목적: 객체를 관계형 데이터베이스에 저장해야 함
- 기존에는 개발자가 SQL 매핑을 진행해야 했음
- 객체와 RDB 간의 패러다임 불일치
객체와 관계형 데이터베이스의 차이
- 상속
- 연관관계
- 데이터 타입
- 데이터 식별 방법
상속
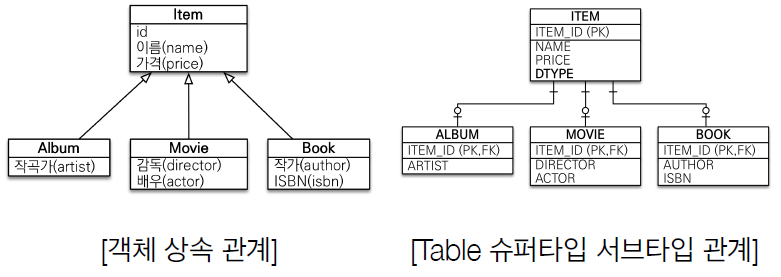
객체 상속 관계를 테이블에서 슈퍼타입 서브타입 관계로 풀어낼 때, 각각의 테이블에 따른 조인 SQL 작성, 각각의 객체 생성 등 매우 복잡함
연관관계
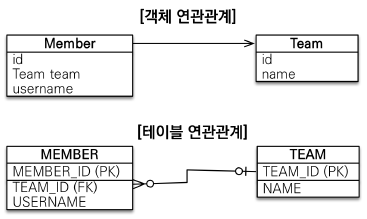
- 객체는 참조를 사용 -> member.getTeam()
- 테이블은 외래 키를 사용 -> JOIN ON M.TEAM_ID = T.TEAM.ID
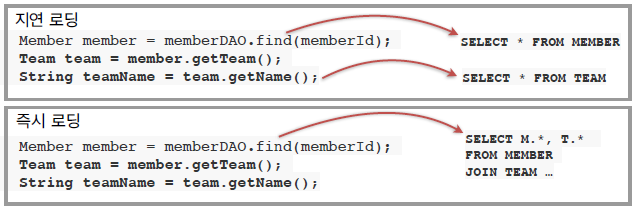
객체 그래프 탐색
- 객체는 자유롭게 객체 그래프를 탐색할 수 있어야 함
- RDB는 처음 실행하는 SQL에 따라서 탐색 범위가 결정됨
(TEAM은 조인했으나 ORDER는 조인하지 않았따면 member.getOrder() -> NULL) - 따라서 서비스 로직을 짤 때 이러한 문제로 DAO 코드를 살펴봐야 함 (엔티티 신뢰 문제)
- DAO를 작성하는 개발자 입장에서도 성능 문제로 모든 객체를 미리 로딩할 수는 없음
- 진정한 의미의 계층 분할이 어려움
객체답게 모델링 할수록 매핑 작업만 늘어남
객체를 자바 컬렉션에 저장하듯이 DB에 저장할 수 없을까? -> JPA
- 객체는 객체대로 설계
- RDB는 RDB대로 설계
- ORM 프레임워크가 중간에서 매핑
- 대중적인 언어에는 대부분 ORM 기술이 존재
JPA (Java Persistence API)
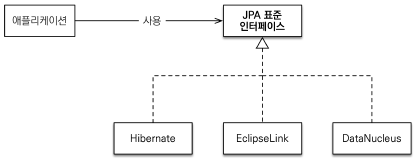
- 자바 ORM 표준 (명세) (Object-Relational Mapping: 객체 관계 매핑)
- 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스 모음
- 실제로 구현된것이 아니라 구현된 클래스와 매핑을 해주기 위해 사용되는 프레임워크
- JPA를 구현한 대표적인 구현체로는 Hibernate가 있음
저장: 객체를 DAO에 넘기고 DAO가 JPA에게 엔티티를 저장하라고 하면
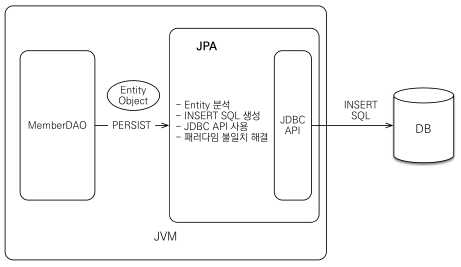
- Entity 분석
- INSERT SQL 생성
- JDBC API 사용
- 패러다임 불일치 해결
조회: JPA에게 ID만 넘기면
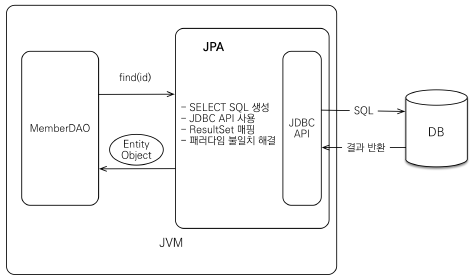
- SEELCT SQL 생성
- JDBC API 사용
- ResultSet 매핑
- 패러다임 불일치 해결 (상속 등)
JPA를 사용해야하는 이유
- SQL 중심적인 개발에서 객체 중심적인 개발이 가능 (자바 컬렉션을 다루듯이)
- 생산성
- 유지보수
- 패러다임 불일치 해결
- 성능
생산성
저장: jpa.persist(member)
조회: Member member = jpa.find(memberId)
수정: member.setName(“변경할 이름”)
삭제: jpa.remove(member)
유지보수
기존: 필드 변경 시 모든 SQL 수정
JPA: 필드만 추가하면 됨 (SQL은 JPA가 처리)
패러다임 불일치 해결
- 상속 (JPA가 알아서 INSERT, JOIN 등 진행해줌)
- 연관관계, 객체 그래프 탐색 (신뢰할 수 잇는 엔티티, 계층)
- 비교하기 (동일한 트랙잭션에서 조회한 엔티티는 같음을 보장)
JPA의 성능 최적화 기능
- 1차 캐시와 동일성(identity) 보장: 같은 트랙잭션 안에서는 같은 엔티티를 반환 (약간의 조회 성능 향상)
- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
- 트랜잭션을 커밋할 때 까지 INSERT SQL을 모음
- JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
- 지연 로딩(Lazy Loading)