
캐시 & 캐싱
캐시
-
동일한 데이터에 반복해서 접근해야 하거나 많은 연산이 필요한 일일때, 결과를 빠르게 이용하고자 성능이 좋은 혹은 가까운 곳에 저장하는 것
즉 캐시는 컴퓨터의 성능을 향상 시키기 위해 사용되는 메모리를 말한다
-
주기억장치와 CPU 사이에 위치하고, 자주 사용하는 데이터를 기억한다
예를 들어, 한번 접속한 웹 사이트에 동일한 브라우저로 다시 접속할 때 용량이 큰 이미지나 비디오는 다시 받아오지 않고 브라우저 캐시에 저장해 놨다가 동일하게 가져다 쓸 수 있다. 이를 통해 훨씬 빠르게 웹 사이트의 컨텐츠를 볼 수 있다. 이처럼 캐시를 사용하면 과거에 계산한 데이터를 효율적으로 재사용할 수 있는 것이다.
캐싱
-
이 캐시 영역으로 데이터를 가져와서 접근하는 방식을 말한다.
예를 들어, 속도가 느린 디스크의 데이터를 속도가 빠른 메모리로 가져와 메모리상에서 읽고 쓰는 작업을 수행한다.
-
다른 의미로는, 메모리상에 있는 데이터를 연산하는데, 이 연산을 더 빠른 CPU 메모리 영역으로 가져와 처리를 수행하는 것도 캐싱이라 표현
Redis란?
웹, 인공지능, 빅데이터 등이 생겨나고 데이터 정보의 크기가 커지면서 DB의 한계가 생기는데, 이는 SSD로 많이 개선되었지만 여전히 디스크에 데이터를 저장해야하므로 이 또한 한계에 다다르게 된다. 데이터를 하드디스크나 SSD에 저장하지 않고 메모리에 저장하는 In-Momory DB인 Redis에 대해서 알아볼 예정이다.
-
고성능 Key-Value 구조의 저장소
-
전체 데이터베이스의 초기 복사본을 받는 마스터/슬레이브 복제를 지원한다.
-
마스터에서 쓰기가 수행되면 슬레이브 데이터 세트를 실시간으로 업데이트하기 위해 연결된 모든 슬레이브로 데이터를 전송한다.
-
빠른 처리 속도
디스크가 아닌 메모리에서 데이터를 처리하기 때문에 속도가 빠름
-
Data Type(Collection)을 지원

➜ 개발의 편의성, 생산성이 좋아지고 난이도가 낮아짐
DB에 데이터를 저장하고, 저장된 데이터를 정렬해서 다시 읽어오는 과정은 디스크에 직접 접근해야하기 때문에 시간이 걸리는데, 인메모리 DB인 Redis를 사용하고 Redis에서 제공하는 Sorted-Set 자료구조를 사용하면 좀 더 빠르고 간단하게 데이터 정렬 가능 -
AOF, RDB 방식
인메모리 데이터 저장소가 가지는 휘발성의 특성으로 데이터가 유실될 경우를 방지하여 백업 기능을 제공- AOF (Append On File) 방식
Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태
- RDB(Snapshotting) 방식
순간적으로 메모리에 있는 내용 전체를 디스크에 담아 영구 저장하는 방식
- AOF (Append On File) 방식
-
Redis Sentinel 및 Redis Cluster를 통한 자동 파티셔닝을 제공
Master와 Slaves로 구성하여 여러대의 복제본을 만들 수 있고, 여러대의 서버로 읽기를 확장 가능 -
다양한 프로그래밍 언어 지원
-
싱글 스레드
한번에 하나의 명령만 수행이 가능하므로 Race Condition이 거의 발생하지 않음Race condition
공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태 즉, 두개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황에서 발생하고 프로그램의 일관성과 정확성을 손상시킬 수 있음
예를들어, 두개의 스레드 A, B가 X라는 공유변수를 사용하는데, A의 역할은 X에 + 1 후 저장 / B의 역할은 X에 - 1 후 저장일 때 A가 X를 읽은 후 B가 실행되기 전에 결과를 저장한다고 하면, A의 결과가 스레드 B의 결과데 덮어씌워지게 됨
-
비정형 데이터를 저장, 관리하기 위한 오픈 소스 기반의 NoSQL(비관계형 데이터베이스)
-
In-Memory 데이터 구조를 가진 저장소
-
DB, Cache, Message Queue, Shared Memory 용도로 사용됨
-
쓰기 성능 증대를 위한 클라이언트 측 Sharding 지원
-
읽기 성능 증대를 위한 서버 측 복제를 지원
-
크게 String, Set, Sorted Set, Hash, List 데이터 형식 지원
인메모리 ( In-Memory )
- 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법
- RAM에 데이터를 저장하게 되면 메모리 내부에서 처리가 되므로
데이터를 저장/조회할 때 하드디스크를 오고가는 과정을 거치지 않아도 되어 속도가 빠름- 그러나 서버의 메모리 용량을 초과하는 데이터를 처리할 경우, RAM의 특성인 휘발성에 따라 데이터가 유실될 수 있음
휘발성이란 전원이 꺼지면 가지고 있던 데이터가 사라지는 특성
기존의 DB가 있는데 왜 Redis를 사용할까?
