
1. Nori 분석기
- Elasticsearch는 기본적으로 단어를 띄어쓰기로 구분하는 Standard analyzer를 제공한다.
- 이 분석기는 한글 형태소를 분석하고 인덱싱하기에 적합하지 않다.
- 한글은 다른 언어와 달리 조사나 어미 같은 접미사가 명사, 동사 등과 결합하기 때문이다.
- 한글 형태소 분석기 nori를 사용하면 한글의 형태를 고려하여 분석하고 저장할 수 있다.
- Nori는 Elasticsearch 6.6 버전부터 공식 지원하고 있다.
2. Nori 설치
Nori를 사용하기 위해서는 Elasticsearch에 analysis-nori 플러그인을 설치해야 한다.
elasticsearch 컨테이너 접속
docker exec -it {elasticsearch 컨테이너 이름} /bin/bashelasticsearch 플러그인을 통해 nori 설치
bin/elasticsearch-plugin install analysis-norinori 설치 완료 후 elasticsearch restart
docker restart {elasticsearch 컨테이너 이름}3. Nori tokenizer를 이용한 Custom Analyzer
- Elasticsearch는 Analyzer를 통해 입력 데이터를 인덱싱하고 도큐먼트화한다.
- Lucene의 Analyzer는 하나의 Tokenizer와 여러 Filter로 구성된다.
- Tokenizer는 입력 문장을 분리하고, Filter는 분리된 단어를 최종 검색어로 가공한다.
- 우리는 Tokenizer를 Nori로 설정하고 추가 Filter를 구성해 Custom Analyzer를 만들어보자.
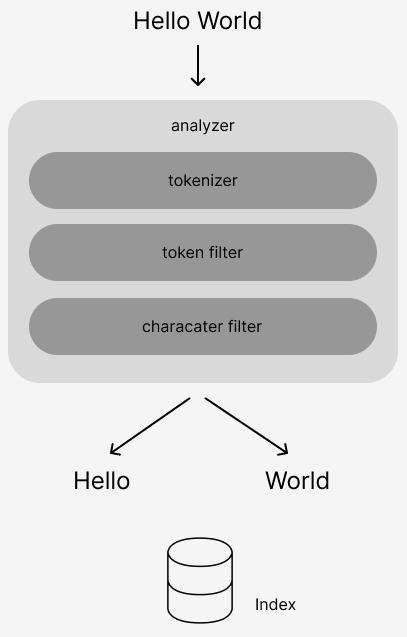
아래와 같이 tokenizer, token filter 등을 조합하여 custom analyzer를 만들 수 있다.
(Elasticsearch에서 사전에 정의하여 제공하는 analyzer들도 있다. https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html)
{
"settings": {
"analysis": {
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"analyzer": {
"my_nori_analyzer": {
"type": "custom",
"tokenizer": "my_nori_tokenizer",
"filter": [
"lowercase",
"stop",
"nori_part_of_speech",
"shingle"
],
"char_filter": [
"html_strip"
]
}
}
}
}
}위에서 사용하고 있는 filter들을 하나씩 살펴보자.
