0. 개념설명
프로모션 분석이란?
프로모션 분석은 마케팅 캠페인의 일환으로 진행된 다양한 프로모션 활동들의 효과를 평가하고 측정하는 과정입니다. 이 과정을 통해 기업은 프로모션 활동이 소비자의 구매 결정, 브랜드 인식, 시장 점유율 등에 미치는 영향을 분석할 수 있습니다. 프로모션 분석을 위해 판매 데이터, 소비자 행동 데이터, 온라인 트래픽 데이터 등 다양한 데이터 소스를 활용할 수 있습니다.
프로모션 분석의 필요성
프로모션 분석은 기업이 자원을 효율적으로 배분하고, 마케팅 목표를 달성하기 위해 필수적인 과정입니다. 이를 통해 기업은 다음과 같은 이점을 얻을 수 있습니다.
- 효과적인 프로모션 전략 수립: 어떤 프로모션이 고객의 구매를 유도하고, 브랜드 인지도를 높이는 데 효과적인지 파악할 수 있습니다.
- ROI 최적화: 프로모션에 대한 투자 대비 수익률(ROI)을 측정하고, 마케팅 예산을 더 효과적인 프로모션에 집중할 수 있습니다.
- 시장 이해도 향상: 소비자 반응을 분석함으로써 시장의 현재 요구와 트렌드를 더 잘 이해할 수 있습니다.
- 경쟁력 강화: 경쟁사 대비 우위를 점할 수 있는 마케팅 전략을 개발하고 실행할 수 있습니다.
개별 프로모션 분석 vs 통합 프로모션 분석
- 개별 프로모션 분석
- 특징
- 한 번에 하나의 프로모션 활동만 평가합니다.
- 구체적인 프로모션의 성공 여부와 직접적인 효과를 분석합니다.
- 장점
- 간단하고 명확한 결과 제공
- 특정 프로모션의 직접적인 효과를 빠르게 평가 가능
- 단점
- 다른 마케팅 활동과의 상호작용을 고려하지 않음
- 장기적인 효과나 전체적인 마케팅 전략과의 연계성 부족
- 특징
- 통합 프로모션 분석
- 특징
- 여러 프로모션 활동을 함께 분석하여 전체적인 마케팅 전략의 효과를 평가합니다.
- 프로모션 간의 상호작용 및 시너지 효과를 고려합니다.
- 장점
- 전략적인 의사결정 지원
- 장기적인 브랜드 가치와 고객 관계를 고려한 분석
- 장기적인 효과나 전체적인 마케팅 전략과의 상호작용 이해 가능
- 특징
개별 프로모션분석과 통합 프로모션분석을 함께 분석해야하는 이유
개별 프로모션 분석과 통합 프로모션 분석을 함께 수행함으로써, 보다 정교하고 효과적인 마케팅 전략을 개발할 수 있으며, 이는 최종적으로 기업의 성장과 수익성 향상에 기여하게 됩니다.
1. 전체적인 마케팅 전략의 효율성 평가
개별 프로모션 분석을 통해 특정 프로모션의 성공 여부를 파악할 수 있지만, 통합 프로모션 분석을 함께 수행하면 여러 프로모션 간의 상호작용과 그 영향을 이해할 수 있습니다. 이는 전체 마케팅 전략의 효율성을 평가하는 데 중요합니다.
2. 다채널 프로모션 전략의 최적화
현대 마케팅은 다양한 채널을 통해 이루어집니다. 개별 프로모션 분석과 통합 분석을 병행함으로써, 각 채널의 성과를 정확히 파악하고, 채널 간 시너지를 극대화하는 전략을 수립할 수 있습니다.
3. 고객 행동의 종합적 이해
고객은 다양한 프로모션에 노출되며, 이러한 노출이 고객의 구매 결정에 복합적으로 작용합니다. 개별 프로모션 분석과 통합 분석을 결합함으로써, 고객 행동의 더 깊은 이해를 도모할 수 있습니다.
4. 마케팅 자원의 효율적 배분
통합 프로모션 분석을 통해 얻은 인사이트는 마케팅 자원의 효율적인 배분을 가능하게 합니다. 각 프로모션의 효과를 개별적으로뿐만 아니라 전체적인 관점에서 평가함으로써, 예산을 더 효과적인 프로모션에 집중할 수 있습니다.
5. 장기적 마케팅 전략 수립
개별 프로모션의 성공은 단기적인 성과에 초점을 맞출 수 있지만, 통합 프로모션 분석은 장기적인 관점에서 마케팅 전략을 수립하는 데 도움을 줍니다. 다양한 프로모션의 장기적인 영향력과 지속 가능성을 평가할 수 있습니다.
6. 경쟁 우위 확보
통합 프로모션 분석을 통해 시장 내 경쟁 상황과 자사의 위치를 종합적으로 이해하고, 경쟁 우위를 확보할 수 있는 전략을 수립할 수 있습니다. 이는 경쟁사 대비 우위를 점하는 데 중요한 역할을 합니다.
1. 진행배경
고객사 상황 및 해당 대시보드를 제작하게된 이유
고객사에서는 프로모션 분석 진행시 앰플리튜드를 통한 단일 프로모션 위주의 분석만을 진행했었습니다.
앞서 언급했듯이 단일 프로모션 분석만 진행하게 된다면 결과적으로 장기적인 효과나 전체적인 마케팅 전략과의 연계성이 부족해지는 문제가 있습니다.
이러한 문제를 해결하기위해 프로모션을 통합적으로 확인하는 것에 대한 필요성이 대두되었습니다. 먼저, 통합 프로모션 분석을 위해 1차적으로 앰플리튜드를 통해 얻은 개별 프로모션별 데이터를 스프레드시트에서 취합해 프로모션들끼리 비교하며 인사이트를 도출했습니다.
하지만 시트를 통해 프로모션을 비교 분석하는 것에는 크게 2가지정도의 한계가 있었습니다.
첫째, 프로모션이 진행될 때마다 데이터를 확인하고, 직접 시트에 옮기는 작업을 해야하기 때문에 자동화가 어렵다는 점입니다.둘째, 시트에 텍스트로만 적혀있다보니 해당 데이터가 무엇을 의미하는지 직관적으로 인지하기가 어렵다는 점입니다.
이러한 한계를 극복하기 위해 고안한 것이 전체 프로모션을 한눈에 파악할 수 있는 대시보드를 구현하는 것이였습니다.
2. 진행과정
대시보드는 태블로(Tableau)를 사용하여 구현했습니다.
태블로는 데이터를 분석하고 시각적으로 표시할 수 있는 비즈니스 인텔리전스(BI)툴입니다. 태블로를 통해 대시보드를 제작했을때의 장점은 다음과 같습니다.
- 여러 raw 데이터 통합: 태블로는 스프레드시트, 데이터베이스, 클라우드 서비스 및 빅데이터 플랫폼과 같은 다양한 데이터 원본들을 원활하게 통합됩니다. 이러한 통합을 통해 다양한 소스의 데이터를 연결가능하게 하여 데이터 사일로를 해결하고 포괄적인 분석을 가능하게 합니다.
*데이터 사일로(Data Silo)란? 서로 분리되어 기업의 다른 부서에서 액세스할 수 없는 데이터 스토리지 및 관리 시스템을 의미하며, 이는 전사관점의 의사결정을 방해하고, 비효율성이 증가시킵니다.
- 예시: Excel 스프레드시트에 저장된 판매 데이터와 SQL 데이터베이스에 저장된 고객 데이터가 있다고 가정합니다. Tableau는 두 원본에 동시에 연결할 수 있으므로 데이터를 혼합하고 시각화하여 판매와 고객 인구 통계 간의 관계에 대한 인사이트를 얻을 수 있습니다. - 실시간 데이터 시각화: 태블로는 라이브 데이터베이스 및 스트리밍 데이터를 비롯한 다양한 데이터 원본에 연결하여 실시간으로 데이터 업데이트할 수 있습니다. 이 기능을 사용하면 변경되는 데이터를 빠르게 모니터링하고 분석하여 빠른 의사 결정을 위한 시기적절한 통찰력을 제공할 수 있습니다.
- 다양한 시각화 옵션: 태블로는 막대 차트, 선 차트, 산점도, 지도 등을 포함하여 다양한 시각화 옵션을 제공합니다. 정보를 효과적으로 전달하기 위해 데이터에 가장 적합한 시각화 유형을 선택할 수 있습니다.
- 대화형 대시보드: Tableau를 사용하면 사용자가 직접 데이터를 탐색하고 상호 작용할 수 있는 고도의 대화형 대시보드를 만들 수 있습니다. 사용자는 세부 정보를 드릴다운하고, 데이터를 필터링하고, 임시 분석을 수행하여 데이터 탐색의 깊이를 향상할 수 있습니다.
2-1. 대시보드 스케치
통합프로모션 분석을 위해 정의한 스케치입니다. 해당 스케치는 피그마(Figma)를 통해 작업했습니다. 스케치를 피그마로 제작한 이유는 여러가지가 있는데, 그 중 가장 중요한 이유는 피그마가 다양한 디자인 도구와 기능을 제공하기때문에 원하는 디자인을 쉽고 효율적으로 제작할 수 있기 때문이였습니다.
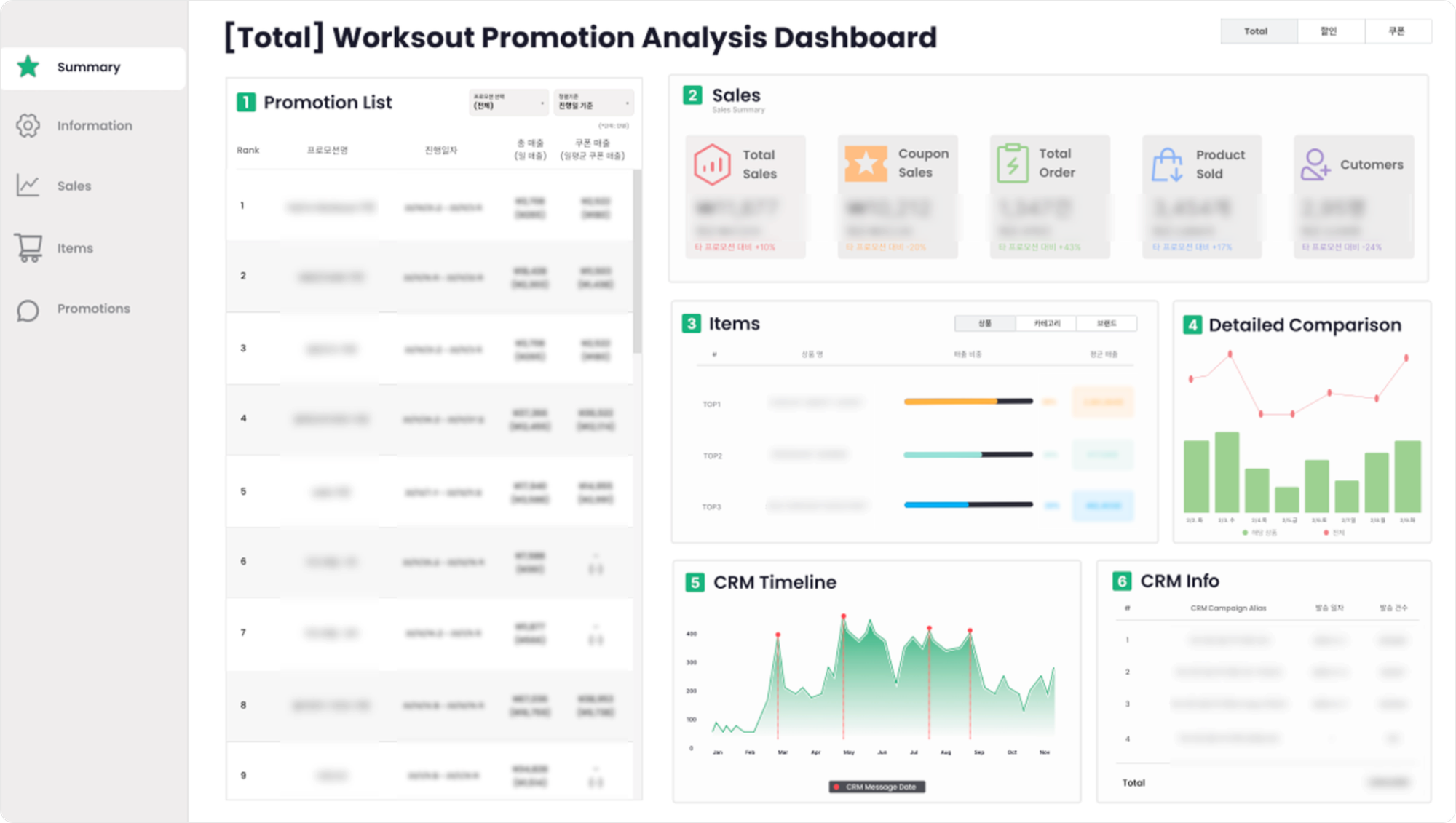
스케치 대시보드를 기준으로 필요한 데이터를 정리보면 데이터는 크게 3가지로 분류할 수 있습니다.
- 프로모션 데이터
- 매출 데이터
- CRM 데이터
프로모션명, 진행일자, 분류, 컨셉 등 프로모션 진행 관련 기본 정보 및 프로모션 관련 아이템 정보가 프로모션 데이터에 해당하며, 각 프로모션에 관련된 실제 결제 정보가 매출 데이터에 해당합니다. 마지막으로 유저들에게 발송된 메시지의 발송일 및 캠페인명, 발송수 등이 CRM 데이터에 해당합니다.
2-2. 필요 데이터 정의 및 추출
필요 데이터 정의
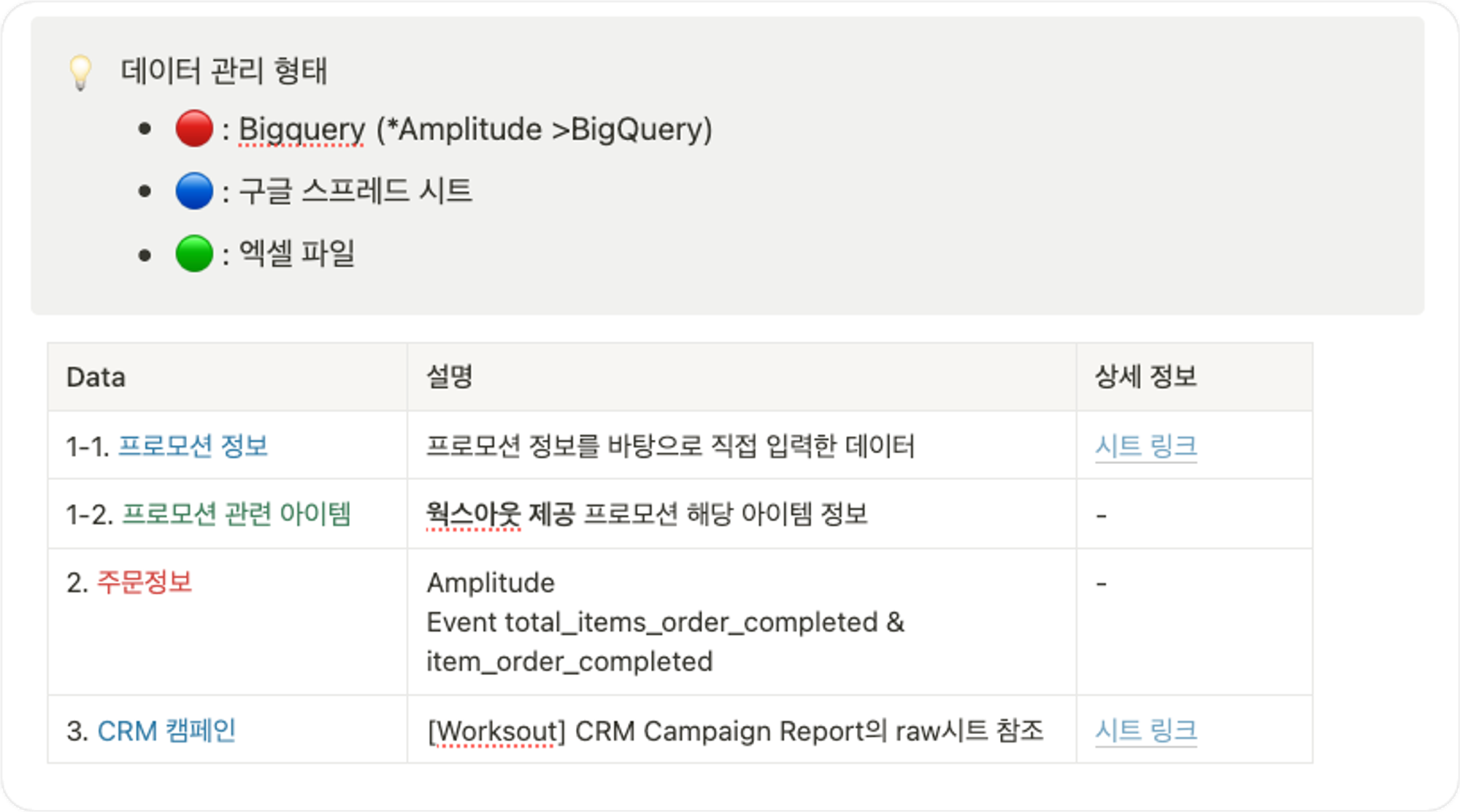
다음으로 앞서 정리한 데이터를 좀 더 구체적으로 정리합니다. 각 항목별 필요한 정보가 정확히 무엇인지, 해당 데이터는 형태로 관리되어야하는지를 비롯해 각 데이터를 연결하기 위해 어떤 컬럼을 키값으로 사용해야는지 등을 파악하여 정리합니다.
