Feature Matching
Template Matching
Template : part of an Image
템플릿 : 영상의 일부
Calculate pixel-wise differences of templates centered on the feature point.
픽셀 단위로 차이를 분석한다. 즉, 어떤 조각이 있고, 같은 크기의 다른 조각이 있으면 이 조각들의 같은 위치에 있는 값들끼리 계산을 하는 것이다.
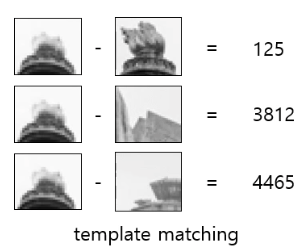
같은 픽셀 값들끼리 빼서, (이상적으로는) 두 개의 템플릿이 완전히 동일한 값이라면 모든 픽셀에서 뺀 값들을 더하면 0 이 나올 것이다.
그 말인즉슨, 내가 두 개의 템플릿의 차이값을 계산할 때에는 값이 작으면 작을 수 록 두 개가 유사하다고 판단할 수 있다는 것이다.
template
2D matrix centered on a point.
The matching process involves computation of the similarity measure for each disparity value, followed by an aggregation within the square window.
값을 뺄 경우 +,- 둘 다 나올 수 있는데 우리는 그 차이의 절댓값만 보고 싶으므로, 전체 값이 절댓값을 취해 준다.
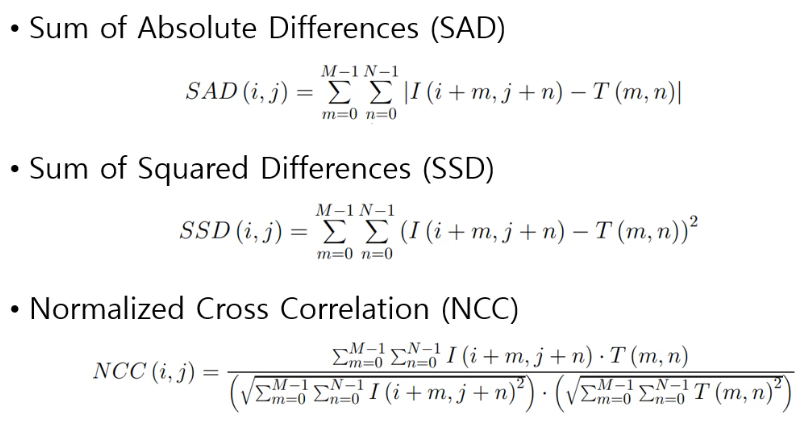
1,2 는 차이를 보는 것이고 3번째 방법은 Correlation 을 보는 것이다.
Difference 와 Correlation 의 차이
Difference 는 모든 요소끼리 같을 경우 0이 되지만
Correlation 은 요소끼리 곱해서 sum 을 빼 주는 것이므로,
모든 요소가 일치할 경우 값이 1이 된다.
만약 순서가 반대라면 -1 이 되고, 아무런 상관이 없으면 0 의 값을 가진다.
따라서 Correlation 은 두 set 가 얼마나 유사하냐? 의 지표가 된다.
L1 norm 과 L2 norm 의 차이
1 번 방법은 제곱하지 않고 절댓값만 취하므로 L1 norm, 2 번 방법은 제곱을 하므로 L2 norm 이라고 할 수 있다.
2번 방법은 튀는 값을 제곱해주므로, 이 둘의 차이는 오류를 얼마나 민감하게 잡아낼 것이냐 하는 것이다.
절댓값을 씌우는 cost function 은 Outlier 라고 이야기를 한다. 하나 정도 툭 튀어나와 있는 요소들에 대해 관대하다.
하지만 제곱을 하는 2번 방법은 이런 요소들에 대해 민감하다.
Disadvantage of template matching
Even if the points were extracted from the same position of the same object, the matching score is degraded if there are any of the following relationships.
- Rotation
- Scaling
- Intensity Change (NCC is invariant)
- Affine Transform

같은 template 이라도, 다음과 같은 변형들이 이루어지면 픽셀 값 차이가 매우 커지게 된다.
따라서, 변환된 영상에서는 템플릿 매칭의 성능이 확연히 떨어진다.
그래서 템플릿 매칭이 직관적이고 간단하지만 이런 단점을 극복하기 위해서 다음 방법이 나왔다.
Distance of descriptors
Calculate the similarity between descriptors describing feature points.
직접적으로 픽셀 값 자체를 비교하는 것이 아니라, 어떤 특징으로부터 추출해 낸 어떤 정보들을 비교하여 구분하는 방식이다.
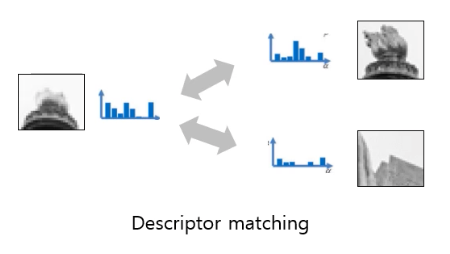
특징들을 뽑아내는 과정 (describe) 을 거쳐서 픽셀들을 다른 domain 으로 변환 시킨다.
템플릿 매칭은 구현하기 쉽고 직관적인 반면, descriptor 을 매칭하는 것은 어떻게 descriptor 를 만드느냐에 따라 성능이 천차 만별이다.
- Description of a feature
- Usually expressed as a vector
We can also regard a tamplate as a kind of descriptors. A template (2D matrix) can be modified to a vector.
We need a better way to describe features which is robust image transform, i.e, rotation, scaling.
