들어가며
알아보고자 했던 바는 reasoning model을 사용할 때 prompt를 어떻게 줄 것인가에 대해서이다. 작업을 진행하면서 해당 모델이 output을 출력하는데 있어 추론과정(결론에 도달하기 까지의 생각하는 과정) 을 알고싶어 reasoning model을 활용할 계획이였다. 하지만 일반적인 model과 동일하게 prompt를 제시했지만 전혀 다른 결과를 출력했다. 지시문대로 출력을 해달라는 prompt를 잘 따르지 않는 모습을 보였다.
reasoning vs inference
reasoning과 inference의 차이점은 ?
reasoning은 결론에 도달하기 까지의 논리적인 사고 과정 전체 또는 사고 능력 자체를 의미한다. inference는 주어진 정보로부터 구체적인 결론을 이끌어내는 행위 또는 그 결과 자체를 의미한다.
핵심은 reasoning은 어떻게 그 결론에 도달했는가? (HOW?)이고, inference는 주어진 정보로부터 무엇을 결론으로 이끌어낼 수 있는가?(What?) 이다.
| 특징 | 추론 모델 | 일반 모델 |
|---|---|---|
| 주요 목적 | 명시적인 단계별 문제 해결 및 논리적 추론 | 범용 텍스트 생성 및 이해 |
| 문제 해결 접근 방식 | 문제를 더 작은 하위 단계로 분해하고 중간 추론 단계를 보여줌 ("생각 단계") | 중간 단계를 보여주지 않고, 직접 결과 출력 ( 패턴 기반 다음 토큰 예측 ) |
| 출력 구조 | 명확한 추론 단계 구분을 통해 고도로 구조화 | 유연한 대화형이며, 추론과 다른 내용이 혼합될 수 있음 |
| 사고 사슬 (CoT) | 핵심 아키텍처 및 훈련 과정에 내장됨 | 사고 사실 프롬프팅을 사용할 수 있지만, 본질적으로 설계된 것은 아님. 프 롬프트에서 명시적으로 요청 필요 |
| 계산 효율성 | 단계별 처리로 인해 특히 추론 시 더 많은 컴퓨팅 자원이 필요 | 추론 시 상대적으로 낮은 컴퓨팅 요구 사항 및 일반적으로 직접 응답에 더 효율적 |
open-source reasoning model
작업 시 고려했던 오픈 소스로 공개된 reasoning 모델은 다음과 같다.
DeepSeek-R1
https://huggingface.co/deepseek-ai/DeepSeek-R1

큰 AI 모델의 생각하는 방식(추론 패턴)을 작은 AI 모델에게 가르쳐(증류), 그 결과 소형 모델에서 강화학습(RL) 을 통해 발견된 추론 패턴과 비교하여 더 나은 성능을 보인다는 것을 입증한다.
DeepSeek는 DeepSeek-R1이 생성한 추론 데이터를 사용하여 여러 dense model을 미세조정한 모델들을 오픈소스로 공개했다.

EXAONE-Deep-7.8B
https://huggingface.co/LGAI-EXAONE/EXAONE-Deep-7.8B?local-app=vllm
논문 : https://arxiv.org/pdf/2503.12524
EXAONE의 추론 모델이 발표되었다. 아무래도 한국어 특화 모델이기에 더 좋은 성능을 보일 수 있겠다라는 생각이 들었다. EXAONE-Deep-7.8B은 EXAONE 3.5 시리즈를 기반으로 추론 과제에 특화하여 미세조정된 버전이다. 언어모델의 추론능력을 향상시키기 위해 SFT에 160만개, DPO에 2만개 그리고 Online RL에 추가적으로 1만개의 instance를 활용했다고 한다.
학습 템플릿은 다음과 같다. and 태그 내에서 추론을 수행하며, step-by-step logical progression along with reflection , self-checking, and correction 을 수행하도록 학습되었다.

논문에서는 모델 성능 평가 결과를 다음과 같이 주장한다.
