[논문]Code as Policies: Language Model Programs for Embodied Control
https://arxiv.org/abs/2209.07753
링크는 여기에.
1. Introduction
- 기존 방식 : end-to-end - 구체적인 제어동작 하나를 그대로 학습
-> 비용도, 시간도 오래 걸림 -> LLM을 사용하는 것으로 변경 - 요즘 LLM : 별도의 파인튜닝 없이도 자연어를 입력받아 거기서 단계를 계획하고 실행시키는 작업이 가능
-> 강화학습과 함께 사용 시 Value Function을 높이는 방향으로 작동시키면 로봇과도 연결 가능! - 그러나 간단한 명령을 받아서 바로바로 반영하는 것은 학습을 처음부터 다시 해야 해서 힘들다.
- 코드 작성이 가능한 LLM의 경우, 단순 코드 작성을 넘어 계획 수립, 정책 로직, 제어를 조합하는 데까지 확장시킬 수 있음.
코드 작성이 가능한 LLM은 언어 기반 피드백 루프도 표현 가능.(단순히 '더 빠르게'나 '좀만 더 왼쪽으로' 등의 표현을 처리 가능)
그리고 정책으로서의 코드 표현은 이러한 LLM의 이점을 그대로 가져갈 수 있음. 자연어 해석은 물론 사용자와의 대화 역시도 가능함.
2. Related Work
- LLM: 인상적인 제로샷 추론능력을 보유
Least-to-Most, Think-Step-by-Step 또는 Chain-of-Thought 방법과 같은 프롬프트 기법을 곁들여 사용하면 추론능력 향상 가능 - Huang - 자연어 명령을 실행 가능한 동작 시퀀스로 분해
- SayCan - 수익 함수를 기반으로 LLM을 공동으로 디코딩하여 로봇에 대한 실행 가능한 계획을 생성
- Inner Monologue - 다른 시각 언어 모델의 출력을 통합하여 LLM의 코드 작성을 확장
- Socratic Models - 계획을 생성하는 언어 프롬프트에 지각 정보를 대체하여 사용
콜라 캔을 조금 오른쪽으로 옮기는 간단한 명령을 내렸다고 치자.
- Socratic Models의 경우 : objects = [콜라 캔]
- robot.grasp(콜라 캔) open vocab
- robot.place_a_bit_right()
- 반면 논문에서 제안하는 모델 CaP의 경우 : while not obj_in_gripper("콜라 캔"):
robot.move_gripper_to("콜라 캔")
robot.close_gripper()
pos = robot.gripper.position
robot.move_gripper(pos.x, pos.y+0.1, pos.z)
robot.open_gripper()
이 정도로 세분화한다.
3. Method

그림은 간략한 이 LMP 구조. 프롬프트를 입력하면 이를 LLM에 넣어 policy에 맞는 코드를 출력하는 방식이다.
LLM에 대한 복잡한 아키텍쳐라던가 그런게 있을 줄 알았는데...없더라구요?
- LMP : LLM을 활용하여 다양한 작업을 수행하도록 만들어진 프로그램.
이 논문 내에서의 LMP는 다음과 같이 작동한다.
(i) 감각 입력(예: 센서 또는 센서 위 모듈에서 발생하는 입력)에 반응하고,
(ii) 제어 원시 API를 매개변수화하며,
(iii) 로봇에서 직접 컴파일되고 실행됩니다. - 작동은 다음과 같다.
//빈 그릇에 블록 쌓기.
empty_bowl_name = parse_obj('empty bowl')
block_names = parse_obj('blocks')
obj_names = [empty_bowl_name] + block_names
stack_objs_in_order(obj_names=obj_names)저 주석 부분이 입력이고, 나머지는 생성한 코드이다.
코드는 일반적으로 알려진 함수들로 조합하거나, 임의의 함수를 쓰고 그 함수에 대해서도 LMP 작업을 진행하는 방식으로 작성된다.
3.1. Prompting Language Model Programs
- LMP 생성에 대한 내용.
- LMP를 생성하기 위한 유도문은 크게 두 파트로 나뉜다.
- 하나는 '힌트'. 사용 가능한 API를 알리는 import 문 및 이러한 API를 사용하는 방법에 대한 정보가 들어간다.
