Recent advances in deep learning based dialogue systems: a systematic survey (Ni et al., 2023)
Dialogue System
Dialogue Models Survey Paper
1 Introduction
Market Size
- 2021년 기준 USD 2.6 bln, 2024년 USD 9.4 bln (CAGR 29.7%) 예상
Categories of Dialogue Systems
- Task Oriented Dialogue System (TOD): solve specific problems
- Open-domain Diaogue Systems (OOD): chat with users without task and domain restrictions & data driven
mapping from user message
to agent response
where denotes each token of user or response message
in many cases, where is external knowledge or database
- TOD pipeline (traditional): Natural Language Understanding, Dialogue State Tracking, Policy Learning, Natural Language Generation
- TOD SoTA: end-to-end system for better optimization
- OOD categories: generative, retrieval-based, ensemble
- generative apply seq2seq, map user message & dialogue history into response sequence not appeared in the training corpus
일관성이 부족 & 멍청한 답변 생성 - retrieval: select pre-exiting response from response set
일관성은 충족하나 응답set이 유한하므로 낮은 일관성 보일 수 있음 - ensemble: retrieval to choose the best among generated responses / generative used to refine retrieved responses
- generative apply seq2seq, map user message & dialogue history into response sequence not appeared in the training corpus
Traditional approach
- Rule-based: 쉽지만, scenario가 한정됨
- non-neural ML: template filling, flexible하지만 성능 별로, scenario 한정
2 Neural models in dialogue systems
2.1 CNN (MG)
- word 많이 쓰긴 하지만, phrase, sentences, paragraph level에서도 사용 가능
- CNN은 보통 hierarchical feature extractor로 사용: user message와 response message를 CNN 통과시켜 encoding 한 후 similarity matrix 만드는 등 (response retrieval task)
- 어쨌거나 sequential한 것에 대해 대응이 안 되기 때문에 사용되지는 않음
2.2 RNN & Seq2Seq (MG)
- NLP의 핵심은 data point에 대한 processing & analyzing인데, CNN은 data point를 independently 처리함 & CNN은 fixed length input에 적합함
- HMM은 sequence가 길어질수록 너무 커짐
2.2.1 Jordan-type and Elman-type RNNs
- long-term dependency problem (gradient vanishing / explosion)
2.2.2 LSTM
2.2.3 GRU
2.2.4 Bi-RNN
2.2.5 Vanilla Seq2Seq
- TOD w/ RNN encoder: dialogue context, dialogue state, nowledge base entried, domain tags
- OOD w/ RNN encoder: history encoders, encoding outside knowledge sources
- RNN이 dialogue embedding 학습에 사용되기도, 이 때 BERT 등 SoTA model보다 일부 task에 대해서는 더 나은 성능을 보여주기도
2.3 Hierarchical recurrent encoder-decoder (HRED) (MH)
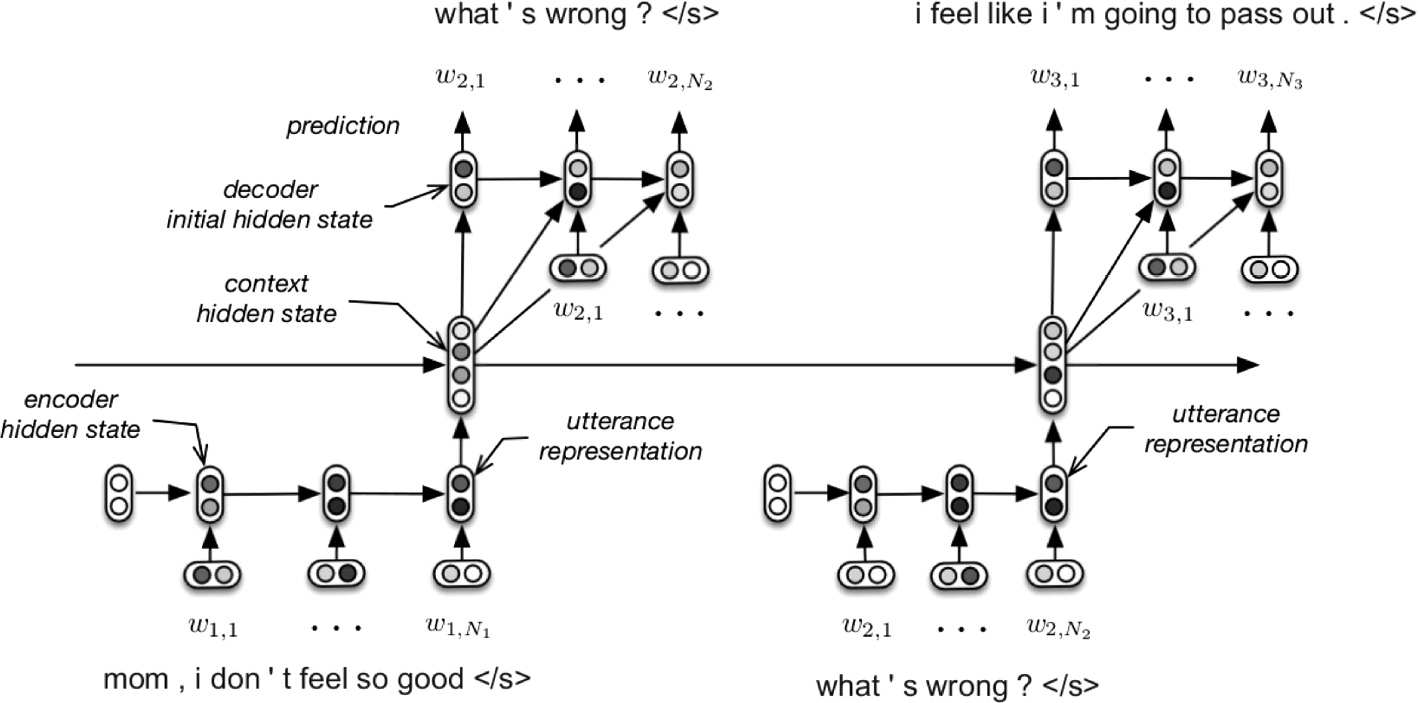
- context-aware seq2seq model
- historical query에 aware하고 rare & high quality result 도출 가능
- multi-turn 방식인 dialogue system에 적합: token level과 turn level을 모두 고려
