
1. This is Fine.
서비스 호출을 시각화하는 네트워크 맵이라는 기능을 만들고 있다.
Trace 데이터를 기반으로 시작지점과 도착지점을 시각화하여, 운영자에게 시스템 아키텍쳐 이해를 돕고 에러 발생 지점을 쉽게 찾을 수 있게 도와주는 기능이다.
맨 처음에는 그냥 MV(Materialized View) 1개로 network map 기능을 위한 데이터 정제 로직을 만들었다.
src, dest, protocol, cluster, namespace 등 몇 가지 주요 컬럼들의 데이터가 잘 변환되는 것을 확인했고, 정상이라고 생각했다.

2. 똑 똑 똑, 누구십니까?
그런데 다른 컬럼을 하나씩 살펴보던 중… 외부 서비스 호출 구분에 문제가 있다는 것을 파악했다.
외부 서비스 호출이란 내 클러스터 밖의 서비스를 호출하는 것을 의미한다.
is_external 컬럼의 값이 1이면 클러스터 밖의 외부 서비스 호출을 의미하고, 0이면 동일 클러스터의 서비스 호출을 의미한다.
문제 상황을 예시로 들면 대략 이런 식이다.
서비스 연결 현황:
├── user-service → product-service ✅ (내부)
├── user-service → redis ✅ (내부)
├── user-service → google.com ✅ (외부)
└── user-service → 192.168.254.80 ??? (이게 뭐지?)google.com은 당연히 외부redis는 당연히 내부- 그런데
192.168.254.80은..?
도메인 주소나 서비스 이름을 사용하는 목적지에 대한 분류는 쉽게 할 수 있었다.
그런데 ip에 대한 내/외부 분류는 그렇게 간단하지 않았다.
외부 서비스 호출인지 아니면 클러스터 내부 서비스 호출인지 판단하는 명확한 기준이 필요했다.
3. 퇴사 동료의 Cilium 분석 보고 영감받은 썰.txt
그러던 중.. 퇴사한 동료가 Cilium을 분석한 글을 통해 힌트를 얻을 수 있었다. (special shout out to Thor,, 거기선 행복해야돼)
cilium의 경우 4개의 BPF 맵을 사용해 순서대로 외부 서비스 여부를 검증한다.
그래서 출발지/목적지의 IP가 이 BPF맵에 존재하는지 순서대로 체크한다.
1. cilium_endpoint_map 체크 (Pod CIDR)
2. cilium_service_v4 체크 (Service CIDR)
3. cilium_host_map 체크 (Node CIDR)
4. cilium_remote_node_map 체크 (Node CIDR - Cluster Mesh)
5. 모든 맵에 없으면 → reserved:world (외부)위 모든 맵에 없으면, reserved:world (외부)로 간주한다.
핵심 아이디어를 정리해보면 이렇다.
- 내부 네트워크 정보를 미리 정의해두고
- 순서대로 체크해서
- 어디에도 속하지 않으면 외부로 분류
솔루션의 기반 기술로 Cilium을 사용하여 Hubble을 써본 경험을 토대로 보아, 이 분류 로직은 정확하다고 생각했다. 지금까지 한 번도 reserved:world가 잘못된 것은 못 봤기 때문이다.
그래서 이 아이디어를 가져와서 우리 상황에 접목시켜보기로 했다.
이 아이디어는 크게 2가지 방안으로 구현이 가능했고, 아래처럼 정리해볼 수 있었다.
구현 방향
- podcidr, nodecidr, service cidr 정보를 미리 clickHouse 딕셔너리에 저장해놓고, MV 실행시 참조하여 사용하는 방식
- otel collector 확장 : custom receiver 만들어서 cidr 정보 조회하여 수집
- 별도 수집 시스템 구성
- Beyla eBPF 개발하여 cilium처럼 BPF 맵 활용하여, 앞에서부터 미리 분류하는 방식
이론적으로는 수집하는 가장 앞에서부터 내/외부를 분류하는 방식이 가장 깔끔해 보인다. 데이터 파이프라인에서 신경쓸 부분도 크게 줄어들어서 좋을 것 같다.
그러나 실질적으로 Beyla eBPF 개발(방향 2)이나 otel custom receiver 개발(방향 1-a)은 공수가 너무 많이 들어서 어렵다고 판단했다. 그래서 cidr 정보를 미리 DB에 보관하고, mv로 데이터 정제하는 과정에 참조하여 사용하는 방식(방향 1-b)을 구현하기로 했다.
설계 고민들 🤔
Q1: 누가 Agent 클러스터의 CIDR을 수집할 것인가?
- A: Agent 클러스터에서 자체 수집하는 게 가장 간단
Q2: 누가 Host 클러스터 ClickHouse에 저장할 것인가?
