사용자가 우리 앱에 상품을 담으면 해당 상품을 스크래핑 해온 후 스크래핑 해온 이미지를 대상으로 카테고리 분석을 통해 해당 사용자의 카테고리별 선호도를 알려주는 기능을 추가하였다. '누군가에게 선물할 때 열심히 고민하지만 당사자가 사고 싶어하는걸 알면 훨씬 수월하지 않을까?'에서 시작되었다..!
그런데 문제가 생겼다. 스크래핑 해온 이미지를 카테고리 분류를 위해 이미지 모델 분석 과정을 거치고 오면 이전에 비해 사용자의 앱에 상품이 뜨는 시간이 느려졌다. 실제로 사용감이 좋지 않았다. 이 정도 속도면 사용자가 떠나겠는데 느껴질 정도로...
이를 어떻게 하면 개선할 수 있을까 팀원들과 고민하던 중 "javascript에는 콜백 함수가 있는데 java도 있지 않을까?" 하는 팀원의 추천으로 시작하게 되었다.
Spring WebFlux
Spring WebFlux는 non-blocking을 통해 적은 수의 리소스로 동시성을 다루기 위해 만들어졌다. 내장 서버는 기본적으로 Netty 서버지만 Tomcat으로 사용할 수 있다.
우리가 기본적으로 Spring MVC와 RDBMS를 사용했으니 Blocking I/O 모델을 사용했다. 해당 모델은 Application에서 I/O 요청을 한 후 완료되기 전까지는 Application이 Block이 되어 다른 작업을 수행할 수 없다. 이는 해당 자원이 효율적으로 사용되지 못하고 있음을 의미하기도 한다.
하지만 그전까지 불편함을 못느꼈던 것은 Multi Thread를 기반으로 동작해서 Blocking 방식임에도 불구하고 마치 Block이 안된듯이 동작하는 것처럼 보였던 것이다. Block 되는 순간 다른 Thread가 동작함으로써 Block의 문제를 해소한 것이다.
하지만, 랜더링 속도 개선을 위해서는 우리는 카테고리 분석을 비동기로 분리하기를 원했다. 실제로 tensorflow가 무거워 t2.micro server에 selenium과 함께 동작하기는 버거워 서버를 분리하기도 했다.
Asynchronous Non-blocking I/O
I/O를 요청 한 후 Non-Blocking I/O와 마찬가지로 즉시 리턴한다. 데이터 준비가 완료되면 이벤트를 발생하여 알려주거나, 미리 등록해놓은 callback을 통해 이후 작업이 진행된다.
특정 시간에 데이터가 준비 다 되었는지 상태를 틈틈이 확인하는 synchronous Non-blocking I/O 의Polling 에 비해 자원을 보다 더 효율적으로 사용할 수 있다.
Event-Driven
Event-Driven Programming은 프로그램 실행 흐름이 이벤트(ex. 마우스 클릭 등)에 의해 결정되는 프로그래밍 패러다임이다. 순차적으로 진행되는 과거 프로그래밍 방식과 달리 GUI가 발전됨에 따라 유저에 의해 종잡을 수 없이 흐름이 진행되기에 더욱 많이 쓰이게 되었다.
우리 서버에서는 HTTP Request라는 Event가 발생한다.
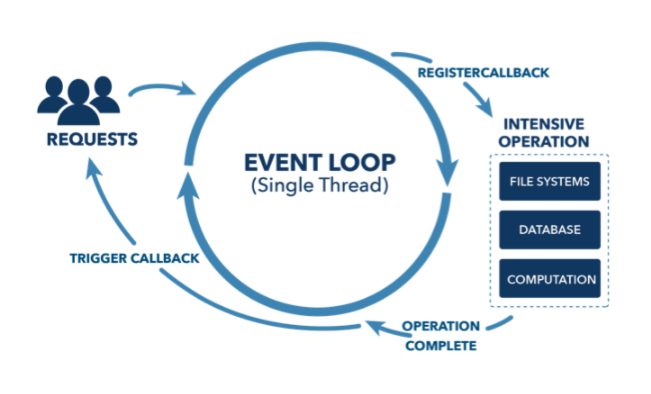
사용자들에 의해 요청이 들어오면 Event Loop를 통해 작업이 처리되어 다수의 요청을 적은 Thread로 커버할 수 있다. MSA에서는 많은 수의 Network I/O가 발생할테니 이를 Non Blocking I/O를 통해 성능을 끌어올릴 수 있을 것이다.
시행 착오 및 적용
기존에는 사용자가 아이템을 담을 때 해당 url을 코어 서버인 스프링 서버에서 받아 스크래핑 서버에 넘겨주면 스크래핑과 카테고리 분석을 마친 결과를 반환하여,
해당 정보를 db에 저장 후 클라이언트에 id를 반환하는 방식이었다.
아래는 변경된 방식을 적용한 코드다.
