https://arxiv.org/pdf/2210.15718.pdf
Retrieval Augmentation
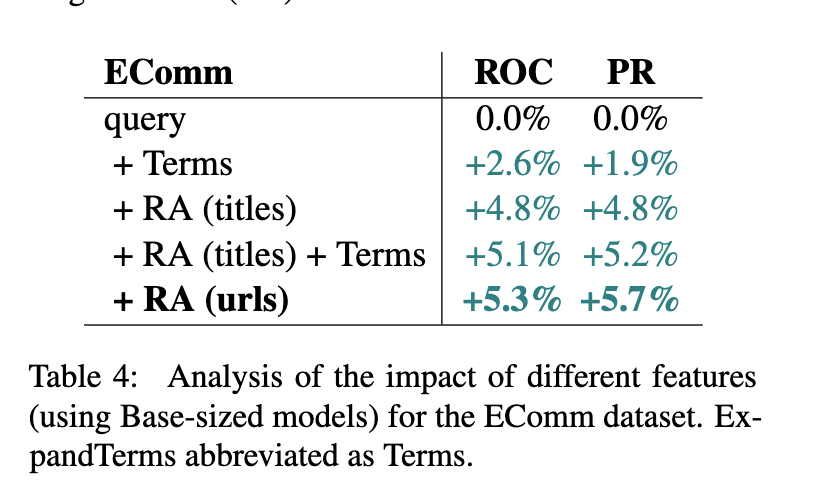
LLM을 가지고 쿼리를 분류하는 모델을 만들어야한다고 생각해보자. <쿼리, 라벨>을 넣는 것이 가장 간단한 방법이고, 그 다음으로는 원래 기존에 알고 있던 쿼리 정보 (논문에서는 ExpandTerm) 를 붙여서 사용하는 <쿼리+ExpandTerm, 라벨> 을 가지고 훈련을 하는 방법이 있겠다. ExpandTerm 말고 좀 더 간단하지만 강력한 방법이 있는데, 쿼리의 검색결과를 구해서 top 검색 결과의 URL이나 제목을 붙이는 것이다 (논문에서는 Retrieval Augmentation, RA 라고 부른다). 그러면 일단 LLM 상에서는 아래로 갈수록 성능이 좋아진다 (RA (url) > RA (titles) + Terms 인 것이 신기하다. URL도 의미가 있는 영어의 위엄).
2-Stage Distillation
이 페이퍼에서 최종 목표는 4-layer, hidden dimension이 256인 작은 트랜스포머를 훈련시키는 것이다. 당연히 얘를 바로 트레이닝하는 것보다 앞에서 만든 LLM을 가지고 distillation하는 것이 더 잘되는데 그것보다 더 좋은 방법이 있다.
LLM이 Professor, 4-layer Transformer가 Student라고 하면 중간에 Teacher를 놓는 것이다. 이 Teacher 모델은 구조가 Professor랑 같은 대신에, <쿼리+RA> 가 아닌 <쿼리 + ExpandTerm>을 사용해서 distillation에 사용된다. <쿼리+RA>를 사용하면 시퀀스가 길어져서 속도가 너무 느려져서 (대략 10배) 효율적으로 distillation을 하려면 이렇게 해야한다고 한다. 이렇게해서 Teacher 모델을 만들고, 이걸 가지고 다시 Student 모델을 만드는 것이 Professor만 가지고 바로 Student 모델을 만드는 것보다 성능이 좋다고 한다. 성능이 어떤 조합에 비해서 어떻게 좋은지는 페이퍼를 읽어보도록 하자.
