핸즈온 머신러닝 191~201p
앙상블 기법
한 가지 모델만이 아닌 여러 모델들을 훈련해 더 좋은 예측 결과를 만드는 알고리즘 기법.
사이킷런에서 기본 제공하며, 정형 데이터(CSV 파일 / 스프레드시트 등)를 다루는 데 있어 가장 성능이 좋은 머신러닝 기법 중 하나. 실제로 여러 머신러닝 대회 우승작들을 보면 앙상블 기법을 사용한 모델을 심심치 않게 확인할 수 있다.
종류는 보팅 / 배깅 / 부스팅 / 스태킹 / 랜덤포레스트 등등이 있다.
Voting Classifier
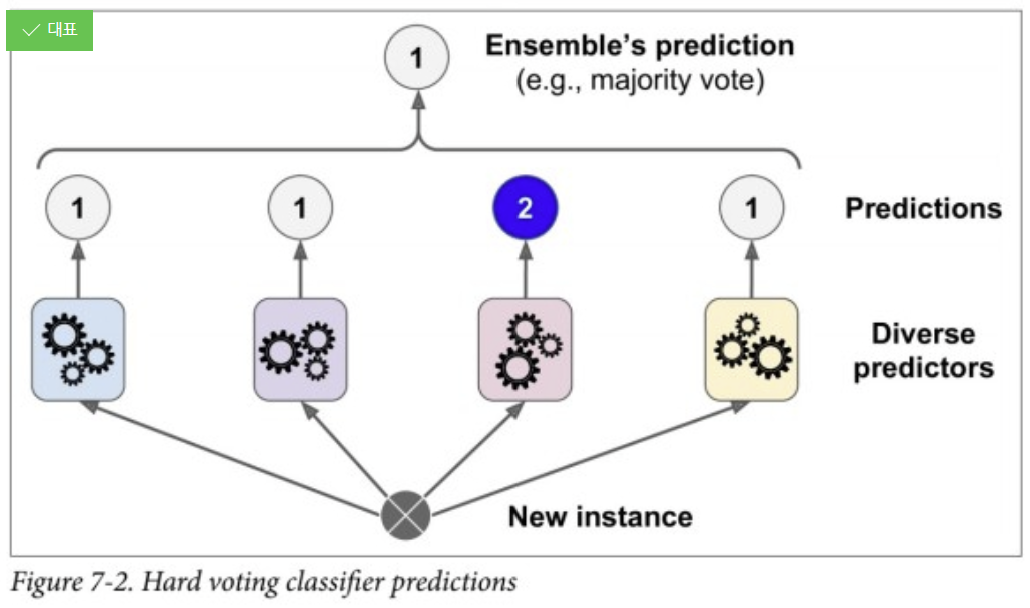
이런 식으로 여러 모델들을 이용해 예측을 하고, 그 중 가장 성능이 좋은 것 하나를 최종 예측으로 사용하는 방식.
가장 기초적이고 간단한 방식이지만, 간혹 이 방식으로 타 앙상블 기법들보다 높은 정확도를 얻는 경우가 있다.
다만 이는 큰 수의 법칙에 의해 그저 많은 수의 모델들을 돌리는 것이기에 정확도가 낮은 모델이 최종적으로 선택되는 경우가 적은 것이며, 반대로 사용되는 모든 각각의 모델들에 대해 동일한 데이터를 사용하므로 각각의 모델들이 모두 동일한 오류를 일으켜 정확도가 떨어질 가능성도 높다.
Voting Classifier 사용해보기
앙상블 기법은 내부의 모델들이 서로 독립적일 수록 더 잘 작동한다. 완전히 다른 두 머신러닝 기법 두개를 이용해 앙상블을 사용하는 것만으로도 나쁘지 않은 정확도의 앙상블 기법 모델을 얻을 수 있다.
Voting Classifier 기반 앙상블 모델을 만들어보았다.
https://www.kaggle.com/code/smarcle/taekyung-ch7-1
코드는 위에서 확인 가능.
내용을 대충 요약하면 이렇다.
로지스틱 회귀, 랜덤포레스트, SVC 3개의 모델을 사용해 각각 moons 데이터셋에 대해 돌리고, 이 3개로 앙상블 모델을 만든 것. 최종 결과는 위 3개 모델 각각의 결과보다 좋은 성능을 보인다.
