Interactive Mongolian Question Answer Matching Model Based on Attention Mechanism in the Law Domain (2022)
LegalAI Papers Review
0. Abstract
Mongolian QA라는 QA task가 아니라 몽골어 QA on legal domain임!! Interactive Mongolian Question Answer Matching Model (IMQAMM)을 제시하는데, attention에 기반하였음
key part는 1. interactive information enhancement & 2. max-mean pooling matching.
-
Interactive information enhancement는 1-1) sequence enhancement와 1-2) multi-cast attention을 포함함. 1-1) Sequence enhancement는 subsequent encoder와 함께 enhanced sequence representation을 제공하고, 1-2) multi-cast attention은 여러 개의 attention mechanism을 통해 scalar features를 생성함
-
Max-Mean pooling matching은 aggregation을 위해 matching vectors를 잡아냄
그 외에도 Mongolian morpheme representation 만들었음
- take-home message
한국어도 몽골어와 비슷한 점 공유(data 부족, sparse data)하니까 IMQAMM의 여러 module 차용할 수 있지 않을까?? 다만 BERT 있으니까 BERT로 바꿔껴보고
그리고 text matching에 관해서 related work 좀 더 상세히 보면 좋을 듯
1. Introduction
question answer matching은 text matching의 일부이고, text matching은 IR, Natural Language Inference (NLI), QA, dialogue system에 이르기까지 다양하게 적용될 수 있음
IR에 관해서는, text matching은 query와 document간의 relevance를 계산해서 relevant document를 셀렉할 수 있게 함. NLI에서는 premise가 hypothesis를 infer할 수 있는지 판단하는 데에 쓰이고, QA에서는 given Q에 most relevant A를 찾는 데에 쓰임.
NN이후로 text matching은 2가지로 나뉘는데, representation-based match와 interatction-based match임. representation-based match는 2개 sequence를 같은 ebmedding space의 representation으로 만드는 데에 주안점이 있고, 후자 interaction-based match는 sentence pair의 information을 계속 맞춰보면서 representation learning process를 향상시키는 것. 보통 interaction-based match가 representation-based match보다 더 잘 맞는데, 이는 representation-based match는 lexcial & syntactic information이 부족하기 때문. 반면, interactive information은 sentence pairs의 interactive information에서 이득을 취할 수 있기 때문. 그래서 요즈음은 interaction-based matching이 text matching의 대세임
몽골어 legal QA system이 지지부진한 이유: lack of labeled corpus & data-sparse problem (몽골어는 한국어와 같이 교착어agglutinative language임)
본 논문에서 몽골어 law domain QA dataset을 만들고, interactive information enhancement와 max-mean pooling matching을 결합한 IMQAMM를 제안함.
Interactive information enhancement는 feature vectors를 cocnat해서 enhanced sequence representation을 만들고, compression function을 사용해서 feature vectors를 scalars로 만드는데, 이 과정에서 data-sparse issue 때문에 multiple attention mechanism이 사용됨. Max-mean pooling matching은 형태소 representation 사이에 maximum과 average cosine similarities를 계산함
2. Related Work
QA에서 Siamese LSTM을 사용한 MaLSTM이 많이 사용되었다는데(Mueller and Thyagarajan, 2016), 코드는 링크참조
previous works, 뭐 좋다 이거야 그런데 low-resource agglutinative language(like 몽골어, 한국어)에는 적합하지 않음.
3. Model Architecture

3.1 Input Layer
원래는 몽골문자를 latin alphabet으로 바꾸고
-> proofreading: 몽골문자 한 글자가 latin alphabet의 여러 개로 대응되므로 이 문자가 맞는가하는 것을 확인
-> suffix segmentation 진행해서 independent taining unit을 만듦
몽골어 morpheme embedding은 Skip-gram을 사용한 Word2Vec으로 구성하였음
3.2 Context Encoding Layer
bi-LSTM 사용
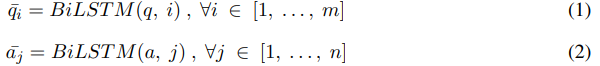
3.3 Interaction Layer
LSTM에 기반한 sequence enhancement가 사용된 interactive information enhancement을 소개하고, 4가지 attention mechanism variants가 사용된 multi-cast attention을 소개함
3.3.1 Sequence Enhancement
ESIM(Chen elt al., 2017)에 영향을 받아, non-parameterized comparison strategy를 sequence enhancement에 적용함.
