DFS와 BFS는 그래프를 탐색하기 위한 대표적인 두 가지 알고리즘이다.
스택과 큐
우선 위의 두 알고리즘을 이해하기 전에 기본적인 자료구조인 스택과 큐에 대해 알아야 한다.
개념과 원리는 이미 알고 있으니 넘어가도록 하고, 파이썬에서의 사용법에 대해 알아보자.
스택
파이썬에서 스택을 사용할 때에는 별도의 라이브러리를 사용할 필요 없이 기본 리스트 자료형을 사용하면 된다.
stack = []
stack.append(5)
stack.append(2)
stack.append(6)
stack.pop()
stack.append(7)
print(stack)
# 결과는 [5, 2, 7] 이다. 스택의 최하단 값부터 출력된다.큐
파이썬으로 큐를 구현할 때는 collections 모듈에서 제공하는 deque 자료구조를 활용한다.
deque는 스택과 큐의 장점을 모두 채택한 것인데, 데이터를 넣고 빼는 속도가 리스트 자료형에 비해 효율적이며 queue 라이브러리를 이용하는 것보다 더 간단하다고 한다.
deque 객체를 리스트 자료형으로 변환하고자 한다면 list() 메서드를 사용하도록 하자.
from collections import deque
q = deque()
q.append(5)
q.append(2)
q.append(6)
q.popleft()
q.append(7)
print(q)
# 결과는 deque([2, 6, 7]) 이다. 먼저 들어온 순서대로 출력한다.
print(list(q))
# 결과는 [2, 6, 7] 이다.
q.reverse()재귀함수
재귀함수 (recursive function) 란 자기 자신을 다시 호출하는 함수를 의미한다.
보통 파이썬 인터프리터는 호출 횟수 제한이 있기 때문에 재귀 함수의 호출 종료 조건을 반드시 명시해 주어야 한다.
컴퓨터 내부에서 재귀 함수의 수행은 스택 자료구조를 이용한다. 컴퓨터 구조 측면에서 보자면 연속해서 호출되는 함수는 메인 메모리의 스택 공간에 적재되기 때문이다.
def factorial(n):
if n <= 1:
return 1
return n * factorial(n-1)
print(factorial(5))
# 결과는 120
# 5 * fac(4)
# -> 5 * (4 * fac(3))
# -> 5 * (4 * (3 * fac(2)))
# -> 5 * (4 * (3 * (2 * fac(1))))DFS
DFS는 Depth-First Search, 즉 깊이 우선 탐색으로, 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
그래프는 노드(Node, Vertex)와 간선(Edge)으로 이루어져 있다. 간선에는 거리 정보가 포함되어 있을 수도, 없을 수도 있다.
DFS는 앞서 말한 스택 자료구조를 사용한다.
동작과정을 살펴보면 다음과 같다.
