
1장부터 2-3장까지 2주간 스터디를 통해 새로 배운 개념을 정리해보았다.
Chapter1
1. 객체, 인스턴스, 클래스
객체는 형태만을 의미
인스턴스는 클래스의 구체적인 예시, 만들어낸 결과물
객체vs클래스 : 클래스는 설계도, 객체는 설계도로 구현한 모든 대상
클래스는 틀, 객체는 구현 대상
늘 새로운 인스턴스가 생겼다! 고 말함 (new instance)
클래스 안에 인스턴스가 있는 것!!
2. 알고리즘 vs 디자인패턴
알고리즘 : 파스터 만드는법
디자인패턴 : 디너코스 (전체적인걸 아우르는) 이지만
굳이 알고리즘을 디자인패턴과 나눌 필요가 없다.
3. DB 연결시 사용하는 디자인 패턴
DB 연결할 때 싱글톤패턴을 가장 많이 쓰는데, 클래스가 여러개가 생성되면 db랑 연결할 때 꼬일수도 있어서 그걸 방지하기 위해서 사용한다.
데이터베이스 연결은 일반적으로 하나의 인스턴스만을 필요로 하므로, 싱글톤 패턴은 여러 개의 연결을 생성하는 것을 방지하고, 리소스를 효율적으로 관리하는 데 도움을 준다.
4. 우리(프론트)는 이미 MVC 패턴을 사용해봤다.

브라우저에서 이 버튼을 클릭했을 때 일어나는 일을 생각해 보자. 잘 구현된 버튼이라면 하나의 기능을 수행하는 이벤트가 버튼에 바인딩 되어 있을 것이다. 사용자는 브라우저의 화면에 보여지는 html과 css로 이루어진 View의 버튼을 통해 이벤트를 호출할 것이다. View에서 호출된 이벤트로 Controller가 서버에 데이터를 요청하든지 상태를 직접 변경하든지 Model을 변경한다. Model이 변경되면 View에 변경된 Model을 반영해준다. 이 때 Model은 직접 View를 변경할 수 없고, Controller를 통해 변경해야 한다.
그래서 프론트엔드의 MVC는 View -> Controller -> Model -> Controller -> View 형태이다. Model, View, Controller는 각각의 의존관계를 가지고 있기 때문에 코드를 작성할 때, 유지보수가 쉽고 코드의 흐름을 예측할 수 있어서 원하는 부분을 찾기 수월해진다.
5. 왜 디도스방어를 해주는 걸까?
보통 서버를 여러개 돌리는데, 디독스가 많은 요청을 보내서 다운시키는 거라서 과부하시키기때문에 프록시서버가 그걸 막아준다.
부가설명
프록시 서버는 원격 서버로부터 클라이언트로 오는 트래픽을 중개하므로, 이러한 트래픽 중에 디도스 공격으로부터의 트래픽도 포함될 수 있습니다. 그러나 프록시 서버는 효율적인 트래픽 필터링과 로드 밸런싱을 통해 공격 트래픽을 감지하고 차단하는 역할을 수행할 수 있습니다.
프록시 서버는 일반적으로 클라이언트와 서버 사이에 위치하며, 디도스 공격 트래픽을 분석하여 악성 트래픽을 식별하고 차단할 수 있습니다. 또한 프록시 서버는 클라이언트의 IP 주소를 숨기고, 서버의 IP 주소를 대신하여 통신을 중개하는 기능을 제공하기 때문에, 원격 서버에 직접적으로 접근하는 것보다 디도스 공격에 대한 보호를 더욱 강화할 수 있습니다.
따라서, 프록시 서버는 클라이언트와 서버 사이에서 중개 역할을 수행하면서 디도스 공격을 탐지하고 방어하는 기능을 제공하여 서버의 가용성과 보안을 강화합니다.
6. 캡슐화를 왜 은닉할까?
좋은 클래스의 조건에 중요한 것이 고유정보, 생성자 말고도 또 있다. 정보은닉과 캡슐화라는 개념이다.