일단 첫번째로, BiLSTM으로 encoding된 Q-A pair의 similarity matrix 계산
(shape은 len(q) x len(a) 혹은 len(a) x len(q)가 될 것임)

soft alignment attention을 사용, attentive vector of a weighted summation of the other hidden states를 계산
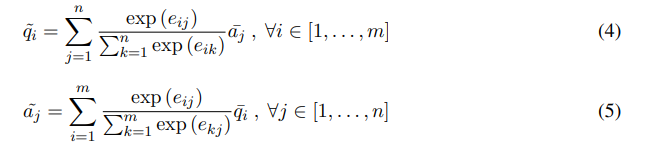
는 의 가중합이며, 는 의 가중합
위에서 구한 original hidden state와 attentive vector를 이용해 difference, element-wise product를 계산하고, original hidden state, attentive vector와 함께 concat해버림

3.3.2 Co-Attention
co-attention이라는 것은 pair-wise attention mechanism으로, pair-wise attention mechanism은 sentence(든 뭐든) pairs 사이의 natural symmetry를 포함함. co-attention은 attention mechanism의 variant로, 여기서는 4가지 variants 사용함: (1) max-pooling co-attention, (2) mean-pooling co-attention, (3) alignment-pooling co-attention, (4) self attention임
처음으로 할 것은, q와 a의 가장 처음 morpheme embeddings 사이에서 similarity matrix()를 계산함으로써 q와 a를 연결하는 것

은 trainable parameter matrix임
- (1) max-pooling co-attention, (2) mean-pooling co-attention
extractive pooling은 max-pooling과 mean-pooling을 포함하는데, max-pooling co-attention은 maximum effect에 기반하여 반대편 sequence의 각각의 형태소에 대해 해당 sequence의 형태소를 attend하는 것을 목표로 함. mean-pooling co-attention은 똑같은데 average effect에 기반한다는 게 다름
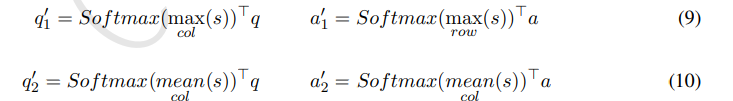
는 의 co-attentive representation임
- (3) alignment-pooling co-attention
위의 sequence enhancement와 비슷, 각 형태소를 다른 sequence에 softly align하는 역할
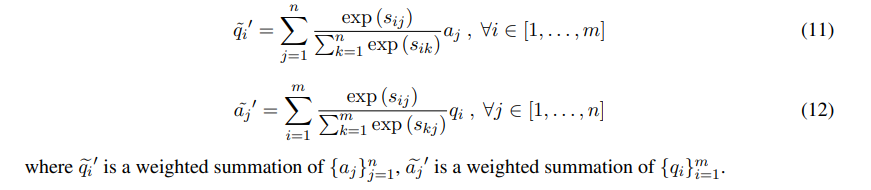
- (4) self attention
self attention은 q와 a에 따로 적용됨, 여기서 q와 a 대신 sentence representation은 x로 표현됨
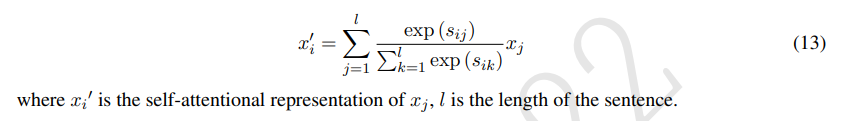
3.3.3 Multi-Cast Attention
multi-cast attention은 multiple attention mechanism으로부터 multi-casted feature vector를 뽑아내줌. 와 로 표현되었던 형태소 embedding은 로 대체되었으며, 는 attentive vector임. 는 compression function 는 concat, 는 element-wise multiplication

Factorization Machiens(FM)은 어떠한 real-valued feature vector에 대해서도 prediction을 만들 수 있으므로, FM을 compression function으로 사용하여 casted scalar를 도출함
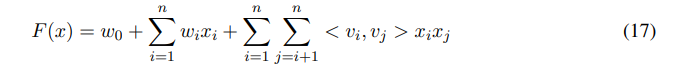
where , 는 FM model의 latent factors 숫자임
각각의 몽골어 q-a pair에 대해 상술한 (1), (2), (3), (4) attention들을 적용함.
