
들어가며
이번 포스팅에서는 저희 회사에서 아주 잘 사용하고 있는 AWS Aurora를 이해하기 위한 첫번째 포스팅 입니다.
우선 AWS Aurora는 분산처리를 위한 DB로 이를 이해하기 위해선 Replication에 대한 이해가 기초라고 생각했기 때문에 첫 번째 포스팅은 Replication을 이해하는 것으로 시작하겠습니다.
해당 글은 MySQL을 기준으로 합니다.
Replication이란?
'두 개 이상의 DBMS 이용하여 Master/Slave (수직적)구조를 활용하여 DB의 부하를 분산 시키는 기술 입니다.'
Replication의 정의만 들어도 Replication 기술이 왜 탄생 했는지 알 수 있습니다. 서비스 사용자가 많아진다면 당연히 DB의 부하는 엄청나게 커질 것 입니다. 이렇게되면 Dead Lock이 발생할 확률이 높아지게 되며 이는 성능저하에 큰 기여를 할 것입니다.
How
어떻게 Replication 방식은 과부하 문제를 해결할까 해답은 Replication 구성을 보면 알 수 있습니다.
.png)
<이미지 출처: https://nesoy.github.io/articles/2018-02/Database-Replication>
Replication은 Master DB에는 Insert, Update, Delete 작업을 수행하도록 하고 Select 작업을 Slave DB에서 하도록 구성을 합니다.
그렇다면 왜 Select 작업을 따로 뺄까요?? 보통 select 작업이 시간이 많이 걸리기 때문 입니다. 데이터가 5만개가 있는데 Table Full Scan을 해야 하거나 한다면 시간을 엄청나게 잡아 먹을 것 입니다. 그리고 이 시간동안 다른 작업을 하지 못하게 되니 병목 현상의 주요 원인이라고 할 수 있습니다.
MySQL은 Replication을 '바이너리 로그'를 통하여 Replication이 이루어지는데 이 바이너리 로그가 무엇인지 알아보겠습니다.
바이너리 로그 기반 복제 (Binary Log)
Slave에 데이터를 복제할 때 로그기반으로 복제가 되며 MySQL이 제공하는 바이너리 로그에는 3가지 종류가 있는데 해당 글은 Replication에 대한 글이기 때문에 어떤 종류가 있는지는 넘어가도록 하겠습니다.
(궁금하신 분은 이 부분에 대해서 잘 정리 해주신 좋은 블로그가 있어 '링크'를 참고 해주세요)
바이너리 로그란
MySQL 서버에서 Create, Alter, Drop과 같은 작업을 수행하면 MySQL은 그 변화된 이벤트를 기록하는데 이러한 변경사항들에 대한 정보를 담고 있는 이진 파일을 바이너리 로그 파일 이라고 합니다.
이때 show나 select와 같은 조회 문법은 제외 됩니다.
Replication 동작 원리
MySQL의 Replication은 기본적으로 비동기 복제 방식을 사용하고 있습니다. Master 노드에서 변경되는 데이터에 대한 이력을 로그에 기록하면 Relication Master Thread가 비동기적으로 이를 읽어서 Slave쪽으로 전송합니다.
Replication 순서도
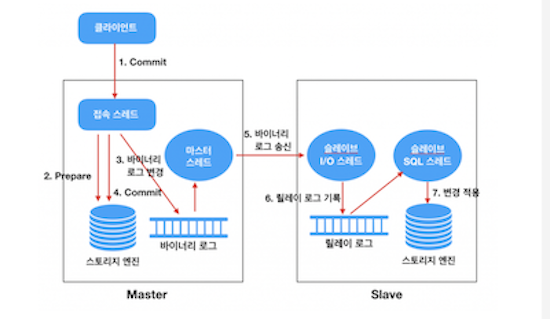
<이미지 출처: http://cloudrain21.com/mysql-replication>
순서
- Commit 발생
- Connection Thread에서 스토리지 엔진에게 해당 트랜잭션에 대한 Prepare(Commit 준비)를 수행
- Commit을 수행하기 전에 먼저 Binary Log에 변경사항을 기록
- 스토리지 엔진에게 트랜잭션 Commit을 수행하도록 한다.
- Master Thread는 시간에 구애받지 않고 (비동기적으로) Binary Log를 읽어서 Slave로 전송
- Slave의 I/O Thread는 Master로부터 수신산 변경 데이터를 Relay Log에 기록
- Slave의 SQL Thread는 Relay Log에 기록된 변경 데이터를 읽어서 Slave의 스토리지 엔진에 적용
각 스레드별 자세한 내용은 '여기'를 참고하세요
Replication의 장점
- select 성능 향상
- 대게 read 작업은 자원을 많이 소비 합니다. Replication을 구성하면 N개의 Slave를 가질 수 있기 때문에 Read에 대한 부하가 그만큼 분산 됩니다.
- 대게 read 작업은 자원을 많이 소비 합니다. Replication을 구성하면 N개의 Slave를 가질 수 있기 때문에 Read에 대한 부하가 그만큼 분산 됩니다.
- 데이터 백업
- Master의 내용을 복제하기 때문에 데이터 베이스를 지워 먹는다고 하더라도 Slave 중 하나를 Master로 활용하면 되기 때문에 데이터를 백업하는 용도로도 사용할 수 있습니다.
Replication의 단점
- 데이터 정합성을 보장할 수 없음
- Slave는 Master의 복사본을 사용하기 때문에 그것이 정말 완벽하고 할 수없습니다. 예를 들어 Slave가 Master의 쿼리 처리량을 따라가지 못한다면 데이터 정합성이 보장되지 않습니다.
- Slave는 Master의 복사본을 사용하기 때문에 그것이 정말 완벽하고 할 수없습니다. 예를 들어 Slave가 Master의 쿼리 처리량을 따라가지 못한다면 데이터 정합성이 보장되지 않습니다.
- Binary Log File 관리
- Master는 Binary Log가 무분별하게 쌓이는 것을 막기위해 데이터 보관 주기를 설정하지만 Master는 Slave까지 관리 않기 때문에 Master에서 Binary Log File을 삭제 했다고 Slave에서 Binary Log를 삭제하지 못합니다.
- Master는 Binary Log가 무분별하게 쌓이는 것을 막기위해 데이터 보관 주기를 설정하지만 Master는 Slave까지 관리 않기 때문에 Master에서 Binary Log File을 삭제 했다고 Slave에서 Binary Log를 삭제하지 못합니다.
- Fail Over 불가
- master에서 Error가 발생 했을 경우 Slave로 Failover하는 기능을 지원하지 않습니다. Slave 역시 Master와 Log 위치가 다르다면 관리자가 작업을 해야 합니다.
정리
-
DB는 기본적으로 Read 작업에서 자원 소모가 많기 때문에 Read작업이 많아 성능 이슈가 발생한다면 경우 가장 먼저 고려해볼 전략 입니다.
-
Replication 적용 하여도 성능 향상을 체감 할 수 있습니다. 하지만 단점 또한 치명적이기 때문에 만능이라고 할 수는 없습니다.
다음에는'Clustering' 에 대해서 알아볼 예정 입니다. Clustering은 데이터 동기화를 진행하기 때문에 일관성을 보장하고 Fail Over를 지원하기 때문에 고가용성이 보장됩니다.
따라서 현재 수많은 기업에서 도입하고 있으며 분산처리에서 핵심 포인트로 자리 잡았습니다. 자세한 내용은 다음 포스팅에서 다루기로 하겠습니다.
감사합니다.
Ref
