
📌SQL 단일행 함수
💡문자 함수
| 함수명 | 의미 | 사용 예 |
|---|---|---|
| INITCAP | 입력 값의 첫 글자만 대문자로 변환 | INITCAP('abcd') -> Abcd |
| LOWER | 입력 값을 전부 소문자로 변환 | LOWER('ABCD') -> abcd |
| UPPER | 입력 값을 전부 대문자로 변환 | UPPER('abcd') -> ABCD |
| LENGTH | 입력된 문자열의 길이 값을 출력 | LENGTH('한글') -> 2 |
| LENGTHB | 입력된 문자열의 길이의 바이트 값을 출력 | LENGTH('한글') -> 4 |
| CONCAT | 두 문자열을 결합해서 출력. || 연산자와 동일 | CONCAT('A','B') -> AB |
| SUBSTR | 주어진 문자에서 특정 문자만 추출 | SUBSTR('ABC',1,2) -> AB |
| SUBSTRB | 주어진 문자에서 특정 바이트만 추출 | SUBSTRB('한글',1,2) -> 한 |
| INSTR | 주어진 문자에서 특정 문자의 위치 추출 | INSTR('A*B#','#') -> 4 |
| INSTRB | 주어진 문자에서 특정 문자의 위치 바이트값 추출 | INSTRB(‘한글로’,’로’) -> 5 |
| LPAD | 주어진 문자열에서 왼쪽으로 특정 문자를 채움 | LPAD(‘love’,6,’*’) -> **love |
| RPAD | 주어진 문자열에서 오른쪽으로 특정 문자를 채움 | RPAD(‘love,’6,’*’) -> love** |
| LTRIM | 주어진 문자열에서 왼쪽의 특정 문자를 삭제 | LTRIM(‘*love’,’*’) -> love |
| RTRIM | 주어진 문자열에서 오른쪽의 특정 문자를 삭제 | RTRIM(‘love*’,’*’) -> love |
| REPLACE | 주어진 문자열에서 A를 B로 치환 | REPLACE(‘AB’,’A’,’E’) -> EB |
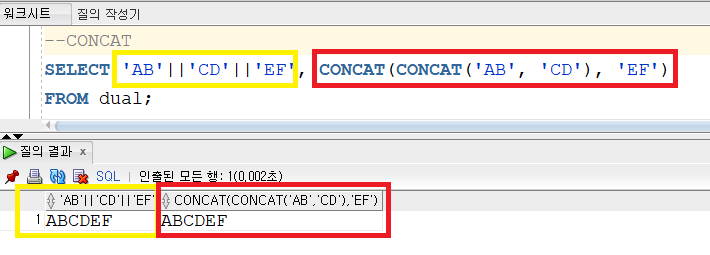
▼CONCAT
CONCAT은 두 문자열을 합치는 기능이다. 두 가지 이상의 문자열을 결합하기 위해선 CONCAT을 중첩해서 사용할 수 있다. ( ||로 더 쉽게 작성할 순 있음 )
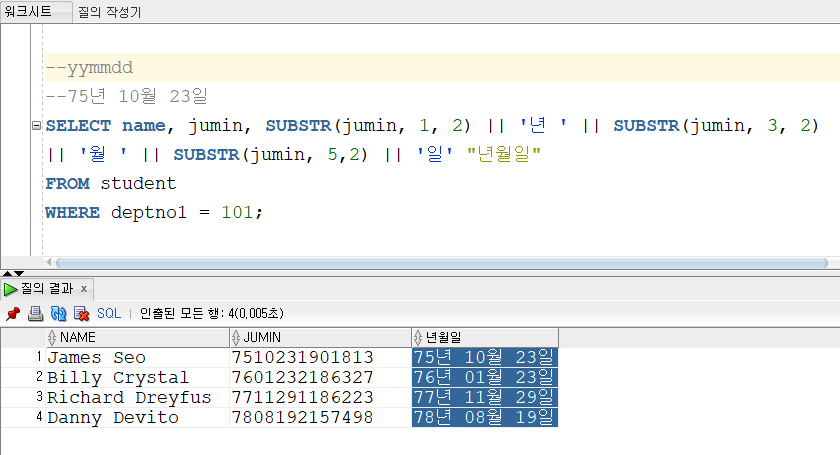
▼SUBSTR
SUBSTR('문자열' or 컬럼명, 시작위치숫자, 개수)
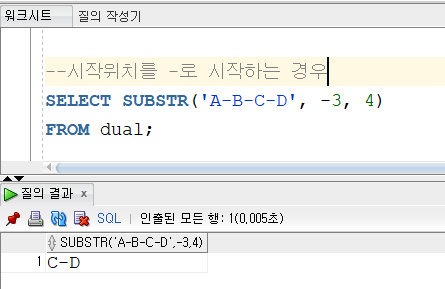
시작위치를 -(마이너스)로 하게되면 자릿수를 뒤에서부터 계산한다.