- 다른 하나는 '예시'. 자연어 지침을 코드로 변환하는 방법을 나타내는 몇 가지 "시연"을 포함하는 지침-코드 쌍으로, 새로운 지침과 응답을 점진적으로 추가하면서 LMP "세션"을 유지할 수 있다.
나중에 입력된 지침은 이전에 입력된 지침을 참고하기 때문에, '방금 전의 지침은 무시해줘' 같은것도 가능하다.
3.2. Example Language Model Programs (Low-Level)
- 간단한 작업에서의 예시.
ret_val = a //변수 a와 b의 합을 찾습니다. ret_val = a + b //xs라는 리스트 내에서 어떤 숫자가 3으로 나누어 떨어지는지 확인합니다. ret_val = any(x % 3 == 0 for x in xs)
이런식으로 프롬프트 입력에 따라서 코드가 작성된다.
- 서드파티 라이브러리 사용 예시. 예시는 numpy.
import numpy as np
#pts_np의 모든 포인트를 오른쪽으로 이동합니다.
ret_val = pts_np + [0.3, 0]
//pt_np를 위쪽으로 이동합니다.
ret_val = pt_np + [0, 0.3]
//pts_np에서 가장 왼쪽의 포인트를 가져옵니다.
ret_val = pts_np[np.argmin(pts_np[:, 0]), :]
//pts_np의 중앙을 가져옵니다.
ret_val = np.mean(pts_np, axis=0)
//pt_np와 가장 가까운 pts_np의 포인트를 가져옵니다.
ret_val = pts_np[np.argmin(np.sum((pts_np - pt_np)**2, axis=1))]LMP는 자주 사용되는 일부 서드파티 라이브러리 코드의 사용 역시 자유롭다.
- 퍼스트파티 라이브러리 사용 예시.
from utils import get_pos, put_first_on_second
//보라색 그릇을 왼쪽으로 이동합니다.
target_pos = get_pos('purple bowl') + [-0.3, 0]
put_first_on_second('purple bowl', target_pos)
objs = ['blue bowl', 'red block', 'red bowl', 'blue block']
//빨간 블록을 약간 오른쪽으로 이동합니다.
target_pos = get_pos('red block') + [0.1, 0]
put_first_on_second('red block', target_pos)
//파란 블록을 같은 색의 그릇 위에 놓습니다.
put_first_on_second('blue block', 'blue bowl')LMP는 훈련 데이터에 없는 퍼스트파티 라이브러리 및 API 사용 역시 자유롭다.
또한, 서드파티/퍼스트파티 라이브러리 사용 시 만들어지는 함수는 유의미한 이름을 가지게 되며, 이는 힌트 및 예제에서 제공된다.
- 힌트는 로봇 환경에서 다음과 같은 두 함수를 불러온다.
- 이름으로 객체의 2D 위치를 가져오는 함수.
ex) 'red block'의 위치 찾기 - 첫 번째 객체를 두 번째 대상 위에 올려놓는 함수.
ex) 'red block'을 'blue block' 위에 올리기
3.3. Example Language Model Programs (High-Level)
- LMP로 간단한 피드백을 포함하는 while루프를 작성하게 할 수 있다.
//빨간 블록이 파란 그릇의 왼쪽에 있는 동안, 5cm씩 오른쪽으로 이동시킵니다.
while get_pos('red block')[0] < get_pos('blue bowl')[0]:
target_pos = get_pos('red block') + [0.05, 0]
put_first_on_second('red block', target_pos)- LMP로 함수가 중첩된 형태의 코드를 작성하는 것도 할 수 있다.
objs = ['red block', 'blue bowl', 'blue block', 'red bowl']
//가장 왼쪽 블록이 빨간 블록일 때, 오른쪽으로 이동합니다.
block_name = parse_obj('the left most block')
while block_name == 'red block':
target_pos = get_pos(block_name) + [0.3, 0]
put_first_on_second(block_name, target_pos)
block_name = parse_obj('the left most block')이러한 중첩 함수 형태의 경우, LMP가 이전에 생성한 코드를 살펴보면서 미정의된 함수를 찾고, 이를 생성하는 데 특화된 또 다른 LMP를 호출해 생성하는 방식으로 작동한다. 따라서 프롬프트를 입력할 때 전체에 대해 알려주지 않더라도, 대략적인 개요만으로 온전한 코드를 만들 수 있다.