정보은닉은 클래스 외부에서 특정 정보에 접근하는 것을 막겠다는 것이다. 개념은 쉬운데 왜 정보에 접근하는 것을 막아야 하는지는 의문이다. 왜 그래야할까? 접근을 허용한다고 했을때 발생 가능한 문제 때문이다.
또 좋은 클래스의 조건 중에 캡슐화라는 개념이 있다. 비슷한 기능은 한 클래스에 모아놓는다는 개념이다. 다시 말해, 클래스가 자신이 감당할 역할만을 충실히 담당하도록 디자인한다는 말이다. 그러나 이것은 모범 답안이라는 것이 존재하지도 않고, 완벽한 캡슐화라는 것도 존재하지 않는다.
캡슐화는 개념만 존재하고 개발자의 역량이 반영되는 것 뿐이다. 그래서 개발자는 이러한 개념이 존재한다는 것을 인지한 상태로, 많은 개별 사례들을 접하면서 익혀나가는 방법 밖에 없다.
데이터 묶는게 캡슐화, 변경하지 않았으면 하는 것을 은닉.
외부에서 접근하지 못하도록, 누구도 바꾸지 못하게, 보여주지 않아야 하니까 감싸야 한다. 한마디로 접근제어!!!
https://analystree.tistory.com/23
7. 리스코프 치환 원칙 vs 의존 역전 원칙
상→ 하가 정상인데 하→ 상이어도 왜 문제없이 돌아가게끔 만들어야 한다는데,
우리가 생각하는 부모, 자식이 아닌 거 같은데?!
p.61에서 dog은 animal 의 자식이고, class Animal , class Dog extends Animal 에서 부모 자식을 바꿔도 출력되는게 똑같아야 된다는 것이다.
부모에 객체가 자식의 객체가 바껴도 똑같아지려면, 부모구조와 자식 구조가 완전히 같아야 한다.
할아버지-아버지-아들 이랑 동물-포유류-고래랑 다른거니까
얘네를 거꾸로 올라가면 전자는 이상하지 않고 후자는 말이 되니까!! 둘은 같은 구조가 아니라는 것.
Chapter2
1. 버스 토폴로지에서만 스푸핑이 가능할까?
아니요, 버스 토폴로지에서만 스푸핑(Spoofing)이 가능한 것은 아닙니다. 스푸핑은 네트워크 공격 기술 중 하나로, 공격자가 자신의 신원을 위조하여 다른 사용자로 가장하거나, 네트워크 패킷의 출발지 주소를 위조하여 불법적인 접근을 시도하는 것을 의미합니다.
스푸핑은 여러 가지 네트워크 토폴로지에서 발생할 수 있습니다. 예를 들어, 스푸핑 공격은 버스, 링, 스타, 메시 등 다양한 토폴로지에서 발생할 수 있습니다. 스푸핑은 주로 ARP 스푸핑, IP 스푸핑, MAC 스푸핑 등의 형태로 나타날 수 있으며, 이러한 공격은 네트워크 보안을 위해 적절한 대책이 필요합니다.
따라서, 스푸핑은 특정한 토폴로지에 제한되지 않고 다양한 네트워크 환경에서 발생할 수 있는 보안 문제입니다.
*주로 버스에서 발생한다는 것뿐!
2. 헤더가 fetch 통신의 header 일까?
아니다!
캡슐화 헤더는 통신 프로토콜 스택의 다른 계층에 추가되는 반면 가져오기 통신 헤더는 웹 통신에 사용되는 HTTP 프로토콜에 따라 다르다.
