Ploutos: Towards Interpretable Stock Movement Prediction with Financial Large Language Model (CoRR 2024)
(paper) Tong, H., Li, J., Wu, N., Gong, M., Zhang, D., & Zhang, Q. (2024). Ploutos: Towards interpretable stock movement prediction with financial large language model. arXiv preprint arXiv:2403.00782.
(code) https://github.com/hanstong/Ploutos/tree/main : 학습하는 코드가 없던데?
- 아직 preprint라서 내용에 오류가 많음 (typo라든가, ARIMA가 Traditional deep model로 들어가있다든가..)
"The rearview mirror is always clearer than the windshield."
- Warren Buffet and Berkshire Hathaway. 1991
다시 말해 사전 예측은 힘들지만 사후 해석은 쉽다
Abstract
- Background: financial investments 에서 LLM 을 못 쓰는 이유
- stock movement prediction을 위한 textual value와 numerical value의 fusion이 힘듦
- 기존 방법이 clarity & interpretability가 부족해서 prediction justification이 안 됨
- Approach & Method: PloutosGen과 PloutosGPT로 구성된 framework인 Ploutos를 제안
- PloutosGen: 여러 expert로 작동해서 different modal data를 처리, different perspective에서 quant strategy를 제시
- PloutosGPT: PlutosGen의 insight와 prediction을 종합해서 interpretable rationale을 만듦, rearview-mirror prompting mechanism을 사용 & dynamic token weighting mechanism을 사용해서 LLM finetune
- Experiment & Result: prediction & interpretability 모두 SoTA를 outperform
1 Introduction
- stock prediction이 힘들어요
- volatile nature of financial market & stock market의 multimodal features 때문
- 그래서 precise stock price prediction보다 stock movement prediction (upside / downside) 을 진행
- Quantitative methods:
- traditional methods: LSTM, graph models (stock text & price) 등 존재. 그런데 interpretability가 부족함
- LLM-based methods: sentiment labeling을 하거나, news & price merging 해서 model training에 사용. 그럼에도 불구하고 interpretable decision making rationaledlsk different market에 적절한 different strategy considering이 부족
- quantitative methods에서 지적된 modality fusion 이슈에 대응하기 위해 PloutosGen을 제시하는데, 여러 aspect에서의 stock movement modeling하기 위해 multiple experts를 사용해요
- Technical Expert: time series에서 technical feature를 추출, based on various alpha formulas time series forecasting model로 넘어가서 next-token prediction으로 학습
- 여기서
alpha란 퀀트에서 stock price prediction에서 사용되는 다양한 time series indicator 와 그를 이용한 로직 (formula라고 했으니)? 을 의미하는 것으로 받아들이는 게 맞을 듯
- 여기서
- Sentiment Expert: news event와 stock valuation 사이의 correlation을 포착. 뉴스의 종류는 breaking news부터 trivial commentary까지 다양. diverse news aggregation 있음
- Human Expert: human thoughts를 framework에 녹여서 real application effectiveness 향상
- Technical Expert: time series에서 technical feature를 추출, based on various alpha formulas time series forecasting model로 넘어가서 next-token prediction으로 학습
- 한편, stock situation마다 strategy expert의 predictive accuracy가 달라질 수 있음
- 그래서 가장 suitable한 expert의 insight를 효과적으로 통합할 수 있는 방법을 제안함: 보아하니 별 건 아니고 modality마다 expert 둬서 분석한 다음에 debate 혹은 argue 비스무리하게 하는 느낌인 듯
- PloutosGen과 같이 돌아가게 하기 위해서 PloutosGPT를 제안
- rearview-mirror prompting strategy를 data construction에 사용
- prompting strategy: GPT4를 써서 가장 suitable expert를 찾아내고 strategy를 적용
- 그래서 PloutosGPT SFT를 위한 high quality rationale 수집 가능
- dynamic token weighting mechanism을 SFT에 사용
- 위에서 얻은 accurate & grounded rationale로도 key token generation에는 low accuracy
- 그래서 dynamic token weighting mechanism을 제안하여 key token을 찾아내고 강조하면서 SFT 진행
- 핵심 알고리즘: 각 토큰의 hidden state와 verbalizer에서 나온 type embedding 사이의 cosine similarity 계산해 token importance를 측정
- rearview-mirror prompting strategy를 data construction에 사용
- experiment에서 SoTA를 outperform: prediction accuracy & interpretability
Contribution
- PloutosGen을 제안: multimodal data (numeric time series from various alpha formulas) 를 분석하고 통합하는 LLM pipeline
- PloutosGPT를 제안: rearview-mirror prompting을 써서 interpretable stock prediction과 dynamic weighting 을 통한 SFT를 진행하는 advanced financial LLM
- Metric 제안: faithfulness & informativeness 를 도입해서 generated rationale의 quality 측정. 이를 통해 effectiveness와 interpretability를 향상하였다고 주장
2 Problem Formulation
Goal of Quantitative Investment Task
learning stock price related information from both social media, specifically tweets, and past stock performance indicators to predict stock trends
일반적인 퀀트의 정의와는 다르지 않나..?