- A: SigNoz OTel Collector 수정은 현실적으로 불가능... 자사 솔루션 Agent App 활용이 답!
Q3: 어떻게 Host 클러스터로 전송할 것인가?
- A: 기존 자사 솔루션 Agent → Host 패턴을 재활용!
이런 점을 고려했을 때 Agent 클러스터에 배포될 자사 솔루션 agent 파드가 PodCidr, NodeCidr, ServiceCidr을 수집해서 자사 솔루션 host 파드로 전송하고, 자사 솔루션 host 파드가 clickHouse에 적재하는 것이 좋아보인다.
아키텍쳐
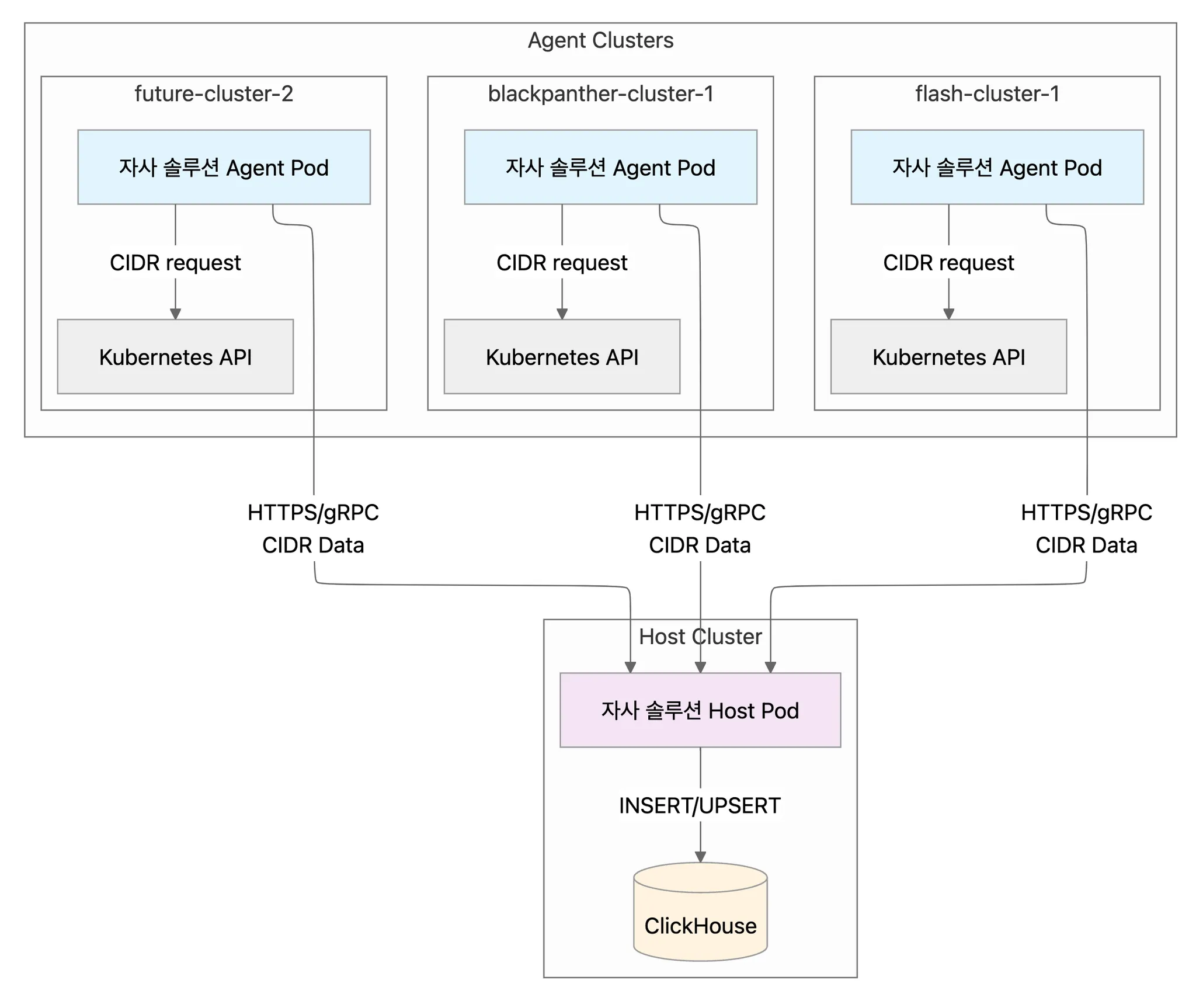
해치웠나…?
개발 테스트 단계에서는 각 agent의 cidr을 수집하는 모듈을 만들어서 사용하고, 추후 자사 솔루션 agent에 통합시키는 것을 목표로 하고 있다.