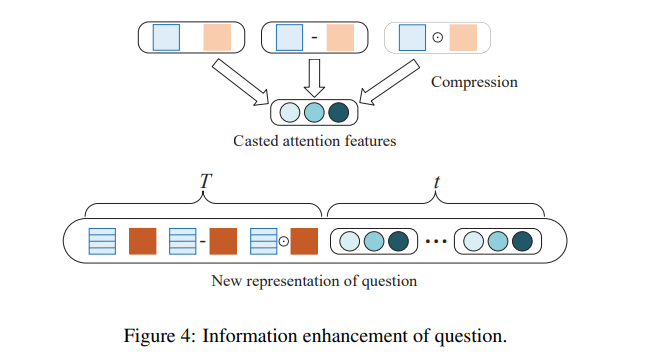
각 attention mechanism마다 scalar 3개씩 나오므로, final multi-casted feature vector 임. 각 형태소마다, enhanced sequence representation 와 multi-casted feature vector 를 concat해서 새로운 representation 를 만들 수 있는데, 다음 수식과 같음
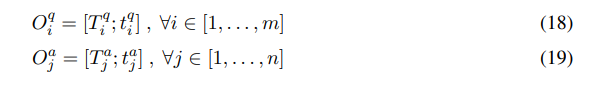
이 다음에는 BiLSTM 사용해서 각 time step의 와 의 interaction information을 encoding함
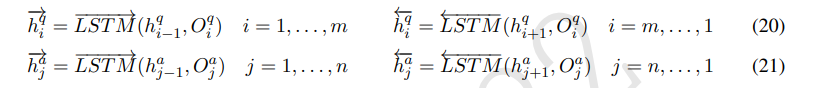
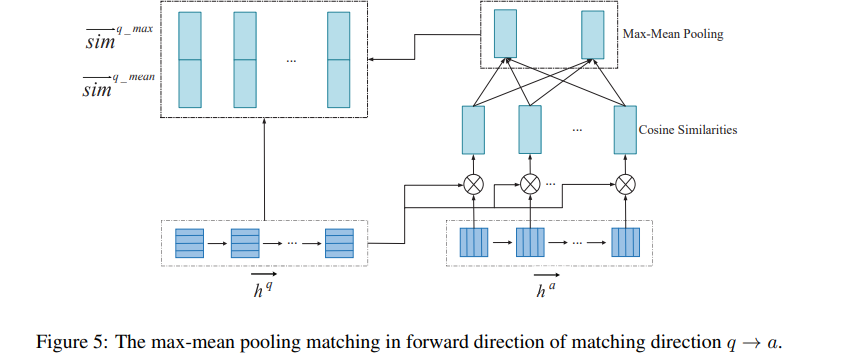
3.4 Matching Layer
q-a pair match를 위해, max-mean pooling matching strategy를 가져왔음. 우선, cosine function을 다음과 같이 정의
는 -dimensional vector로, 서로 match해볼 vector이며, 는 trainable parameter matrix, 의 은 perspective의 갯수임. 각 dimension space(각각 다른 )마다 different weight를 줄 수 있으며, -th perspective에서의 matching value는 다음과 같이 계산될 수 있음
는 element-wise product를 의미하고, 는 의 -th row임
question의 각 time step 마다의 representation을 answer의 모든 time step의 representation과 비교함(from answer to question도 있음). 이 matching direction을 로 나타낼 수 있음
- Morpheme Matching
q-a pair의 initial 형태소 embedding에 대해 max-mean pooling matching strategy를 정의하자면 다음과 같음
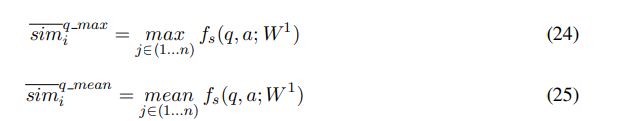
- Interaction Matching
interaction 이후의 q-a pair representation에 대해, 이 또한 max-mean pooling matching strategy를 정의할 수 있는데, bi-directional임
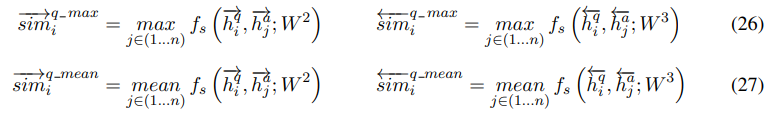
그리고 max-mean pooling matching의 결과물들을 죄다 concat해줌
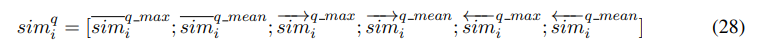
