Redis
고성능 Key-Value 구조의 저장소로, 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 NoSQL이다.
인메모리 데이터 구조 저장소로 DB, Cache, Message Queue 등으로 사용된다.
인메모리
컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법
RAM에 데이터를 저장하게 되면 메모리 내부에서 처리가 되므로
데이터를 저장/조회할 때 하드디스크를 오고가는 과정을 거치지 않아도 되어 속도가 빠름
하지만 RAM의 특성인 휘발성에 따라 데이터가 유실될 수 있음
Redis 특징
- Redis 데이터는 메모리에 저장되어 대기 시간을 낮추고 처리량을 높이며,
평균적으로 읽기 및 쓰기의 작업 속도가 1ms로 디스크 기반 데이터베이스보다 빠르다. - Redis의 데이터는 String, List, Set, Hash, Sorted Set, Bitmap, JSON 등 다양한 데이터 타입을 지원한다. 따라서, 애플리케이션의 요구 사항에 알맞은 다양한 데이터 타입을 활용할 수 있다.
- Redis는 싱글 스레드 방식을 사용하여 한 번에 하나의 명령어만을 처리하기 때문에 연산을 원자적으로 처리하여 Race Condition(경쟁 상태)가 거의 발생하지 않는다. 하지만, 멀티 스레드를 지원하지 않기 때문에 시간 복잡도가 O(n)인 명령어의 사용은 주의해서 사용해야 한다. (Redis 6.0 부터는 ThreadedIO가 추가되어 사용자 명령에 멀티 쓰레드가 지원되지만, 명령어를 실행하는 코어 부분은 여전히 single thread며 IO Socket read/write를 할 때 멀티 쓰레드로 동작한다.)
여기까지가 Redis에 대한 기본 설명이고 오늘은 Redis Cluster에 대해 정리해보려 한다.
Redis Cluster
Cluster란 여러 대의 서버를 하나로 묶어서 1개의 시스템처럼 동작하게 하는 것을 의미한다. 그래서 여러 대의 서버에 데이터를 분산하여 저장하기 때문에 1대의 서버에 부하를 여러 대의 서버로 분산시키므로 더 빠른 속도로 사용자에게 서비스를 제공할 수 있다.
Redis의 경우 단일 스레드로 동작하기 때문에 서버에 CPU를 추가한다고 해도 여러 CPU 코어를 동시에 활용할 수 없다. 즉, 성능 향상이 필요한 경우 서버의 수를 늘려 처리 량을 선형적으로 확장시켜야 한다.
Redis는 이러한 확장을 위해 샤딩을 지원한다.
샤딩
동일한 스키마를 가지고 있는 데이터를 다수의 데이터베이스에 분산하여 저장하는 기법
수평 파티셔닝과 비슷하지만 수평 파티셔닝의 경우 동일한 서버에 저장되어 있지만 샤딩은 서로 다른 서버에 분산하여 저장한다. 따라서 쿼리 성능 향상뿐만 아니라 부하가 분산되는 효과까지 얻을 수 있다. 즉, 샤딩은 데이터베이스 차원의 수평 확장( scale-out )이다.