Direction of a Stock's Movement
2 consecutive trading days의 adjusted closing prices를 비교하여 결정 binary classification task (move up / move down)
where 는 prediction date 의 adjusted closing price
3 Methodology
3.1 PloutosGen Pipeline
핵심: diverse expert pool
- 언뜻 보기에는 MoE라든가, multihead attention 이 쪽이랑 비슷해보임
- 처리 가능한 modality: sentiment, technical analysis, human analysis
3.1.1 Sentiment Analysis Expert
- 가정: sentiment information이 효과적임 (ok 이건 내가 봤던 논문들에서도 정도의 차이가 있을 뿐 가능성 자체는 확인했음)
- challenge 1: existing LLM not finetuned for stock prediction from sentiment perspective
- challenge 2: different events affect stock price differently aggregating news / tweets into stock signal 이 모호
- unsupervised/supervised/supervised&unsupervised 3가지 측면에서 어떻게 sentiment-based stock prediction이 될 지 가능성 tapping
Unsupervised
- 통상적으로 일컫는 unsupervised (MLM, NSP etc.) 는 아님: stock prediction 을 하지 않는다는 점에서는 unsupervised 이긴 한데, stock prediction 대신 sentiment prediction task 로 바꾸었을 뿐
- dataset 이 말투, financial domain 등 측면에서는 다양하긴 하지만 sentiment prediction task 하나로 퉁쳤다는 점에서 한계가 있지 않나 싶음
- 다양한 asset & news type의 데이터를 사용했다고 함~ 아래는 사용한 prompt template

- backbone: LLaMA-2
- evaluation dataset: ACL18 dataset
- model usage (정확히 어떻게 학습시켰다는 건지 이해는 안 됨)
- past 5 day에 대해서 sentiment labeling (pos, neg, neu) 하고, the very day 의 stock prediction은 sentiment score avg.
- pos score == increase, neg == decrease
Supervised
- stock prediction 을 label로 부여. prompt template은 아래와 같음. 마찬가지로 backbone으로 LLaMA-2 사용
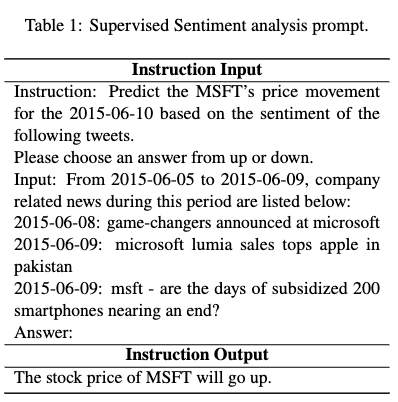
Sup. & Unsup.
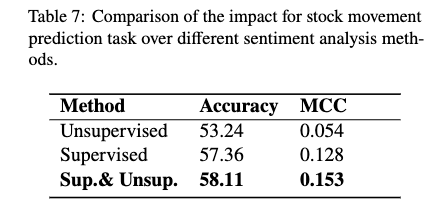
- unsupervised에서 사용한 데이터와 supervised에서 사용한 데이터 모두 사용해서 학습. 최종적으로는 Sup. & Unsup.이 가장 좋았다고.