where , 는 element-wise maximum이고, 은 element-wise mean임. 의 계산과정은 와 같음
3.5 Aggregation Layer
matching vector (matching direction )와 (matching direction )를 aggregate하기 위해 BiLSTM 또 사용하고, BiLSTM의 last hidden state들을 concat해줌

3.6 Prediction Layer
q에 대해 a가 match하느냐의 binary classification task이므로 ffc layer 2개 거치고 softmax 씌워줌
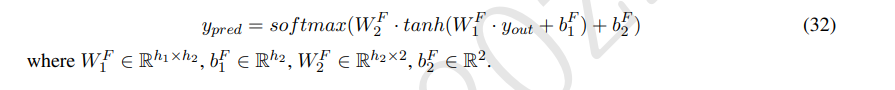
3.7 Model training
binary cross-entropy loss를 minimize(그냥 bce 그대로임)
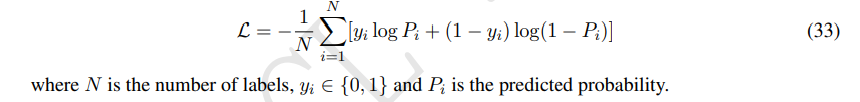
4. Experiments
4.1 Dataset and Evaluation Metrics
본 논문의 몽골어 qa dataset은 중국어 qa corpus에서 번역된 것도 있고, 몽골 웹사이트에서 크롤링된 것도 있음. negative sample도 만들어서 positive samples:nevative samples = 1:1이 되게 했음. 총 265,194 qa pairs, train/dev/test는 8/1/1임
4.2 Model Configuration
tensorflow
batch size 128
epoch 20
max sentence length 50
number of perspective 5
pretrained Mongolian W2V of 300-dimension
all BiLSTM의 hidden layer size 100
dropout 0.1, 모든 layer에 들어감
Adam optimizer, initial lr of 0.0005 to update parameters
4.3 Baselines
앞의 둘(SINN, DiSAN)은 sentence encoding method, 그 다음 둘(ABCNN, DRCN)은 attentive networks, 나머지(MULT, CAFE, MCAN, ESIM)은 compar-aggregate network임
1) SINN (Yang and Kao, 2020): self attention based RNN, CNN을 sentence encoding으로 사용
2) DiSAN (Shen et al., 2018): directional self attention을 encoding에 사용하고, multi-dimensional self attention을 써서 feature compression 진행
3) ABCNN (Yin et al., 2016): sentence pair modeling에 CNN 썼고, CNN 앞뒤로 attention matrix 사용