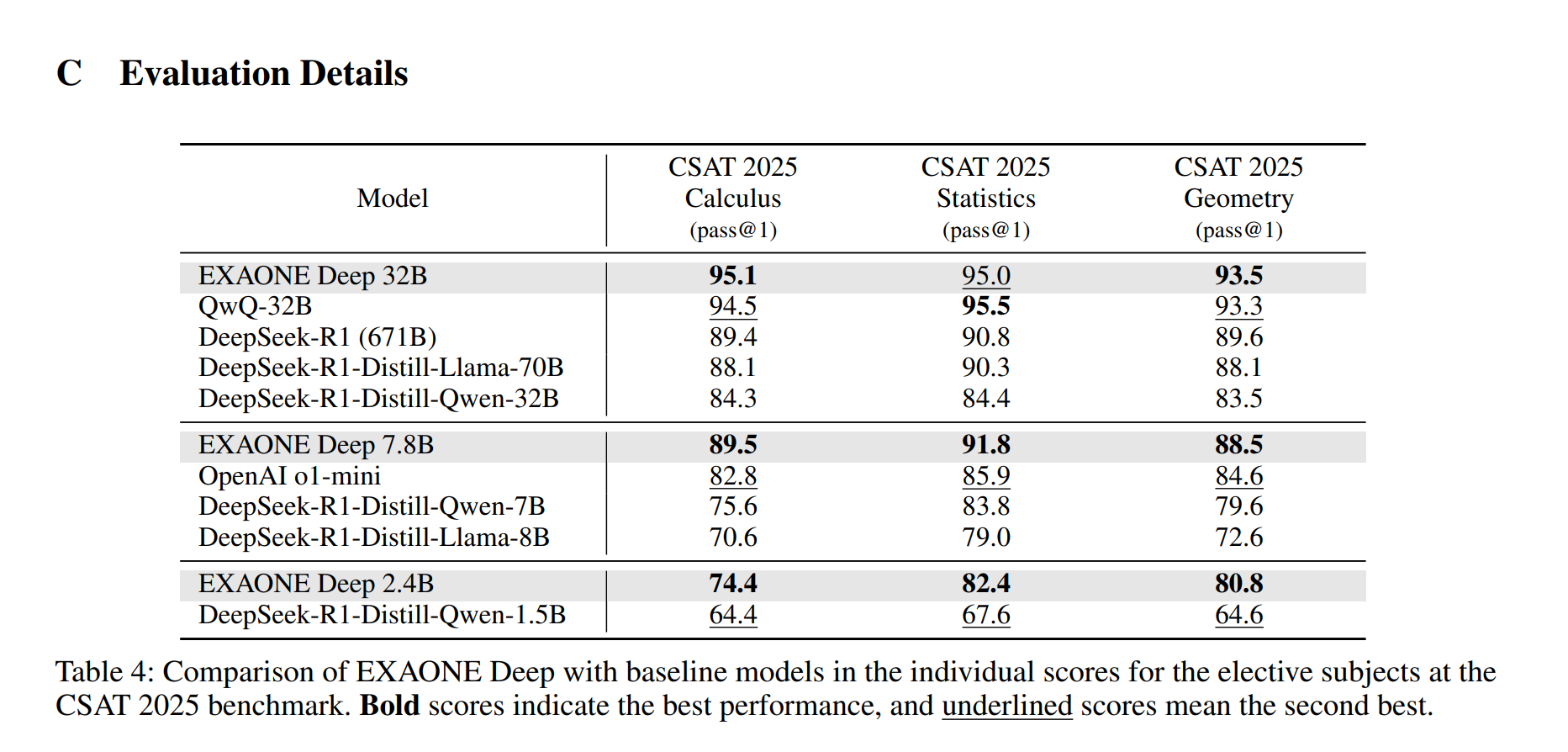
2.4B 모델은 DeepSeek-R1-Distill-Qwen-1.5B [2]보다 우수한 성능을 보였습니다. 7.8B 모델의 경우, DeepSeek-R1-Distill-Qwen-7B 및 DeepSeek-R1-Distill-Llama-8B [2]와 같은 유사한 규모의 공개 가중치 모델뿐만 아니라 독점 추론 모델인 OpenAI o1-mini [12]보다도 뛰어난 성능을 나타냈습니다. 32B 모델의 성능은 QwQ-32B [13] 및 DeepSeek-R1 [2]과 같은 선도적인 공개 가중치 추론 모델과 경쟁적인 수준이며, 그림 1에서 볼 수 있듯이 DeepSeek-R1-Distill-Qwen-32B 및 DeepSeek-R1-Distill-Llama-70B [2]보다 우수합니다.
