Hier-SPCNet: A Legal Statute Hierarchy-based Heterogeneous Network for Computing Legal Case Document Similarity (SIGIR, 2020)
LegalAI Papers Review
a.k.a. Hier-SPCNet 논문, 피인용수 14(Jan.3.2023 기준)
how to draw hierarchical graph with python: https://stackoverflow.com/questions/29586520/can-one-get-hierarchical-graphs-from-networkx-with-python-3
코멘트
인용판례뿐 아니라 참조조문도 써서 PCNet보다는 훨씬 적용가능성이 높을 듯. graph embedding하는 것만 익히면 한 번 해볼 만 한 것 같은데?
조문이 조문을 cite하는 게 뭔지 곰곰이 생각해봤는데 '준용'이라는 게 있었다. e.g. 제11장 무고의 죄 제157조(자백, 자수) 제153조(제10장 위증과 증거인멸의 죄 제153조(자백, 자수))는 전조(제156조(무고))에 준용한다
Abstract
- network based similarity methods: e.g. PCNet 등은 판례 간의 인용례만을 고려하였음
- 그러나 실제로는 hierarchy of legal statute that are applicable in a given legal jurisdiction에 대한 고려가 부족
- 본 연구는 PCNet과 hierarchy of legal statute를 합쳐서 "Hier-SPCNet"이라 하는, heterogeneous network를 만듦
- 이는 기존의 인용판례 + statute 간의 hierarchy link를 결합한 것임 - 인도 대법원 데이터에 적용한 결과, PCNet보다 나았으며, text-based approach에 대한 보완수단으로 쓰일 수 있을 것으로 기대함
1. Introduction
- 영미법계에 대한 설명 & why unsupervised method
인도, 호주, 미국, 영국 등과 같은 영미법계에서는 two primary sources of law가 있음: (1) 성문법전(statutes or written laws), (2) 주요 법원(Supreme Court, High Courts 등 important courts)에서 판시한 사항(precedents, prior cases). 두 번째 선행판례 때문에 prior-case search, recommendation 등 legal IR이 필요함
similarity 학습에 supervised method 사용하는 것은 gold standard가 수천 개 단위로 필요한 이유 때문에 여의치 않음. 그래서 unsupervised method가 선호됨
- 이전 PCNet의 한계와 key idea
network-based method와 text-based mehtod가 있는데, network-based method는 PCNet에 의존(PCNet에 대한 내용은 여기 참조)하는데, 법조문(statute)를 고려하지 않는다는 치명적인 문제가 있음. statutes는 상술한 (1) written laws를 나타내는데 이게 legal document similarity를 잡아낼 수 있다는 idea임. PCNet에서의 참조판례 & 법조문까지 합쳐서 Hier-SPCNet (Hierarchical Statute and Precedent Citation Network)를 만들었음
graph embedding algoritm인 Metapath2vec을 사용해 heterogeneous Hier-SPCNet에 적용. key idea는 두 판례가 같은 법조문/판례를 인용하거나, network 안에서 similar하지만 다른 법조문/판례들을 인용한다면, 두 판례들은 비슷한 legal issue를 다루고 있으며, document similarity의 strong signal로 사용됨
- experiment
인도 대법원(Supreme Court)의 판례쌍 100개를 legal expert가 annotate한 것 사용. PCNet만 사용한 것보다는 나음. SoTA text-based approach(Mandal, A., Chaki, R., Saha, S., Ghosh, K., Pal, A., & Ghosh, S. (2017, November). Measuring similarity among legal court case documents. In Proceedings of the 10th annual ACM India compute conference (pp. 1-9)., document embedding 사용)하고도 비교했음. network-based, text-based 둘 다 써서 multiple aspect를 제공할 수 있을 것으로 보임
영미법계의 두가지 큰 축인 statutes & precedent를 모두 사용한 첫 연구이며, 본 연구는 인도의 판결을 대상으로 사용하였지만, 법률(statutes/codes)를 사용하는 어떠한 사법 시스템에 대해서도 적용 가능할 것으로 보임(본 연구에서는 프랑스를 예로 들었는데, 프랑스는 독일법계civil law system에 더 가깝다고 함)
