
📌복수행 함수
💡GROUP 함수
| 함수이름 | 의미 |
|---|---|
| COUNT | 입력되는 데이터들의 총 건수를 출력 |
| SUM | 입력되는 데이터들의 합계값 구해서 출력 |
| AVG | 입력되는 데이터들의 평균값 구해서 출력 |
| MAX | 입력되는 데이터들 중 가장 큰 값을 출력 |
| MIN | 입력되는 데이터들 중 가장 작은 값을 출력 |
| STDDEV | 입력되는 데이터 값들의 표준 편차 값 출력 |
| VARIANCE | 입력되는 데이터 값들의 분산 값 출력 |
| ROLLUP | 입력되는 데이터들의 소계값을 자동으로 계산해서 출력 |
| CUBE | 입력되는 데이터들의 소계 및 전체 총계를 자동 계산 후 출력 |
| GROUPINGSET | 한 번의 쿼리로 여러 개의 함수들을 그룹으로 수행 가능 |
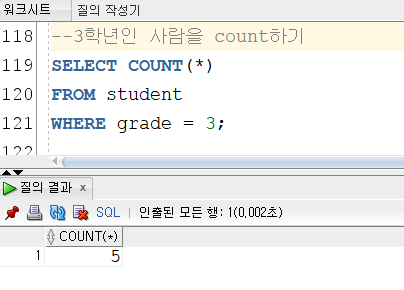
▼COUNT 함수의 사용
▼GROUP 함수의 사용

▼GROUP 함수의 잘못된 사용
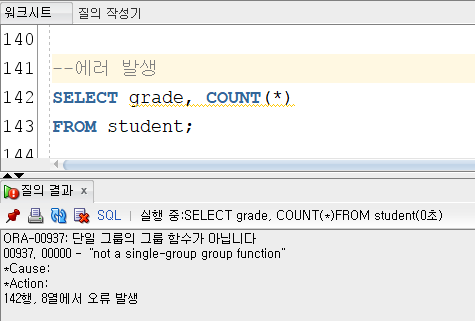
-> ORA-00937:단일 그룹의 그룹 함수가 아닙니다.
그룹함수를 사용하였는데 GROUP BY절을 사용하지 않아 발생한 오류! GROUP BY절만 추가해주면 해결되는 부분이다.
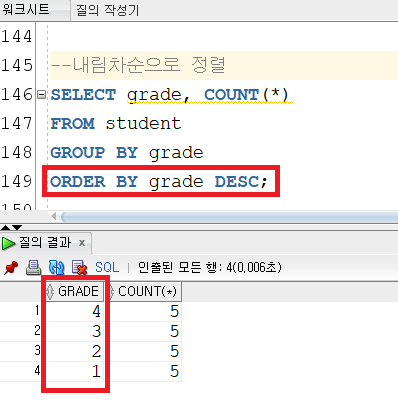
▼GROUP BY절 작성

-> 정상적으로 잘 집계되었지만 GRADE 컬럼이 정렬되지 않은게 신경쓰인다.
▼ORDER BY절로 정렬
※GROUP BY절 사용 시 주의사항!
GROUP BY절에는 반드시 컬럼명이 사용되어야 하며 별칭을 사용하면 안 된다.
▼HAVING절 사용
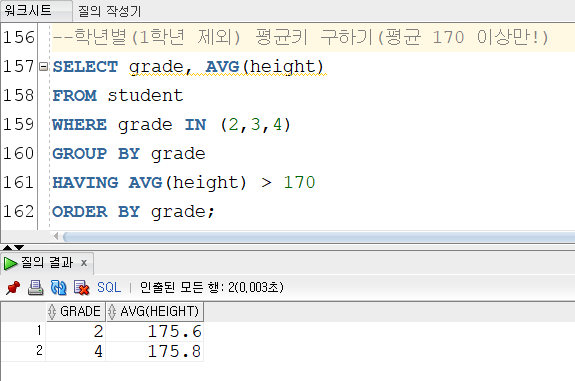
-> 그룹핑한 결과에 조건을 주기 위해 HAVING절을 사용하여 조회할 수 있다.
▼ROLLUP() 함수
ROLLUP() 함수는 소그룹 간의 합계를 계산하는 함수로, 순서를 주의해서 사용해야 한다.