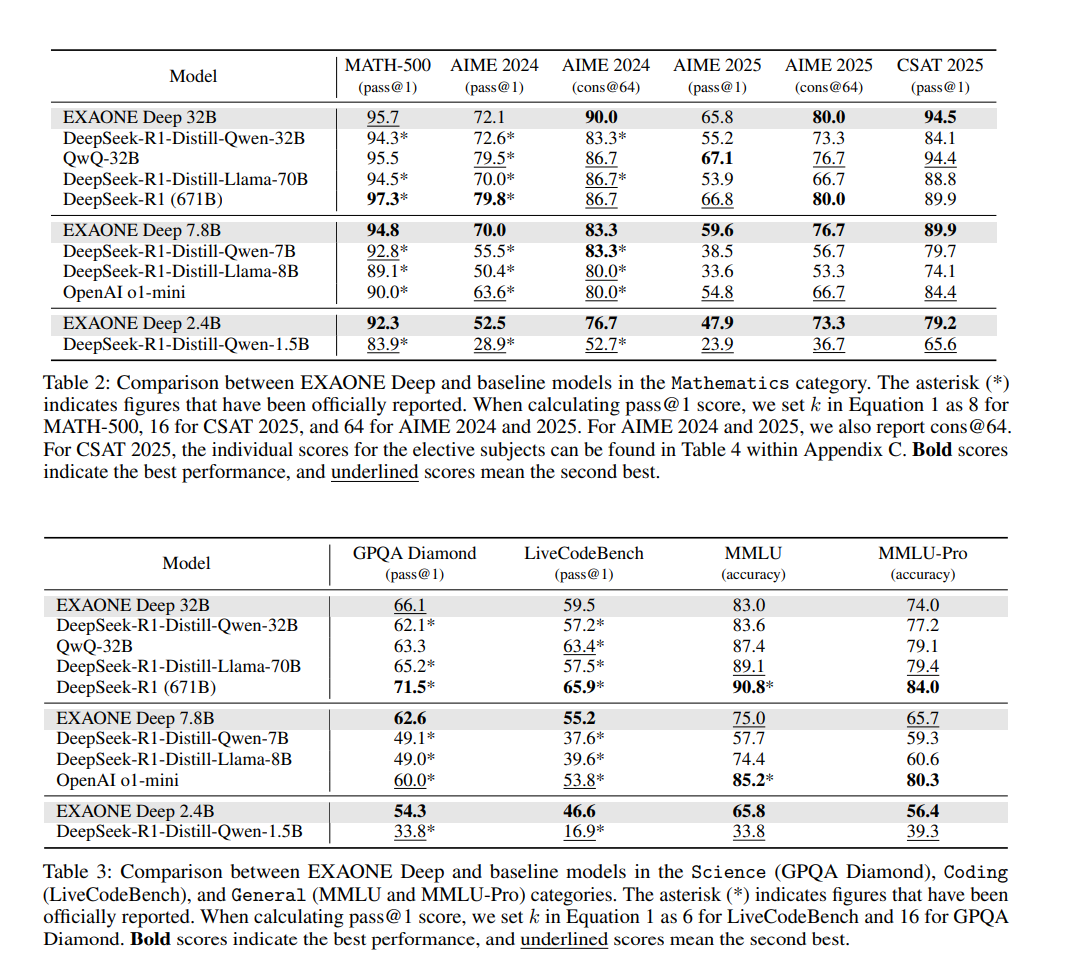
위 표는 수학 분야(MATH-500, AIME 2024 및 2025, CSAT 2025), 과학 (GPQA Diamond), 코딩 (LiveCodeBench), 일반 (MMLU 및 MMLU-Pro) 분야에서의 성능이다.