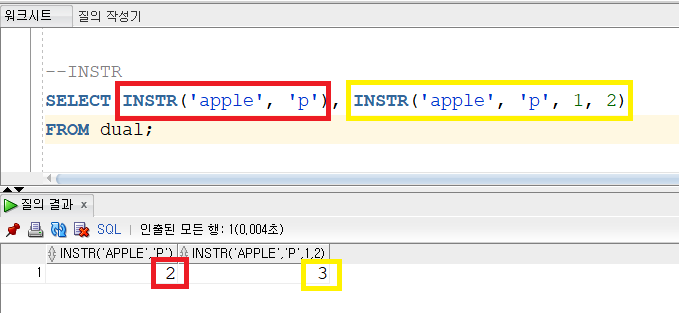
▼INSTR
INSTR('문자열' or 컬럼명, 찾는글자, 시작위치, 몇번째인지(기본값은 1))
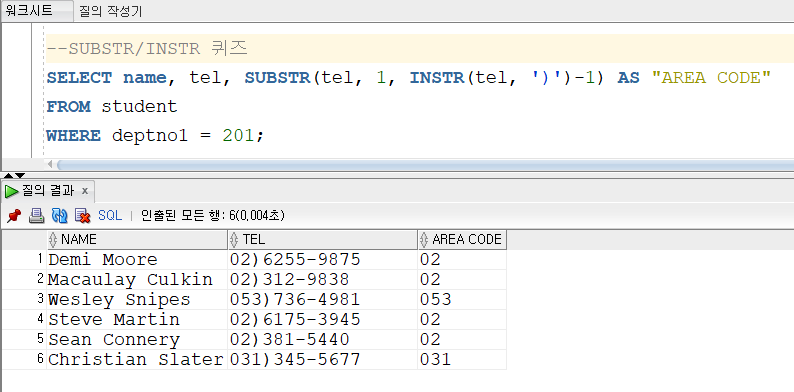
Q. SUBSTR / INSTR 퀴즈
Student 테이블을 참조해서 아래 화면과 같이 1 전공이(deptno1 컬럼) 201번인 학생의 이름과 전화번호와 지역번호를 출력하세요.
단 지역번호는 숫자만 나와야 합니다.