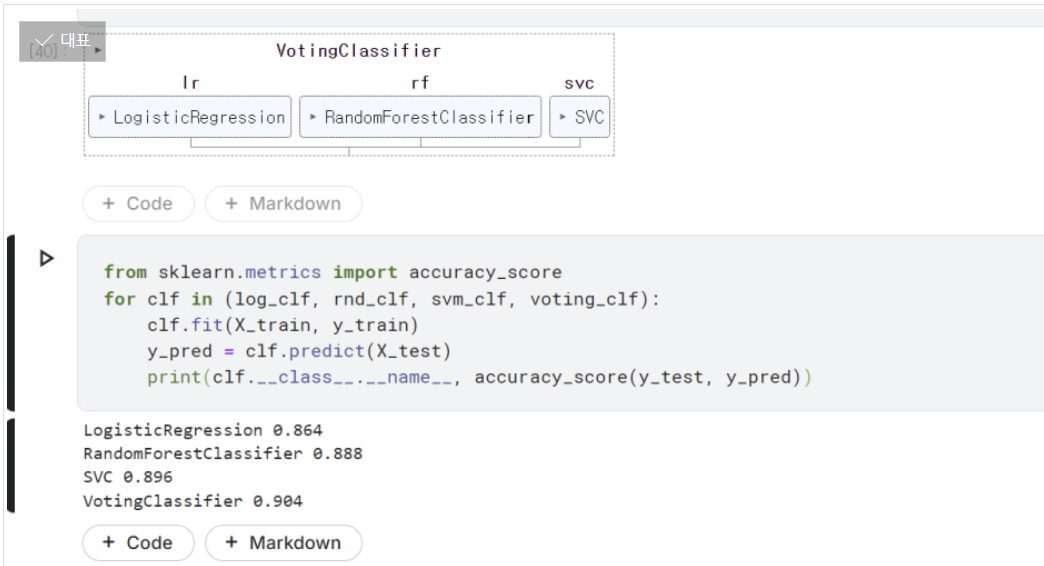
해당 코드는 hard voting 방식으로, 이것과 살짝 다르게 각각의 모델들에 대해 단순히 최다득표가 아닌 각 모델이 예측한 클래스별 확률 평균 중 가장 높은 클래스를 최종 결과로 사용하는 soft voting 방식이 있다.
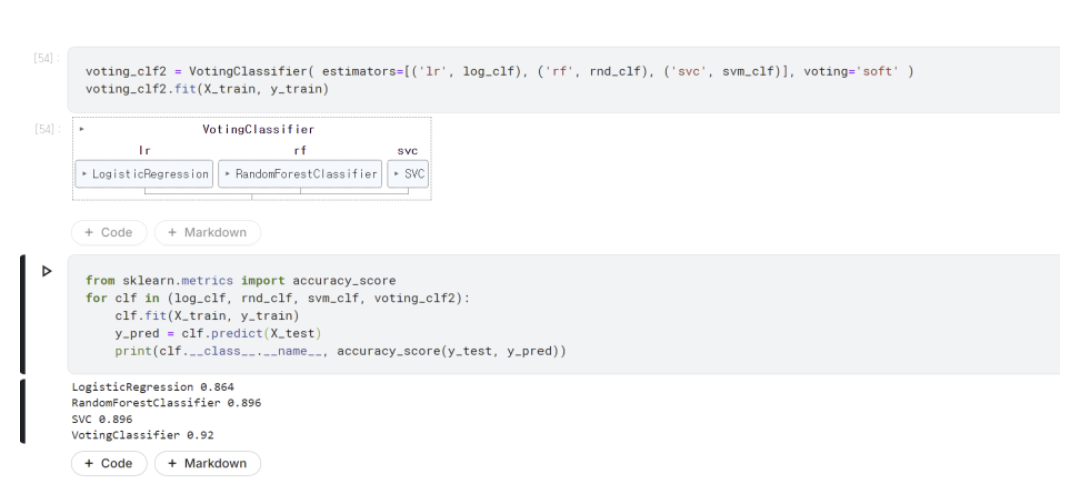
성능은 hard voting에 비해 soft voting이 살짝 더 좋다. 다만 내부에서 사용하는 모델들 중 predict_proba를 사용하지 않는 모델이 있는 경우 hard voting이 강제된다.