DeepSeek-R1 기술 보고서에 기술된 설정에 따라 모델 생성의 최대 길이는 32K 토큰으로 설정되었다고 한다. 구체적으로는 각 테스트 케이스에 대해 sampling temperature= 0.6 과 top-p = 0.95을 사용한다고 한다.
모델 평가에 사용된 prompt
- Prompt for Short-Answer Questions
{{question}}
Please reason step by step, and put your final answer within \boxed{}.- Prompt for Multiple-Choice Questions
Question : {{question}}
Options :
A) {{option A}}
B) {{option B}}
...
Please reason step by step, and you should write the correct option alphabet within \boxed{}.- prompt for code generation
You will be given a question (problem specification) and will generate a correct Python program that matches
the specification and passes all tests. You should first think about the step-by-step reasoning process and then
provide the code.
Question: {{question}}QWQ : Qwen-with-question
https://huggingface.co/Qwen/QwQ-32B
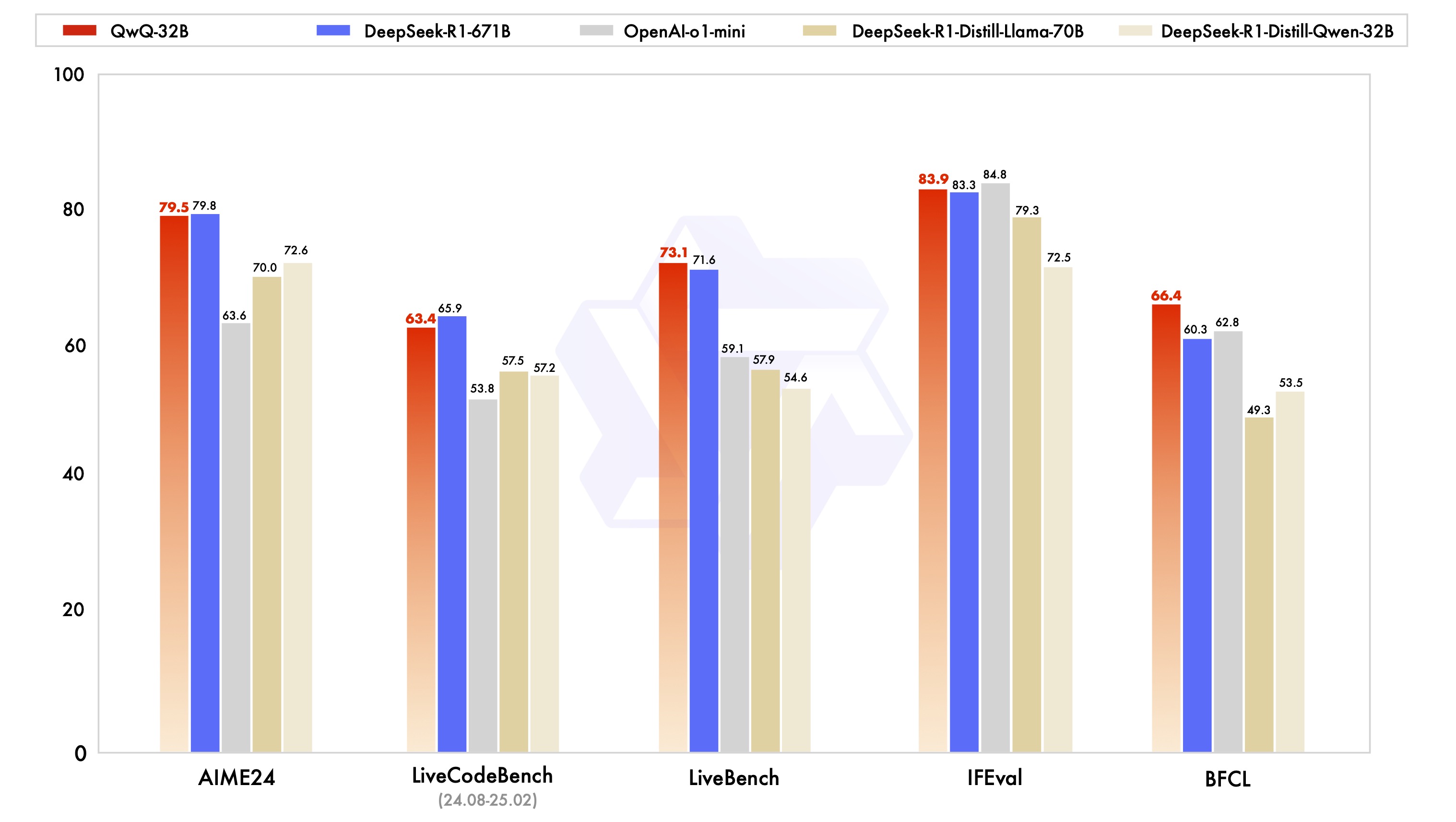
Qwen with question : resoning을 할 수 있도록 fine-tuning 된 모델이다. 해당 모델은 671B인 DeepSeek-R1과 유사한 성능을 보인다고 주장한다. 훨씬 작은 크기로, 높은 성능을 내는 것이다.
해당 모델을 사용할 때 최적의 성능을 얻기 위해서는 다음 설정을 권장한다.
Enforce Thoughtful Output