DB는 데이터를 디스크에 직접 저장하기 때문에 서버에 문제가 발생하여 다운되더라도 데이터가 손실되지 않는데 매번 디스크에 접근해야 하기 때문에 사용자가 많아질 수록 부하가 많아지고 느려져서 캐시 서버를 도입해서 사용해야 한다.
같은 요청이 여러번 들어올 때 Redis를 사용함으로써 매번 DB를 거치지 않고 캐시 서버에서 저장했던 값을 바로 가져와 DB의 부하를 줄이고 서비스의 속도도 느려지지 않게 할 수 있다.
Redis 장점
- 리스트, 배열 데이터를 처리하는데 유용
- 리스트 형 데이터 입력 & 삭제가 MySQL에 비해 10배정도 바름
- 영속적인 데이터 보존
Redis 데이터 타입
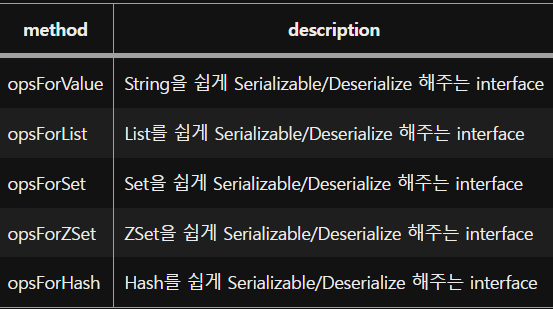
Redis-cli 명령어
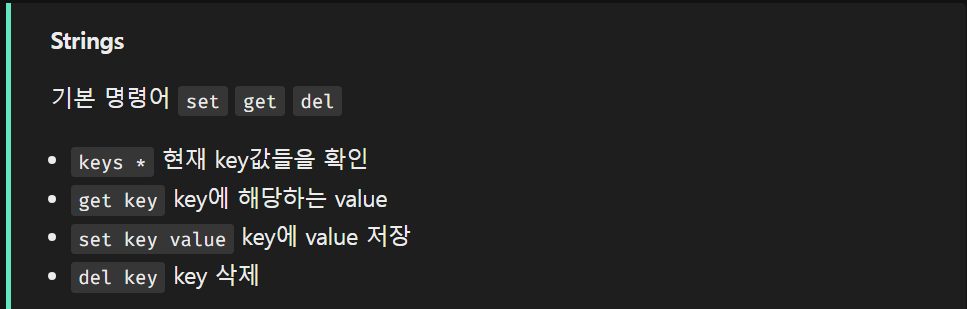


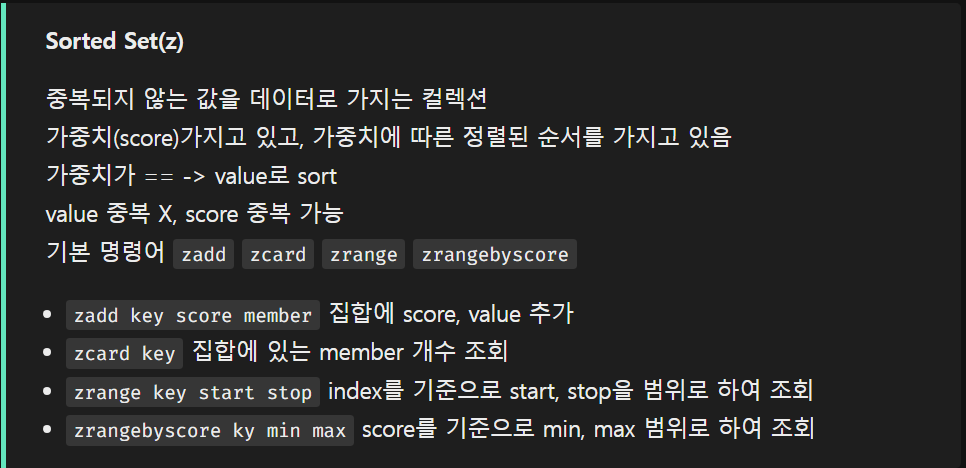



Redis 구조와 특징
Redis는 데이터베이스, 캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 인메모리 데이터 구조 저장소이다.