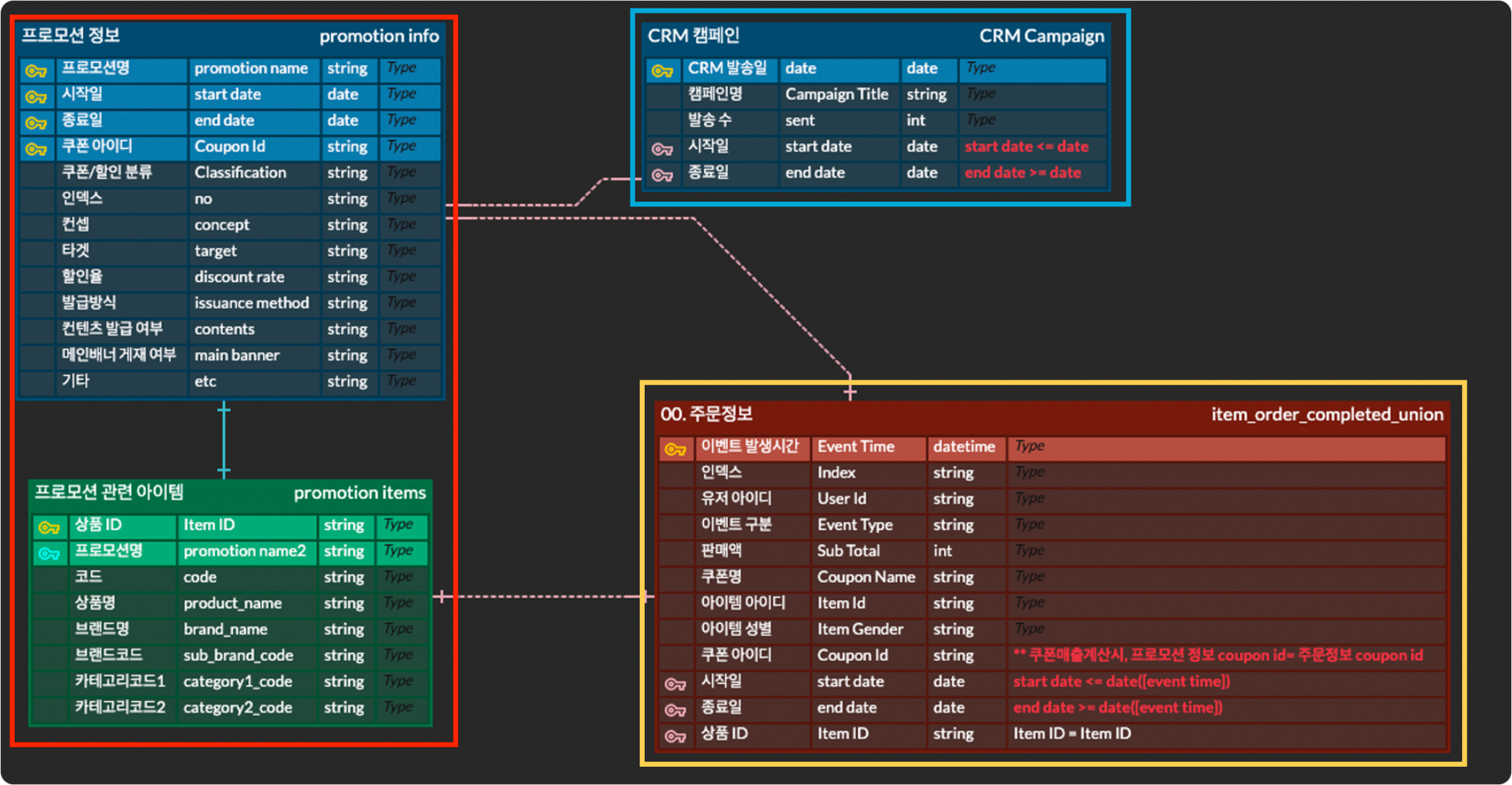
이때 테이블 색상에 차이를 두어 각 데이터가 어떤 소스에서 관리되는지 직관적으로 파악할 수 있도록 합니다.
데이터 추출 요청 및 추출
필요 데이터 정의를 완료했다면, 데이터 추출을 위해 해당 데이터에 대해 알맞은 형태로 적재를 요청하는 단계가 필요합니다. 효율적인 작업을 위해 원하는 이벤트 및 세부 항목(*이벤트 프로퍼티, 유저 프로퍼티, 적재형식, 적재기준일, 요청사유 등) 관련 내용을 최대한 상세하게 기입합니다.
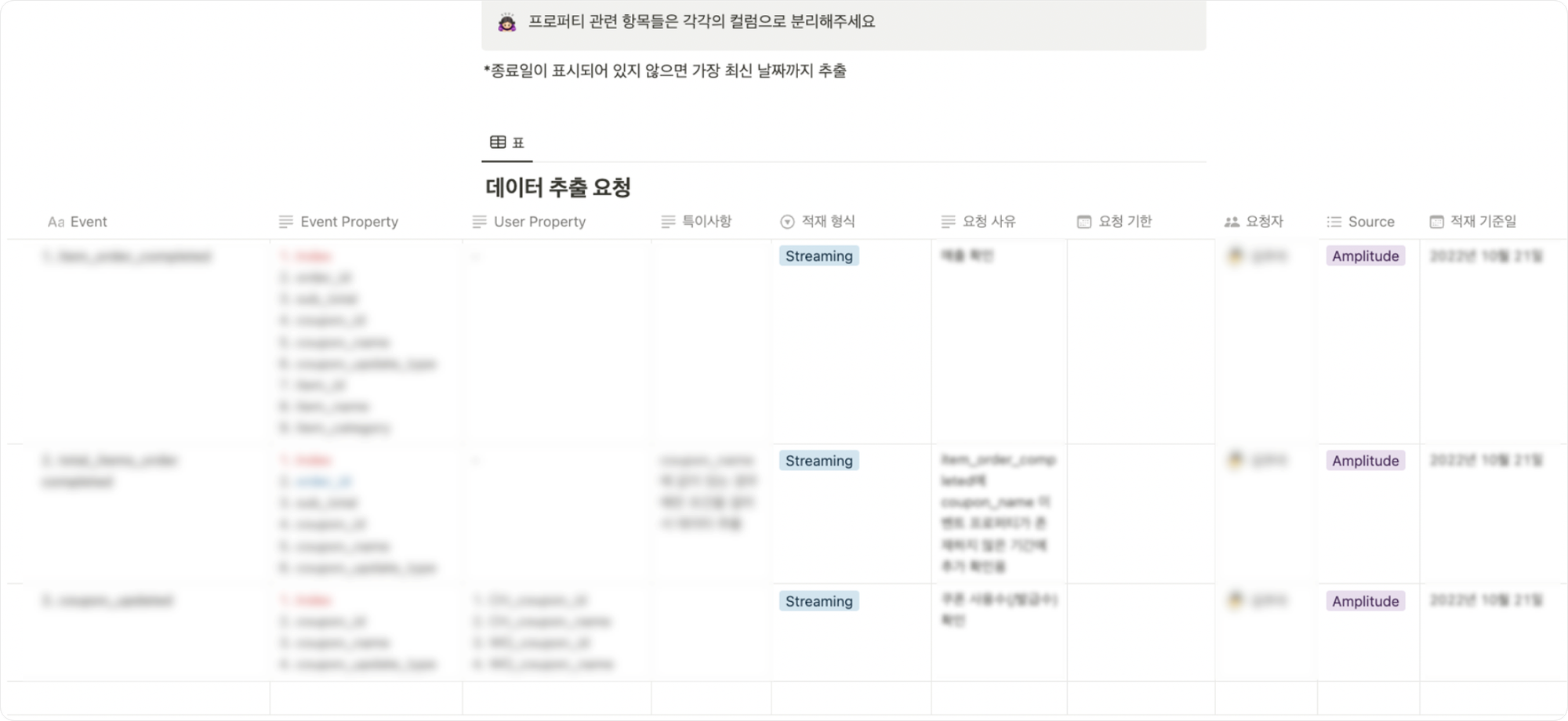
원하는 이벤트 및 세부 항목을 작성한 다음에 해당 내용을 정확히 어떤 형태로 적재되기 원하는지를 보여주는 샘플을 함께 작성합니다.

2-3. 데이터 연결
Amplitude → Bigquery → Tableau
이제 데이터 연결을 진행해야합니다. 해당 프로젝트에는 구글 스프레드시트, 엑셀 파일, 구글 클라우드(빅쿼리)의 소스가 사용되었습니다. 저는 그 중 ‘구글 클라우드’에 초점을 맞추어 데이터 연결과정에 대해 설명하려고 합니다.

구글 클라우드를 사용한 이유는 무엇일까요? 그 이유는 앰플리튜드(Amplitude)에 있는 매출 데이터를 연결하기 위함입니다. 앰플리튜드는 그 자체로 사용성이 높이며, 매출 데이터를 비롯하여 많은 데이터를 손쉽게 확인할 수 있는 툴입니다.
하지만 지금과 같이 더 많은 내용을 확인하기 위해서는 다른 로데이터와 결합을 해서 데이터를 확인하는 과정이 필요합니다. 이 때, 앰플리튜드에서 태블로로 데이터를 바로 전달할 수는 없습니다.

태블로로 데이터를 전송하기 위해서는 앰플리튜드의 로데이터를 가공하여 알맞은 형태로 테이블을 가공해주는 선행작업이 필요합니다. 앰플리튜드와 연동이 가능할 뿐만아니라 태블로와의 연동도 가능해야하며 무엇보다 앰플리튜드로부터 전달받은 로데이터를 가공할 수 있는 플랫폼이여야합니다.
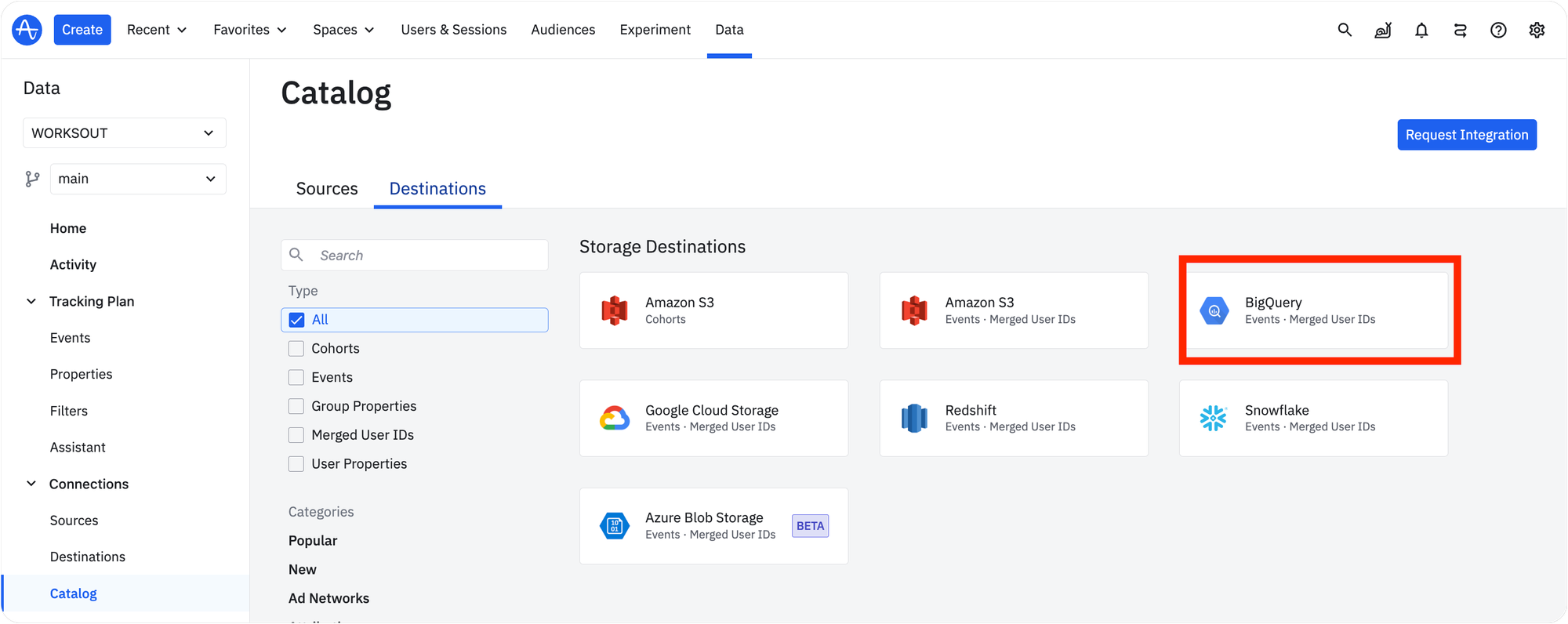
이 작업을 수행할 수 있는 플랫폼은 무엇일까요? 저희는 이러한 요건을 모두 고려할 때 해당 작업을 수행하기에 가장 적합한 것이 Google BigQuery라고 판단했고, 이를 활용하기로 했습니다.

앰플리튜드는 기본적으로 빅쿼리로 데이터를 바로 내보내는 기능을 제공합니다. 우선 해당 기능을 활용해 앰플리튜드 데이터를 빅쿼리에 내보내는 작업을 진행했습니다.