- 모델이 "\n" 으로 시작하도록 하여 빈 생각을 생성하는 것을 방지하세요. apply_chat_template 와 add_generation_prompt=True 을 설정하면 해당 기능은 자동으로 구현된다. 다만,응답 시작부분에 태그가 없을 수 있는데 이는 정상적인 작동이다.
Sampling parameters
- 끝없는 반복을 피하기 위해 greedy decoding 대신 temperature=0.6, top_p=0.95, min_p=0 설정
- 생성된 출력의 다양성을 유지하면서 희귀한 토큰 발생을 필터링하기 위해 top_k를 20에서 40 사이의 값으로 생성
- 끝없는 반복을 줄이기 위해 presence_penalty 파라미터를 0에서 2 사이로 조정할 수 있습니다. 그러나 더 높은 값을 사용하면 때때로 언어 혼합 및 성능의 약간의 저하가 발생할 수 있다.
배포시에는 vllm을 활용하는 것이 좋다.
https://qwen.readthedocs.io/en/latest/deployment/vllm.html
결론
reasoning 모델들은 추론 과제에서 뛰어난 성능을 보이도록 특화되어 미세조정된 모델들이다. 기반 모델들이 명령어에 따라 미세조정되어 일반적인 지시문을 따르는 능력을 갖추고 있지만, 더 넓은 범위에서 실제 사용 사례를 다루기 위해서는 instruct model을 활용하는 것을 권장한다고 한다.
reasoning 모델은 추론 후 명확하고 간결한 답변을 생성하도록 학습되었으나, 복잡한 지시 수행 능력은 상대적으로 약하다. 따라서 reasoning 모델의 추론 능력과 instruct 모델의 지시 수행 능력을 결합하여 최종 출력을 생성하는 것이 효과적일 것이다.
따라서 다음과 같은 흐름을 활용할 것이다.
- reasoning model prompt : 간단한 문제 제시
- instruct model prompt : reasoning 모델의 추론 과정 + 지시문 (출력 형식, 제한 사항 등)
최종적으로는 instruct model이 resaoning model의 추론 과정을 입력받아 사용자가 원하는 출력 형식에 맞춰 생성하는 것이다. 이러한 방식을 활용해 더욱 높은 결과물을 얻을 수 있을 것이라 판단한다.