-
구성요소
- publisher: 메세지를 게시(pub)
- channel: 메세지를 쌓아두는 (queue)
- subscriber: 메세지를 구독(sub)
-
동작
- pusblisher가 channel에 메세지 게시
- 해당 채널을 구독하고 있는 subscriber가 메세지를 sub해서 처리함
-
특징
- channel은 이벤트를 저장하지 않음.
- channel에 이벤트가 도착 했을 때 해당 채널의 subscriber가 존재하지 않는다면 이벤트가 사라짐
- subscriber는 동시에 여러 channel을 구독할 수 있으며, 특정한 channel을 지정하지 않고 패턴을 설정하여 해당 패턴에 맞는 채널을 구독할 수 있다
-
장점
- 처리 속도가 빠름
- 캐시의 역할도 가능
- 명시적으로 데이터 삭제 가능
-
단점
- 메모리 기반이므로 서버가 다운되면 Redis 내의 모든 데이터가 사라짐
- 이벤트 도착 보장을 못함
Redis 사용시 주의할점
-
시간 복잡도
Single Threaded(싱글 스레드) 사용으로 한번에 하나의 명령만 수행이 가능하므로 처리 시간이 긴 요청의 경우 장애가 발생 -
메모리 단편화
크고 작은 데이터를 할당하고 해제하는 과정에서 메모리의 파편화가 발생하여 응답 속도가 느려질 수 있음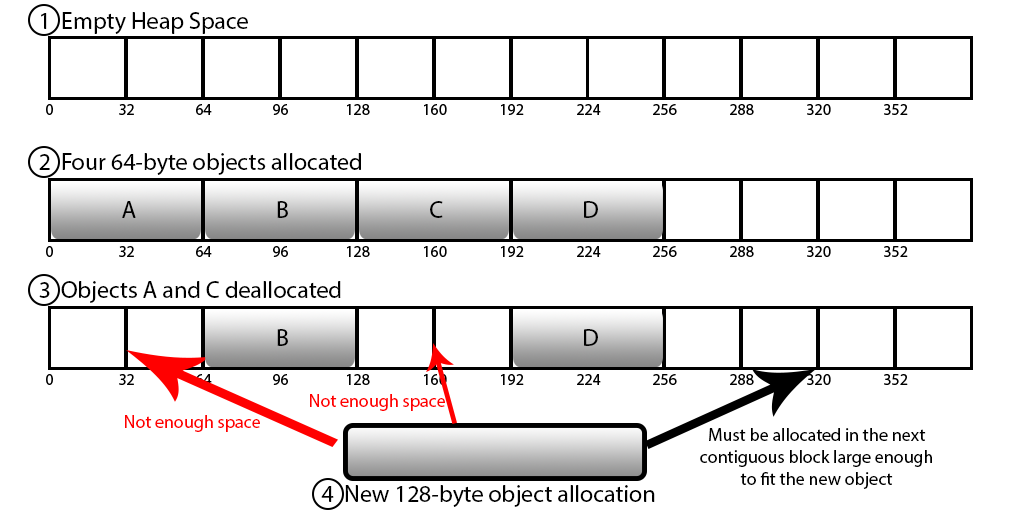
RAM에서 메모리를 할당받고 해제하는 과정에서 위와같이 부분부분 빈 공간이 생기는데, 새로운 메모리 할당 시에 사용 가능한 메모리가 충분히 존재하지만 메모리의 크기만큼의 부분이 없어 마지막 부분에 할당되어 메모리 낭비가 심하게 됨. 이 현상이 계속되면 실제 physical 메모리가 커져 프로세스가 죽는 현상이 발생 할 수도 있으므로, redis를 사용 시에 메모리를 적당히 여유있게 사용하는 것이 좋음 -
주기적인 모니터링
메모리 사용량이 너무 많으면 Redis 서버의 성능 저하나 장애로 이어질 수 있기 때문에 주기적인 모니터링을 통해 메모리를 관리해주어야함 -
레디스는 싱글 스레드로 동작하기 때문에
Key *를scan으로 대체
Collection이 필요한 이유
- 개발 난이도가 낮아진다.
