🔵 너비우선탐색, BFS
▶ BreadthFirst Search
✔ 그래프 순회
DFS는 한 우물만 계속 파다가 끝을 보고 나서야 다른 곳으로 옮기는 데 반해, BFS는 모든 곳을 똑같이 조금씩 판다.

BFS가 이루어지는 방식
처음엔 0번 정점
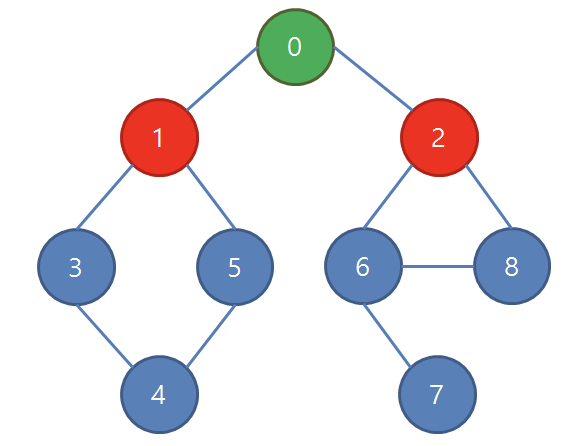
0번 정점과 인접한 정점 모두 방문!
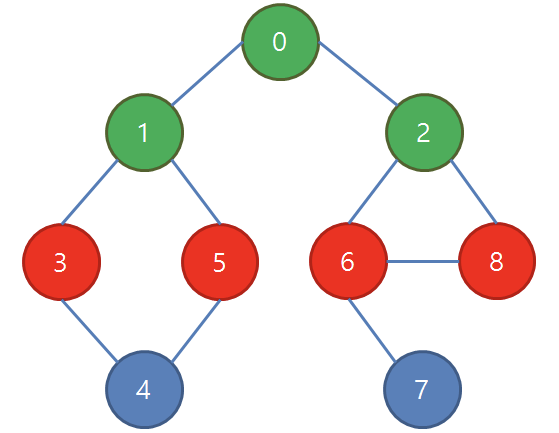
바로 전 단계에서 방문한 1, 2번 정점들로부터 인접한 3, 5, 6, 8 모두 방문!
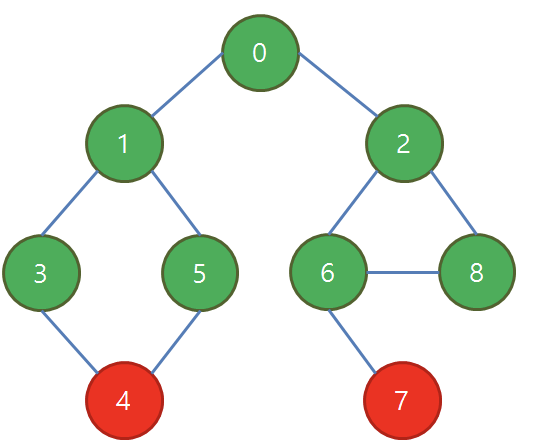
마지막으로 4, 7번 방문
→ 시작점 방문을 0단계라 하고 그 다음부터 1, 2, 3단계라고 부를 때, k단계에 방문하는 정점들은 시작점으로부터 최단거리가 k이다.
여기서 최단거리는 A에서 B로 이동하는 데 필요한 최소 개수의 간선이라고 보면 된다.

가운데에서부터 BFS를 시작했다고 할 때, 색이 얕아지는 쪽으로 퍼져가면서 탐색한다.
👉 bfs 구현 (queue)
dfs는 스택이 필요했던 것에 반해 bfs는 큐를 필요로 한다. dfs는 최근에 방문한 노드들부터 보지만, bfs는 먼저 방문한 노드들부터 보기 때문!
일단 전체 소스코드
#include <iostream>
#include <cmath>
#include <algorithm>
#include <vector>
#include <string>
#include <queue>
using namespace std;
class Graph {
public:
int N; // 정점의 개수
vector<vector<int>> adj;
Graph() :N(0) {}
Graph(int n) : N(n) { adj.resize(n); }
void addEdge(int u, int v) {
adj[v].emplace_back(u);
adj[u].emplace_back(v);
}
void sortList() {
for (int i = 0; i < N; i++)
sort(adj[i].begin(), adj[i].end());
}
void bfs() {
vector<int> visited(N, false); //방문여부 저장 배열
queue<int> Q;
Q.emplace(0);
visited[0] = true;
// 탐색 시작
while (!Q.empty()) {
int cur = Q.front();
Q.pop();
cout << "node " << cur << " visited\n";
for (int next : adj[cur]) {
if (!visited[next]) {
visited[next] = true;
Q.emplace(next);
}
}
}
}
};
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
Graph G(9);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(1, 3);
G.addEdge(1, 5);
G.addEdge(3, 4);
G.addEdge(4, 5);
G.addEdge(2, 6);
G.addEdge(2, 8);
G.addEdge(6, 7);
G.addEdge(6, 8);
G.sortList();
G.bfs();
return 0;
}bfs()를 다시 뜯어보면
void bfs() {
vector<int> visited(N, false); //방문여부 저장 배열
queue<int> Q;
Q.emplace(0);
visited[0] = true;
// 탐색 시작
while (!Q.empty()) {
int cur = Q.front();
Q.pop();
cout << "node " << cur << " visited\n";
for (int next : adj[cur]) {
if (!visited[next]) {
visited[next] = true;
Q.emplace(next);
}
}
}
}먼저 시작점 0을 큐에 넣고 방문을 표시한다. 그리고 큐가 비어있지 않을 때까지 방문을 시도한다! 큐에서 지금 나온 정점의 인접한 노드들 중 아직 방문하지 않은 애들을 다시 큐에다 넣어주는 것이다. 이런식으로 먼저 방문한 노드들부터 차례대로 방문해나간다.
요 bfs()를 깊이를 구하도록 바꿔준다면?
깊이 구하기
dfs는 컴포넌트의 개수나 크기를 구하는데 쓰였다면,
bfs는 깊이/높이를 알아낼 때 쓰인다
void bfs() {
vector<int> visited(N, false); //방문여부 저장 배열
queue<int> Q;
Q.emplace(0);
visited[0] = true;
int level = 0;
// 탐색 시작
while (!Q.empty()) {
int qSize = Q.size();
cout << "------- level : " << level << "-------\n";
for (int i = 0; i < qSize; i++) {
int cur = Q.front();
Q.pop();
cout << "node " << cur << " visited\n";
for (int next : adj[cur]) {
if (!visited[next]) {
visited[next] = true;
Q.emplace(next);
}
}
}
level++;
}하나의 더 큰 반복문으로 감싸주었다. 먼저 현재 Q의 크기를 보고, Q의 크기만큼 안쪽 반복문을 반복한다. K번째 단계가 끝났을 때의 큐 크기는 K번째 단계에서 새로 방문하기 위해 큐에 넣은, K+1번째 단계에 방문할 노드의 개수가 된다.
✔ BFS 의 시간복잡도는?
DFS와 마찬가지로 인접리스트를 사용하였을 때 시간복잡도는 O(|V| + |E|) 이다!
💙 스터디 예제
◼ ch11
🔘II 1260 DFS와 BFS
🔘III 2606 바이러스
🔘I 1389 케빈 베이컨의 6단계 법칙
🔘II 2644 촌수계산
🔘I 2178 미로 탐색
🔘II 7562 나이트의 이동
🔘I 1697 숨바꼭질
🔘I 7576 토마토
🔘I 7569 토마토
🟡V 5014 스타트링크
🟡V 6593 상범 빌딩