2. Existing Network-based Methods for Legal Document Similarity
- PCNet에 대한 간단한 설명과 거기서 차용한 것들
vertices: case documents
edge : 이 을 인용
fig1의 grey box가 PCNet
Bibliographic Coupling: 두 판결의 out-citations(한 판결이 인용한 다른 판결들)을 jaccard similarity로 계산한 것

Co-citations: in-citations를 대상으로 한 jaccard similarity
Dispersion(Minocha, A., Singh, N., & Srivastava, A. (2015, May). Finding relevant indian judgments using dispersion of citation network. In Proceedings of the 24th International Conference on World Wide Web (pp. 1085-1088).: 두 판결의 out-citations가 어느정도까지 similar한지(e.g. occurs in the same community/cluster) 측정함. NetworkX에 dispersion 구하는 함수 있어서 이를 이용해 구했음
3. Proposed Augmentation of PCNet with Legal Statute Hierarchy

3.1 Constructing Hier-SPCNet
- Modeling the hierarchy of statutes
인도의 경우, acts → parts → chapters → topics → sections/articles 순으로 나뉜다고 함(한국의 '편장절항호목'과 비슷한 듯)
e.g. Constitution of India, 1950 → Part IV: The States → Chapter III: The State Legislature → Topic: Disqualification of members → Section 192: Decision on questions as to disqualification of members
위와 같은 구조가 불완전할 때는 act → sections/articles로 가는 등 유동적으로 구성한 듯
e.g. Dowry Prohibition Act, 1961 → Section 3: Penalty for giving or taking dowry
statute에서 hierarchy를 뽑아내서 hierarchical structure of nodes(act / parts / chapters / topics / sections)와 hierarchy link로 구성
regex 이용해 각 판결에서 statute/precedent citation을 뽑아냄
- Hier-SPCNet
node: case documents, acts, parts, chapters, topics, sections/articles (total 6 types)
edge: hierarchy links, citation links (total 2 types)
Citation edges
document → document: if one document cites another document(PCNet)
document → statute: if a document cites a statute(e.g. or )
statute → statute: if a statute cites another statute(e.g. )
Hierarchy edges
법조문 사이의 상하관계(e.g. ), 상술하였듯 모든 hierarchy가 동일하지는 않음
3.2 Document similarity using Hier-SPCNet
graph embedding techniques인 Node2Vec과 Metapath2Vec을 Hier-SPCNet 구축에 사용하였음. 각 node를 vector space에 매핑시켜서 representation 내지 embedding으로 만들고 node embedding 간 cosine similarity를 계산하는 방식으로 이루어짐
- Node2Vec
PCNet과 Hier-SPCNet에 모두 Node2Vec 사용해 node embedding 구성. homogeneous graph를 가정하는 Node2Vec에 Hier-SPCNet은 맞지 않을 수 있긴 한데 어쨌든 진행
- Metapath2Vec
heterogeneous networks(node, edge 모두 different type 내지 different semantics를 지칭)에 Metapath2Vec을 사용. metapath는 두 노드 사이의 edge가 different semantic을 가질 수도 있는 edge를 의미함. Hier-SPCNet에서는 두 판결이 동일하거나 연관된 법조항을 인용하는 14개의 서로다른 metapath를 정의하는데, 이러한 metapath에서 signal of similarity를 infer할 수 있음. 몇몇 metapath는 다음과 같음