- 문제를 줄여줄 수 있다.
자료구조에 따라서 어떤 상황에서 활용되는지 알아보자.

Redis 장애 포인트
- Redis가 Single Thread임을 무시한 경우
- Hash나 Sort Set에서 데이터를 많이 저장할수록 느려짐
- 너무 짧은 timeout 값 설정
Redis의 장점
-
높은 성능
모든 Redis 데이터는 메모리에 저장되어 대기 시간을 낮추고 처리량을 높인다. 평균적으로 읽기 및 쓰기의 작업 속도가 1ms로 디스크 기반 데이터베이스보다 빠르다. 이게 가능한 이유는 레디스는 모든 데이터를 메모리에 저장하므로 디스크 I/O 오버헤드가 없습니다. 이로 인해 매우 빠른 읽기와 쓰기 작업을 수행할 수 있습니다. -
유연한 데이터 구조
Redis의 데이터는 String, List, Set, Hash, Sorted Set, Bitmap, JSON 등 다양한 데이터 타입을 지원한다. 이를 통해 레디스는 많은 응용 프로그램에서 데이터 구조를 효과적으로 모델링할 수 있습니다. -
개발 용이성
Redis는 쿼리문이 필요로 하지 않으며, 단순한 명령 구조로 데이터의 저장, 조회 등이 가능하다. 또한, 다수의 언어를 지원한다. -
영속성
Redis는 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있다. 서버에 치명적인 문제가 발생하더라도 디스크에 저장된 데이터를 통해 복구가 가능하다. -
싱글 스레드 방식
Redis는 싱글 스레드 방식을 사용하여 한 번에 하나의 명령어만을 처리한다. 따라서 연산을 원자적으로 처리하여 Race Condition(경쟁 상태)가 거의 발생하지 않는다. 하지만, 멀티 스레드를 지원하지 않기 때문에 시간 복잡도가 O(n)인 명령어의 사용은 주의해서 사용해야 한다.
Redis의 사용 사례
- 캐싱
- 채팅, 메시징 및 대기열
- 랭킹 보드(순위표)
- 인증 토큰 저장(세션 스토어)
- 다양한 미디어 스트리밍
- 실시간 분석
- 위치기반 데이터 타입 사용
Redis를 사용하는 이유
-
높은 성능
레디스는 모든 데이터를 메모리에 저장하므로 디스크 I/O 오버헤드가 없습니다. 이로 인해 매우 빠른 읽기와 쓰기 작업을 수행할 수 있습니다. 또한 단일 쓰레드 모델을 사용하여 데이터베이스 작업을 순차적으로 처리하므로 복잡한 동시성 문제를 피할 수 있습니다. -
다양한 데이터 구조
레디스는 단순한 키-값 구조 이상의 다양한 데이터 구조를 지원합니다. 문자열, 해시, 리스트, 셋, 정렬된 집합 등 다양한 데이터 유형을 저장하고 조작할 수 있습니다. 이를 통해 레디스는 많은 응용 프로그램에서 데이터 구조를 효과적으로 모델링할 수 있습니다. -
캐싱
레디스는 주로 데이터베이스 쿼리나 계산 결과를 캐싱하는 데 사용됩니다. 많은 쿼리 작업을 레디스에 저장하여 데이터베이스에 대한 부하를 줄일 수 있습니다. 레디스는 인 메모리 데이터베이스이므로 빠른 응답 시간을 제공하여 애플리케이션 성능을 향상시킵니다. -
메시지 브로커
레디스는 Pub/Sub 모델을 지원하여 메시지 브로커로 사용될 수 있습니다. 다양한 컴포넌트나 서비스 간의 비동기 통신을 위해 사용되며, 실시간 채팅, 이벤트 기반 시스템, 실시간 분석 등에 적합합니다. -