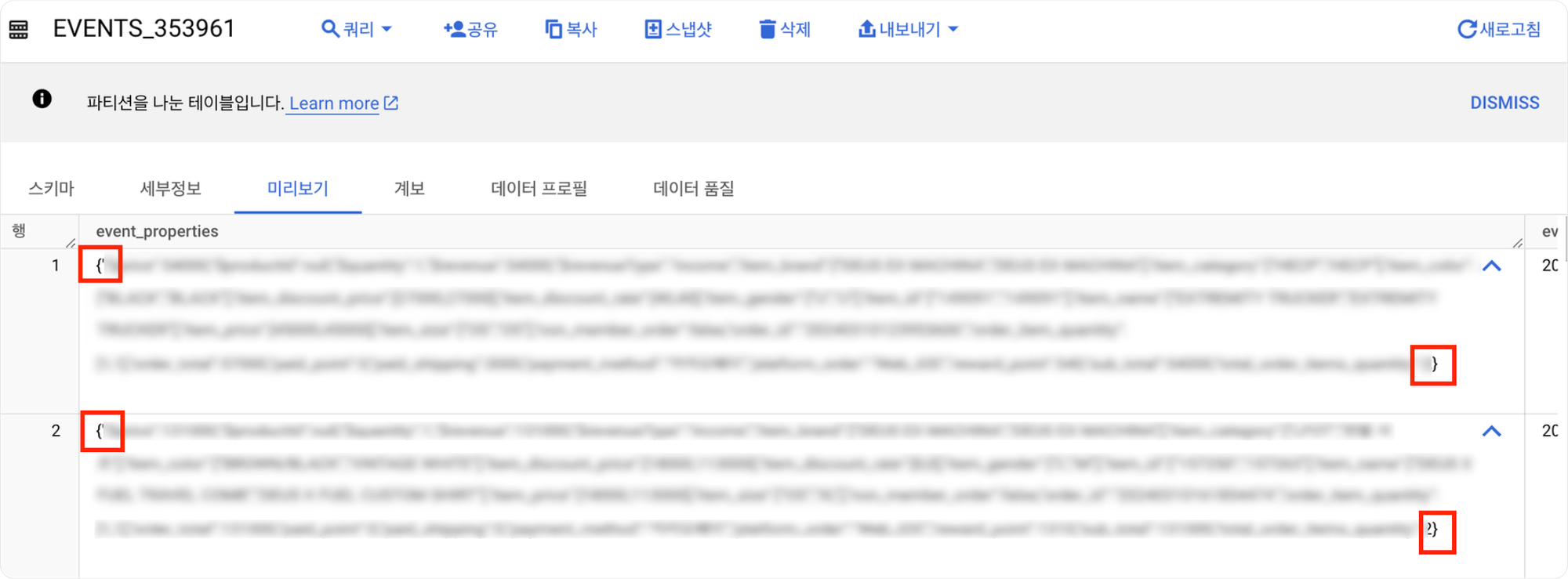
해당 방법을 통해 데이터를 받아올 경우, 이벤트 프로퍼티가 분리된 표 형식으로 넘어오는게 아니라 json이라는 괄호 안에 키와 값형태로 구성돼 있는 포맷(*”{”~”}”)으로 데이터가 불러와지는 문제가 발생했습니다.
태블로는 표 형태의 데이터프레임을 인식하므로, 태블로에 데이터를 연결하기 위해서는 앰플리튜드 로데이터를 전처리하는 과정이 필요했습니다.
해당 데이터를 전처리하기위해서는 로데이터의 형태를 파악해야했습니다. 데이터를 확인한 결과, 텍소노미에 따라 로데이터의 구조가 다를 수 있음을 확인했습니다.
구매이벤트의 경우 아이템 수량이 1개일 경우에는 값으로, 2개 이상일 경우에는 배열로 이벤트 프로퍼티 데이터가 들어오는 구조였습니다.
- 아이템 수량=1인 경우
{"item_brand":"OOO", "item_category":"OOO", "item_id":"000000", "item_name":"OOO", "item_price":"100000", "order_id":"2024_______", "total_order_items_quantity":1 …} - 아이템 수량=2 이상인 경우
{"item_brand":["OOO","XXX"], "item_category":["OOO","XXX"], "item_id":["00000","11111"], "item_name":["OOO","XXX"], "item_price":[10000,100000], "total_order_items_quantity":2}
따라서 데이터 전처리를 위해서는 각 케이스별로 다른 전처리과정을 거쳐야했습니다. 아이템 수량이 1개일경우는 JSON의 값을 파싱하는 처리를 하고, 2개 이상일 경우에는 JSON의 배열을 파싱하는 처리를 진행했습니다.
해당 내용을 처리하는 쿼리문 다음과 같습니다. 케이스별로 결과 테이블이 도출되면, 두 테이블을 유니온하여 한 테이블로 합치는 작업을 진행했습니다.
- 아이템 수량=1인 경우
SELECT event_time, user_id, JSON_VALUE(event_properties, '$.order_id') as order_id, JSON_VALUE(event_properties, '$.item_category') as item_category, JSON_VALUE(event_properties, '$.item_brand') as item_brand, JSON_VALUE(event_properties, '$.item_name') as item_name, JSON_VALUE(event_properties, '$.item_id') as item_id, JSON_VALUE(event_properties, '$.item_price') as item_price FROM amplitude_test.EVENTS_353961 WHERE event_type='total_items_order_completed' AND JSON_VALUE(event_properties,'$.total_order_items_quantity')='1';
-
아이템 수량=2 이상인 경우
WITH item_details AS ( SELECT event_time, user_id, JSON_VALUE(event_properties,'$.order_id') AS order_id, ARRAY( SELECT AS STRUCT item_category, item_name, item_id, item_price, item_brand FROM UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_id')) AS item_id WITH OFFSET AS pos JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_category')) AS item_category WITH OFFSET AS pos_cat ON pos = pos_cat JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_brand')) AS item_brand WITH OFFSET AS pos_br ON pos = pos_br JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_name')) AS item_name WITH OFFSET AS pos_name ON pos = pos_name JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_price')) AS item_price WITH OFFSET AS pos_price ON pos = pos_price ) AS items FROM amplitude_test.EVENTS_353961 WHERE JSON_VALUE(event_properties,'$.total_order_items_quantity')!='1' ) -
두 CASE 합치기
WITH single_item_orders AS ( SELECT event_time, user_id, JSON_VALUE(event_properties, '$.order_id') AS order_id, JSON_VALUE(event_properties, '$.item_category') AS item_category, JSON_VALUE(event_properties, '$.item_brand') AS item_brand, JSON_VALUE(event_properties, '$.item_name') AS item_name, JSON_VALUE(event_properties, '$.item_id') AS item_id, JSON_VALUE(event_properties, '$.item_price') AS item_price FROM amplitude_test.EVENTS_353961 WHERE event_type='total_items_order_completed' AND JSON_VALUE(event_properties,'$.total_order_items_quantity')='1' ), multi_item_orders AS ( SELECT event_time, user_id, JSON_VALUE(event_properties,'$.order_id') AS order_id, item.item_category, item.item_brand, item.item_name, item.item_id, item.item_price FROM amplitude_test.EVENTS_353961, UNNEST( ARRAY( SELECT AS STRUCT item_category, item_name, item_id, item_price, item_brand FROM UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_id')) AS item_id WITH OFFSET AS pos JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_category')) AS item_category WITH OFFSET AS pos_cat ON pos = pos_cat JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_brand')) AS item_brand WITH OFFSET AS pos_br ON pos = pos_br JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_name')) AS item_name WITH OFFSET AS pos_name ON pos = pos_name JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_price')) AS item_price WITH OFFSET AS pos_price ON pos = pos_price ) ) AS item WHERE JSON_VALUE(event_properties,'$.total_order_items_quantity')!='1' ) -- 아이템 수량= 1인 경우의 결과와 아이템 수량= 2 이상인 경우의 결과를 합치기 SELECT * FROM single_item_orders UNION ALL SELECT * FROM multi_item_orders;
해당 작업을 완료한 결과는 다음과 같습니다.
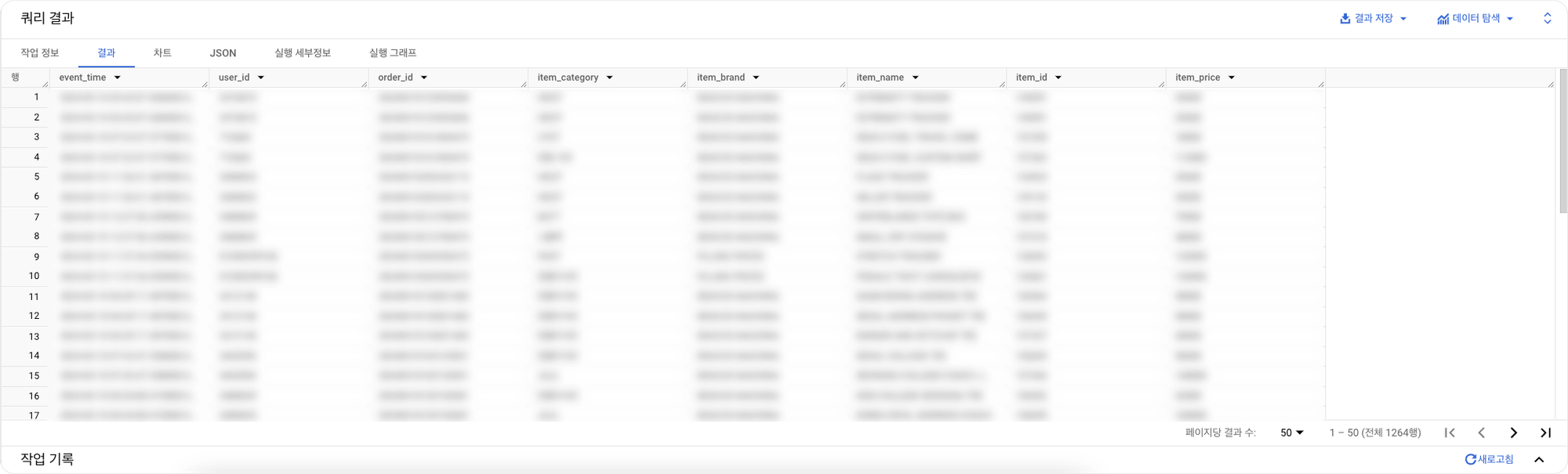
UNNEST()함수를 포함한 단계를 거쳐 데이터 전처리를 진행할 경우 JSON을 데이터프레임형태, 즉 테이블 형식으로 바꾸는 것은 가능했습니다.
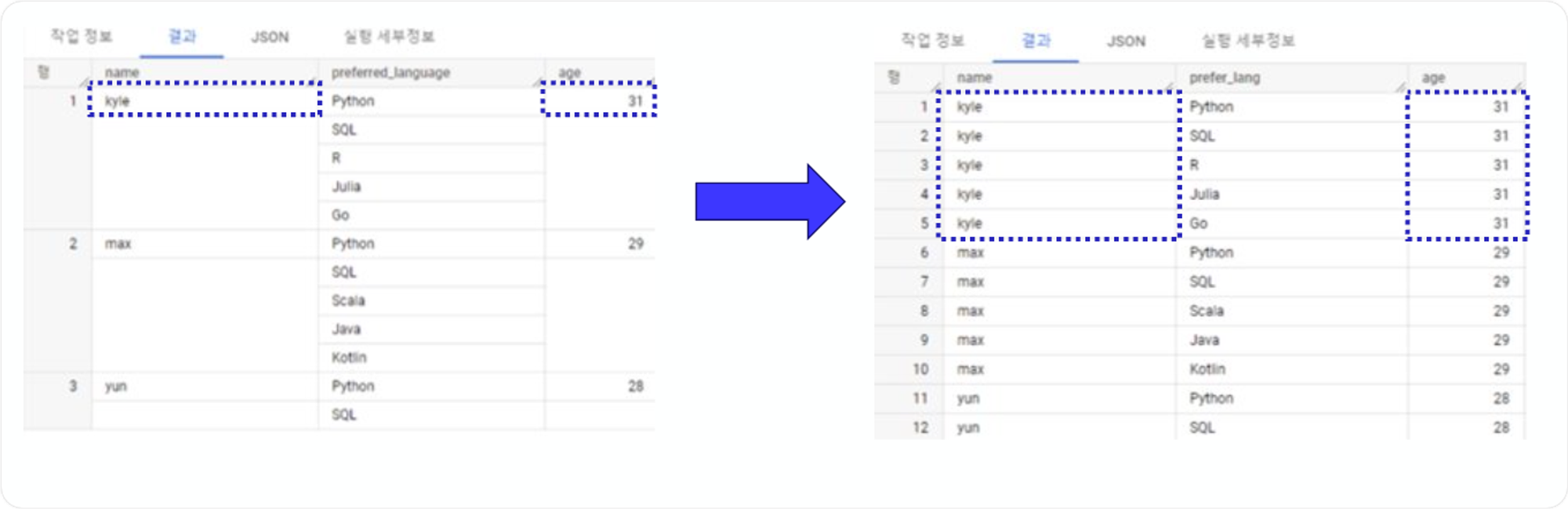
좀 더 직관적으로 UNNEST()함수를 이해하기 위해 예시를 들어보겠습니다. name이라는 컬럼은 값이지만, preferred langauge는 배열일 경우 빅쿼리는 테이블을 왼쪽처럼 인식합니다. 즉 값으로 구성된 행에 배열로 구성된 행을 묶어두는 구조인데요, 이 묶어둔다라는 것을 nest된 상태라고 하고, 값을 배열에 맞춰서 풀어주는 행위를 unnest라고 합니다.
하지만 UNNEST()함수를 사용할 경우 단점이 있었습니다.이 함수는 배열 내 각 요소를 별도의 행으로 확장하는 기능을 제공하기때문에 비정규화된 데이터나 중첩된 데이터 구조를 다룰때 필수적입니다. 그러나 비용관리의 관점에서 주의가 필요하다는 단점이 있습니다. UNNEST() 함수는 배열 내의 각 요소를 별도의 행으로 확장하기때문에 배열에 많은 요소가 포함되어 있을 경우, 결과 데이터 세트의 크기가 급격히 증가할 수 있습니다. 이는 쿼리 처리 시간을 늘리고 처리해야 할 데이터양이 증가함으로써 비용이 증가하는 원인이 될 수 있으며, 처리한 데이터 양에 따라 비용이 청구되는 빅쿼리에서는 쿼리비용의 증가로 이어질 수 있습니다.
실제 프로젝트를 진행하면서 해당 쿼리문을 사용해 약 한달간 매시간마다 업데이트되도록 쿼리를 돌려본 데이터 업데이트를 진행한 결과, 총 8GB를 사용해 월 40만원가량의 비용이 소진되었습니다. 따라서 비용효율성 측면을 고려해 전처리를 클라우드 SQL구문이 아닌 파이썬 코드로 처리하도록 우회했습니다.
앰플리튜드의 데이터를 빅쿼리로 바로 내보내는 것이 아니라 앰플리튜드 서버를 호출하여 데이터를 받아오는 방식으로, 빅쿼리에서 로우 데이터를 쌓은 후 이를 전처리하는 방식 대신 전처리를 완료한 후 가공된 데이터를 빅쿼리에 쌓는 방식으로 변경했습니다.
Amplitude → Google Cloud Storage → Bigquery → Tableau
즉, 기존 Amplitude → Bigquery → Tableau의 단계에서 데이터 전처리를 위해 Google Cloud Storage를 추가한 Amplitude → Google Cloud Storage → Bigquery → Tableau 단계로 진행됩니다.