- 고수준의 LMP는 추상화 구조를 잘 따른다.
추상화 구조 : 함수를 나누거나 적절히 구조화한다는 뜻.
모든 기능을 한 줄에 몰아넣는다거나 하지 않는다.
//함수 정의: get_obj_bbox_area(obj_name).
def get_obj_bbox_area(obj_name):
x1, y1, x2, y2 = get_obj_bbox_xyxy(obj_name)
return (x2 - x1) * (y2 - y1)이런 식으로 기능을 나눠넣으면서, 코드를 읽기 쉽게 만든다. 여기서 get_obj_bbox_xyxy가 무슨 역할인지 명시되지는 않았지만, 그 이름에서 대략적인 역할을 추론할 수도 있다.
3.4. Language Model Programs as Policies
-
로봇 policy의 맥락에서 볼 때, 자연어 지침을 바탕으로 인식-제어 피드백 논리를 구성할 수 있다. 사용 가능한 인식 및 제어 API에 대한 이전 정보는 예제 및 힌트를 통해 안내되고, 그 API들은 LMP와 로봇을 실질적으로 연결해주는 역할을 맡는다.
-
LMP 기반 policy가 가지는 이점은 다음과 같다.
- 향후 입력받거나, 생성될 자연어 지침에 의해 지정된 새로운 작업과 행동에 맞춰 정책 코드와 매개변수를 조정할 수 있다.
- 새로운 객체와 환경에 일반화할 수 있다.
- 별도의 추가 데이터 수집이나 모델 학습이 필요하지 않다.
따라서, LMP를 활용하는 것은 LLM의 이점을 그대로 가져온다고 볼 수 있다.
4. Experiments
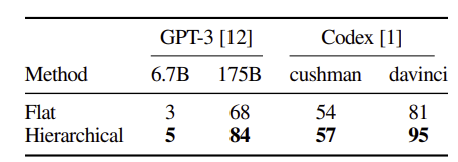
4가지 LLM에 대해, LLM이 생성한 코드가 얼마나 인간이 작성한 테스트 기준을 통과했는지에 대한 지표.
GPT에 비해 Codex 모델이, Flat 보다는 계층적 모델이 더 우수한 성능을 거두었다.
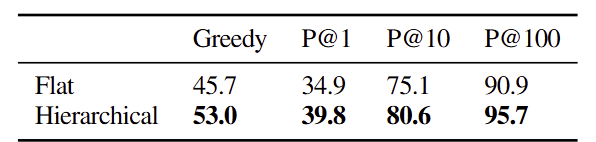
아까에서 더 나아가, 계층적 코드 생성 LLM 부분에 특히나 주목한 실험 결과. 4가지 방식 모두 Flat에 비해 계층적인 모델이 더 강점을 가진다.
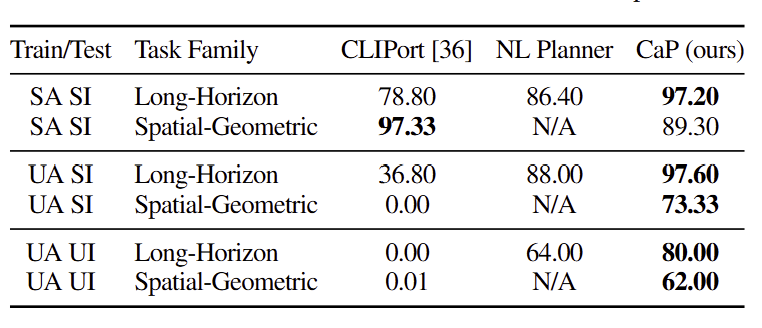
5. Discussion and Limitations
- 결론적으로, Code as Policies는 LLM의 강점을 이용해 다양한 자연어 명령을 이해하고, 코드를 작성하여 로봇 동작까지도 가능하게 한다.
- 다국어에 대응할 수 있거나, 이모지 등에 대한 이해도 가능하다는 것, 그리고 코드를 인간이 이해하기 쉽고, 계층적으로 구성할 수 있다는 점이 특히나 강점이다.
- API에 따라 같은 작업을 다른 방식으로 진행할 수 있게 하는 것도 가능하다.
- 다만 과하게 추상적인 부분에 대해서는 작동할 수 없으며, 너무 긴 문장이나 복잡한 작업에 활용하기에는 한계가 있다.