배깅 / 페이스팅
아까처럼 서로 다른 여러 개의 모델을 사용하여 앙상블하는 것도 가능하지만, 같은 모델들을 사용하되 전체 train 데이터셋 내에서 무작위 부분집합에 대해 모델을 돌리는 방법도 있다.
여기서 부분집합을 만들 때 2가지 방식으로 갈리는데
- 중복을 허용하는 경우는 배깅
- 중복을 허용하지 않는 경우는 페이스팅이다.
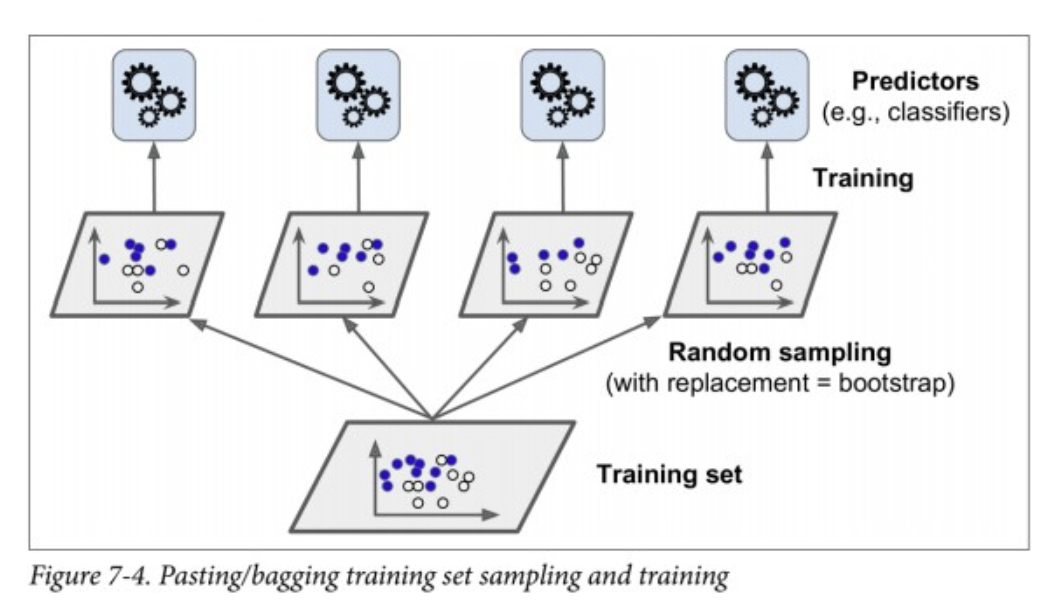
위 그림과 비슷하게 흘러간다고 보면 된다.
각각의 부분집합들에 대해 모델들을 돌리고, 이 모델들에 대해 예측값을 뽑고, 이 예측값들을 토대로 새로운 데이터들을 예측할 수 있다.
배깅/페이스팅의 장점 중 하나는 바로 병렬로 훈련이 가능하다는 것. 저 그림의 4개를 모두 다른 CPU나 서버에서 돌릴 수 있고, 따라서 확장성이 좋다.
배깅 / 페이스팅 사용해보기
이번에는 디시전트리 방식 하나만 이용하여 배깅을 진행해보았다.
아까 그 캐글 노트북에서 아래쪽에 코드를 작성했다.
500개의 디시전 트리에 대해 최대 크기 100인 부분집합들을 각각 학습시킨 모델이다.
해당 코드 부분에서 bootstrap을 True로 설정하면 배깅, False로 설정하면 페이스팅.
일반적으로 배깅이 페이스팅에 비해 성능이 살짝 더 좋게 나오는 편.
Out of bag 평가 방법
배깅에 대해 치명적인 단점이 하나 있는데, 바로 배깅 특유의 중복을 허용하는 방식 자체다.
이는 부분집합을 만들 때 여러 번 뽑혀가는 데이터가 있을 수 있는 반면 1번도 사용되지 않는 데이터들도 있다는 것을 의미한다. 이 때 안 쓰인 데이터들을 Out Of Bag / 줄여서 oob 라고 칭한다.
이 oob 역시 하나의 정확도 평가 지표가 될 수 있다.