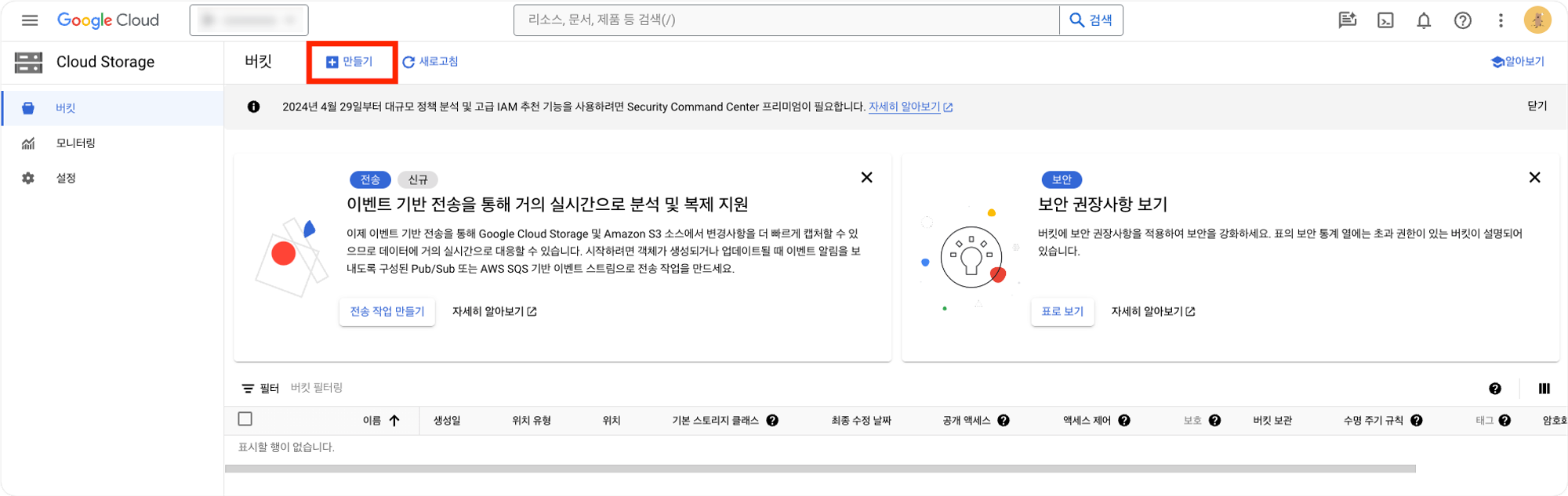
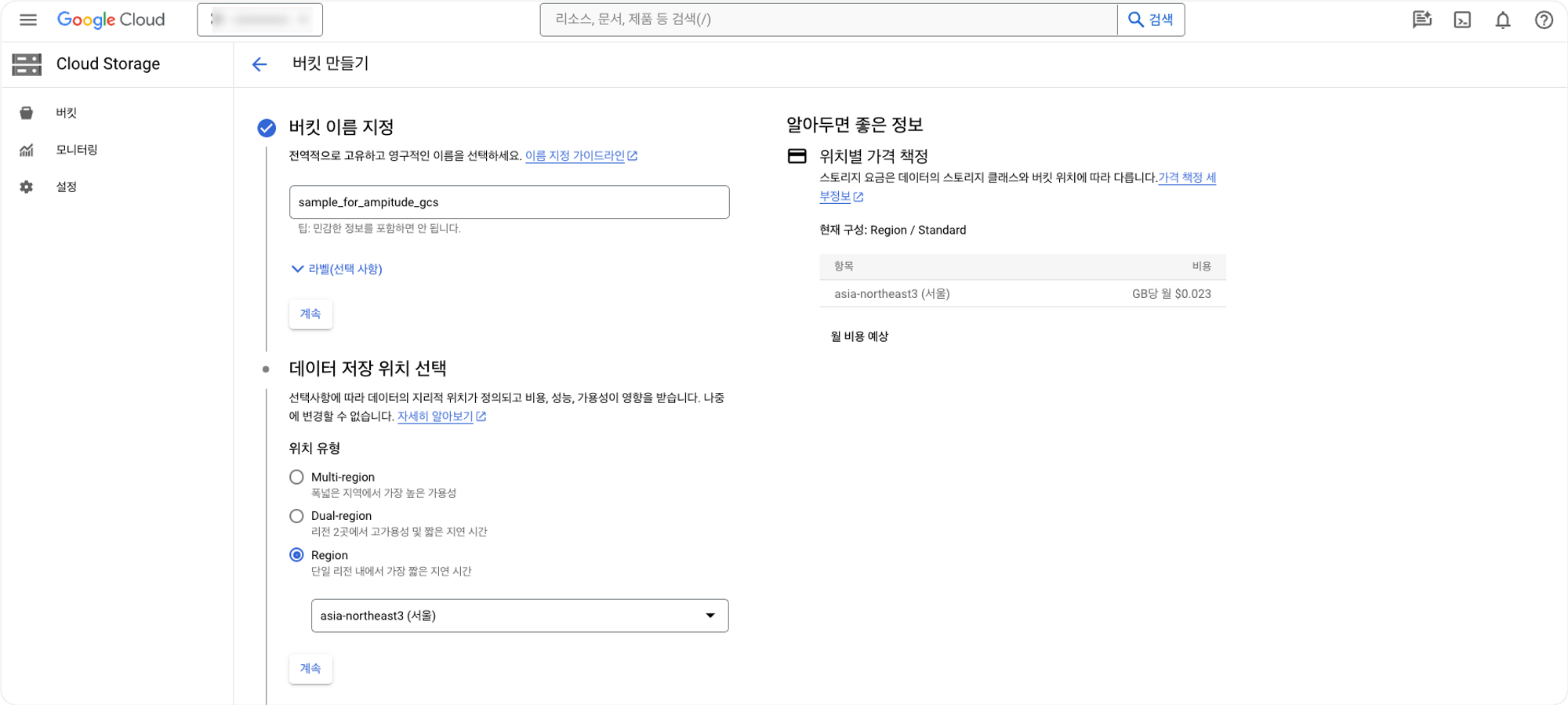
이 작업을 위해서는 우선 앰플리튜드와 Google Cloude Storage를 연결하는 작업을 진행해주어야합니다. 먼저 Cloud Storage에서 고객사 프로젝트 관련 Bucket을 생성합니다.
다음으로 IAM 및 관리자 → 서비스계정을 클릭하여 새로운 서비스계정을 생성합니다.
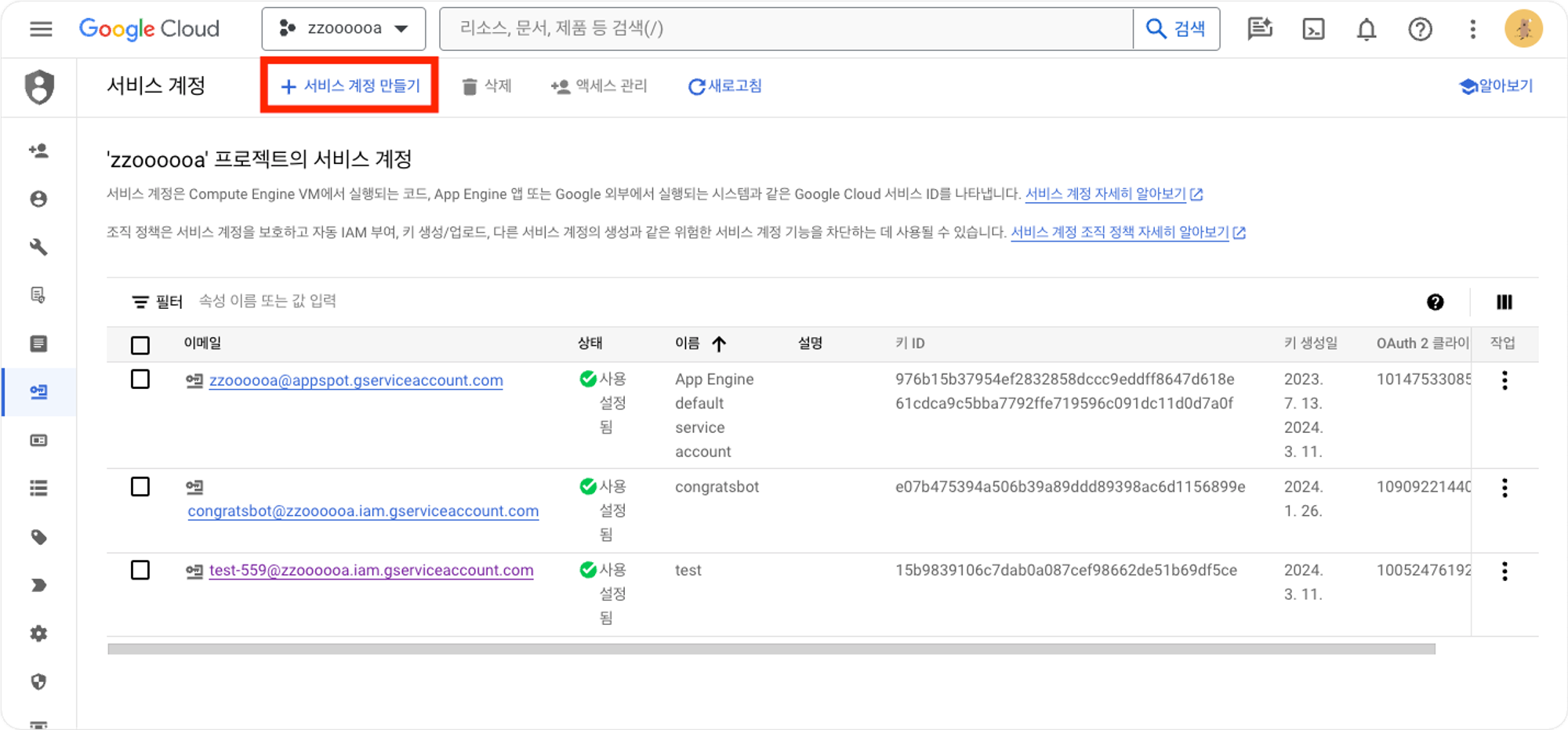
서비스 계정을 생성한 후, 해당 서비스계정에 해당하는 이메일을 확인합니다.
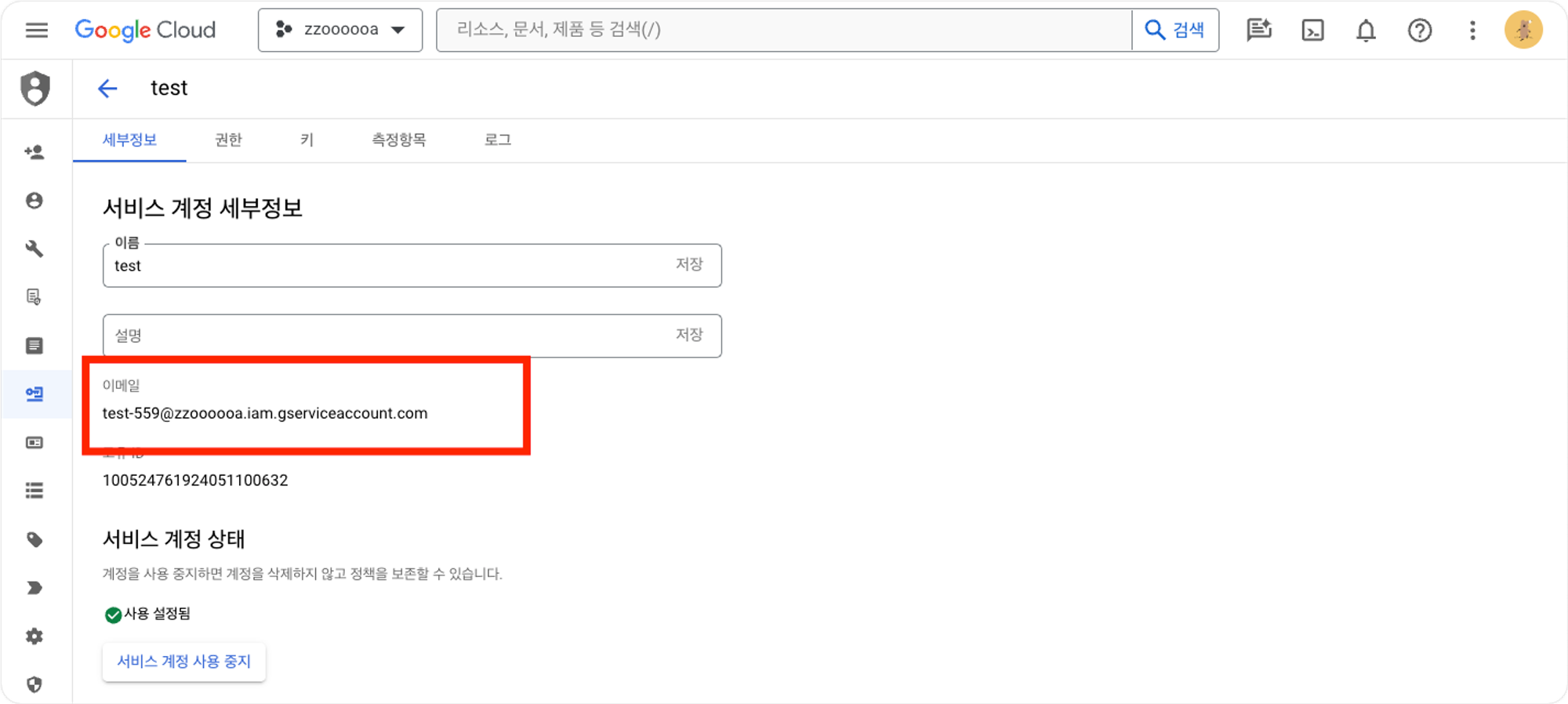
키 → 키추가를 클릭하여 키를 생성합니다.
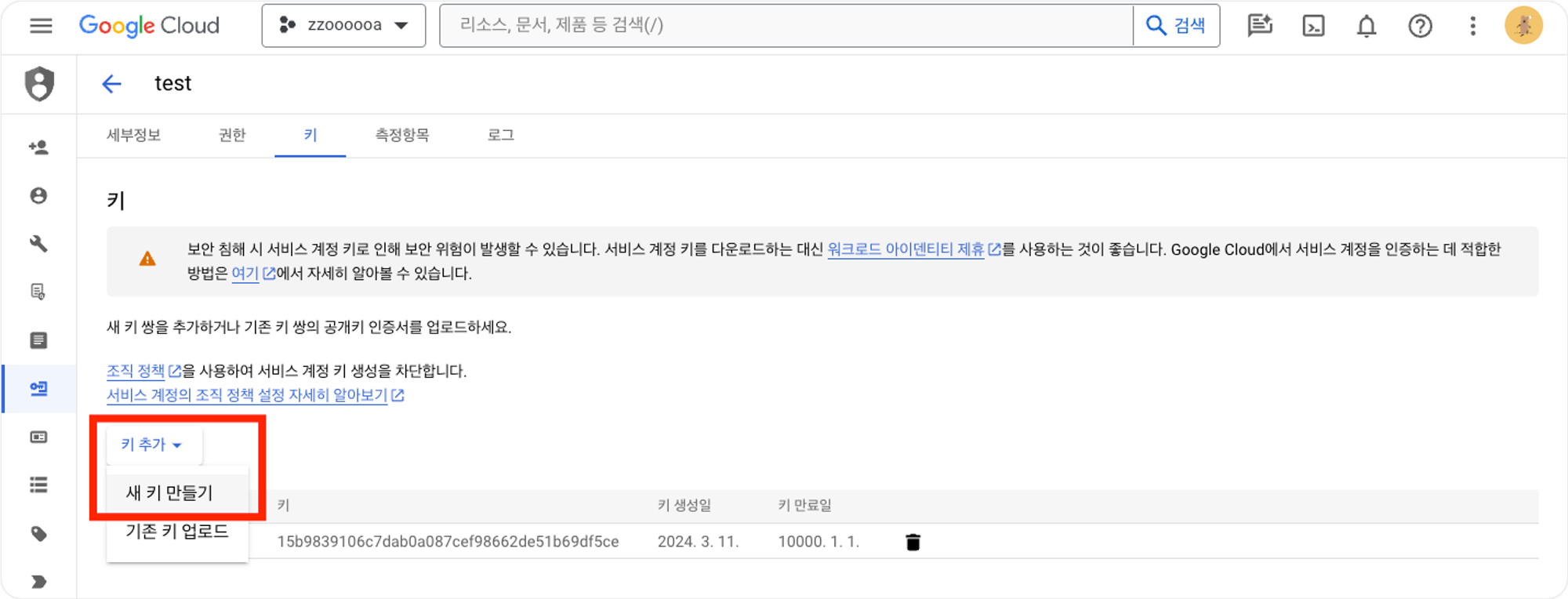
IAM 및 관리자 → 역할을 클릭하여 새로운 역할을 생성합니다. Send Amplitude Event Data to Google Cloud Storage(문서링크)를 참고해서 역할에 다음 5개의 권한을 부여해줍니다.
storage.buckets.getstorage.objects.getstorage.objects.createstorage.objects.deletestorage.objects.list
앞서 생성한 버킷으로 돌아가서 권한을 클릭한 후 액세스 권한 부여를 클릭합니다.