4) DRCN (Kim et al., 2019): stacked RNN 사용했고, co-attentive features 사용해서 representation 향상
5) MULT (Wang and Jiang, 2017): word-level matching을 element-wise multiplication 이용해 진행하고, CNN 사용해 aggregation
6) CAFE (Tay et al., 2017): factorization machines를 써서 alignment vectors를 scalar features compression, scalar features를 word representation의 augmentation에 사용
7) MCAN (Tay et al., 2018): attention variants 여러 개를 사용하고, multiple comparison operators 사용
8) ESIM (Chen et al., 2017): chain LSTM을 사용한 sequential inference model
4.4 Results
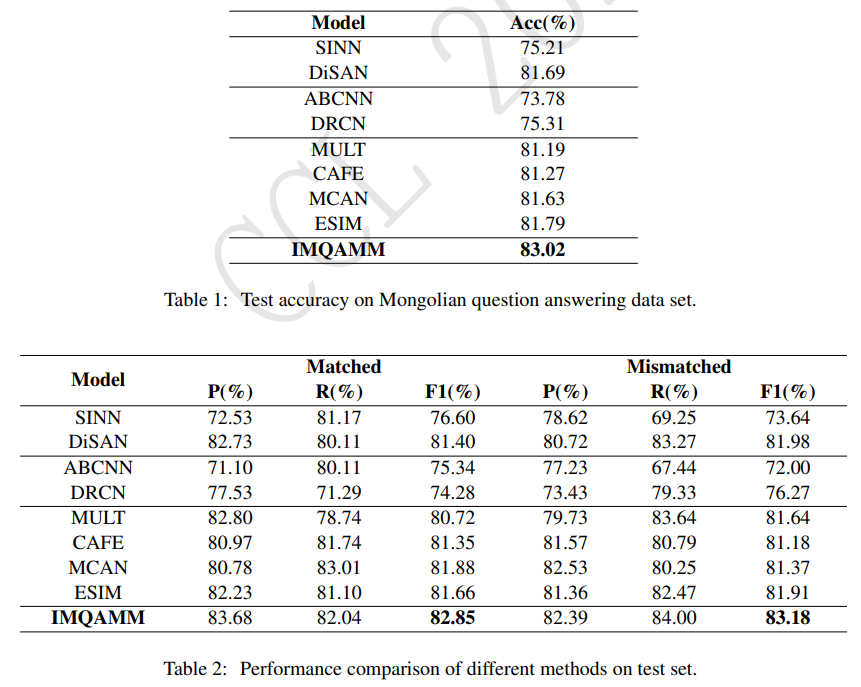
ESIM보다 1.23% 높은데, multi-cast attention의 영향임
MCAN과 CAFE보다 1.39%, 1.75% 높은 것은 sequence enhancement 덕분
DRCN, ABCNN보다 높은 것은 compare-aggregate networks가 attentive networks보다 interactive information 더 잘 제공함
4.5 Ablation Study
Multi-cast attention, morpheme matching, interaction matching을 각각 없앴을 때 셋 다 하빈 것보다 성능 안 나옴

5. Conclusion
IMQAMM은 interactive information enhancement, max-mean pooling matching을 합친 것임.
morpheme vector 만들고, feautre vector 여러 개를 concat해서 sequence representation을 enhance하고, multi-cast attention을 사용해서 data-sparse problem(몽골어의 특성 때문에 생기는)을 경감했음. 마지막으로 max-mean pooling matching strategy를 써서 q-a pair를 bidirection으로 match하였음
result는 뭐 SoTA 달성. 그런데 몽골어는 이전 관련 task나 model이 없었는데 SoTA라고 할 수 있나?
앞으로는 BERT 사용해서 initialization 향상시킬 거고, 그게 model performance 개선할 것으로 예상함