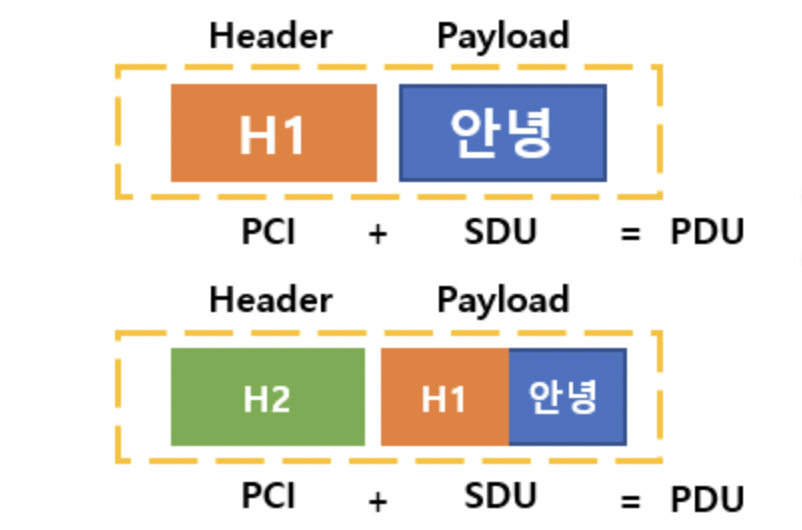
패킷 = 헤더(보안이되고) + 페이로드(보안이 덜되고)
이 헤더가 캡슐화에서의 헤더
헤더는 패킷의 소스 및 대상을 식별하는 반면, 실제 데이터는 페이로드라고 한다.
💿 페이로드란?
데이터가 인터넷을 통해 전송되면, 전송 된 각 장치에는 헤더 정보와 전송되는 실제 데이터가 모두 포함됩니다. 헤더는 패킷의 소스와 목적지를 식별하는 반면 실제 데이터는 페이로드라고합니다. 헤더 정보 또는 오버 헤드 데이터는 전송 프로세스에서만 사용되기 때문에 목적지에 도달하면 패킷에서 제거됩니다. 따라서 페이로드는 대상 시스템에서 수신 한 유일한 데이터입니다.
3. 요청이 있으면 무조건 응답이 있을까?
아니다!
응답신호는 보내지만 return 은 없을 수 있다. (ex. 204) 그래도 이걸 응답으로 본다면 1:1 관계일것.
4. TCP/IP 4계층의 애플리케이션 계층과 개발자도구의 애플리케이션은 같은가?
아니다! TCP/IP 4계층의 애플리케이션 계층과 개발자도구의 애플리케이션은 같은 개념이 아니다.
TCP/IP 모델은 인터넷 프로토콜 스택을 기반으로한 네트워크 통신 모델로, OSI 7계층과는 다른 계층 구조를 가지고 있습니다. TCP/IP 모델에서는 애플리케이션 계층이 최상위 계층에 위치하며, 사용자 애플리케이션과의 인터페이스를 제공합니다. 이 계층에서는 HTTP, FTP, DNS 등과 같은 다양한 응용 프로토콜이 동작합니다. 애플리케이션 계층은 사용자와 네트워크 간의 상호작용을 담당합니다.
반면에 개발자도구의 애플리케이션은 소프트웨어 개발을 위한 도구나 환경을 의미합니다. 이러한 개발자도구의 애플리케이션은 개발자가 코드 작성, 디버깅, 테스트, 프로파일링 등의 작업을 수행하는 데 사용됩니다. 이는 소프트웨어 개발 생명주기의 다양한 단계에서 사용되며, 개발자의 생산성을 높이고 개발 프로세스를 효과적으로 관리할 수 있도록 도와줍니다.
5. 웹브라우저에 google.com 치면 일어나는 과정
사용자가 웹 브라우저를 통해 google.com 을 입력하면 URL 주소 중 도메인 네임 부분을 DNS 서버에서 검색한다. DNS 서버에서 해당 도메인 네임에 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다. 브라우저는 HTTP 프로토콜을 사용하여 요청 메시지를 생성하고 HTTP 요청 메시지는 TCP/IP 프로토콜을 사용하여 서버로 전송된다. 서버는 특정한 포맷(JSON, XML, HTML)으로 response 메시지를 생성하여 다시 브라우저에게 데이터를 전송한다. 브라우저는 response를 받아 파싱하여 화면에 렌더링한다.
DNS : Domain Name System URL의 이름과 IP주소를 저장하고 있는 데이터베이스