세션 저장소
레디스는 세션 데이터를 저장하는 데 사용될 수 있습니다. 세션 클러스터링과 부하 분산을 지원하여 대규모 웹 애플리케이션에서 확장성과 고가용성을 제공할 수 있습니다. -
대기열 관리
레디스는 메시지 큐 시스템으로도 사용될 수 있습니다. 작업 처리를 비동기적으로 관리하기 위해 레디스의 리스트 데이터 구조를 활용하여 작업을 대기열에 추가하고, 워커 프로세스가 해당 작업을 처리하는 방식으로 사용할 수 있습니다. 이를 통해 작업의 순서와 우선순위를 조절하고, 작업 처리량을 제어할 수 있습니다. -
실시간 데이터 분석
레디스는 실시간 데이터 처리 및 분석에 사용될 수 있습니다. 스트림(Stream) 데이터 구조를 활용하여 이벤트 시퀀스를 저장하고, 소비자가 실시간으로 이벤트를 처리하고 분석할 수 있습니다. 이를 통해 실시간 대시보드, 실시간 알림, 로그 분석 등 다양한 실시간 데이터 처리 시나리오를 구현할 수 있습니다. -
분산 환경 지원
레디스는 마스터-슬레이브 복제, 클러스터링 등의 기능을 제공하여 데이터의 가용성과 확장성을 높일 수 있습니다. 여러 서버에 데이터를 분산 저장하고 복제하여 고가용성을 보장하고, 수평적인 확장이 가능합니다. -
간편한 사용 및 다양한 언어 지원
레디스는 간단하고 직관적인 명령어를 제공하며, 다양한 프로그래밍 언어에서 접근할 수 있는 클라이언트 라이브러리를 지원합니다. 이를 통해 레디스를 편리하게 사용할 수 있으며, 다양한 환경과 언어로 개발된 애플리케이션과 통합할 수 있습니다.
이러한 이유들로 인해 레디스는 높은 성능, 다양한 데이터 구조, 캐싱, 메시지 브로커, 세션 저장소, 대기열 관리, 실시간 데이터 분석, 분산 환경 지원 등의 다양한 사용 사례에 적합한 선택지가 됩니다.
Redis를 캐시로 사용할 경우
어떻게 배치하는지에 따라 성능 차이가 납니다. 이를 캐싱 전략이라고도 합니다. 캐싱 전략은 데이터의 유형과 해당 데이터에 대한 엑세스 패턴을 잘 고려해서 선택해야 합니다.
어플리케이션에서 데이터를 읽는 작업이 많을 때 사용하는 전략
어플리케이션에서 데이터를 읽는 작업이 많을 때 많이 사용하는 Look-Aside(Lazy Loading) 전략은 일반적으로 레디스를 캐시로 사용할 때 많이 사용하는 전략입니다.
어플리케이션에서는 데이터를 찾을 때 먼저 캐시에 먼저 확인합니다. 캐시에 데이터가 있으면 캐시에서 데이터를 가져오고 없으면 DB에서 가져와서 레디스에 입력하는 과정을 거칩니다. 캐시는 찾는 데이터가 없을 때만 입력되기 때문에 이를 Lazy Loading이라고도 부릅니다. 이 구조는 레디스가 다운되더라도 바로 장애로 이어지지 않고 DB에서 데이터를 가지고 올 수 있습니다.
대신 캐시에 붙어있던 커넥션이 많이 있었다면 그 커넥션이 모두 DB에 붙기 때문에 DB에 갑자기 많은 부하가 몰릴 수 있습니다. 그래서 이런 경우에 캐시를 새로 투입하거나 DB에만 데이터를 저장했다면 처음에 캐시 미스가 엄청 발생해서 성능에 저하가 올 수 있습니다. 이럴 경우 DB에서 데이터를 캐시에 데이터를 밀어 넣어주는 작업을 할 수 있는데 이를 cache warming이라고도 합니다.