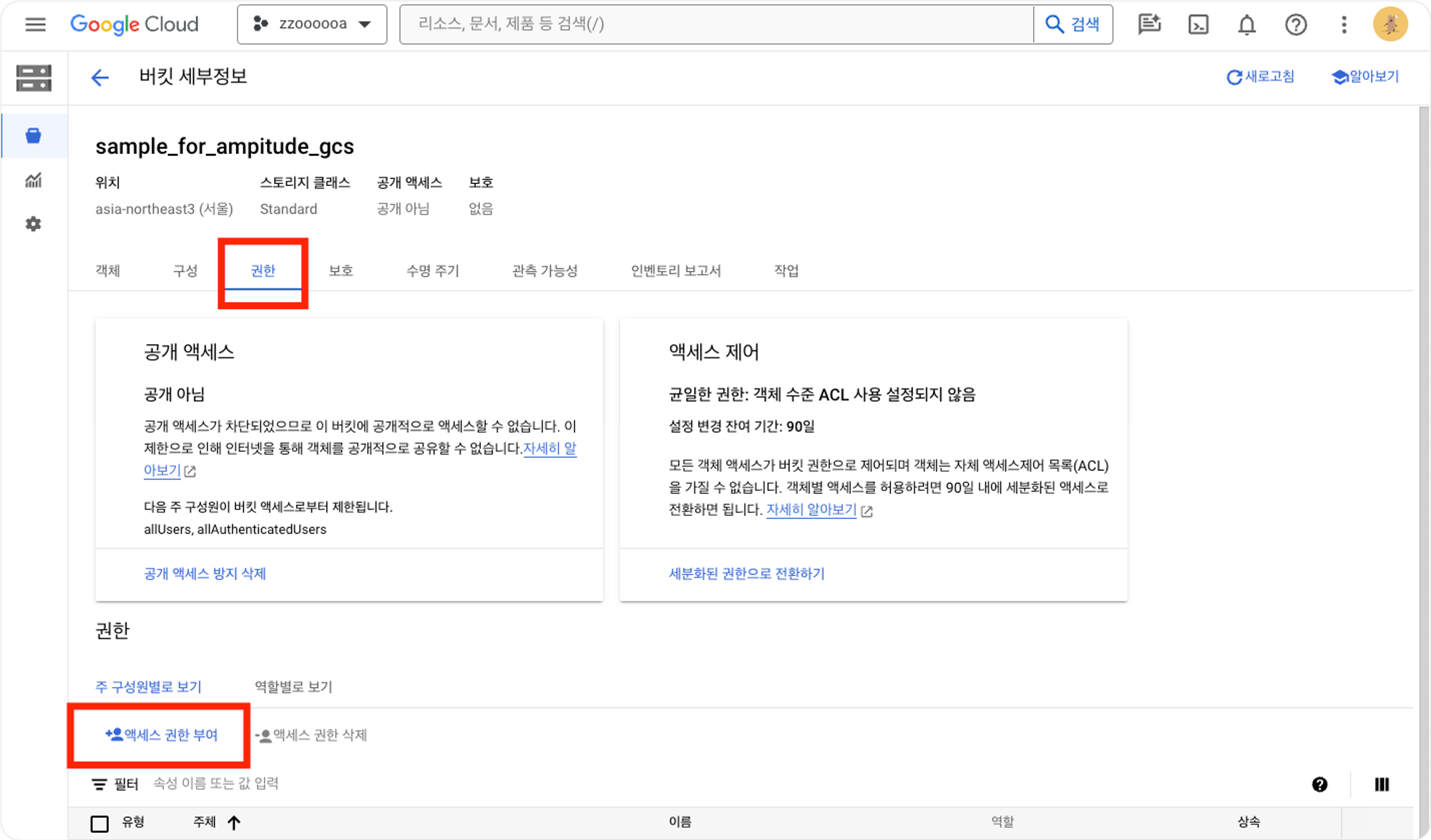
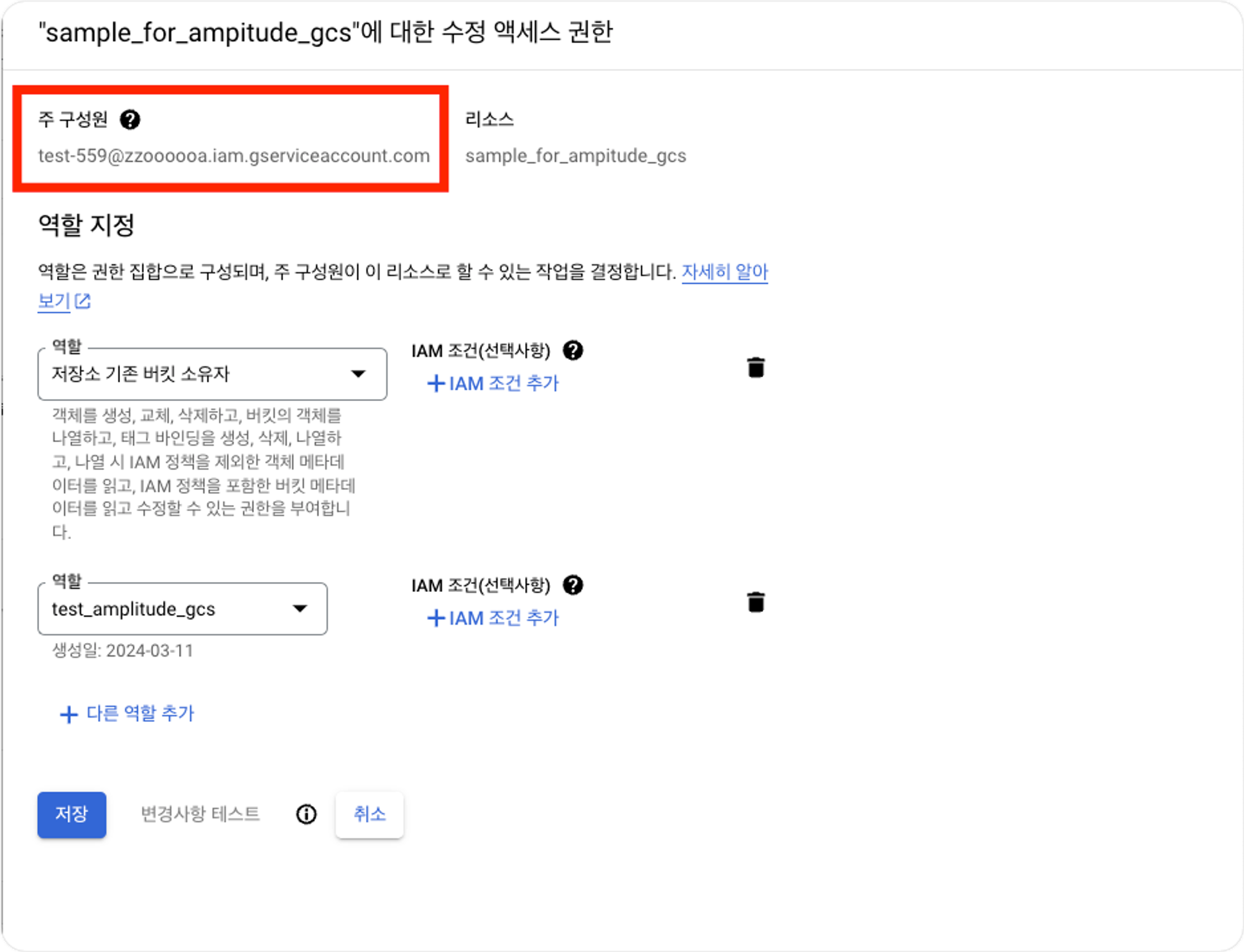
서비스계정에서 추가한 새로운 계정에 해당하는 이메일을 입력한 후, 역할을 지정해줍니다.
이때 역할은 1.저장소 기존 버킷 소유자와 2.역할만들기를 통해 생성한 역할, 총 2개를 부여해줍니다.
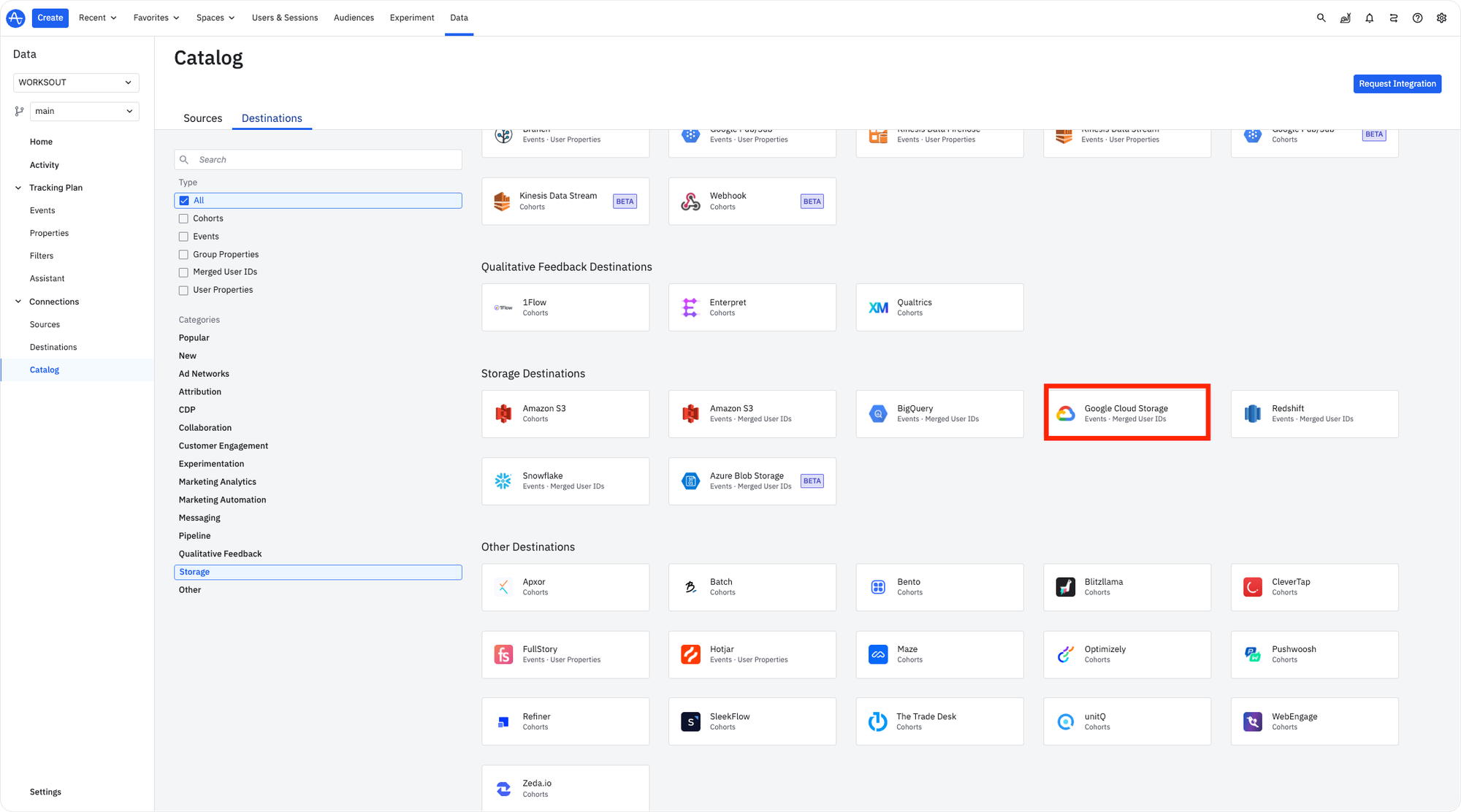
해당 작업까지 완료했으면 앰플리튜드에서 Google Cloude Storage를 연결하는 작업을 진행해주어야합니다. 앰플리튜드 Data → Destination에서 Google Cloud Storage를 클린한 후 GCS로 보낼 데이터를 선택합니다.
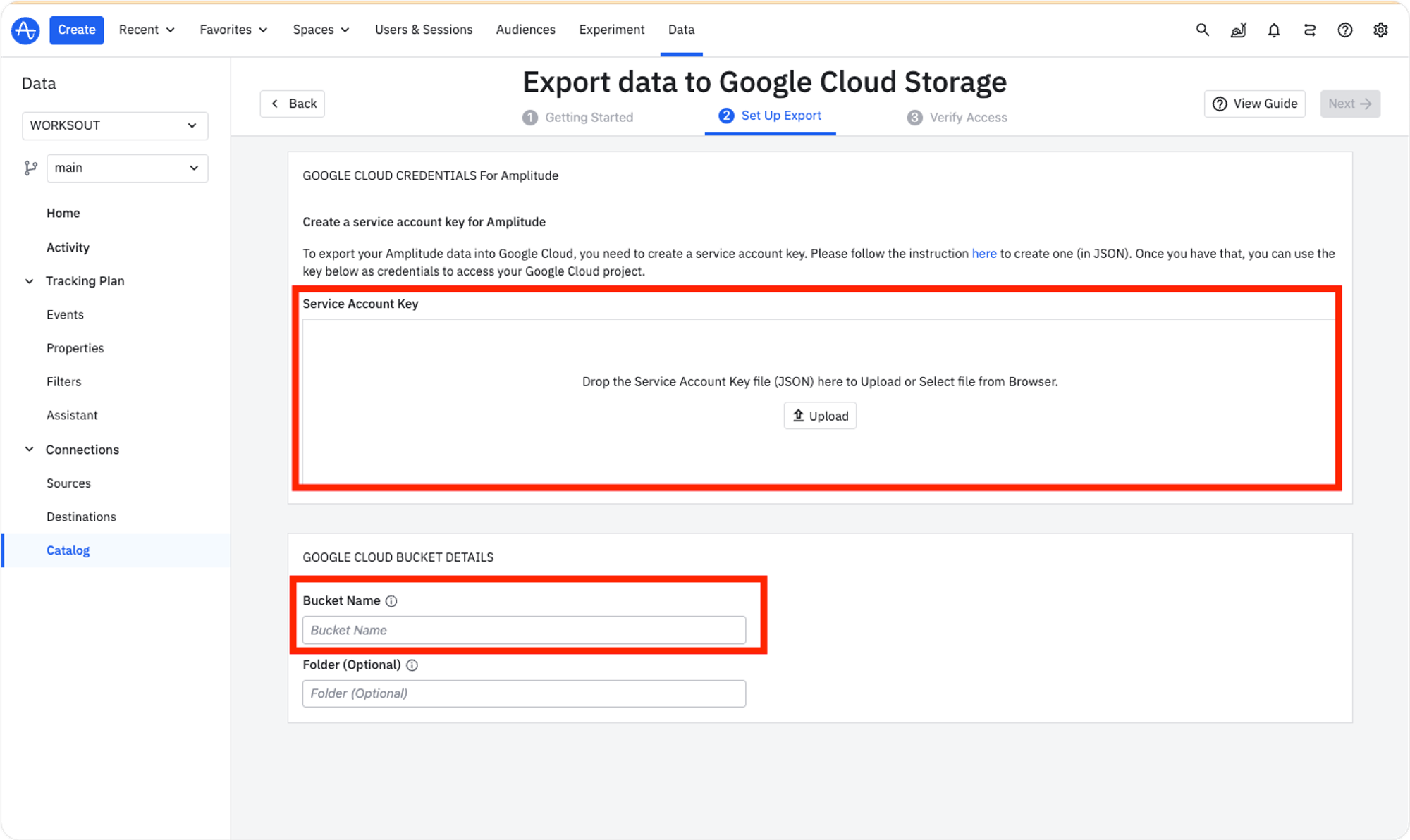
서비스 계정 생성에서 생성한 JSON키 파일을 Service Account Key에 업로드 한 후, 하단의 Bucket Name에 구글 GCS에서 생성한 버킷이름을 입력해줍니다.
해당과정을 성공적으로 마치면 Google Cloud Storage Bucket에 데이터가 들어옵니다.