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없다면 스택에서 최상단 노드를 꺼낸다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
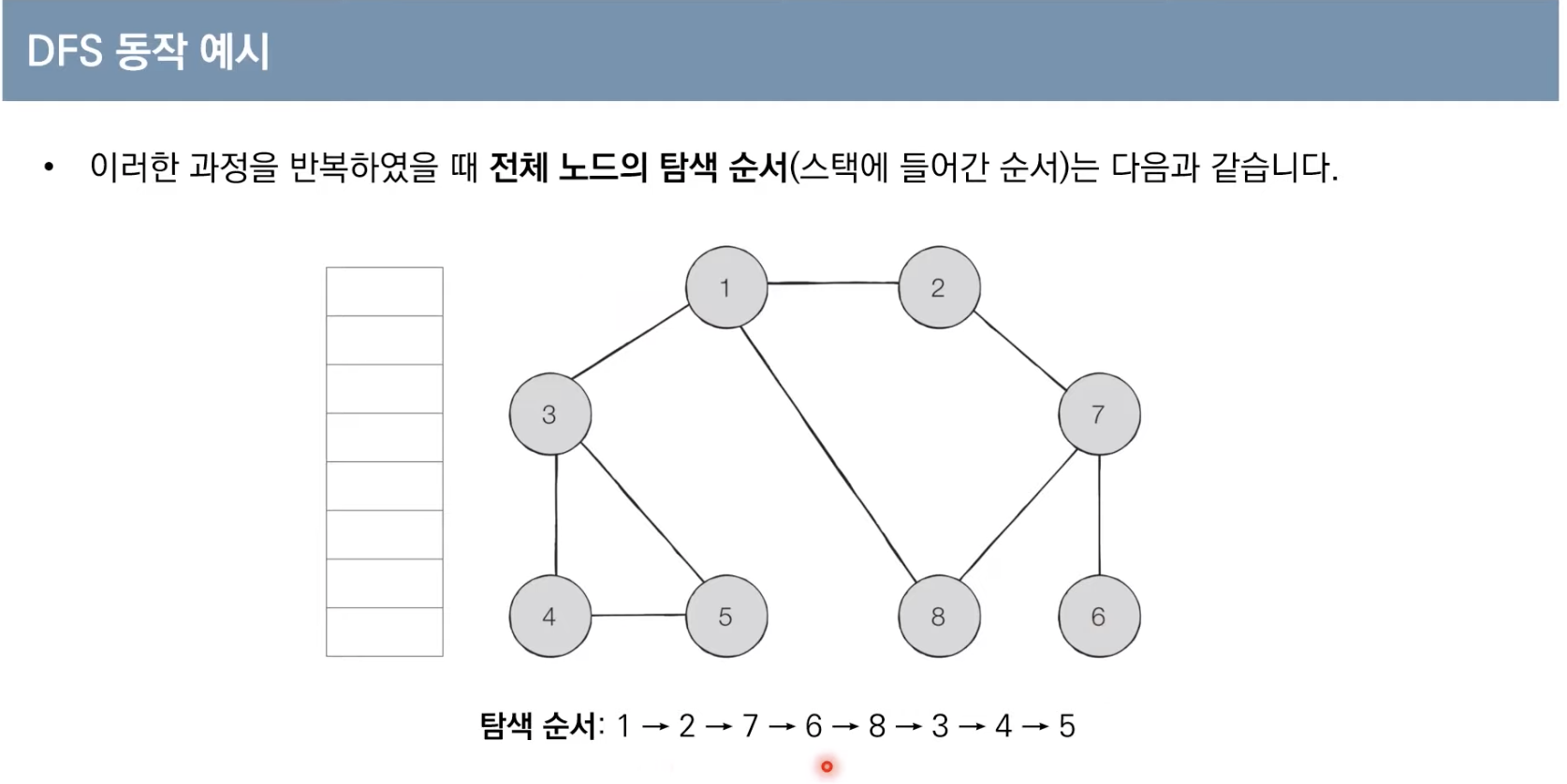 1. 1번, 2번, 7번, 6번이 순서대로 스택에 쌓인다. (1, 2, 7, 6)
1. 1번, 2번, 7번, 6번이 순서대로 스택에 쌓인다. (1, 2, 7, 6)
2. 6번의 인접노드 중 방문하지 않은 노드가 없기 때문에 6번을 꺼낸다. (1, 2, 7)
3. 7번의 인접노드 중 방문하지 않은 8번 노드가 스택에 쌓인다. (1, 2, 7, 8)
4. 8번의 인접노드 중 방문하지 않은 노드가 없기 때문에 8번을 꺼낸다. (1, 2, 7)
5. 7번과 2번도 마찬가지 이므로 순서대로 꺼내진다. (1)
6. 1번의 인접노드 중 방문하지 않은 3번부터 차례대로 4번과 5번까지 스택에 쌓인다. (1, 3, 4, 5)
7. 5번의 인접노드 중 방문하지 않은 노드가 없기 때문에 5번을 꺼낸다.
8. 4번, 3번, 1번 모두 순서대로 꺼내진다.