GROUP BY ROLLUP(컬럼1, 컬럼2);
-> 1. 컬럼1 그룹 집계
-> 2. 컬럼1, 컬럼2 그룹 집계
-> 3. 전체 그룹 집계
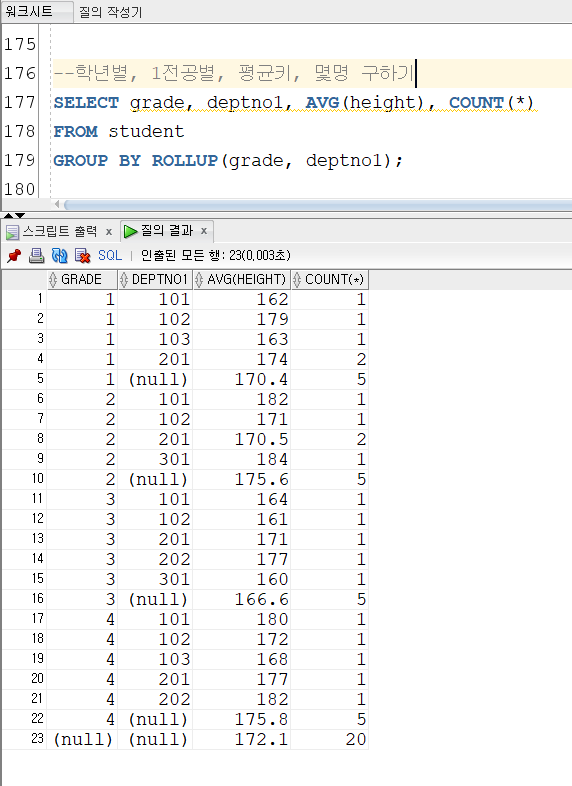
> grade 집계
> grade, deptno1 집계
> 전체 집계
▼CUBE() 함수
CUBE() 함수는 소계와 전체 합계까지 출력하는 함수로, ROLLUP과 달리 GROUP BY절에 명시한 모든 컬럼에 대해 소그룹 합계를 계산해준다.
▼GROUPING SETS() 함수
GROUPING SETS() 함수는 특정 항목에 대한 소계를 계산하는 함수로 앞서 나온 ROLLUP, CUBE과 달리 각 소그룹별 합계만 간단히 보여준다.
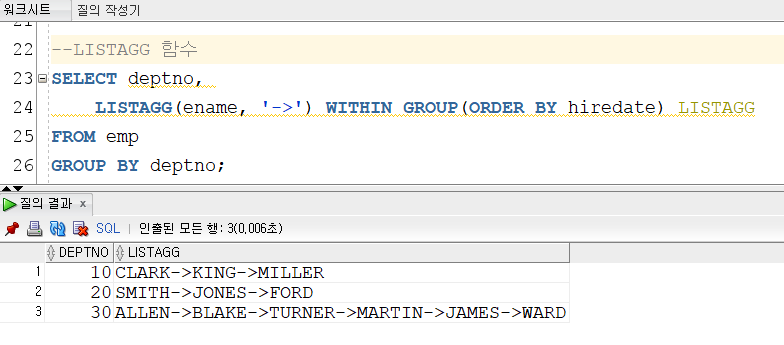
▼LISTAGG() 함수
LISTAGG() 함수는 여러 개의 열로 된 값을 한 행의 값으로 가져와야 할 때 사용한다.
▼LAG 함수(& LEAD 함수)
LAG(출력할 컬럼명, OFFSET, 기본 출력값) OVER (Query_Partition 구문, ORDER BY 정렬할 컬럼)
이전 행의 값을 찾을 때 LAG 함수를, 다음 행의 값을 찾을 때 LEAD 함수를 사용한다.
▼RANK 함수
순위 출력 함수로 특정 데이터의 순위를 확인할 때 사용한다. 중복 값들에 대해 동일 순위로 표시하고, 중복 순위 다음 값에 대해서는 중복 개수만큼 떨어진 순위로 출력하는 함수이다.
RANK(조건값) WITHIN GROUP (ORDER BY 조건값 컬럼명 [ASC|DESC])
이 때 RANK 뒤에 나오는 데이터와 ORDER BY 뒤에 나오는 데이터는 값은 컬럼이어야 한다. 전체 순위를 확인할 때는 RANK() 뒤가 WITHIN GROUP이 아닌 OVER를 사용하면 된다.
RANK(조건값) OVER (ORDER BY 조건값 컬럼명 [ASC|DESC])
▼DENSE_RANK 순위 함수
DENSE_RANK도 RANK와 마찬가지로 중복 값들에 대해선 동일 순위로 표시하지만, 중복 순위 다음 값에 대해서는 중복 값 개수와 상관없이 순차적인 순위 값을 출력한다.
▼ROW_NUMBER() 순위 함수
ROW_NUMBER는 중복 값들에 대해서도 순차적인 순위를 표시하도록 출력하는 함수이다.