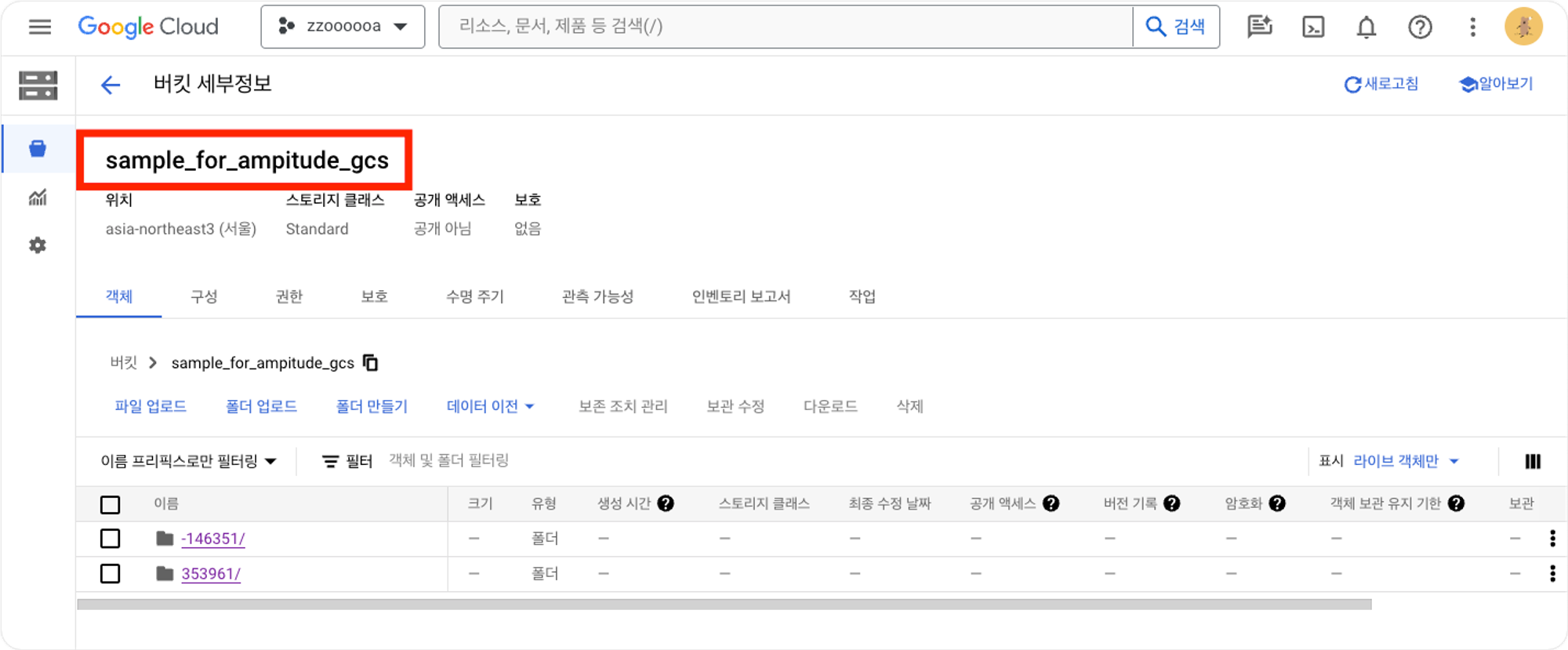
연동이 완료되면 다음과 같이 생성됩니다.
*merged ID 된 데이터 : -000000/, raw 데이터: 000000/ → 우리가 사용하게될 데이터는 000000/(raw 데이터)
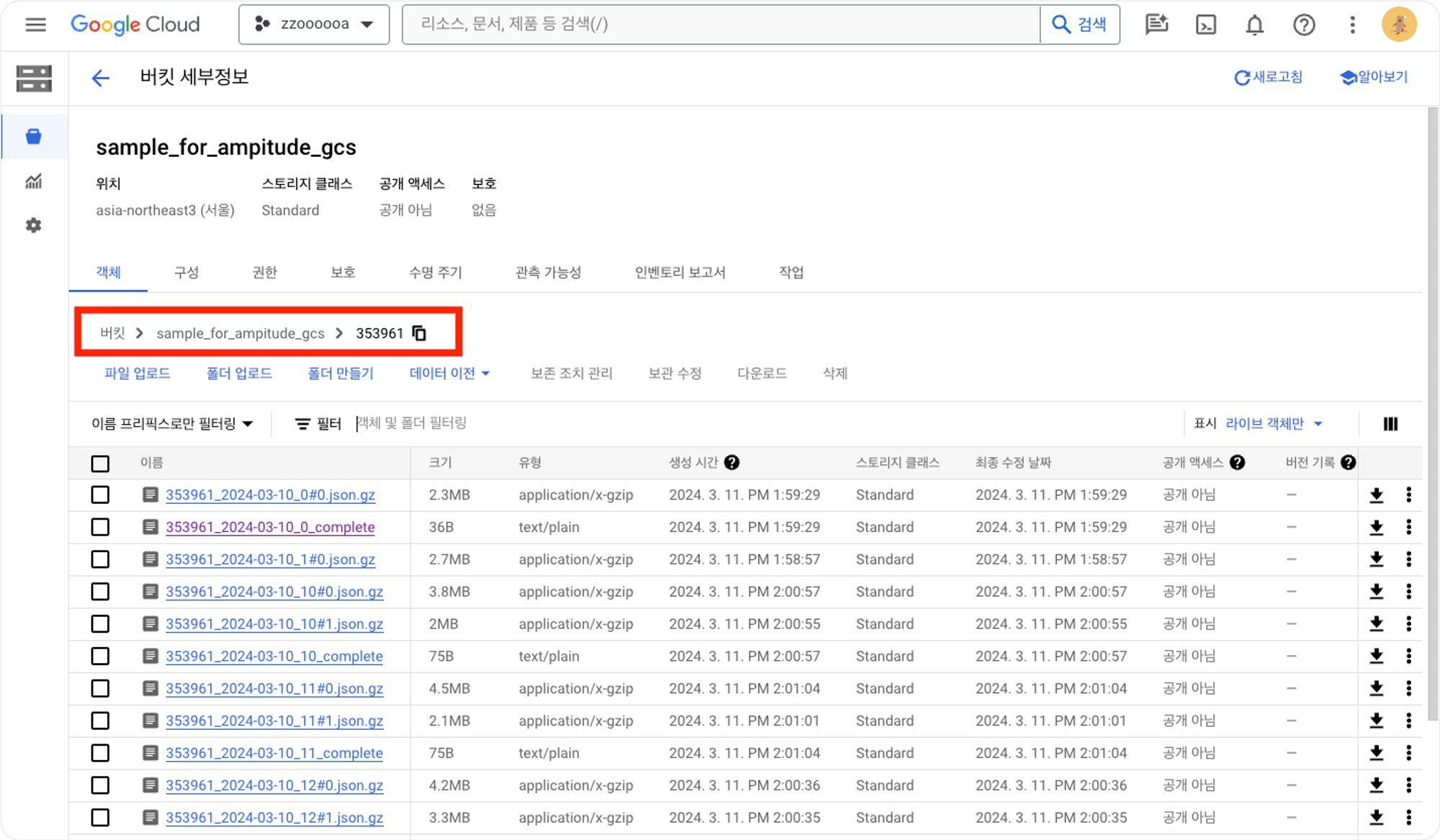
- 압축된 아카이브 JSON 파일로 매 시간 내보내지고 시간 당 하나 이상의 파일로 시간별로 분할
- 파일명: projectID_yyyy-MM-dd_H#partitionInteger.json.gz
앰플리튜드는 export API라는 서비스를 제공하므로 이 API를 호출하여 데이터를 불러올 수 있습니다. 파이썬의 request모듈로 API요청을 보내는 함수를 구현하고, 다음으로 데이터 전처리 모듈은 pandas모듈을 활용하여 JSON 포맷을 테이블형식의 데이터프레임으로 전처리했습니다. 1차 시도당시 빅쿼리로 진행했던 조건문을 프로그래밍 언어로 대체한 것입니다. 마지막으로 빅쿼리 클라이언트 라이브러리를 설치하여 전처리한 테이블을 빅쿼리로 업로드하는 함수를 구현했습니다.
내용을 요약하면 다음과 같습니다.
-
앰플리튜드
- 앰플리튜드가 GCS 버킷에 접근하여 이벤트 데이터를 전송합니다.
-
GCS
- 앰플리튜드 이벤트 데이터는 GCS의 객체로 생성됩니다. 이때 객체 트리는 “버킷>폴더>시간대(yyyy-mm-dd_h)#순번’으로 네이밍되어 적재됩니다. (*e.g: 353961_353961_2023-06-25_1#0)
-
GCF
: 버킷에 객체가 생성될때마다 객체 데이터를 전처리한 후, 빅쿼리에 로드하는 함수 구현
3-1. 트리거
: GCS에 객체가 생성될때마다 호출합니다.
‘(Amplitude → Google Cloud Storage)’와 ‘(Google Cloud Storage) → Bigquery)’를 Google Cloud Functions로 연결하고자 트리거를 “Google Cloud Storage에 앰플리튜드 파일(객체)가 생성될 때”로 정의했습니다.
트리거 진입함수는 main()으로 설정합니다. 이때 트리거 대상 객체의 파일명을 확인하기 위해
datajson 객체를 로드하여 메타 데이터를 확인합니다.3-2. gcs_read()
: 트리거 수신 위치의 버킷 객체를 참조하여 읽어들입니다.
- gcs_read()로 트리거 대상 객체의 파일을 읽어오고 빅쿼리의 index가 되어 줄 부분을 파싱합니다.
index_prefix: projectID_yyyy-MM-dd_H#partitionInteger.json.gz 파일명에서 ‘yyyy-MM-dd_H#partitionInteger’을 가져와 정수형으로 변환한 뒤 값을 할당합니다.json_objects: 버킷에 저장돼 있던 압축된 아카이브 JSON 파일을 압축해제한 뒤, 데이터프레임으로 변환하기 위해 줄바꿈되어 있는 부분을 기준 삼아 데이터를 분리합니다.
3-3. json_make_dataframe()
: json객체를 total_items_order_completed, item_order_completed 각각의 데이터프레임(df1, df2)으로 변환합니다.
3-4. join_dataframes()
: df1, df2를 index 컬럼 기준으로 조인하여 joined_df라는 데이터프레임을 생성합니다.
3-5. append_to_bigquery()
: joined_df 데이터프레임에 맞는 스키마를 정의하여 빅쿼리에 로드합니다.
- gcs_read()로 트리거 대상 객체의 파일을 읽어오고 빅쿼리의 index가 되어 줄 부분을 파싱합니다.
해당 작업을 완료하면, 최종적으로 빅쿼리에 데이터가 정상적으로 저장되며, 태블로에 연결해서 시각화할 수 있습니다.
3. 대시보드 체크포인트
3-1. 가장 중점적으로 고민한 부분
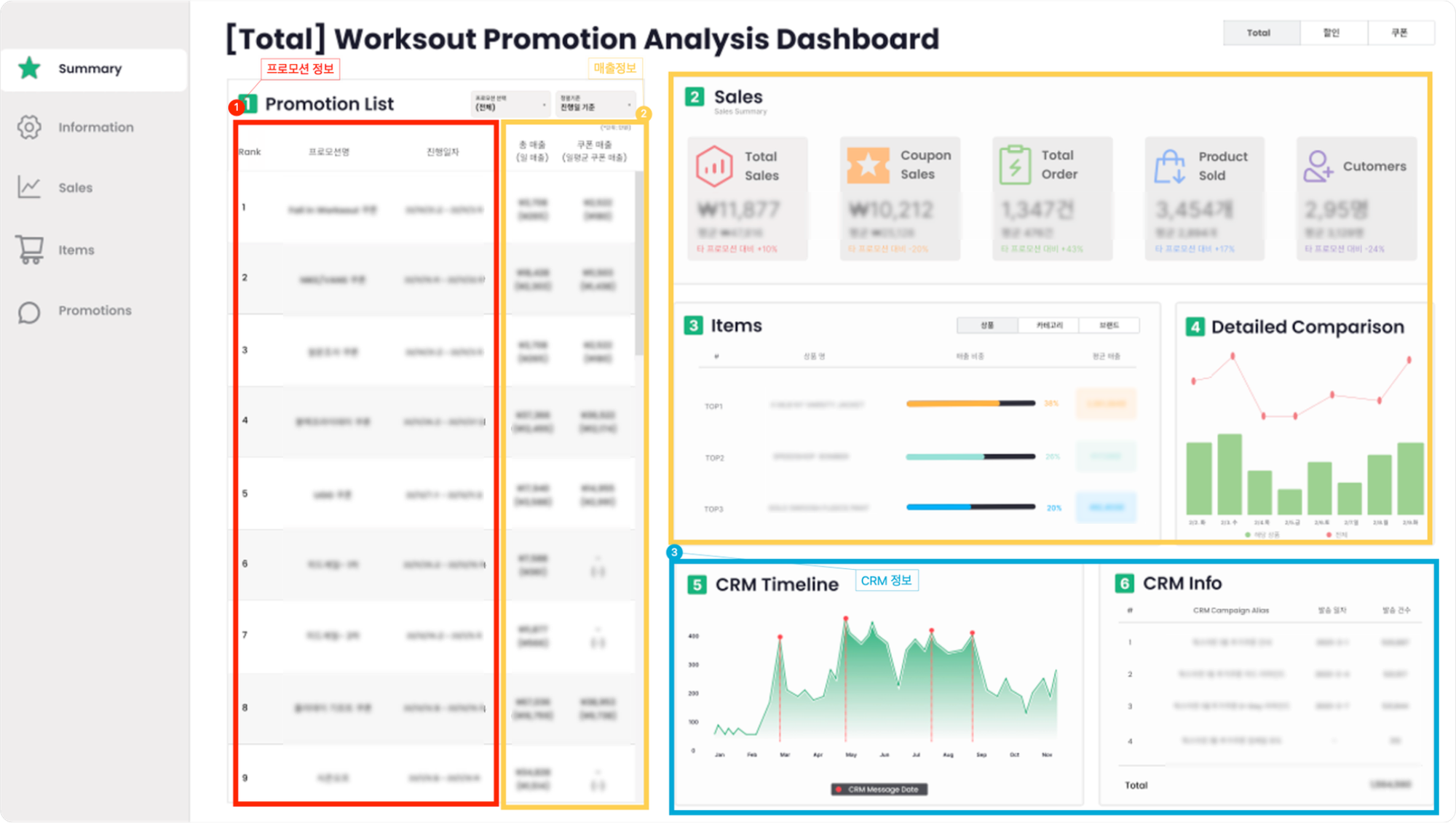
통합 프로모션 대시보드이므로 프로모션간의 비교가 가능하도록 하는 것이 최우선순위 목표였습니다. 하지만 통합 프로모션 대시보드 내에서 개별 프로모션의 성과 및 관련 내용도 바로 파악이 가능하도록 대시보드를 구성하고자 했습니다.
프로모션 리스트 부분에서 프로모션 성과들을 직관적으로 비교해서 확인할 수 있도록 했으며, sales summary내의 각 KPI의 프로모션 평균값을 제공하여 프로모션의 평균값과의 비교가능하게함으로써 프로모션간의 비교분석이 가능하도록 대시보드를 구성했습니다. 또한 프로모션 리스트에서 개별 프로모션 클릭시 해당 프로모션에 해당하는 내용으로 필터링이되어 표현되게함으로써 개별 프로모션의 성과 역시 파악할 수 있도록 대시보드를 구성했습니다.
3-2. 대시보드 구현시 발생했던 문제점 및 이를 해결하기 위한 과정
데이터를 태블로로 넘긴후 ERP 기준 매출 데이터와 정합성을 확인하는 과정에서 매출액의 약 0.2%의 차이가 발생함을 확인했습니다. 이는 최종 매출액에서 반품 및 교환비용을 고려하지 못했기때문에 발생한 결과였습니다.
따라서 앰플리튜드의 반품 및 교환관련 이벤트인 return_completed의 return_paid_shipping(교환 및 환불금액)관련 항목을 추가하여 해당 금액을 반영해줌으로써 데이터 정합성을 맞췄습니다.
3-3. 가장 어려웠던 부분
해당 대시보드를 사용하는 고객사는 프로모션의 분류를 크게 할인과 쿠폰 2가지로 구분하고 있습니다.
즉, 1차적으로 가격을 낮춰 세일가에 제품을 구매하는 ‘할인’ 프로모션과 쿠폰을 소지하고 있는 고객이 쿠폰을 직접 사용해서 제품을 구매하는 ‘쿠폰’ 프로모션이 존재합니다. 이때 쿠폰 프로모션의 경우 총 매출 관련 항목과 쿠폰 매출 관련 항목으로 구분해서 성과를 확인할 수 있지만, 할인 프로모션의 경우 쿠폰 관련값이 존재하지 않으므로 쿠폰 매출 관련 성과는 확인이 불가능합니다. 따라서 성과를 확인함에 있어서 쿠폰 프로모션의 경우에는 쿠폰 매출 관련 항목을 확인해야하고, 할인 프로모션의 경우에는 총 매출 관련 항목을 확인해야합니다.
이를 적용했을 때 Sales Summary를 확인함에 있어서 결제상품수, 결제건수, 구매고객수의 경우 할인 프로모션의 경우에는 총 매출액 관련 항목으로, 쿠폰 프로모션의 경우에는 쿠폰 매출액 관련 항목으로 구분해서 표현해주어야합니다.
이를 위해 케이스를 나누고, 쿠폰아이디가 존재할 경우 쿠폰 프로모션으로 판단해서 쿠폰 매출 관련으로 카운트 하고, 쿠폰아이디가 존재하지않을 경우 할인 프로모션으로 판단해서 총 매출 관련항목으로 카운트할 수 있도록 계산된 필드를 생성합니다.