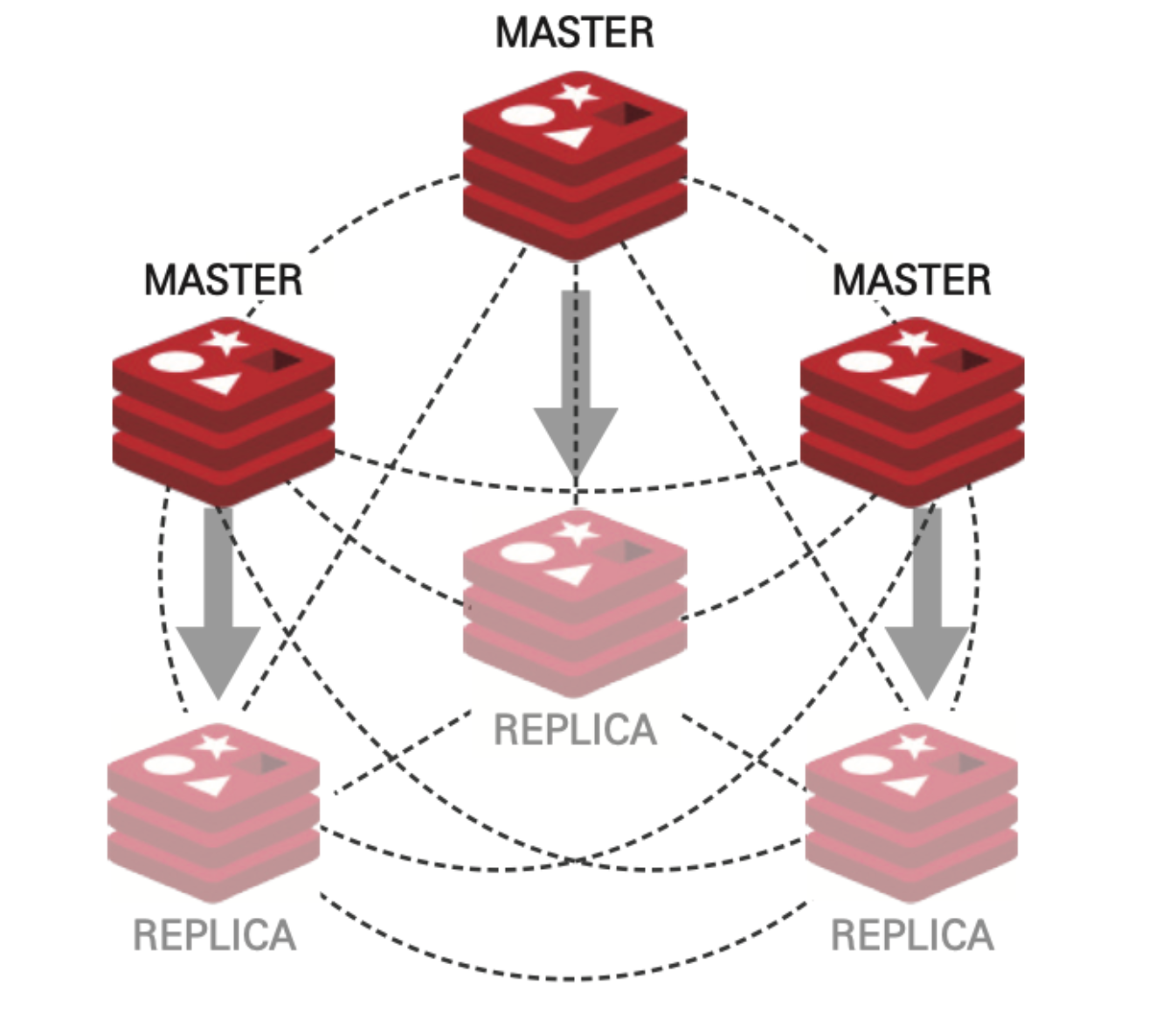
클러스터는 기본적으로 최소 3대의 마스터, 복제 노드를 구성한다.
하나의 클러스터 구성에 속한 각 노드는 서로를 모니터링하고 마스터 노드에 장애가 발생하면 이를 인지한 다른 노드들이 마스터에 연결됐던 복제본 노드를 마스터로 자동 페일오버시킨다.
