
유튜브 강의 및 여러 레퍼런스를 참고한 정리입니다.
👋 분할정복법(Divide & Conquer)
어렵고 큰 문제를 쉽고 작은 문제로 분할해 재귀적으로 해결하는 방법이다.
📕 분할정복 설계 전략
- 분할 : 문제의 입력사례를 둘 이상의 작은 입력 사례로 분할한다.
- 정복 : 작은 입력 사례들을 각각 정복한다. 작은 입력 사례들이 충분히 작지 않으면 재귀 호출을 통해 더 작게 분할하여 정복할 수 있도록 한다.
- 통합 : 필요하면, 작은 입력 사례의 해답을 통합하여 원래 입력사례의 해답을 도출한다.
📗 분할정복 vs 동적계획
- 분할 정복은 주로 하향식(Top-Down) 문제풀이 방식을 보이며, 동적 계획은 주로 상향식(Bottom-Up) 문제풀이 방식을 보인다.
- 기존 알고 있던 동적 계획법의 Top-Down 문제풀이 방식 중 하나, 아니면 그 자체를 분할 정복이라고 이해하면 될 것 같다.
📊 퀵 정렬 : 대표적인 분할 정복을 활용한 정렬 방법
- 내부(in-place) 정렬 : 추가적인 리스트를 사용하지 않는 정렬이다.
- 퀵 정렬의 분할 정복 설계 전략
- [Divide] 기준 원소(pivot을 정해서 기준 원소를 기준으로 좌우로 분할
- [Conquer] 왼쪽의 리스트와 오른쪽의 리스트를 각각 재귀적으로 퀵 정렬
- [Obtain] 정렬된 리스트를 리턴
- 구현
기준 원소(pivotpoint)를 정하고, 이를 기준으로 분할하는 파티션(partition)알고리즘을 정의해야 한다.S = [15, 22, 13, 27, 12, 10, 20, 25] def quicksort(S, low, high): if high > low: pivotpoint = partition(S, low, high) quicksort(S, low, pivotpoint-1) quicksort(S, pivotpoint+1, high)
📙 기준 원소(pivot) 정하기
- 가장 첫번째 원소, 가장 마지막 원소를 pivot으로 정한다.
- 가장 첫번째 원소, 가운데 원소, 가장 마지막 원소 중 중간 값을 가지는 원소를 pivot으로 정한다.
- 가장 첫번째 원소를 첫번째 pivot, 가장 마지막 원소를 두번째 pivot으로 정하여 pivot을 2개 사용하는 dual pivot 방식의 quick sort 방법 등이 있다.
⇒ 본 정리에서는 첫 번째 원소를 pivot으로 활용하는 방법을 채택했다.
📘 기준 원소로 리스트 나누기 : 첫 번째 방법(보편적 X)
- 두 개의 인덱스(i, j)를 이용해서 비교(compare) 후 교환(swap) 한다 : compare & swap
- i를 pivot다음 인덱스(1), j를 pivot 인덱스(0)로 두고 비교한다.
- i위치의 원소가 j위치의 원소보다 크다면 그대로 둔다.
- i만 +1해준다.
- i위치의 원소가 j위치의 원소보다 작다면 i위치의 원소와 j+1위치의 원소를 교환한다.
- i와 j를 모두 +1 해준다.
