
🔴 문제 개요
🚀 난이도 : GOLD 4
세로 칸, 가로 칸으로 된 표 모양의 보드가 있다. 보드의 각 칸에는 대문자 알파벳이 하나씩 적혀 있고, 좌측 상단 칸 (행 열) 에는 말이 놓여 있다.
말은 상하좌우로 인접한 네 칸 중의 한 칸으로 이동할 수 있는데, 새로 이동한 칸에 적혀 있는 알파벳은 지금까지 지나온 모든 칸에 적혀 있는 알파벳과는 달라야 한다. 즉, 같은 알파벳이 적힌 칸을 두 번 지날 수 없다.
좌측 상단에서 시작해서, 말이 최대한 몇 칸을 지날 수 있는지를 구하는 프로그램을 작성하시오. 말이 지나는 칸은 좌측 상단의 칸도 포함된다.
제한사항
첫째 줄에 과 가 빈칸을 사이에 두고 주어진다. () 둘째 줄부터 개의 줄에 걸쳐서 보드에 적혀 있는 개의 대문자 알파벳들이 빈칸 없이 주어진다.
🟠 Solution
📍 시행착오
단순 그래프 탐색, 백트래킹으로 풀이할 수 있어 보입니다. 입력 받은 보드에 (0, 0) 좌표부터 알파벳을 기록하고, 상, 하, 좌, 우 탐색을 하며 새로운 알파벳이 지금까지 기록된 알파벳에 없는 경우만 계속 진행 하는 방식으로 구현할 수 있겠네요. 즉, 이미 포함된 알파벳이 아닌 경우는 가지치기 해버리는 백트래킹 개념입니다.
def dfs(points: Tuple[int], alpha: str, depth: int) -> None:
"""
points에서 중복되지 않는 알파벳을 가진 상하좌우 칸으로 재귀한다.
max depth를 global 변수 answer에 저장한다.
"""
global answer
if answer < depth:
answer = depth
y, x = points
for d in range(4):
ny = y + dy[d]
nx = x + dx[d]
# 다음 조건을 만족하는 경우만 재귀(백트래킹)
if (
0 <= ny < R
and 0 <= nx < C
and matrix[ny][nx] not in alpha
):
dfs((ny, nx), alpha + matrix[ny][nx], depth + 1) # 재귀이 경우 대부분의 경우에서 시간 초과가 발생하게 됩니다. (대부분이라고 표현한 것은 코드 형태에 따라 아슬아슬하게 통과하는 케이스도 봤기 때문입니다.) 이유는 많은 중복된 재귀 발생입니다. 다음의 예시를 보겠습니다.
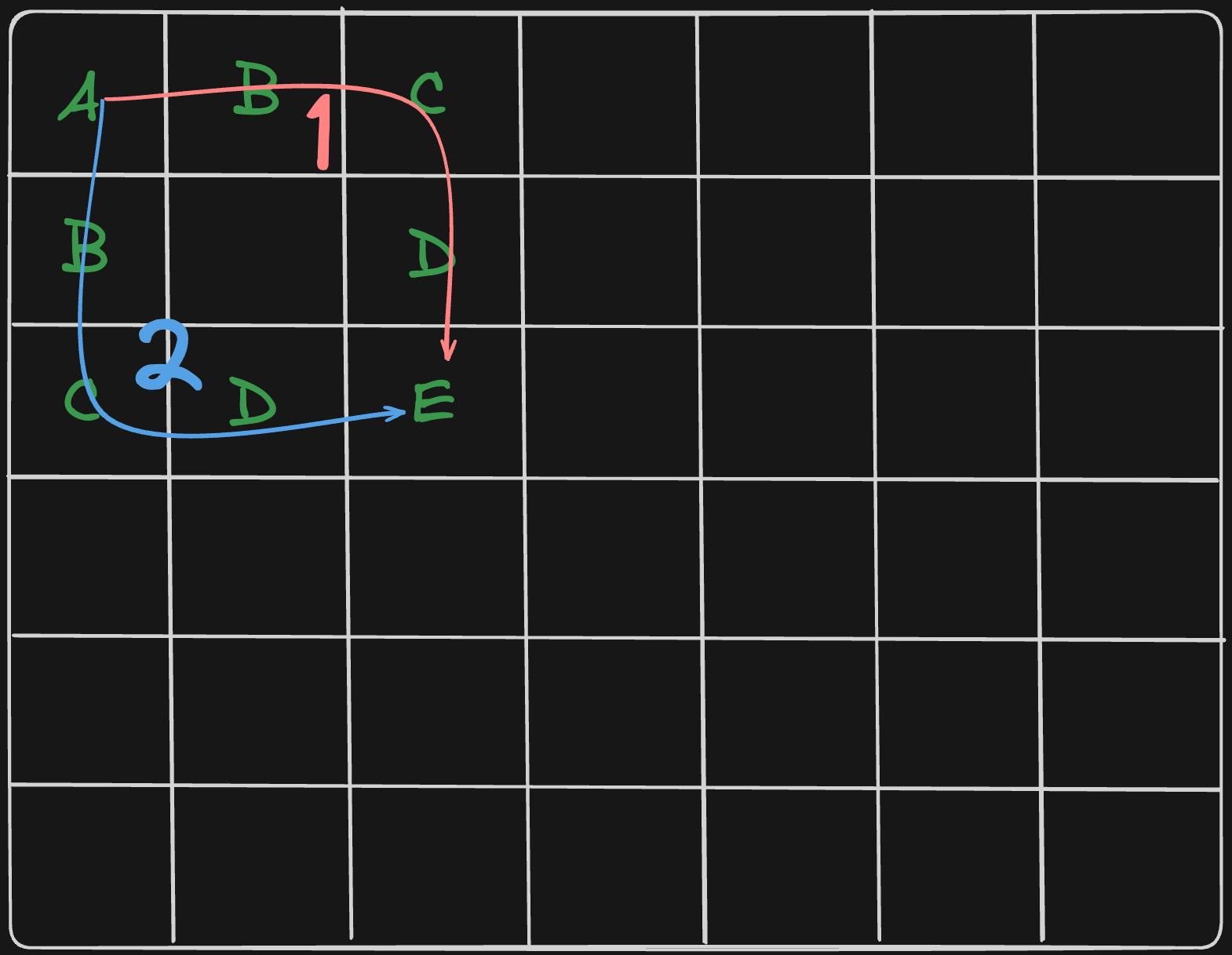
- (0, 0)에서 1번 루트로 A -> B -> C -> D -> E
- (0, 0)에서 2번 루트로 A -> B -> C -> D -> E
두 경우는 명백하게 다른 경우이지만 (2, 2) 좌표에 도착 이후에 탐색하게 되는 경우는 동일합니다. 하지만, 일반적인 DFS, 백트래킹에서는 이를 고려하지 않기 때문에 이러한 경우도 중복해서 탐색하게 됩니다. matrix의 크기가 작은 경우 별 문제가 없어 보이지만, 최대인 20x20에서는 엄청난 연산량으로 시간 초과를 야기하게 됩니다.