@PostMapping("/item/parsing")
public ResponseEntity<?> createItem(@RequestBody ItemCreateRequestDto dto, @Value("${server.url.scrap}") String scrapUri, @Value("${server.url.category}") String categoryUri) {
try {
if(dto.getUrl() == null){
throw new DtoNullException();
}
Item find = itemService.findItem(dto.getUrl());
if(find != null){
itemService.checkMemberReferenceByItem(find, dto.getNickname());
return ResponseEntity.ok().body(find.getId());
}
// Python Server 호출
JSONObject jsonObject = createHttpRequestAndSend(dto.getUrl(), scrapUri);
String imgUrl = jsonObject.getString("img");
Item item = Item.builder()
.name(jsonObject.getString("title"))
.price(jsonObject.getInt("price"))
.imgUrl(jsonObject.getString("img"))
.originUrl(dto.getUrl())
.memberItems(new ArrayList<>())
.collectionItems(new ArrayList<>())
.build();
Long saveItem = itemService.saveItem(item, dto.getNickname());
Flux<ItemCategoryResponseDto> response = itemService.categorization(imgUrl, item, categoryUri);
return ResponseEntity.ok().body(saveItem);
} catch (JSONException jsonException) {
throw new ScrapingException();
} catch (Exception e) {
e.printStackTrace();
ResponseErrorDto errorDto = ResponseErrorDto.builder()
.error(e.getMessage())
.build();
return ResponseEntity.internalServerError().body(errorDto);
}
}public Flux<ItemCategoryResponseDto> categorization(String imgUrl, Item item, String uri) {
ItemCategoryRequestDto img = ItemCategoryRequestDto.builder()
.imgUrl(imgUrl)
.build();
Flux<ItemCategoryResponseDto> stringFlux = WebClient.create()
.post()
.uri(uri)
.bodyValue(img)
.retrieve()
.bodyToFlux(ItemCategoryResponseDto.class);
stringFlux.subscribe(responseDto -> {
log.info("비동기 완료 [카테고리] : {}", responseDto.getCategory());
item.updateCategory(responseDto.getCategory());
itemRepository.save(item);
});
return stringFlux;
}- 스크핑만 한 후 카테고리는 null로 db에 저장한다.
- db 저장 후 categorization함수를 호출한 후 클라이언트에 id를 반환한다.
- WebFlux의 WebClient를 통해 비동기적으로 카테고리 분석 서버에 요청을 보내고 응답이 오면 db에 해당 아이템 카테고리 결과를 업데이트한다.
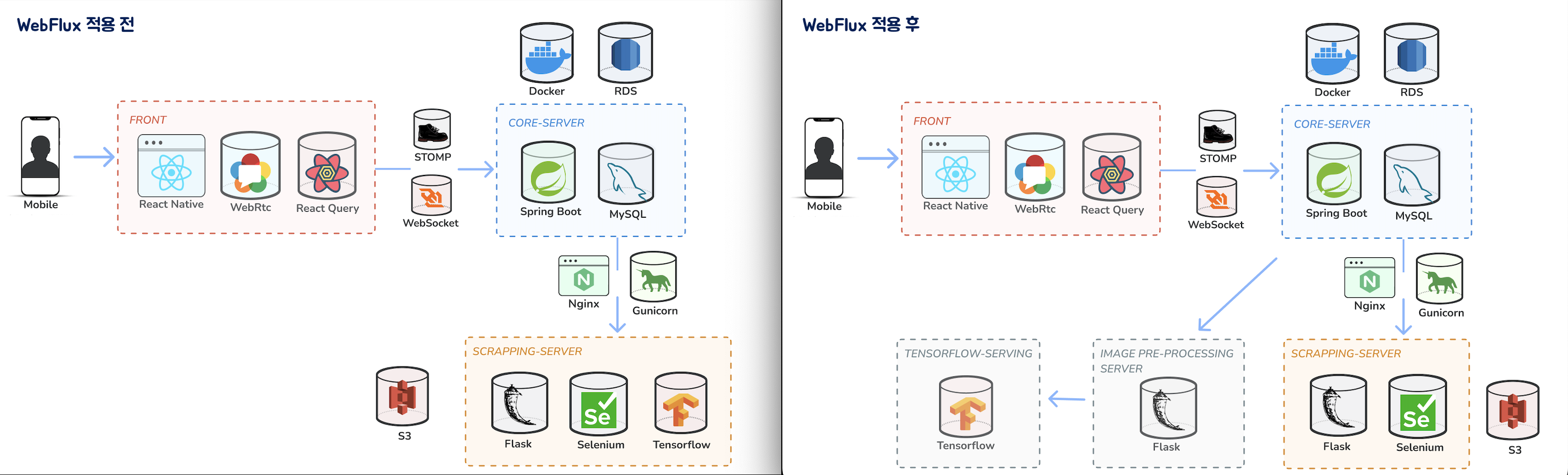
우리는 아직 만나본 적 없지만 WebFlux에도 단점도 존재한다. 순서대로 작업이 처리되는 것이 아니라 Event에 기반해 실타래가 엉킨 듯 작업이 처리되기에 트래킹하기 힘들다는 문제가 있다. 상황에 따라 고려해서 사용하면 좋을 것 같다!
참고. Spring WebFlux
Get List of JSON Objects with WebClient
Spring WebFlux는 어떻게 적은 리소스로 많은 트래픽을 감당할까?
WebFlux로 Asynchronous & Non-blocking I/O 전환하여 API 성능 튜닝하기