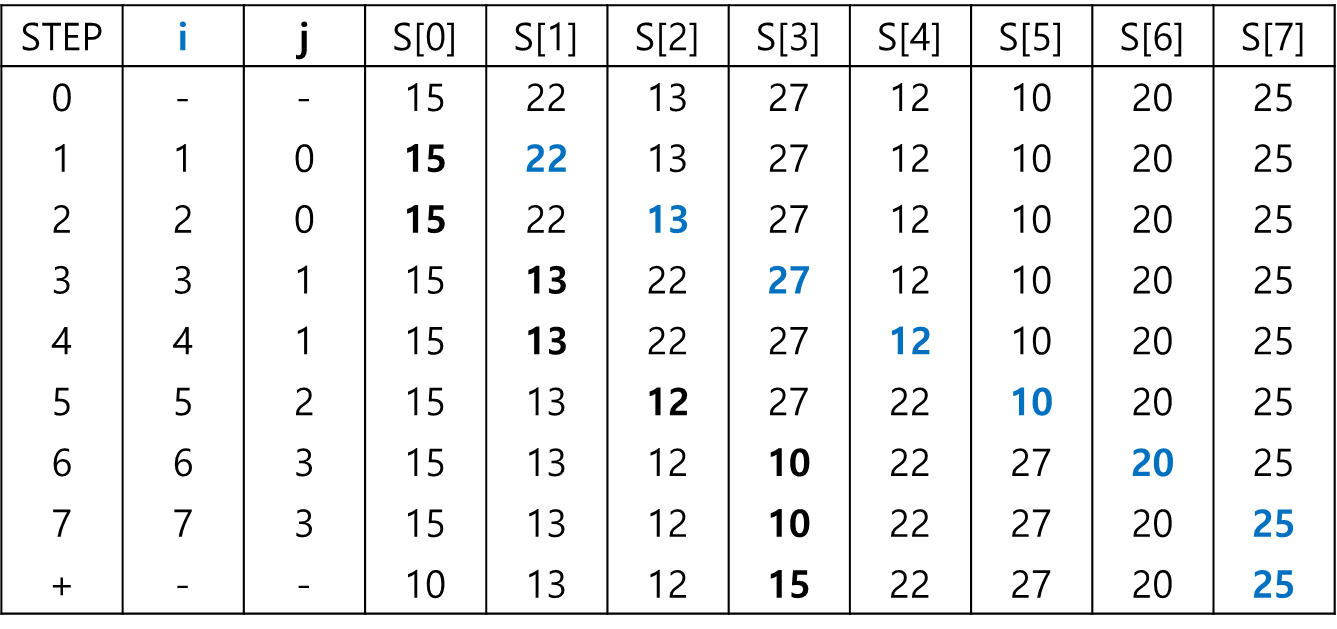
- STEP1 : i를 pivot다음 인덱스(1), j를 pivot 인덱스(0)로 두고 비교한다.
- 이 때 i위치의 원소가 j위치의 원소보다 크다면 그대로 두고 작으면 i위치의 원소와 j위치의 원소를 교환한다.
- i위치의 원소가 더 크므로 교환하지 않았다, i를 1 증가시킨다.
- STEP2 : i(2)번째 원소가 j(0)번째 원소보다 더 작다.
- i(2)번째 원소와 j+1(1)번째 원소를 교환한다.
- i와 j 모두 1씩 증가시킨다.
- 이 과정을 i가 리스트 길이가 될 때까지 반복한다.
- 마지막 j(3)위치의 원소와 pivot(0)위치의 원소를 교환한다. 최종적으로 pivot을 기준으로 왼쪽은 더 작은 리스트, 오른쪽은 더 큰 리스트로 분할되었다.
- 구현
def partition(S, low, high): pivotitem = S[low] j = low for i in range(low+1, high+1): if S[i] < pivotitem: j += 1 S[i], S[j] = S[j], S[i] pivotpoint = j S[low], S[pivotpoint] = S[pivotpoint], S[low] return pivotpoint
📕 기준 원소로 리스트 나누기 : 두 번째 방법(보편적인 방법)

- 마찬가지로 두 개의 인덱스(i, j)를 이용해서 비교(compare) 후 교환(swap)하되, i는 앞에서부터, j는 뒤에서 부터 시작한다.
- i인덱스를 pivot 다음 인덱스부터 시작하여 pivot 위치의 원소보다 더 큰 원소를 처음 만나는 위치까지 증가시킨다.
- 동시에 j인덱스를 뒤에서부터 시작하여 pivot 위치의 원소보다 더 작은 원소를 처음 만나는 위치까지 감소시킨다.
- i와 j위치의 원소를 교환한다. 이 과정을 i와 j가 역전될 때까지 반복한다.
- j위치의 원소와 pivot위치의 원소를 교환한다. 최종적으로 pivot을 기준으로 왼쪽은 더 작은 리스트, 오른쪽은 더 큰 리스트로 분할되었다.
- 구현
def partition2(S, low, high): pivot = S[low] i = low+1 j = high while i <= j: while S[i] < pivot: i += 1 while S[j] > pivot: j -= 1 if i < j: S[i], S[j] = S[j], S[i] pivot = j S[low], S[pivot] = S[pivot], S[low] return pivot
REFERENCE

Grow Exponentially