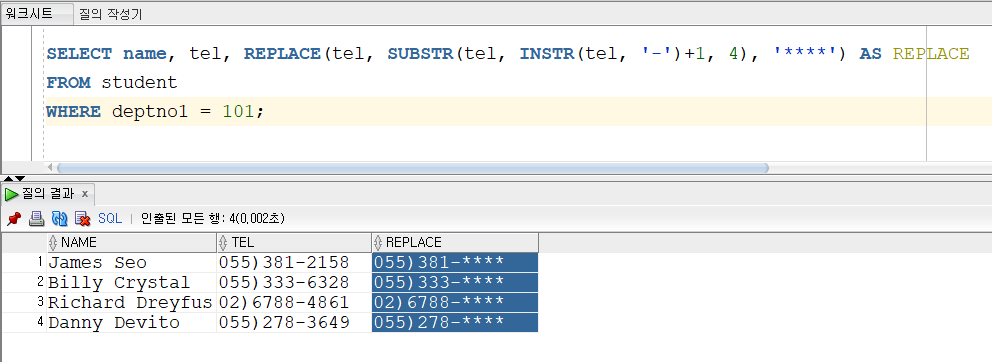
▼REPLACE
REPLACE('문자열' or 컬럼명, '문자1', '문자2')
💡숫자 함수
| 이름 | 의미 | 사용 예 |
|---|---|---|
| ROUND | 주어진 숫자를 반올림 한 후 출력 | ROUND(12.345, 2) -> 12.35 |
| TRUNC | 주어진 숫자를 버림 한 후 출력 | TRUNC(12.345, 2) -> 12.34 |
| MOD | 주어진 숫자를 나누기 한 후 나머지 값 출력 | MOD(12, 10) -> 2 |
| CEIL | 주어진 숫자와 가장 근접한 큰 정수 출력 | CEIL(12.345) -> 13 |
| FLOOR | 주어진 숫자와 가장 근접한 작은 정수 출력 | FLOOR(12.345) -> 12 |
| POWER | 주어진 숫자1의 숫자2승을 출력 | POWER(3, 2) -> 9 |
💡날짜 함수
| 함수명 | 의미 | 결과 |
|---|---|---|
| SYSDATE | 시스템의 현재 날짜와 시간 | 날짜 |
| MONTHS_BETWEEN | 두 날짜 사이의 개월 수 | 숫자 |
| ADD_MONTHS | 주어진 날짜에 개월을 더함 | 날짜 |
| NEXT_DAY | 주어진 날짜를 기준으로 돌아오는 날짜 출력 | 날짜 |
| LAST_DAY | 주어진 날짜가 속한 다르이 마지막 날짜 출력 | 날짜 |
| ROUND | 주어진 날짜를 반올림 | 날짜 |
| TRUNC | 주어진 날짜를 버림 | 날짜 |
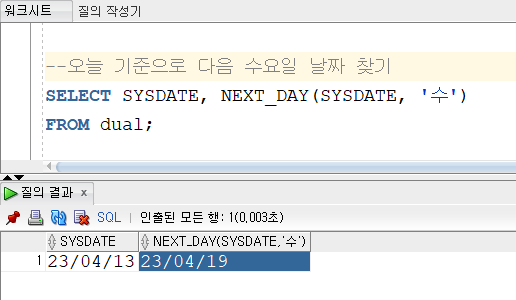
▼NEXT_DAY
▼연습하기
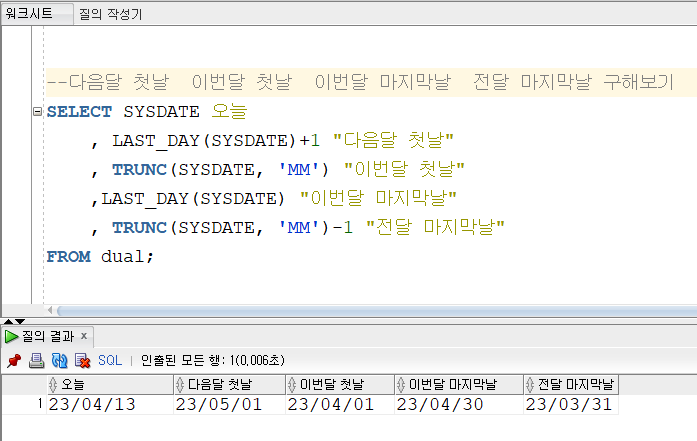
- TRUNC(SYSDATE, 'MM') : 월을 기준으로 주어진 날짜를 버린다. -> 이번 달의 첫날을 조회할 수 있다.
- TRUNC(SYSDATE, 'MM')-1 : 이번 달 첫날에서 -1을 한다. -> 저번달의 마지막날을 조회할 수 있다.
