
1.조건으로 검색하기
2.함수로 데이터 처리하기
3.그룹으로 묶기
4.MultiIndex & pivot_table
1. 조건으로 검색하기
numpyarray와 마찬가지로 masking 연산이 가능
조건에 맞는 DataFrame row를 추출 가능하다

import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df[(df["A"] < 0.5) & (df["B"] > 0.3)] #인덱스 방식
df.query("A < 0.5 and B > 0.3") #query 방식문자열이라면 다른 방식으로도 조건 검색이 가능하다

pet["animal"].str.contains("cat") #contains
pet.animal.str.match("cat") #match2. 함수로 데이터 처리하기
apply를 통해서 함수로 데이터를 다룰 수 있다
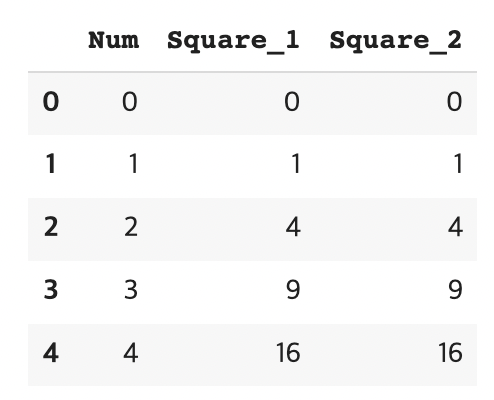
df= pd.DataFrame(np.arange(5), columns=["Num"])
def square(x):
return x**2
df['Square_1'] = df["Num"].apply(square)
df["Square_2"] = df.Num.apply(lambda x: x ** 2) #람다식replace: apply 기능에서 데이터 값만 대체하고 싶을때 사용

df['age'] = df.age.replace({"child": 0, "adult": 1}) #변수에 값 대입
df.age.replace({"child": 0, "adult": 1}, inplace=True) #값 바로 변경
3. 그룹으로 묶기

df / df.groupby('key').sum() / df.groupby(['key','data1']).sum()
df= pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1,2,3,1,2,3],
'data2':np.random.randint(0, 6, 6)})
df.groupby('key')
#<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f5d92085d10>
df.groupby('key').sum()
df.groupby(['key','data1']).sum()- aggregate
groupby를 통해서 집계를 한번에 계산하는 방법
df.groupby('key').aggregate(['min', np.median, max])
df.groupby('key').aggregate({'data1': 'min', 'data2': np.sum})- filter
groupby를 통해서 그룹 속성을 기준으로 데이터 필터링
def filter_by_mean(x):
return x['data2'].mean() > 3
df.groupby('key').mean()
df.groupby('key').filter(filter_by_mean)- apply
groupby를 통해서 묶인 데이터에 함수 적용
df.groupby('key').apply(lambda x: x.max() - x.min())4. MultiIndex & pivot_table
- MultiIndex
인덱스를 계층적으로 만들 수 있다.
df= pd.DataFrame(np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2'])열 인덱스 또한 계층적으로 만들 수 있다.
df= pd.DataFrame(np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]])- pivot_table
데이터에서 필요한 자료만 뽑아서 새롭게 요약, 분석할 수 있는 기능
df.pivot_table(index='sex',
columns='class',
values='survived', aggfunc=np.mean)
= 이 진