- VHRED는 HRED에 decoding단에서의 latent variable sampling step을 추가하였음
- 이후 attention을 적용하거나, hierarchy를 좀 더 많이 가져가는 등의 variation 생김
2.4 Memory networks (MG)
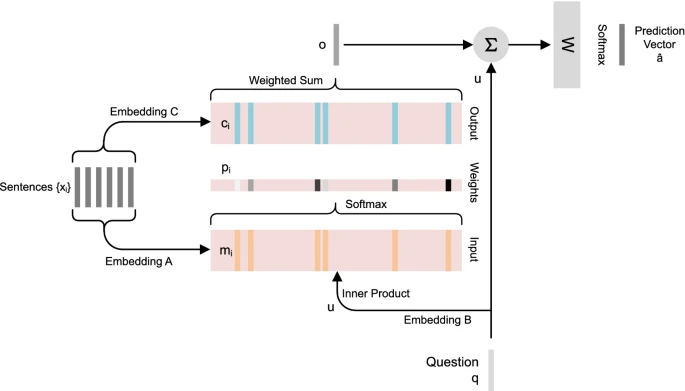
- past experiences / outside knowledge source 처리에 중요 (hard disk의 역할)
- RNN 계열의 memory module 은 너무 작아서 compress fact & reusing에 불리함
- memory network는 external knowledge base를 사용하는 task(TOD, QA etc.)에 적합함
- memory network modules:
- I: input memory fact를 embedded representation으로 mapping
- G: pdate of the memory module deciding
- O: input representation & memory representation에 condition된 output generation
- 위를 본딴 3 stage: weight calculation, memory selection, final prediction으로 구성
2.4.1 Weight calculation
weight
where for input memory set, for memory representation (by model A)
for input query embedding (by model B)
stands for weight corresponding to each input memory
2.4.2 Memory selection
selected memory vector
where is embedded vectgor of input memory (by model C)
2.4.3 Final prediction
probability vector
2.5 Attention (MG) & transformer (MH)
2.5.1 Attention
- memory network와 비슷하긴 하지만, memory model은 cosine distance를, attention은 ff layer를 사용한다는 점에서 similarity model이 다름
- attention을 hierarchical하게 적용하거나, seq2seq + attention
2.5.2 Transformer
- transformer를 stack하거나 하는 식으로 transformer blocks를 사용하는 경우가 있었고, GPT & BERT를 사용
2.6 Pointer Net and CopyNet
2.6.1 Pointer Net (MH)
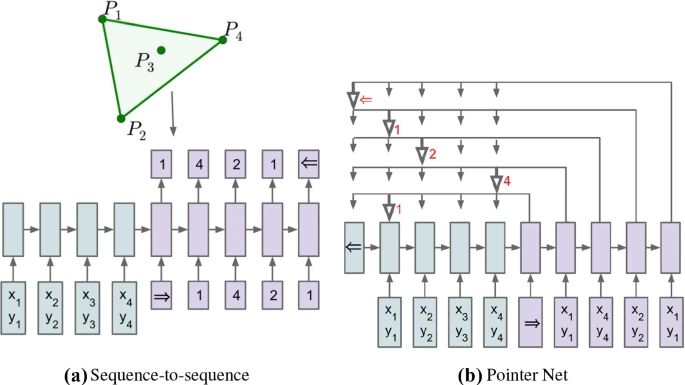
- dialogue system이나 QA에서는 user message의 한 부분을 '그대로 따오는' 모듈이 필요하며, 이는 Pointer Net으로 input sentence에서 tokens를 그대로 따오는 것으로 실현하였음
- attention based seq2seq에서 약간의 수정: weighted sum of encoder hidden state에서 token distribution 구하는 대신, distribution에 normalized weights ()를 사용
where denotes grount target sequence, denotes input sequence
- 위와 같은 변형은 token prediction (attention) problem에서 position prediction problem으로 바뀌는 것
2.6.2. Copy Net (MG)
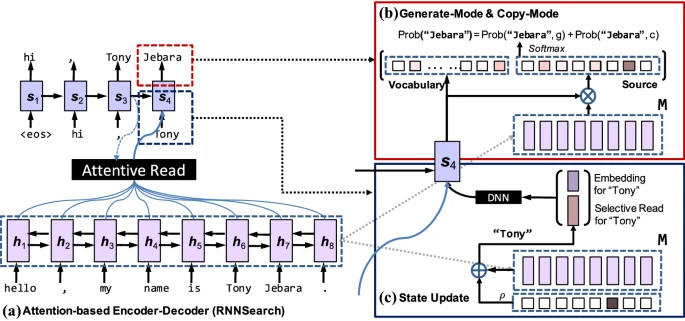
- 때로는 pointer net의 일을 하면서도 input sequence에 없는 단어를 generate해야 할 필요도 있음
- seq2seq encoder와 동일 + attention-based decoder에서 약간의 변용
where denote for decoder hidden state, predicted token, weighted sum of encoder hidden states, encoder hidden states
for generate-mode, copy-mode
- terminology나 external knoweldge source, knowledge-grounded or TOD에 적합함
- 실제 모델에서 OOV를 잡아내거나, internal utterance (dialogue history)와 external utterance (similar cases) 를 잡아내는 데에 사용하였음
- Ji C, Zhou X, Zhang Y, Liu X, Sun C, Zhu C, Zhao T (2020) Cross copy network for dialogue generation. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), association for computational linguistics, online, pp 1900–1910, https://doi.org/10.18653/v1/2020.emnlp-main.149