따라서 위와 같이 특정 좌표에 특정 알파벳 순서로 동일하게 도착한 여러 경우에 대해 한 번만 처리되도록 추가적인 조치가 필요합니다.
👍 중복 제거 : Set 활용
중복을 효과적으로 제거하는 방법이 있죠. 바로 Set 자료형을 활용하는 것입니다. 매 탐색 시에 Set에다 (좌표, 알파벳 순서)를 저장하면 이후 탐색에서 동일한 탐색이 이미 진행되었는지를 확인할 수 있게 됩니다. 특히 우리는 최대 몇 개의 칸을 지날 수 있는 지만을 탐색하는 것이기 때문에 이 방법은 유효합니다.
방법은 간단합니다. 아래처럼 별도의 set을 정의해서 매 탐색마다 (좌표, 알파벳 순서)가 set에 있는지 확인하고 이미 있다면 중복이므로 패스, 없다면 set에 넣어주고 재귀를 진행하면 됩니다. 이 방법이 dp의 메모이제이션과 유사하여 해당 set을 dp_set으로 정의하여 구현하였습니다.
import sys
from typing import Tuple
sys.setrecursionlimit(10**6)
input = sys.stdin.readline
def dfs(points: Tuple[int], alpha: str, depth: int) -> None:
"""
points에서 중복되지 않는 알파벳을 가진 상하좌우 칸으로 재귀한다.
재귀하는 과정에서 중복 방지를 위한 dp set을 활용하고, max depth를 global 변수 answer에 저장한다.
"""
global answer
if answer < depth:
answer = depth
y, x = points
for d in range(4):
ny = y + dy[d]
nx = x + dx[d]
# 다음 조건을 만족하는 경우만 재귀(백트래킹)
if (
0 <= ny < R
and 0 <= nx < C
and matrix[ny][nx] not in alpha
and (ny, nx, alpha + matrix[ny][nx]) not in dp_set # 중복 제거
):
dp_set.add((ny, nx, alpha + matrix[ny][nx])) # 중복 케이스 저장
dfs((ny, nx), alpha + matrix[ny][nx], depth + 1) # 재귀
R, C = map(int, input().rstrip().split())
matrix = [list(input().rstrip()) for _ in range(R)]
dy = [-1, 1, 0, 0]
dx = [0, 0, -1, 1]
answer = 0
dp_set = set() # 중복 제거를 위한 set 활용
dp_set.add((0, 0, matrix[0][0]))
dfs((0, 0), matrix[0][0], 1)
print(answer)
🙏 문제 접근 방법 및 코드에 대한 피드백과 질문은 환영입니다!
