 명세를 구현한 구현체가 바로 Hibernate이다.
Sequelize
Sequelize는 Postgres, MySQL, MariaDB, SQLite 등을 지원하는 Promise에 기반한 비동기로 동작하는 Node.js ORM이다. Promise의 장점은 아래와 같다.
1) 복잡한 비동기 코드를 깔끔하고 쉽게 만들 수 있도록 한다.
2) Chaining을 통해 값을 전달하거나 연속된 일련의 작업을 처리 할 수 있다.
3) Error handling에 대한 처리를 깔끔하게 할 수 있다.
Django ORM
Python 기반 프레임워크인 Django에서 자체적으로 지원하는 ORM이다.
Prisma
Prisma의 특징은 GraphQL스키마를 기반으로 DB를 자동생성 해준다는 것이다. (*GraphQL? facebook에서 만든 Graph Query Language로 애플리케이션 Query 언어로써 기존의 REST API의 한계점을 극복하고자 나온 통신 규약으로 REST API를 대체할 수 있다.) GraphQL의 장점은 아래와 같다.
1) 요청메세지가 값이 없는 JSON과 비슷하며 받는 데이터는 JSON형태 이다.
2) 단일요청으로 원하는 데이터를 한번에 가져올 수 있다.
3) type system을 지원한다.
4) GraphiQL 등의 강력한 도구를 사용 할 수 있다.
5) 확장성이 좋다.
ORM의 장단점
장점
- 객체지향적인 코드로 인해 더 직관적이고 로직에 집중할 수 있도록 도와준다.
- SQL문이 아닌 클래스의 메서드를 통해 데이터베이스를 조작할 수 있으므로 개발자가 객체 모델만 이용해서 프로그래밍을 하는 데 집중할 수 있다.
- 선언문, 할당, 종료 같은 부수적인 코드가 없거나 줄어든다.
- 객체마다 코드를 별도로 작성하기 때문에 코드의 가독성이 높아진다.
- SQL의 절차적이고 순차적인 접근이 아닌 객체지향적인 접근으로 인해 생산성을 높여준다.
- 재사용 및 유지보수의 편리성이 증가한다.
- ORM은 독립적으로 작성되어있고, 해당 객체들을 재활용할 수 있다.
- 매핑 정보가 명확하여, ERD를 보는 것에 대한 의존도를 낮출 수 있다.
- DBMS에 대한 종속성이 줄어든다.
- 대부분 ORM 솔루션은 DB에 종속적이지 않기 때문에 구현 방법뿐만 아니라 많은 솔루션에서 자료형 타입까지 유효하다. (*종속성? 프로그램 구조가 데이터 구조에 영향을 받는다.)
- 프로그래머는 Object에 집중함으로 극단적으로 DBMS를 교체하는 거대한 작업에도 비교적 적은 리스크와 시간이 소요된다.
또한 자바에서 가공할 경우 equals, hashCode의 오버라이드 같은 자바의 기능을 이용할 수 있고, 간결하고 빠른 가공이 가능하다.
단점
- 완벽한 ORM 으로만 서비스를 구현하기가 어렵다.
- 사용하기는 편하지만 설계는 매우 신중하게 해야한다.
- 프로젝트의 복잡성이 커질경우 난이도 또한 올라갈 수 있다.
- 잘못 구현된 경우에 속도 저하 및 심각할 경우 일관성이 무너지는 문제점이 생길 수 있다.
- 일부 자주 사용되는 대형 쿼리는 속도를 위해 SP를 쓰는등 별도의 튜닝이 필요한 경우가 있다.
- DBMS의 고유 기능을 이용하기 어렵다. (하지만 이건 단점으로만 볼 수 없다 : 특정 DBMS의 고유기능을 이용하면 이식성이 저하된다.)
- 프로시저가 많은 시스템에선 ORM의 객체 지향적인 장점을 활용하기 어렵다.
- 이미 프로시저가 많은 시스템에선 다시 객체로 바꿔야하며, 그 과정에서 생산성 저하나 리스크가 많이 발생할 수 있다.