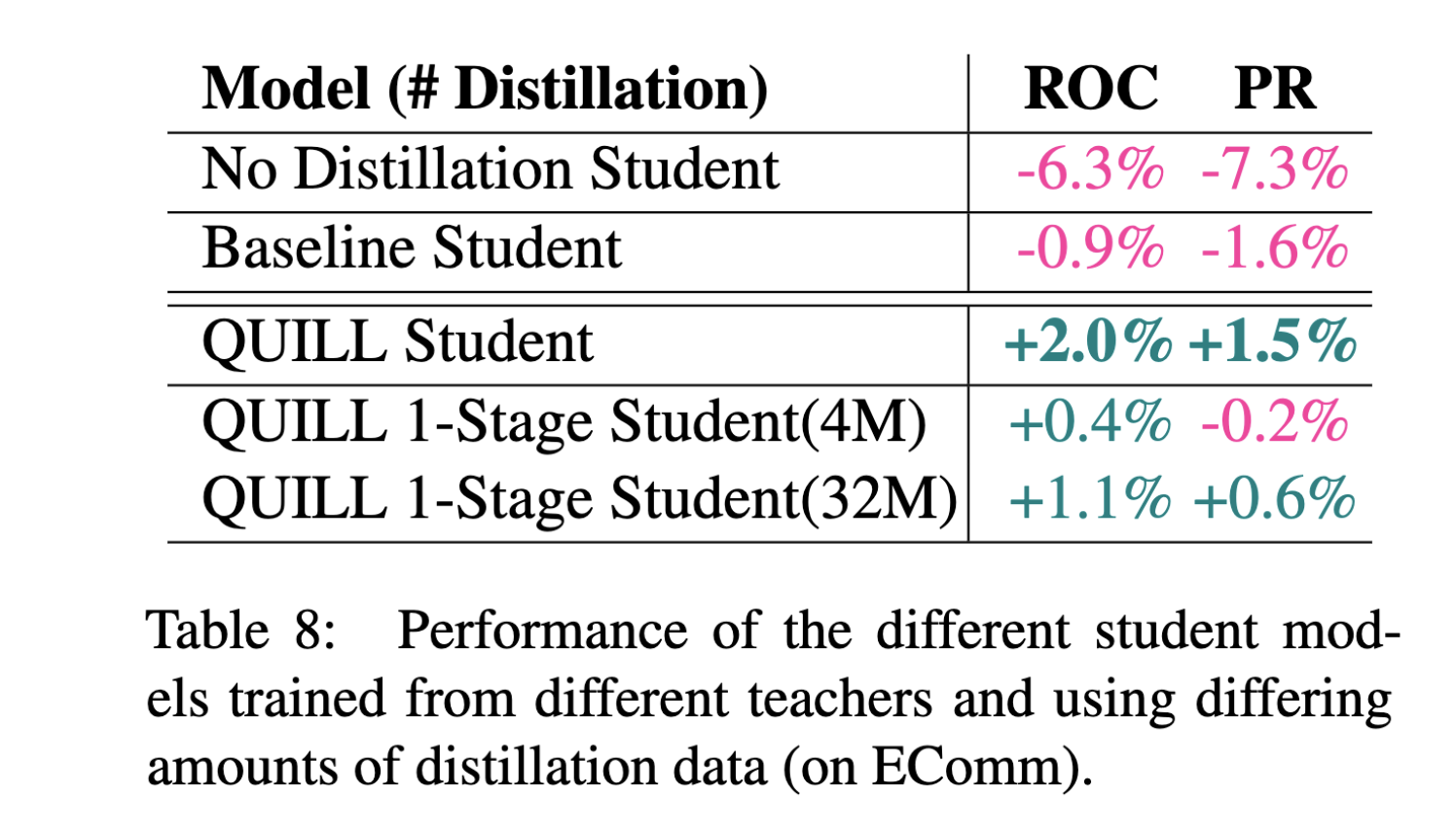
결론적으로 최종 Student 모델끼리 비교할 때 그냥 student만 가지고 트레이닝한거에 비해서 8.5% gain이 있다 (Baseline student라고 복잡하게 안하고 <쿼리+ExpandTerm>으로 Teacher부터 만든 것이 있는데 이거 성능이 꽤 좋은 것도 주목할 포인트).
Q
- Student 모델은 그래서 ExpandTerm을 사용을 하는지? 안하는지 명확하게 찾지를 못했다. 연산 속도가 중요하니까 안 썼을 것 같다.
기타
- 여기서 말하는 LLM은 mT5-base(580M) 이라서 아주 손도 못 댈 방법은 아니다.
- velog에는 처음 글을 써보는데 확실히 글을 쓰기 편해야 이렇게 간단히 메모 남길 때 마찰이 적다. Velopert님 존경합니다.