-- 결제상품수 예시
{FIXED [Promotion name1],[Classification],[Coupon Id]:
SUM(IF [Classification]='쿠폰' and ([# COUPON ID_1]= [Coupon Id]
OR [# COUPON ID_2]= [Coupon Id] OR [# COUPON ID_3]= [Coupon Id])
THEN 1
ELSEIF [Classification]='할인' THEN 1
END)}4. 대시보드 템플릿
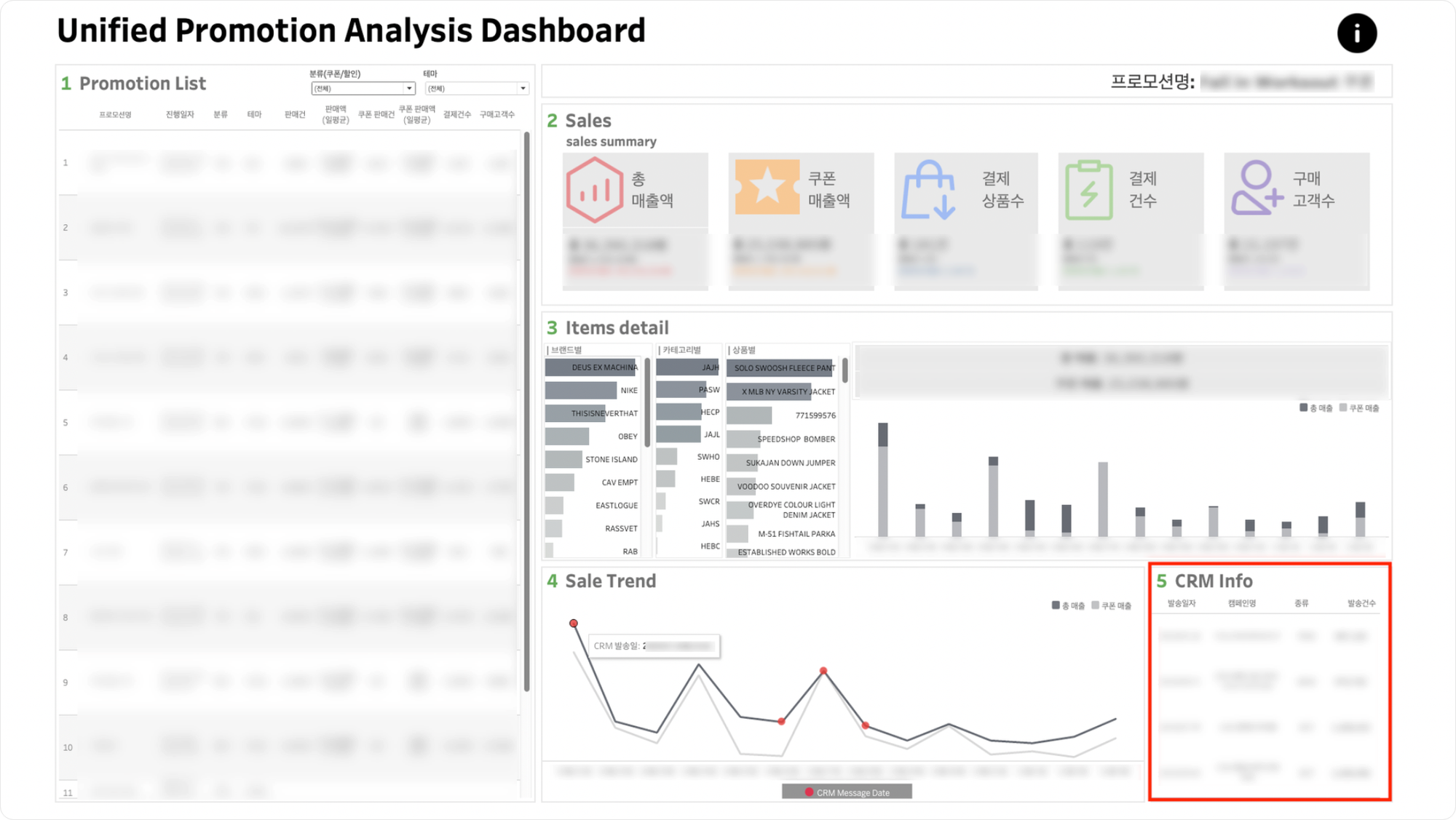
📊 통합프로모션 대시보드 설명
-
분류(쿠폰/할인) 및 테마 필터
-
해당 필터를 클릭하여
1. 프로모션 리스트에서 프로모션을 확인할 수 있습니다. -
필터가 동작함에 따라
2. 세일 요약내의 프로모션 평균이 변동됩니다.
-
-
3. 아이템 디테일내 브랜드별, 카테고리별, 상품별 막대그래프를 클릭하여 상세 판매현황을 확인할 수 있습니다.- 클릭했던 막대그래프를 재클릭하시면 클릭을 해제하실 수 있습니다.
-
5. CRM 정보에 표기되는 CRM 리스트 기준은 다음과 같습니다.1) 전송건수: 10,000건 이상
2) Campaign Category: RAF, NTC(라플 및 공지) 제외
3) App: WO (칼하트윕 제외)
4-2. 해당 템플릿을 사용하는 방법
대시보드 우측 상단의 i표시를 클릭하면, 대시보드에 대한 설명을 확인할 수 있습니다. 프로모션의 분류가 할인일 경우, 1. Promotion List에 쿠폰 판매건 및 쿠폰 판매액은 0건, 0원으로 표시됩니다. 2. Sales의 결제 상품수, 결제 건수, 구매고객수의 경우, 프로모션 분류가 쿠폰일 경우에는 쿠폰 판매에 관련된 내용으로, 프로모션 분류가 할인일 경우에는 총 판매액에 관련된 내용으로 표시됩니다.
대시보드 작동예시를 좀 더 자세히 살펴보면 다음과 같습니다.
-
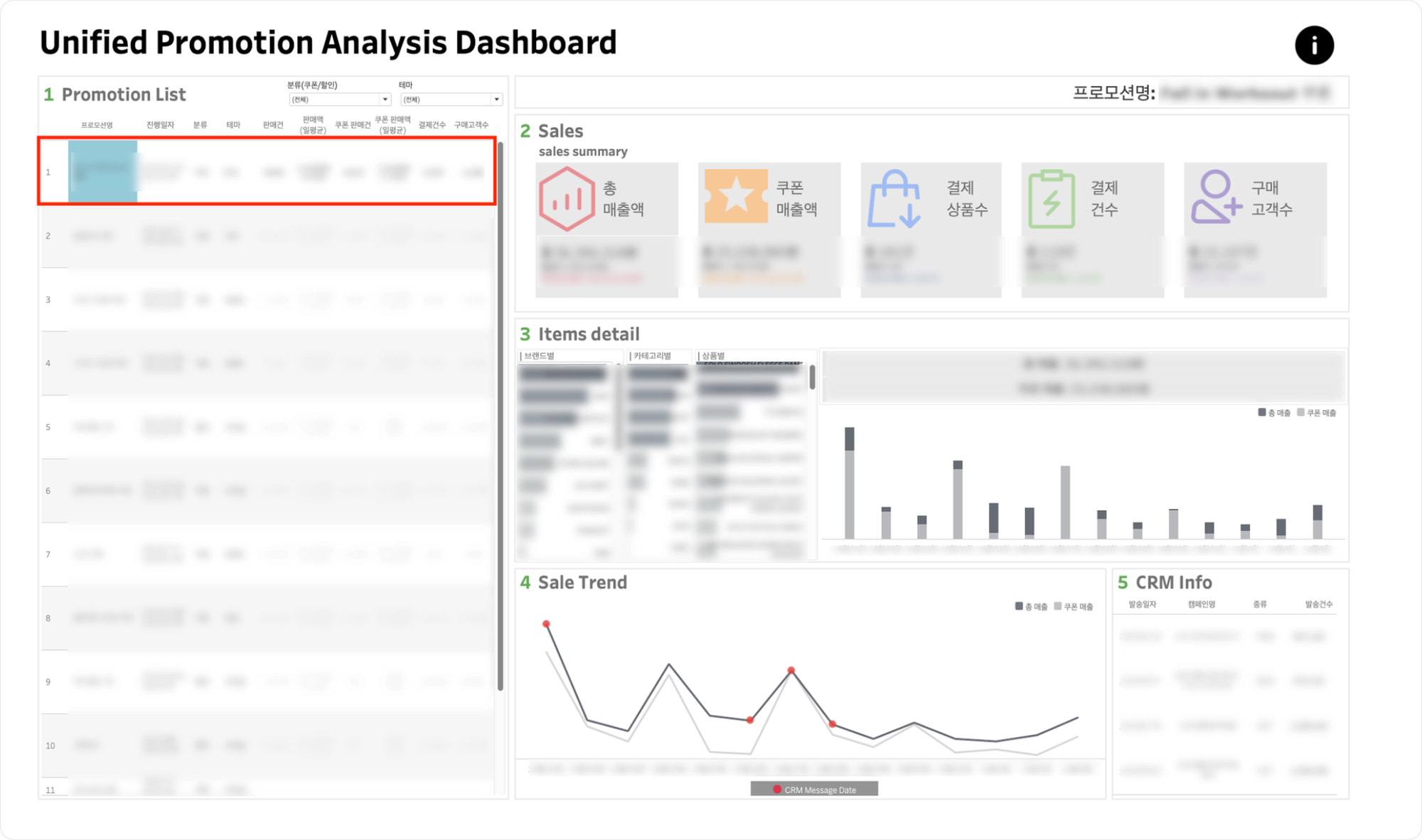
Promotion List
- 프로모션 명을 클릭해서 해당 프로모션에 해당하는
2.sales,3. Item datail,4. Sale Trend,5 CRM Info를 확인할 수 있습니다.
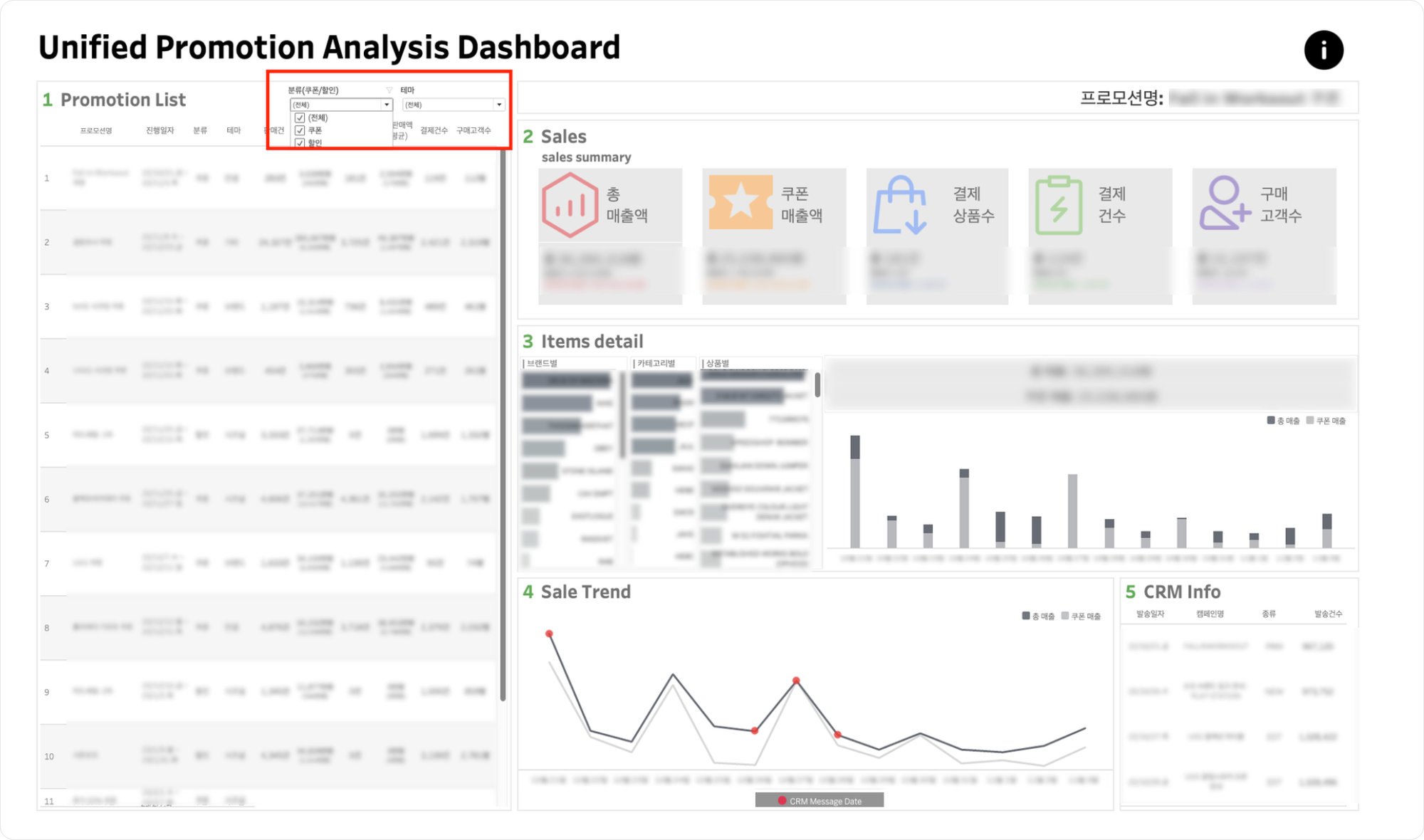
- Promotion List 우측 분류 및 테마 필터를 클릭하여 해당하는 프로모션을 확인할 수 있습니다.