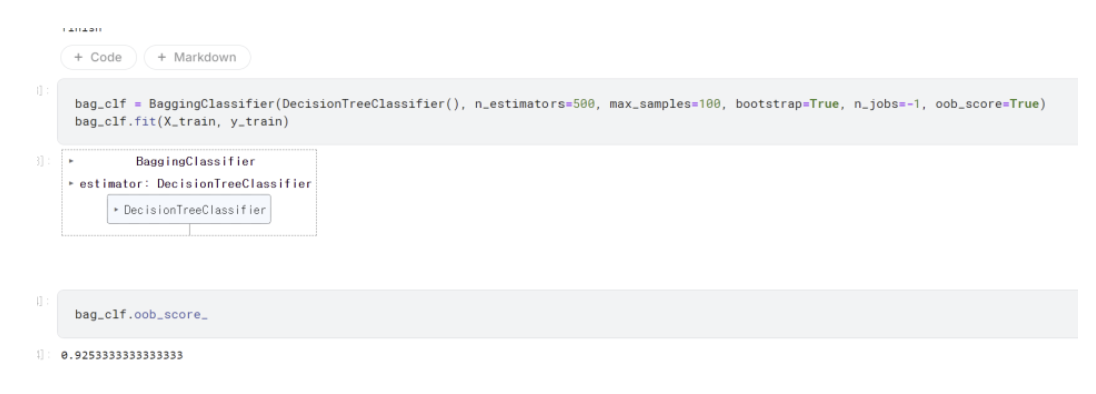
baggingclassifier를 사용할 때 oob_score를 True로 해놓으면 사용 가능.
위와 같이 확인 가능하며 해당 모델의 정확도는 92.5%쯤 되는듯.
7.3 랜덤 패치와 랜덤 서브스페이스
배깅의 경우 특성 샘플링도 지원한다.
훈련 특성과 샘플을 모두 샘플링하는 방식 - 랜덤 패치 방식
훈련 샘플을 모두 사용하고 특성을 샘플링하는 방식 - 랜덤 서브스페이스 방식
랜덤 포레스트
랜덤 포레스트 방식은 위의 방식들 중 배깅을 기반으로 사용된다.
위의 디시전트리 방식을 사용하는 대신, 랜덤포레스트 분류기 모델을 사용하면 조금 더 간편하게, 그리고 조금 더 디시전트리에 최적화된 방식으로 사용할 수 있다.
랜덤포레스트 분류기는 디시전트리와 배깅 두가지의 하이퍼파라미터를 가진다.
- 디시전트리의 트리 성장 방식 제어에 대한 하이퍼파라미터
- 배깅의 앙상블 자체 제어에 대한 하이퍼파라미터
간단히 위에서 한 배깅+디시전트리 를 하나로 합쳐서 더 개량한 버전이라고 생각하면 편할 듯.
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)7.4.1 엑스트라 트리
트리를 더 랜덤하게 만들기 위해, 임곗값을 찾는 대신 후보 특성을 사용해 랜덤으로 분할 수 그 중 최적의 분할을 선택하는 방식.
7.4.2 특성 중요도
랜덤포레스트 분류기의 장점 중 하나는 특성들의 상대적 중요도를 측정하기 쉽다는 것.
from sklearn.datasets import load_iris
iris = load_iris(as_frame=True)
rnd_clf2= RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf2.fit(iris.data, iris.target)
for score, name in zip(rnd_clf2.feature_importances_, iris.data.columns):
print(round(score, 2), name)아래 처럼 결과가 나오는데, 이걸로 각 특성의 중요도를 확인할 수 있다.
0.11 sepal length (cm) 0.02 sepal width (cm) 0.44 petal length (cm) 0.42 petal width (cm)
7.5 부스팅
약한 학습기 여러개를 연결해 강한 학습기를 만드는 앙상블 기법
- Adaboost : 이전 모델에서 언더피팅된 데이터에 대해서 가중치를 높여 학습시키는 방식. 이렇게 하면 학습이 어려운 샘플에 대해 점점 더 맞춰진다.
- gradientboosting : 위의 Adaboost랑 비슷한데, 얘는 가중치가 아니라 이전 모델의 '잔여 오차'를 이용해 새 모델을 점점 학습시켜나간다.
- HGB : 히스토그램 기반 gradientboosting의 약자. 입력 특성을 구간으로 나눠서 정수로 대체하는 방식.
7.6 스태킹
앙상블 방식 중 하나로, 각각의 모델들의 결과를 input 값으로 받는 모델을 하나 만들어 최종 예측을 뽑는 방식.