💡변환 함수
| 데이터 타입 | 설명 | ※ |
|---|---|---|
| VARCHAR2(n) | 변하는 길이의 문자를 저장. 최대값은 4000bytes | 문자 |
| NUMBER(p,s) | 숫자 값을 저장. p는 전체 자리수로 1-38자리까지 가능. s는 소수점 이하 자리수로 -84 ~ 127 자리까지 가능 | 숫자 |
| DATE | 총 7Byte로 BC 4712년 1월 1일부터 AD 9999년 12월 31일까지의 날짜 저장 가능 | 날짜 |
참고) CHAR와 VARCHAR2
| 타입 | CHAR | VARCHAR2 |
|---|---|---|
| 고정 | 가변 | |
| 예 | CHAR(13) | VARCHAR2(13) |
| 1234567891234(13자리 차지) | 1234567891234(13자리 차지) | |
| 123 (13자리 차지) | 123(3자리 차지) |
묵시적 데이터형 변환
자동 형 변환으로 숫자처럼 생긴 문자만 변환이 가능하다.
명시적 데이터형 변환
- TO_CHAR : 문자로 변환
날짜 -> 문자 :TO_CHAR(원래날짜, '원하는 모양')
숫자 -> 문자 :
| 종류 | 의미 | 사용 예 | 결과 |
|---|---|---|---|
| 9 | 9의 개수만큼 자리수 | TO_CHAR(1234, '99999') | 1234 |
| 0 | 빈자리를 0으로 채움 | TO_CHAR(1234, '099999') | 001234 |
| $ | $ 표시를 붙여서 표시 | TO_CHAR(1234, '$9999') | $1234 |
| . | 소수점 이하를 표시 | TO_CHAR(1234, '9999.99') | 1234.00 |
| , | 천 단위 구분기호를 표시 | TO_CHAR(12345, '99,999') | 12,345 |
TO_CHAR의 날짜 형태
<년도>
▷'YYYY' : 연도를 4자리로 표현
▷'RRRR' : 2000년 이후에 Y2K 버그로 인해 등장한 날짜 표기법. 연도 4자리 표기
▷'YY' : 연도를 끝의 2자리만 표시
▷'RR' : 연도를 끝의 2자리만 표시
▷'YEAR' : 연도의 영문 이름 전체를 표시
<월>
▷MM : 월의 숫자 2자리로 표현
▷MON : 유닉스용 오라클에서 월을 뜻하는 영어 3글자
▷MONTH : 월을 뜻하는 이름 전체를 표시
<일>
▷DD : 일을 숫자 2자리로 표시
▷DAY : 요일에 해당하는 명칭을 표시(윈도우-한글/유닉스-영어)
▷DDTH : 몇 번째 날인지 표시
<시간>
HH24 : 하루를 24시간으로 표시
HH : 하루를 12시간으로 표시
MI : 분(Minite)
SS : 초(Second)
-
TO_NUMBER : 숫자로 변환
TO_NUMBER('숫자처럼 생긴 문자') -
TO_DATE : 날짜로 변환
TO_DATE('문자')
💡일반 함수
① NVL() 함수 : NULL 값을 만나면 다른 값으로 치환해서 출력하는 함수이다.
NVL(컬럼, 치환할 값)
② NVL2() 함수 : NULL 값이 아닌 값을 다른 값으로 치환해서 출력하는 함수이다.
NVL2(컬럼, 지정값1, 지정값2)
③ DECODE() 함수 : IF문을 오라클 안으로 가져온 함수로 오라클에서만 사용되는 함수이다.
DECODE(A, B, '1', null)
-> A가 B일 경우 '1'을 출력, 아닐 경우 null
-> 마지막 null은 생략 가능
-> 조건은 여러개 혹은 중첩도 가능하다.