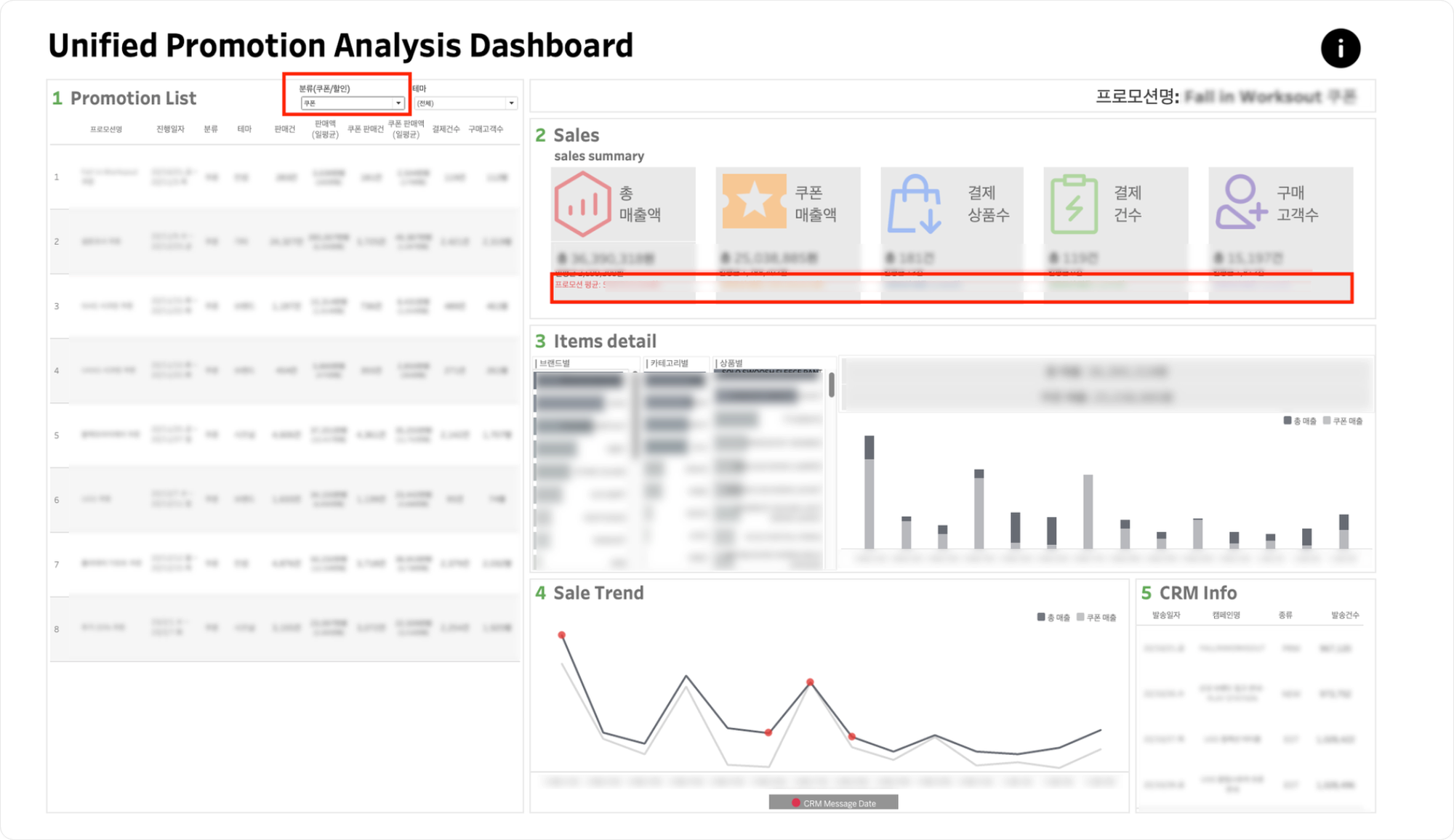
- 프로모션 명을 클릭해서 해당 프로모션에 해당하는
-
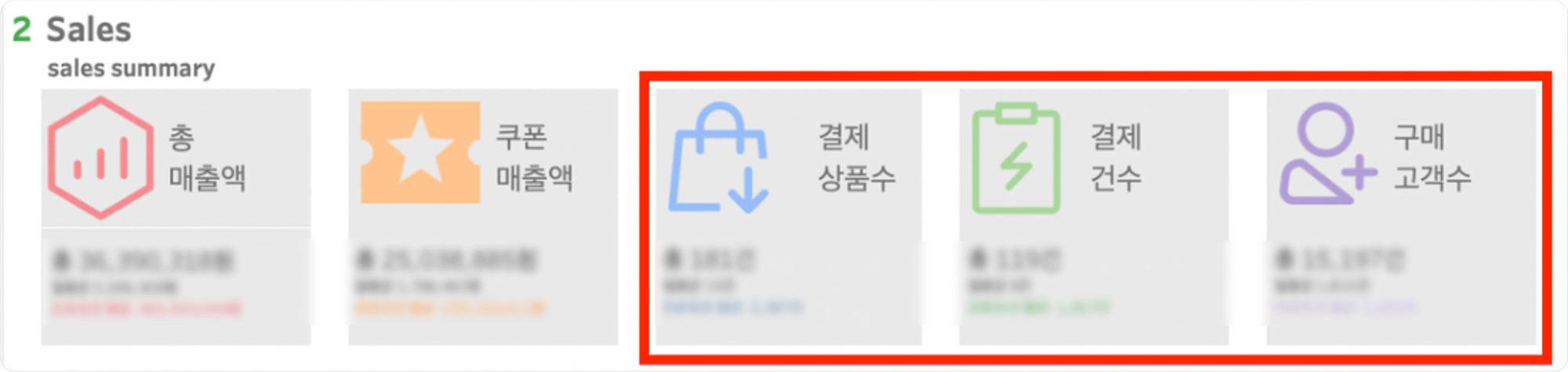
Sales(sales summary)
- 해당 프로모션의 총 매출액, 쿠폰 매출액, 결제 상품수, 결제 건수, 구매고객수 및 각 항목에 해당하는 일평균 액수를 확인할 수 있습니다.
- Promotion List 우측 분류 및 테마 필터 적용 시,
2.salesKPI의 프로모션 평균이 필터에 해당하는 프로모션의 평균으로 변경됩니다.
-
Item datail
- 좌측의 브랜드별, 카테고리별, 상품별 차트를 클릭해 각 항목에 해당하는 상품의 일자별 판매현황을 확인할 수 있습니다.
- 클릭한 항목을 재클릭하면 원본으로 돌아갈 수 있습니다.
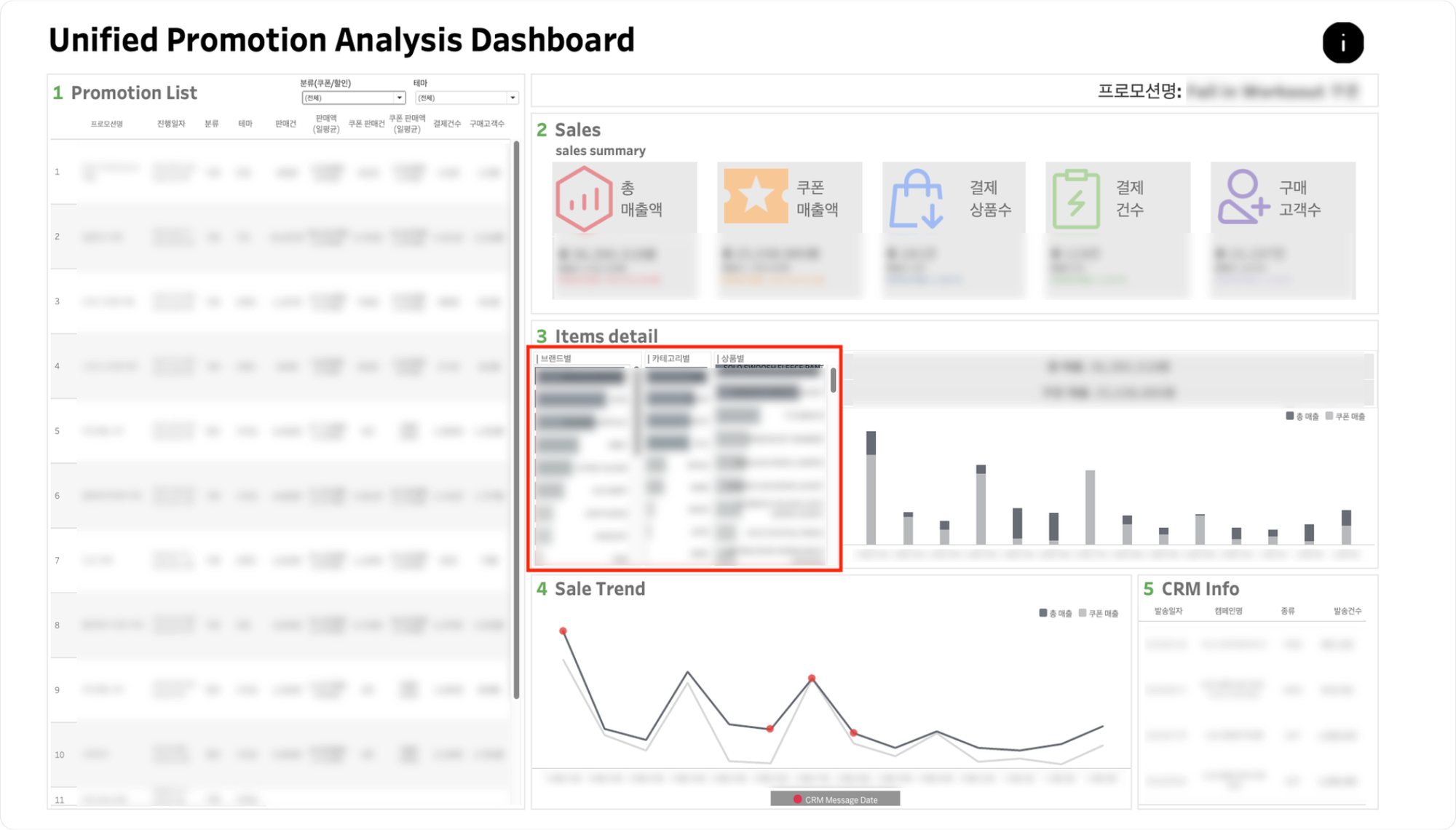
- 클릭한 항목을 재클릭하면 원본으로 돌아갈 수 있습니다.
- 우측 막대그래프에 마우스를 오버하면, 각 일자별 총 매출 및 쿠폰 매출, 총 매출 대비 쿠폰 매출 비율을 확인할 수 있습니다.
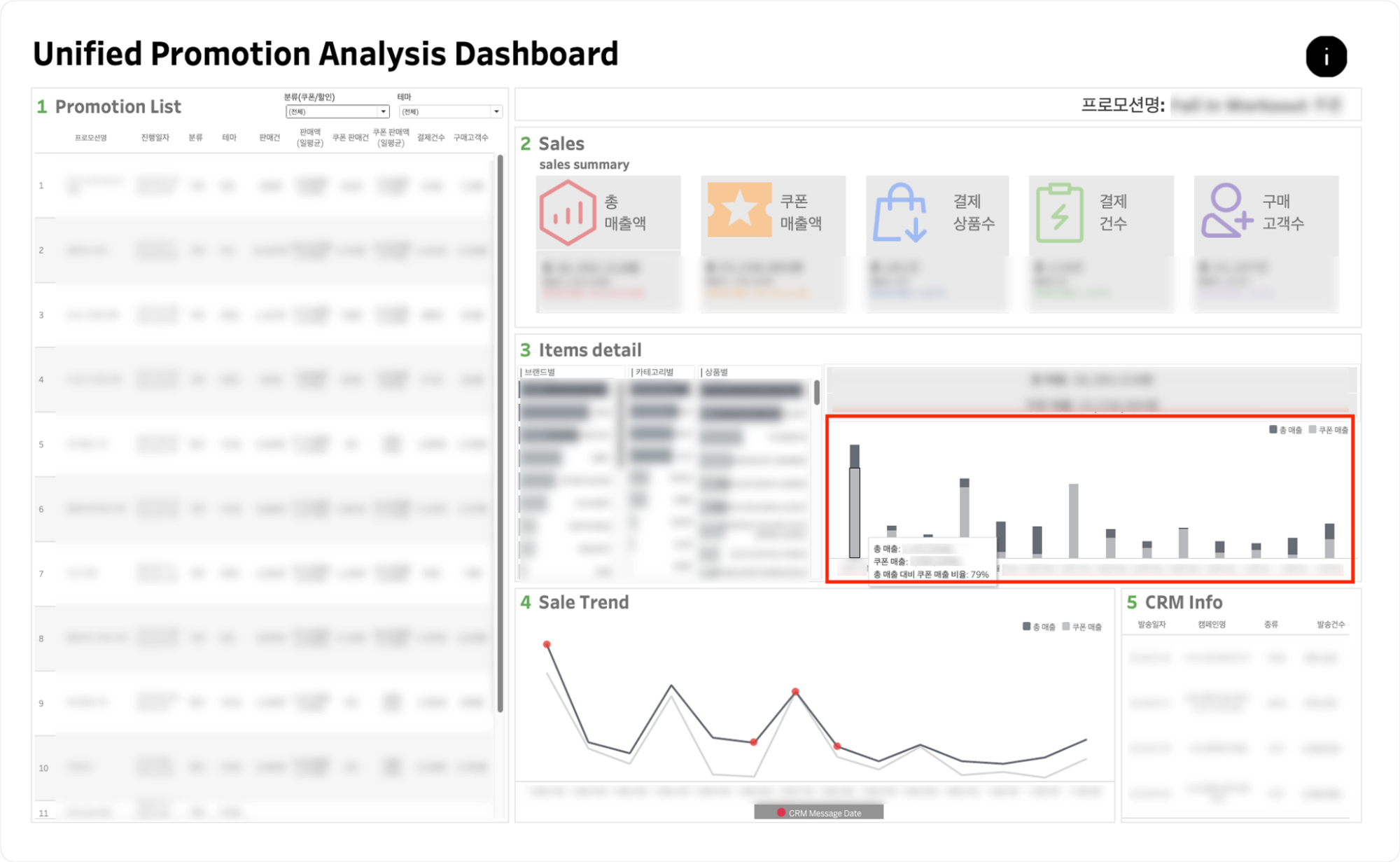
- 좌측의 브랜드별, 카테고리별, 상품별 차트를 클릭해 각 항목에 해당하는 상품의 일자별 판매현황을 확인할 수 있습니다.
-
Sale Trend & 5.CRM Info
- Sale Trend에서 프로모션 기간 동안의 총 매출 및 쿠폰 매출, 해당 기간 동안 CRM이 발송된 날짜에 대한 정보를 확인할 수 있습니다.
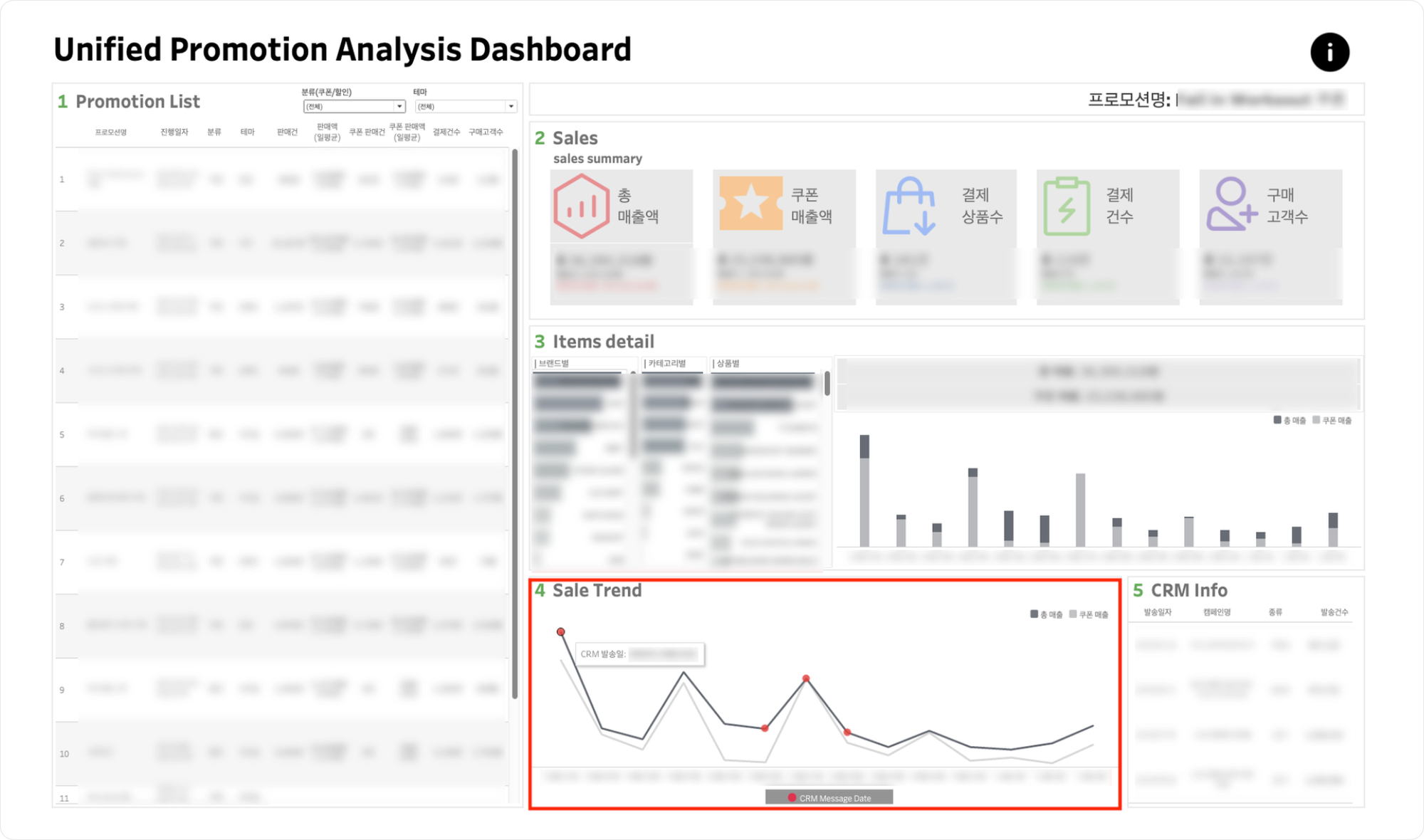
- Sale Trend에서 프로모션 기간 동안의 총 매출 및 쿠폰 매출, 해당 기간 동안 CRM이 발송된 날짜에 대한 정보를 확인할 수 있습니다.
- 5.CRM Info에서 해당 CRM에 대한 세부 정보를 확인할 수 있습니다.