데이터를 쓸 때 사용하는 전략
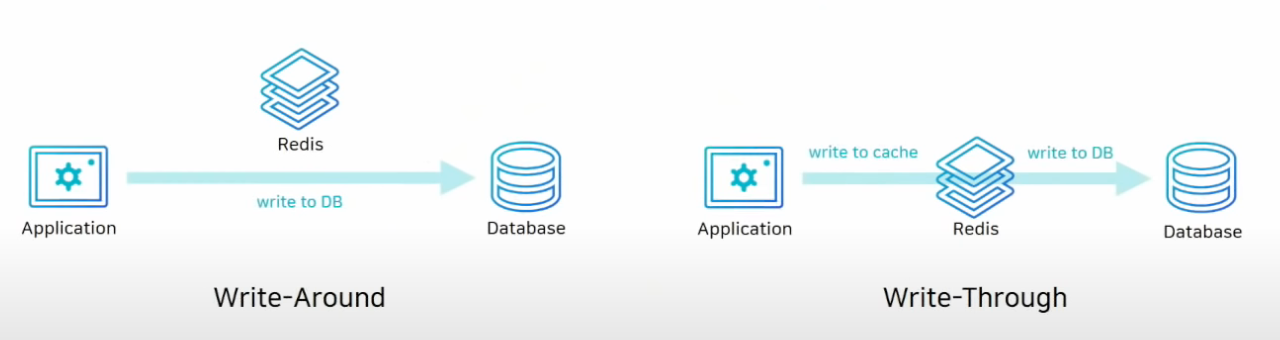
-
왼쪽의 Write-Around 방식은 DB에만 데이터를 저장합니다. 일단 모든 데이터는 DB에 저장되고 cache miss가 발생한 경우 cache에 데이터를 끌어오게 됩니다. 이 경우엔 캐시 내의 데이터와 DB 내의 데이터가 다를 수 있다는 단점이 있습니다.
-
오른쪽의 Write-Through 방식은 DB에 데이터를 저장할 때 캐시에도 함께 저장하는 방법입니다. 캐시는 항상 최선 정보를 가지고 있다는 장점이 있지만 저장할 때 마다 두 단계 스텝을 거쳐야 하기 때문에 상대적으로 느리다. 그리고 저장하는 데이터가 재사용되지 않을 수 있는데 무조건 캐시에 넣어버리기 때문에 일종의 리소스 낭비로 볼 수 있습니다. 그래서 이렇게 데이터를 저장할 때 몇 분 혹은 몇 시간만 데이터를 보관하겠다는 의미인 expire time을 설정해주는 것이 좋습니다. 근데 이 값의 관리를 어떻게 하는지가 장애 포인트가 될 수 있습니다.
Redis에서 데이터를 영구 저장하려면?
레디스는 인메모리 데이터 스토어
- 서버 재시작 시 모든 데이터 유실
- 복제 기능을 사용해도 사람의 실수 발생 시 데이터 복원 불가
- 레디스를 캐시 이외의 용도로 사용한다면 적절한 데이터 백업이 필요
영구 저장하는 방법
-
AOF(Append Only File)
데이터를 변경하는 커멘드가 들어오면 커멘드를 그대로 저장- 자동 : redis.conf 파일에서 auto-aof-rewrite-percentage 옵션(크기 기준)
- 수동 : BGREWRITEAOF 커맨드를 이용해 CLI 창에서 수동으로 AOF 파일 재작성
-
RDB
스냅샷 방식으로 동작하기 때문에 저장 당시의 메모리를 사진 찍듯 찍어서 저장- 자동 : redis.conf 파일에서 SAVE 옵션(시간 기준)
- 수동 : BGSAVE 커맨드를 이용해 cli 창에서 수동으로 RDB 파일 저장
SAVE 커맨드는 절대 사용 X
선택 기준
-
백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우
- RDB 단독 사용
- redis.conf 파일에서 SAVE 옵션을 적절히 사용
-
장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우
- AOF 사용
- APPENDFSYNC 옵션이 everysec인 경우 최대 1초 사이의 데이터 유실 가능(기본 설정)
-
제일 강력한 내구성이 필요한 경우
RDB & AOF 동시 사용
Redis 아키텍처의 종류
-
Replication
단순한 복제 연결- replicaof 커맨드를 이용해 간단하게 복제 연결
- 비동기식 복제
- HA 기능이 없으므로 장애 상황 시 수동 복구
- replicaof no one
- 애플리케이션에서 연결 정보 변경
-
Sentinel
자동 페일오버 가능한 HA 구성(High Availability)- sentinel 노드가 다른 노드 감시
- 마스터가 비정상 상태일 때 자동으로 페일오버
- 연결 정보 변경 필요 없음
- sentinel 노드는 항상 3대 이상의 홀수로 존재해야 함
과반수 이상의 sentinel이 동의해야 페일오버 진행
-
Cluster
스케일 아웃과 HA 구성- 키를 여러 노드에 자동으로 분할해서 저장(샤딩)
- 모든 노드가 서로를 감시하며 마스터 비정상 상태일 때 자동 페일오버
- 최소 3대의 마스터 노드가 필요
변경하면 장애를 막을 수 있는 기본 설정 값