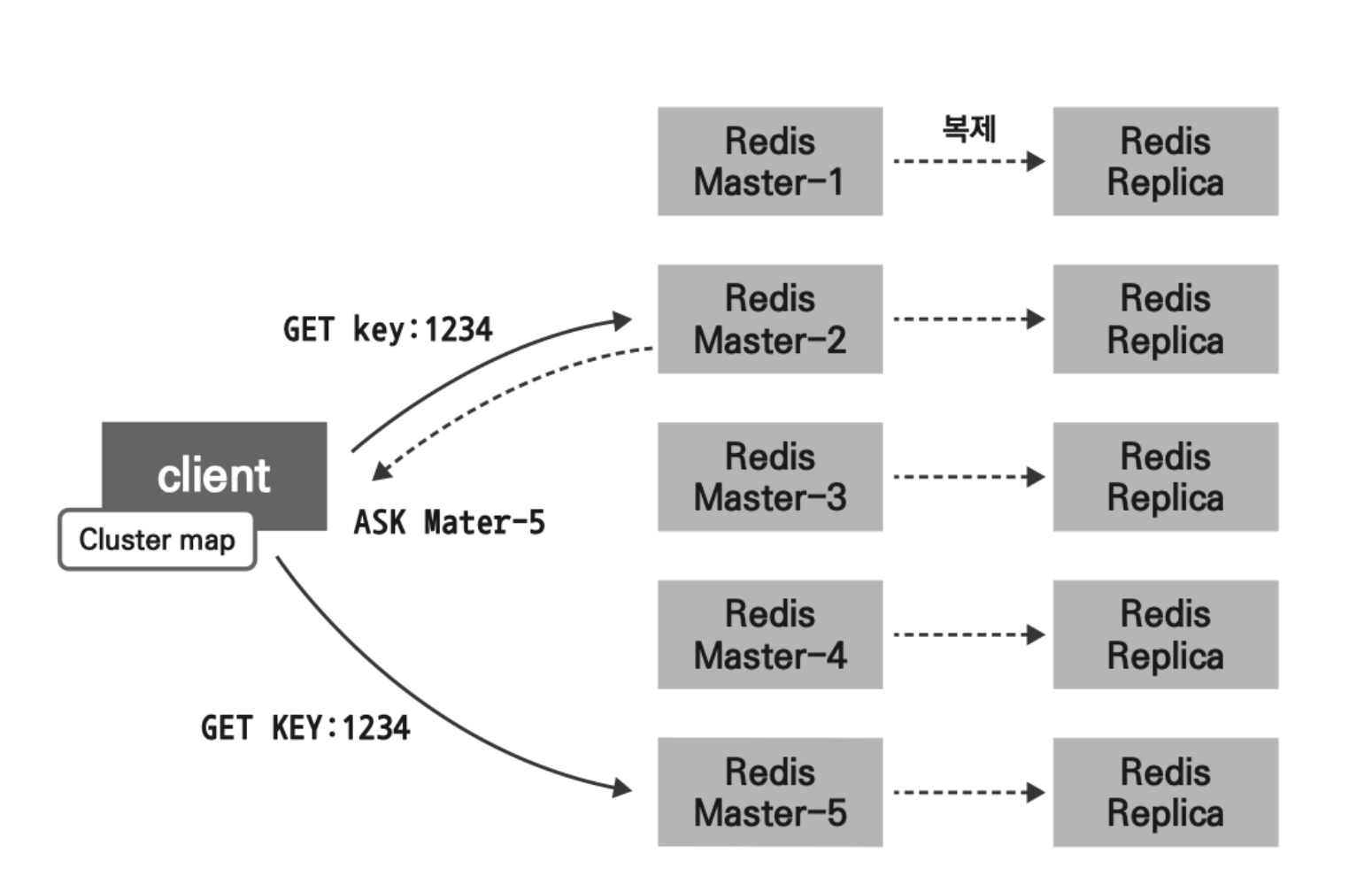
자 그럼 어떤 데이터가 어떤 노드에 저장되는지는 어떻게 정해질까?
Redis Cluster는 hash slot 알고리즘을 사용하여 데이터를 분산 저장한다.
각 노드는 총 16384개의 해시 슬롯을 나눠 가지며, 데이터의 키 값을 해시 함수로 넘긴 후 해시 슬롯 값을 계산한다.
해시슬롯은 마스터 노드 내에서 자유롭게 옮겨질 수 있으며, 옮겨지는 중에도 데이터에 정상적으로 접근할 수 있다.
또한 해시태그를 이용해서 관련 데이터를 같은 슬롯에 저장할 수 있다. 해시태그는 중괄호 {}를 사용하여 키의 특정 부분만 해싱하도록 지정한다.
예: "user:{1234}:name"과 "user:{1234}:age"는 같은 슬롯에 저장
이러한 방식을 통해 클러스터 환경에서 다중 키 명령어를 사용할 수 없는 문제를 해결한다.
오늘은 평소 Redis를 사용하며 궁금했던 Redis 서버의 확장에 대해 정리해보았다. 실제 환경을 구성해서 테스트한게 아니라 명확하게 이해되지는 않았지만, 대략적인 감은 잡을 수 있었다. 우선 계획했던 내용들을 다 정리한 후 실제 테스트를 통해 명확히 이해해보겠다.