2.7 Deep reinforcement learning models (MG) and generative adversarial networks (MH)
2.8 Knowledge graph augmented neural networks (MH)
- entity와 relation을 lower dimension space에서 represent하고, NN을 써서 relevant fact를 retrieve함
- 2 categories: structure-based representation, semantically-enriched representations
- 후자는 combine semantic information into representation of entities and relations
- neural retireval models (2 categories): distance-based matching, semantic matching
3 Task-oriented dialogue systems
-
4 modules:
- Natural Language Understanding: user message를 semantic slot으로 변경, classification of domain & user intention
필수는 아니고, NLU가 빠지면 original error와 module 간 error를 줄일 수 있음 - Dialogue State Tracking: dialogue state를 current input과 dialogue history에 대해 calibrate함, dialogue state는 related user actions, slot-value pairs를 포함
- Dialogue Policy Learning: DST에서의 calibrated dialogue states를 이용, dialogue agent의 next action을 결정
- Natural Language Generation: selected dialogue action을 natural language로 재구성함
- Natural Language Understanding: user message를 semantic slot으로 변경, classification of domain & user intention
-
DST와 DPL은 Dialogue Manager로 묶이고, TOD의 핵심임
-
보통 knowledge base와 함께 감
3.1 NLU
- NLU quality가 response quality를 좌지우지함
- user message를 semantic slots로 넣어버리고 classification을 수행
- NLU task: domain classification, intent detection, slot filling(tagging -> seq2seq task)
- e.g. predicted domain: movie & intent: find_movie
- e.g. "Golden Village": B_desti, I_desti 와 같은 식으로, Inside-Outside-Beginning tagging (NER 식으로)
- Techniques for domain classification & intent detection: RNN과 CNN의 혼합, BERT+LSTM 등
- Techniques for slot filling(semantic tagging), CRF, LSTM 등
- Unifying 3 tasks: MTlearning 하여 unseen domain에 대해서도 zero/few shot setting에서 robust하도록 한 바 있음, capsule-based NN을 사용한 경우가 몇 있음
- novel approach로는 NLU와 NLG를 묶어서 dual-supervised learning으로 처리한 바 있음
3.2 DST
- DST의 역할: first module of a dialogue manager로써, whole dialogue history에 기반하여 각 turn마다 user goal과 related details를 track하고, Policy Learning module에 어떤 정보를 전달할 지 결정함
- NLU와의 차이점: DST는 classify나 tagging하지 않음, 대신 pre-existing slot list에 value를 채울 뿐..
- Dialogue state components: Goal constraint corresponding with informable slots, Requested slots, Search method of current turn
- predefined list를 유지한다면, multi-class or multi-hop classification task로 분류할 수 있음: 당연히 complexity는 상승
- 최근 트렌드는 fixed slot value list를 유지하지 않고, DST module이 raw text나 context에서 directly value를 generate함
- target domain change하는 상황에서 flexible