④ CASE문
CASE 조건 WHEN 결과1 THEN 출력1
[WHEN 결과2 THEN 출력2]
ELSE 출력3
END "컬럼명"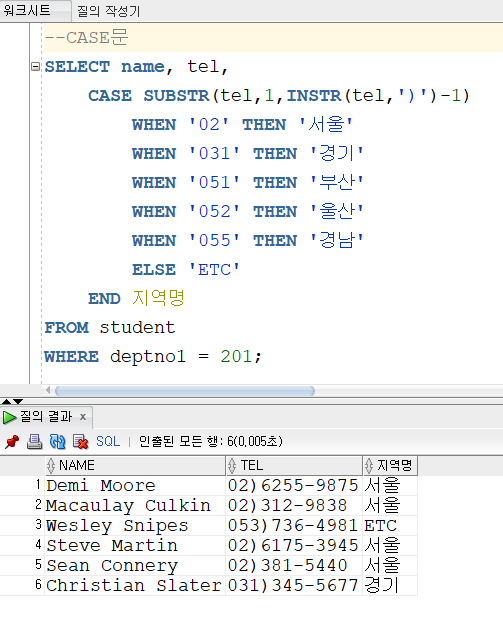
-> CASE문은 안의 내용을 작성 후 END를 꼭 붙여주어야 한다.
⑤ 정규식(Regular Expression) 함수로 다양한 조건 조회
| 사용기호 | 의미 | 사용 예 |
|---|---|---|
| ^(캐럿) | 해당 문자로 시작하는 line 출력 | '^pattern' |
| $(달러) | 해당 문자로 끝나는 line 출력 | 'pattern$' |
| . | S로 시작하여 E으로 끝나는 line (. -> 1 character) | 'S....E' |
| * | 모든 이라는 뜻. 글자수가 0일 수도 있음 | '[a-z]*' |
| [] | 해당 문자에 해당하는 한 문자 | '[Pp]attern' |
| [^] | 해당 문자에 해당하지 않는 한 문자 | '[^a-m]attern' |
1) REGEXP_LIKE 함수 : 단순히 문자열이 포함되어 있는지를 비교하는 LIKE를 넘어 정규식을 비교하여 일치할 경우 추출해주는 함수
2) REGEXP_REPLACE 함수 : 정규식 패턴을 검색하여 대체 문자열로 변경
3) REGEXP_SUBSTR 함수 : 지정된 문자열 내에서 정규식 패턴을 검색하고 일지하는 부분 문자열을 추출
4) REGEXP_COUNT 함수 : 입력 문자열에서 패턴 일치가 발견되는 횟수를 반환
※ 특수 문자 찾기
정규식 함수를 이용해 특수 문자를 찾을 때 ?(물음표), *(별표), .(점) 등은 메타 캐릭터이기 때문에 사용에 주의해야 한다.
예를 들어

위의 ip 주소에서 .(점)을 /(슬래시)로 바꾸고자 할때
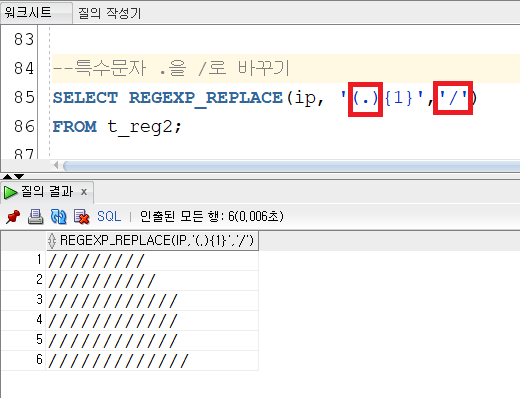
.은 메타 캐릭터로 모든 단일 문자를 검색하기 때문에 다 /(슬래시)로 바뀌고 만다. 이런 경우엔 메타 캐릭터 앞에 역슬래시를 넣어 사용할 수 있다.
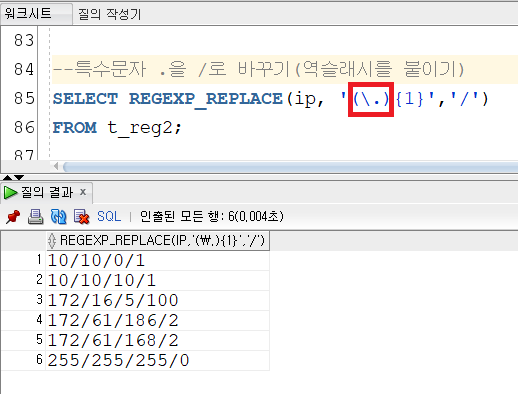
-> 원하는 대로 .(점)만 /(슬래시)로 바뀌었다.