3.1.2 Technical Analysis Expert
- alpha (time series feature) 와 explanation (text feature) 을 이용해 next token prediction 학습
Number-to-Text Alignment (N2I-Align)을 제안해서 explaining text와 time series data 와의 연결을 높임. prompt template 은 아래와 같음.- time series data, target prediction date, fixed window size, common alpha 가 input prompt 에 녹아 들어감
- alpha로 mv7, mv20, MACD, EMA, Bollinger Bands- Upper Band / Lower Band / Middle Line, LogMomentum, VMA60 썼다는 듯 (table 9)
- LLaMA-2 사용

3.1.3 Human Experts
- 역할: fundamental analysis, macroeconomic indicators, market cycles에 대한 insights 같은 것들을 encapsulating하는 것
- text는 quantify하기 힘들어도 investment decision에 필요한 사항들을 잘 감싸는데 필요함
- customizable and optional component
- 아니 그래서 어떻게 뭘 만든 건데
3.2 PloutosGPT Training
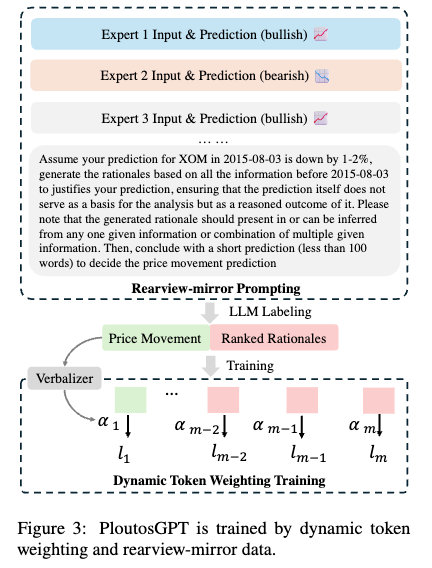
- PloutosGPT의 objective: generating explainable and accurate rationales for predicting price movements
- interpretability 관련해서도 이전에는 neural network learning phase에 의존했는데, Ploutos는 처음으로 rationale을 제공한다는 점
- Steps
- step 1
rearview-mirrorbased data construction - step 2
dynamic token weightingtraining strategy
- step 1
rearview-mirror based data construction
- prompt 끄트머리에 보면 'to justify your prediction ...' 이런 식으로 prediction을 요구하는 게 아니라, prediction을 제시하고 그에 대한 justification을 요구하는 형태임
- bullish & bearish rationale을 모두 summarize해서 faithful (correct prediction에 더 걸맞는) rationale을 생성: GPT 같은 LLM 사용
- 위를 기반으로 final decision 생성; constraint로 model은 ground truth를 rationale로 직접적으로 사용하면 안 됨
- input: diverse expert의 analysis
- output: generated rationale & stock movement
- 아래는 prompt example

dynamic token weighting training strategy
-
위처럼 했을 때 rationale key token generation을 힘들어 해서 특정 단어 (e.g. upward) 를 특별히 처리해야 할 필요 있음
-
아래 loss 계산할 때 token log prob에 특별히 계산한 weight ()를 곱해주는 형태임
where
input, generated content consists of rationales and albel,
: weight of -th token in generated content -
는 up/down 에 해당하는 token들 (verbalizer 통해서 매핑 가능한 애들) 의 average pooling과 각 token 사이의 softmax로 계산됨
는 기본적으로 token embedding과 verbalizer token embedding의 cosine similarity의 softmax로 계산되는데, 상세히는 아래와 같음
where
: last layer hidden state of -th token
: type embedding (avg. pooling of verbalizer tokens embedding)
verbalizer (Appendix C)
- label을 word list로 mapping 하는 단순한 형태 (너무 나이브하지 않나)
- Up label [up, boost, positive, rise]
- Down label [down, reduce, negative, drop]
- 소스코드에서 detect_trend_from_sent가 verbalizer..?
def detect_trend_from_sent(sent):
sent = sent.lower()
wordsmap = {"rebound":1,"rise":1, "rise by":1,"move up":1,"up":1,"down":0, "drop":0,
"up":1,"decline":0,"downward":0,"uptrend":1,"bullish":1,"bearish":0,"increase":1,
"decrease":0,"rally":1,"close do":0,"pullback":0,"flat or slightly down":0}
wordstr = "|".join(list(wordsmap.keys()))
matches = re.compile(fr"Prediction:\s*(?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"I predict that (?P<stock_symbol>.*) will continue to (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"The prediction is (?P<action>{wordstr}) by 0-1% for (?P<stock_symbol>.*)").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*) will experience a slight (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"The prediction is (?P<action>{wordstr}) by").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*) will continue its (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*) will (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*) will have a slight (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"The price may (?P<action>{wordstr}) by").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*)'s stock price will go (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"expect (?P<stock_symbol>.*) to (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"The stock price of (?P<stock_symbol>.*) is expected to (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
matches = re.compile(fr"predict that (?P<stock_symbol>.*)'s stock price will remain (?P<action>{wordstr})").search(sent)
if matches:
return wordsmap[matches.group("action")]
return -14 Experiments
RQ's
RQ1: How does Ploutos perform compared with current LLM based and traditional prediction models?
RQ2: How do the different components in Ploutos affect its effectiveness?
RQ3: Does the decision making rationales informative and consistent with given information?
4.1.1 Experiment Setup
- 다른 건 논문 확인
- 5일을 window로 설정
- positive sample:
>= 0.55%, negative sample:<= 0.5% - trianing set 19m, validation 2m, test 3m 로 설정: 7:1:2 ratio 라는데 안 맞지 않나?
4.4 Faithfulness and Informativeness of Interpretability (RQ3)
- Faithfulness: given knowledge에 model response의 fact가 기반하는지, model response의 fact가 given knowledge에서 infer될 수 있는지 측정
- HaluEval 을 따라 GPT-4를 이용해 측정 (논문 따로 봐야 할 듯)
- Informativeness: model response에 들어있는 information amount. 어떤 모델들은 대체로 correct하지만 대체로 uninformative한 output을 내보낼 수 있음
- TruthfulQA의 informativeness measurement를 사용 (논문 따로 봐야 할 듯)