9. 따라서 탐색 순서는 1, 2, 7, 6, 8, 3, 4, 5 이다.
def DFS(graph, v, visited):
# 현재 노드를 방문처리 -> 핵심 로직 처리 구간
visited[v] = true
print(v, end=' ') # 핵심 로직 처리
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
graph = [
[],
[2, 3, 8] # 1번 노드와 인접한 노드들
[1, 7], # 2번 노드와 인접한 노드들
[1, 4, 5], # 3번 노드와 인접한 노드들
[3, 5], # 4번 노드와 인접한 노드들
[3, 4], # 5번 노드와 인접한 노드들
[7], # 6번 노드와 인접한 노드들
[2, 6, 8], # 7번 노드와 인접한 노드들
[1, 7] # 8번 노드와 인접한 노드들
]
visited = [False] * 9
dfs(graph, 1, visited)
# 결과는 1 2 7 6 8 3 4 5BFS
BFS는 Breadth-First Search, 즉 너비 우선 탐색으로, 가까운 노드부터 탐색하는 알고리즘이다. 최대한 멀리 있는 노드를 우선으로 탐색하는 방식으로 동작하는 DFS와는 반대로 동작한다.
BFS는 앞서 말한 큐 자료구조를 사용한다.
동작과정을 살펴보면 다음과 같다.
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내고 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
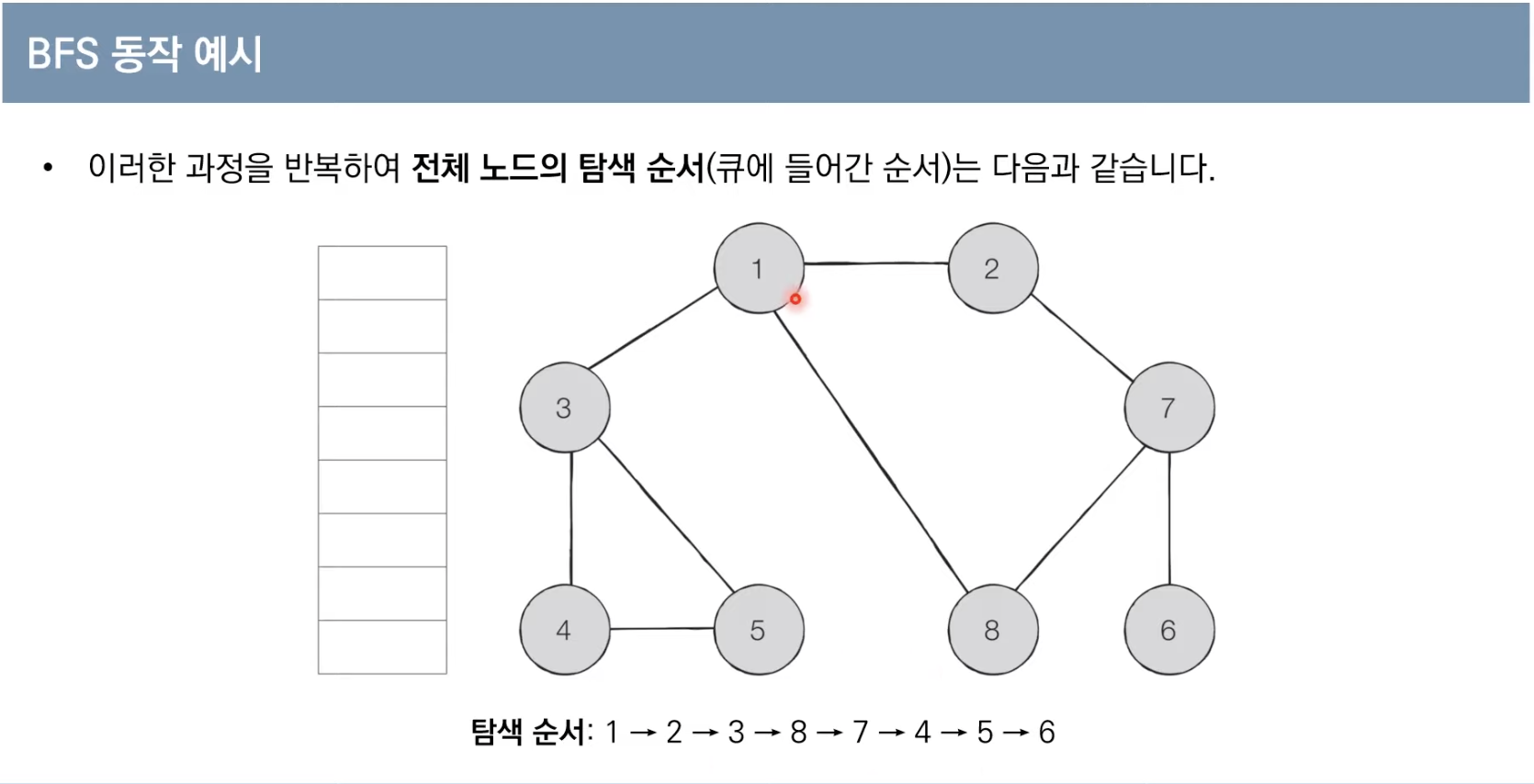
1. 1번 노드를 큐에 삽입하고 방문 처리한다. (1)
2. 1번 노드를 꺼내면서 그와 인접한 2, 3, 8을 큐에 삽입하고 방문 처리한다. (2, 3, 8)
3. 2번 노드를 꺼내면서 그와 인접한 7을 큐에 삽입하고 방문 처리한다. (3, 8, 7)
4. 3번 노드를 꺼내면서 그와 인접한 4, 5를 큐에 삽입하고 방문 처리한다. (8, 7, 4, 5)