doc-sec-doc: 두 판결이 같은 section/article을 인용 e.g. , 가 를 인용
doc-sec-topic-sec-doc: 두 판결이 다른 sections/articles 인용하지만, 두 sections/articles가 같은 topic에 속해있을 때 e.g. cites section and cites and , 가 에 속해있음
doc-sec-topic-chap-topic-sec-doc: 위와 같은데, sections/articles가 같은 chapter에 속해있는 경우
doc-doc-doc: 두 판결이 같은 판결을 인용하는 경우, PCNet으로 Metapath2vec을 만들면 이게 나옴
4. Experiments and Results
4.1 Experimental setup
- Dataset
인도 대법원(Supreme Court of india) & statutes in the Indian judiciary(https://www.westlawindia.com 에서 크롤링했음)
1,806 판례, 128 법조항(& hierarchies) 사용했으며, 22,566 nodes & 31,309 edges 생성. PCNet은 1,806 nodes(판례) & 542 edges
- Developing gold standard for document similarity
2명의 legal experts(로스쿨 학생)가 100개 판례쌍의 유사도를 0에서 1점 사이로 annotate했음. 불합치 별로 없었다고 함. 두 점수를 평균냈음
- metrics
100개 쌍에 대해 전문가들이 낸 점수들과 Hier-SPCNet의 점수들 사이 pearson correlation coefficient 사용
4.2 Results: PCNet vs Hier-SPCNet
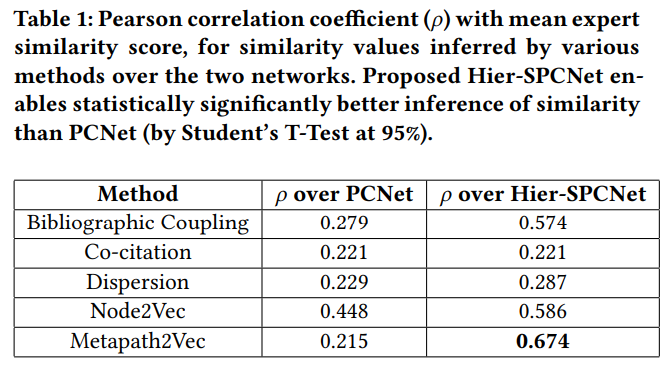
Hier-SPCNet의 BC score, dispersion, Node2Vec, Metapath2Vec의 pearson correlation이 PCNet보다 더 높았음. CC score는 PCNet과 Hier-SPCNet 동일
주) 본 연구에서 BC score 계산할 때는 common out-cited statute까지 고려했고, CC score 계산할 때는 자연히 statute의 in-citations을 계산하지 않으므로 BC score의 결과는 차이나고, CC socre의 결과는 차이나지 않을 수밖에 없음
Node2Vec이 homogeneous network에 대해 사용되기는 하지만, leaf nodes(sections/articles)이 구조적으로 비슷해서 PCNet에 법조항의 hierarchical structure 낑겨넣어도 괜찮았음
Hier-SPCNet에서 가장 높았던 것은 Metapath2Vec
5. Comparing Network-based and Text-based Similarity
Mandal, A., Chaki, R., Saha, S., Ghosh, K., Pal, A., & Ghosh, S. (2017, November). Measuring similarity among legal court case documents. In Proceedings of the 10th annual ACM India compute conference (pp. 1-9).에서 한 대로 large corpus of Indian Supreme Court case judgement(단, 상술한 100개 pair의 판례는 포함하지 않음)를 대상으로 doc2vec을 구축하고, document pair의 embeddings에 대해 representation의 cosine similarity를 구하였음
- Comparing network-based and text-based similarity
Doc2Vec의 pearson correlation은 0.734로, Hier-SPCNet의 Metapath2Vec(0.674)보다 높았음(다만, p = 0.34). 100개 쌍 중에서 58 case는 network-based approach가 text-based approach보다 expert score에 비해 더 근접했음. 이후 case study
Hier-SPCNet이 text-based보다 나은 점은 explainability
- Combining network-based and text-based similarity

case study를 보면 text-based method와 network-based method는 서로를 보완하는 관계임. 본 연구진은 두 method의 점수를 평균하거나, max하거나 하는 식으로 두 method를 결합했는데, table2를 보면 나쁘지는 않았던 듯함
6. Conclusion
Hier-SPCNet은 hierarchy of statute와 case citations를 모두 고려하여 network embedding으로 만들어놓은 network이고, statute의 inherent domain knowledge를 녹여낸 첫 번째 연구임. 본 연구는 hierarchy of statute가 있는 어떤 사법시스템에도 적용가능함