이렇게 각종 cidr 수집&전송&적재에 대한 프로세스는 정립되었다. 이제 cidr 정보를 토대로 mv에서 데이터 정제만 잘 하면 된다. 그러면 내/외부 서비스 호출을 분류 할 수 있게 된다.

4. MV: "JOIN, 서브 쿼리 안돼" / 나: "응, (2개로) 쪼갤게~"
여기서 첫 번째 문제를 마주했다.
바로 mv에서 join, 서브 쿼리 사용이 불가능하다는 것이다.
정확히 말하자면 where절 서브쿼리 지원이 되지 않아서, 사실상 사용이 불가능하다.
그래서 아무리 깔쌈해보이는(!) MV DDL을 만들어도 동작하지 않았다…
-- 이렇게 하고 싶었는데...
CREATE MATERIALIZED VIEW network_final_mv AS
SELECT
src, dest, protocol,
CASE
WHEN dest_ip IN (
SELECT cidr_block
FROM cluster_network_config
WHERE cluster_name = k8s_cluster_name -- ❌ 이 조건이 무시됨
) THEN 0
ELSE 1
END as is_external
FROM network_raw_data
JOIN cluster_network_config ON ... -- ❌ JOIN도 불가능!
에러: Subqueries are not supported in Materialized Views
ClickHouse MV 문서 한참 뒤적이고, ‘아 이거 안 되네? 진짜 안 되네? 지인짜로 안되네??? ’ 하다가 결국..
MV와 테이블을 2개로 나누는 꼼수를 생각해냈다.
"서브쿼리나 JOIN이 한 번에 두 작업을 처리하는 거라면... 단계를 2개로 쪼개보자!”
-- Stage 1: 원시 데이터 정제만
CREATE MATERIALIZED VIEW network_raw_mv TO network_raw AS
SELECT
serviceName as src,
dest_raw, dest_ip, protocol,
duration_sum, error_count, timestamp,
k8s_cluster_name -- 클러스터 정보 보존!
FROM signoz_traces.signoz_index_v3
WHERE ... -- 필터링 조건들
GROUP BY ...;
-- Stage 2: CIDR 기반 분류 (어떻게든 해보자!)
CREATE MATERIALIZED VIEW network_final_mv TO network_connections AS
SELECT
src, dest, protocol,
-- 여기서 어떻게 cluster_network_config를 참조하지?
FROM network_raw;
해보면서 반신반의 했지만 결과적으로는 의도한대로 잘 동작했고, 1800만 개 레코드가 수천 개로 압축되었다.
사실 애초에 이 문제를 서브쿼리나 join문을 사용하는 접근법 자체가 에러였던 것 같지만, 그래도 어떻게 해결을 했다.
2개의 테이블과 2개의 MV가 순서대로 작동하면서 내/외부 서비스 호출 분류가 가능해졌다.
5. ??? : 니가 뭘 좋아하는지 몰라서 그냥 다 준비했어
그리고 2번째 문제를 마주하게 된다.
분명히 다른 클러스터의 서비스를 호출하는 요청이었지만, 내부 서비스 호출 로직으로 판단되어 is_external = 0 인 난감한 상황..
2번째 mv의 외부 서비스 분류 로직에서 모두 동일한 기준을 사용한 것이 원인이었다.
a클러스터는 a클러스터 만의 cidr을 사용하여 분류해야하는데, a+b+c+d 같이 다른 클러스터의 CIDR도 가져와서 검사를 했다. 그러니까 다른 클러스터를 호출하는 요청이 내부 서비스 호출로 분류된 것이다.
mv가 실행되는 단계에서 클러스터 이름을 기준으로 특정한 클러스터의 cidr만 검사 로직에 사용하면 문제가 없을 것이라 생각했다. 이번에도 해결해야하는 문제는 명확했다.
그런데 우리는 1번째 문제를 마주하며 삽질한 경험이 있다.
(이런 식으로 알고 싶지는 않았지만..) mv로는 서브 쿼리와 join이 불가능하다는 것을 경험으로 체득했다는 의미다.
따라서 다른 방식으로 해결책을 구현해야 했다.
6. 우리는 Dictionary의 시대에 살고 있다.
여기서 딕셔너리를 도입하게 되었다.
딕셔너리는 clickHouse 메모리에 보관되는 일종의 임시 테이블 같은거다.
(DB 용어로 치면 인메모리 캐시 테이블 같은 개념)
주기적으로 source(DB 테이블, 외부 http, 파일)를 바라보고 딕셔너리를 만들어놓을 수 있다.
딕셔너리 사용 장점
- 메모리에 캐시되어서 조회 속도가 빠름 ⚡
- 설정이 바뀌면 자동으로 갱신 🔄
dictGet()함수 하나로 조회 가능! 🎯
사실상 ClickHouse 팀이 “JOIN 쓰고 싶으면 그냥 딕셔너리 써라..” 라고 말하는 듯한 기능으로 보인다!
