마스터 노드가 망가지더라도 일단 워커 노드는 정상적으로 작동한다.
그러나 파드에 문제가 생겨서 api를 호출하는 일이 생긴다거나 한다면 정상적으로 작동할 수 없게 된다.
그래서 멀티 마스터 클러스터 구성이 운영 환경에서 중요하다.
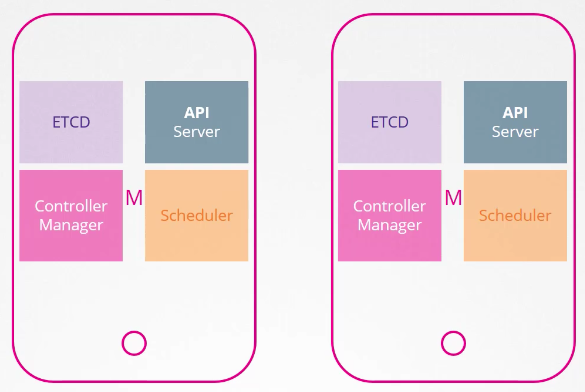
마스터 노드가 2개라면, 같은 작업을 2번 하나? 그럴리가
그렇다면 어떻게 여러 마스터 노드가 서로 일을 분담해서 처리할까?
kube-apiserver

active-active 모드로 동시에 실행 중인 상태이다.
일종의 LB를 둬서 분산시켜 호출하게 만든다.
nginx, haproxy 같은 장치를 사용하여 구현할 수 있다.
contoller manager & scheduler
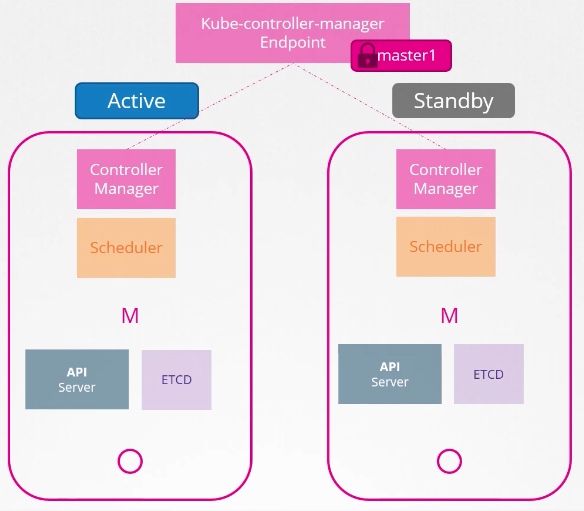
두 객체의 작업 특성상(파드 생성) 동시에 실행되지 않아야 하기 때문에 active-standby 모드로 실행한다.
어느 쪽이 active 상태가 되는지는 일종의 선거를 통해 정해진다.
kube-controller-manager --leader-elect true [other options]
--leader-elect-lease-duration 15s
--leader-elect-renew-deadline 10s
--leader-elect-retry-period 2s15초 간의 잠금장치
2초마다 한 번씩 리더 선출 시도함 - 현재 리더가 비정상일 수 있기 때문에
controller-manager와 scheduler 동일한 프로세스
etcd
etcd의 위치에 따라 2가지 디자인 방식이 존재함
stacked topology

etcd가 마스터 노드 내에 존재하는 경우
설치와 관리가 쉽고 더 적은 서버 갯수가 필요함
그러나 문제 발생시 리스크가 더 크다
external etcd topology
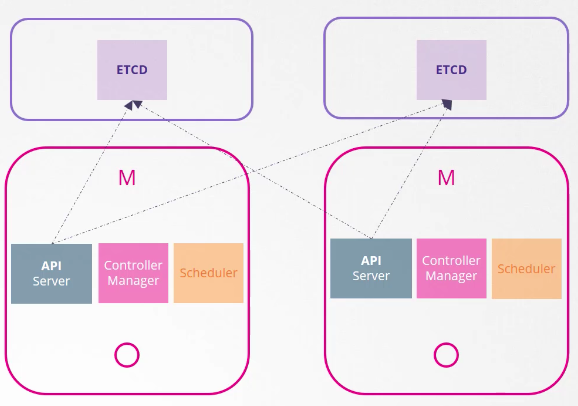
etcd가 마스터 노드 밖에서 다른 서버에 설치되는 경우
리스크가 적지만 세팅이 더 어렵고 더 많은 서버 갯수가 필요하다.
etcd 정보
kube-apiserver는 etcd와 통신하는 유일한 객체이다.
그래서 kube-apiserver 설정을 보면 바라봐야 하는 etcd 주소가 명시되어 있다.
etcd가 마스터노드 내에 있든, 밖에 있든 상관 없다.