5. 8번 노드를 꺼낸다. (8번 노드와 인접한 노드 중 방문하지 않은 노드가 없기 때문) (7, 4, 5)
6. 7번 노드를 꺼내면서 그와 인접한 6번 노드를 큐에 삽입하고 방문 처리한다. (4, 5, 6)
7. 4, 5, 6의 인접 노드 중 방문하지 않은 노드가 없으므로 차례대로 꺼낸다.
8. 따라서 탐색 순서는 1, 2, 3, 8, 7, 4, 5, 6 이다.
from collections import deque
def bfs(graph, start, visited):
# 탐색 시작 노드를 큐에 삽입 후 방문처리
q = deque([start])
visited[start] = true
while q:
# 하나씩 꺼내면서 핵심 로직 처리 구간
v = q.popleft()
print(v, end=' ')
# 인접 노드 중 방문하지 않은 것은 큐에 삽입 후 방문 처리
for i in graph[v]:
if not visited[i]:
q.append(i)
visited[i] = True
graph = [
[],
[2, 3, 8] # 1번 노드와 인접한 노드들
[1, 7], # 2번 노드와 인접한 노드들
[1, 4, 5], # 3번 노드와 인접한 노드들
[3, 5], # 4번 노드와 인접한 노드들
[3, 4], # 5번 노드와 인접한 노드들
[7], # 6번 노드와 인접한 노드들
[2, 6, 8], # 7번 노드와 인접한 노드들
[1, 7] # 8번 노드와 인접한 노드들
]
visited = [False] * 9
bfs(graph, 1, visited)
# 결과는 1 2 3 8 7 4 5 6 핵심 로직 처리 구간
dfs 함수를 호출할 때마다, 인수로 포함되는 i 값이 스택에 쌓인다고 생각하자. (재귀함수는 스택 자료구조 사용)
즉, 스택에 값이 들어갈 때마다, dfs가 호출될 때마다 핵심 로직을 처리한다고 생각하자.
bfs는 큐에서 값이 하나씩 나올 때마다 핵심 로직을 처리한다고 생각하자.
참고
해당 블로그는 나동빈님의 '이것이 취업을 위한 코딩 테스트다. with 파이썬' 교재와 유튜브 강의를 참고하여 작성되었습니다.