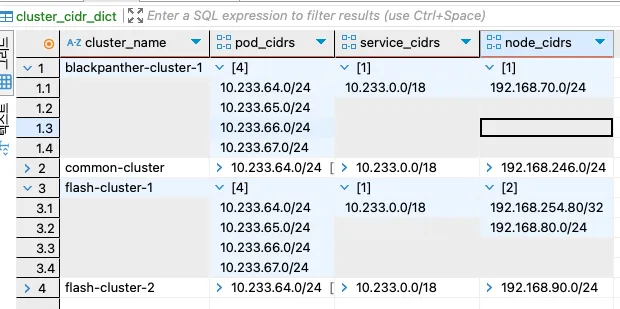
나는 cidr 정보가 담긴 테이블을 source 테이블로 삼아 딕셔너리를 만들었다.
클러스터 이름을 조건으로 node cidr, pod cidr, service cidr을 array 형식으로 저장하여 보관했다.
그리고 이 딕셔너리를 mv 수행할 때 참조하게 하여 자기 클러스터에 해당하는 cidr만 분류 로직에 사용하도록 만들었다.
-- 1단계: CIDR 설정 테이블
CREATE TABLE cluster_network_config (
cluster_name String, -- flash-cluster-1, blackpanther-cluster-1...
network_type String, -- pod_cidr, service_cidr, node_cidr
cidr_block String, -- 10.233.64.0/24, 192.168.254.0/24...
is_active UInt8 DEFAULT 1
);
-- 2단계: Dictionary
CREATE DICTIONARY cluster_cidr_dict (
cluster_name String,
pod_cidrs Array(String), -- 클러스터별 Pod CIDR 배열
service_cidrs Array(String), -- 클러스터별 Service CIDR 배열
node_cidrs Array(String) -- 클러스터별 Node CIDR 배열
)
PRIMARY KEY cluster_name
SOURCE(CLICKHOUSE(
query 'SELECT
cluster_name,
groupArray(CASE WHEN network_type = ''pod_cidr'' THEN cidr_block END) as pod_cidrs,
groupArray(CASE WHEN network_type = ''service_cidr'' THEN cidr_block END) as service_cidrs,
groupArray(CASE WHEN network_type = ''node_cidr'' THEN cidr_block END) as node_cidrs
FROM cluster_network_config
WHERE is_active = 1
GROUP BY cluster_name'
))
LAYOUT(HASHED())
LIFETIME(MIN 300 MAX 600); -- 5-10분마다 자동 갱신!
아 그리고 솔직히 CIDR이 바뀌는 건 노드풀 추가 같은 특수 상황밖에 없어서,, 초 단위 수집은 쫌 오버같았다.
그래서 그냥 5~10분마다 싹 긁어오는 쪽으로 타협했다. 이 정도면 ‘내부 IP인데 외부로 잘못 분류됐다’는 사고를 막을 수 있고, 더 짧게 가져가는 건 리소스 낭비 같아서.
일단 간단한 테스트는 통과 했다.
그래서 실제 일어날 수 있을법한 조건으로 데이터를 수정하고 테스트를 다시 진행했다…
cluster_cidr_dict 상황
is_external 분류 결과
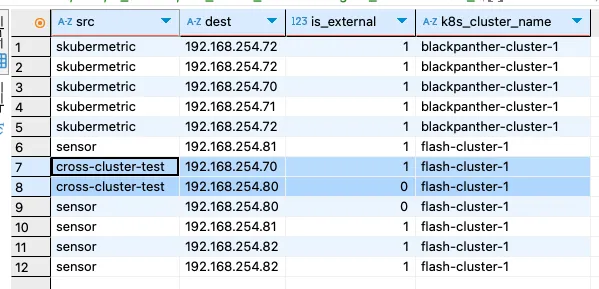
결과 해석
- cross-cluster-test→ 192.168.254.80 (flash-cluster-1 CIDR 체크) → 내부 ✅
- cross-cluster-test → 192.168.254.70 (flash-cluster-1 CIDR 체크) → 없음 → 외부 ✅
- 딕셔너리 기반으로 외부 서비스 분류가 정상 작동함을 확인
이제 외부 서비스 호출을 명확하게 구분할 수 있게 되었다.
기능 개발 하고 QA를 거치면서 예외 케이스들이 또 존재할 수 있겠지만 현재까지는 잘 동작하는 것 같다.
이제는 외부/내부 서비스 호출을 명확히 구분할 수 있게 되었고, 운영자는 네트워크 맵을 보면서 ‘이 IP 대체 뭐냐?’라는 고민을 덜 수 있다. 삽질은 했지만, 덕분에 한층 튼튼한 설계를 갖추게 되었다.
