
• Pandas
파이썬 라이브러리
구조화된 데이터를 효과적으로 처리하고 저장
Array 계산에 특화된 NumPy를 기반으로 설계
• Series
- numpy array가 보강된 형태
Data와 Index를 가지고 있음

import pandas as pd
data = pd.Series([1, 2, 3, 4])- 인덱스를 가지고 있고 인덱스로 접근 가능

data = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
data['b'] #2- name 인자로 이름을 지정할 수 있음

data = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'], name="Title")
data['c'] = 5- Dictionary로 Series 변환

population_dict= {'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676}
population = pd.Series(population_dict)• DataFrame
여러 개의 Series가 모여서 행과 열을 이룬 데이터
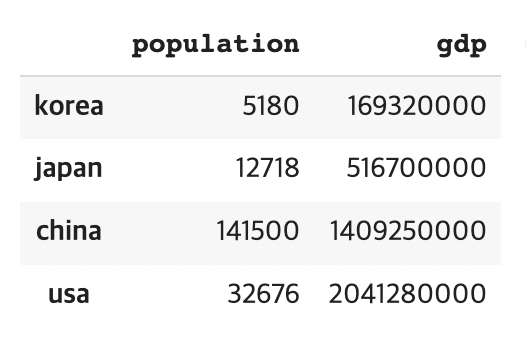
population_dict= {'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676}
gdp_dict= {'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,}
population = pd.Series(population_dict)
gdp= pd.Series(gdp_dict)
country = pd.DataFrame({'population': population,'gdp': gdp})- Dictionary로 변환할 수 있다.

country['gdp’] # ↑↑
country.index
#Index(['china', 'japan', 'korea', 'usa'], dtype='object’)
country.columns
#Index(['gdp', 'population'], dtype='object’)- Series도 numpy array처럼 연산자를 활용
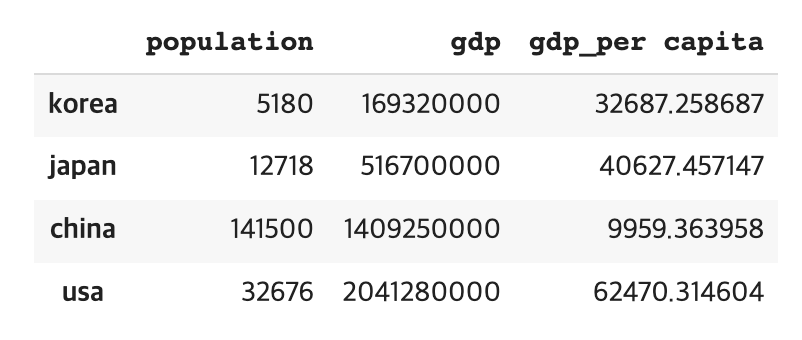
gdp_per_capita= country['gdp'] / country['population']
country['gdp_per capita'] = gdp_per_capita- 저장과 불러오기
country.to_csv(“./country.csv”) #csv 파일로 저장
country.to_excel(“country.xlsx”) #엑셀 파일로 저장
country = pd.read_csv(“./country.csv”) #csv 파일 불러오기
country = pd.read_excel(“country.xlsx”) #엑셀 파일 불러오기- 데이터 추가
리스트로 추가, 딕셔너리로 추가
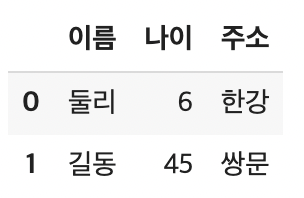
dataframe= pd.DataFrame(columns=['이름','나이','주소'])
dataframe.loc[0] = ['둘리', '6', '한강'] #리스트 방식
dataframe.loc[1] = {'이름':'길동', '나이':'45', '주소':'쌍문'} #딕셔너리 방식- 데이터 수정
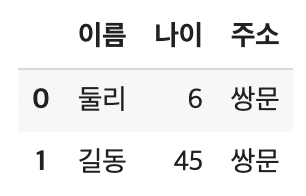
dataframe.loc[0, '주소'] = '쌍문'- 새로운 column 추가

dataframe['전화번호'] = np.nan
dataframe.loc[1, '전화번호'] = '011-7777-7777'- 컬럼 선택하기
컬럼 이름이 하나만 있다면 Series
컬럼 이름이 리스트로 여러개 있다면 DataFrame

dataframe['이름']
dataframe[['이름','나이']] #대괄호 2개!• Pandas 연산과 함수
- 누락된 데이터 확인
현실의 데이터는 누락되어 있는 경우가 많다.
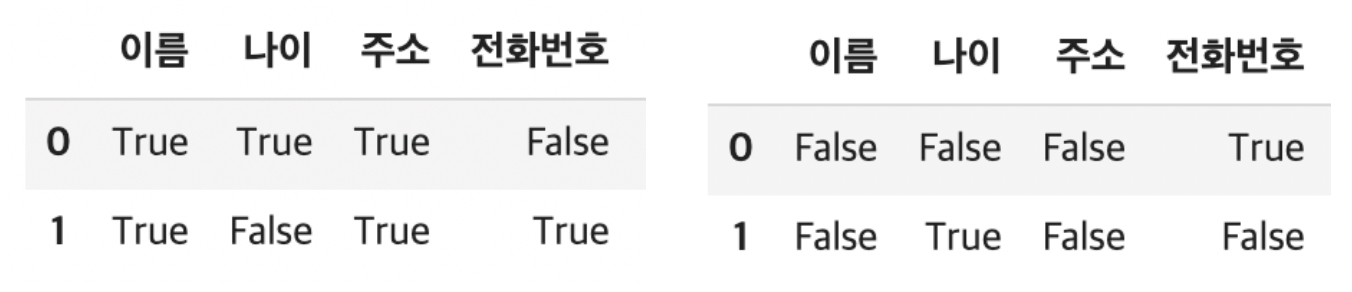
dataframe.notnull() #값이 null일 경우 False
dataframe.isnull() #값이 null일 경우 True- 누락된 데이터 제거 / 변경

기존 dataframe / dropna() 결과 / fillna() 결과
dataframe.dropna()
dataframe['전화번호'] = dataframe['전화번호'].fillna('전화번호없음')- 사칙 연산

A / B / A+B / A.add(B, fill_value)
A = pd.DataFrame(np.random.randint(0, 10, (2, 2)), columns=list("AB"))
B = pd.DataFrame(np.random.randint(0, 10, (3, 3)), columns=list("ABC"))
A + B
A.add(B, fill_value=0)- 집계함수

df / df.sum() / df.mean()
df = pd.DataFrame(np.random.randint(0, 10, (3, 3)), columns=list("ABC"))
df.sum()
df.mean()
df['A'].sum()- DataFrame 정렬
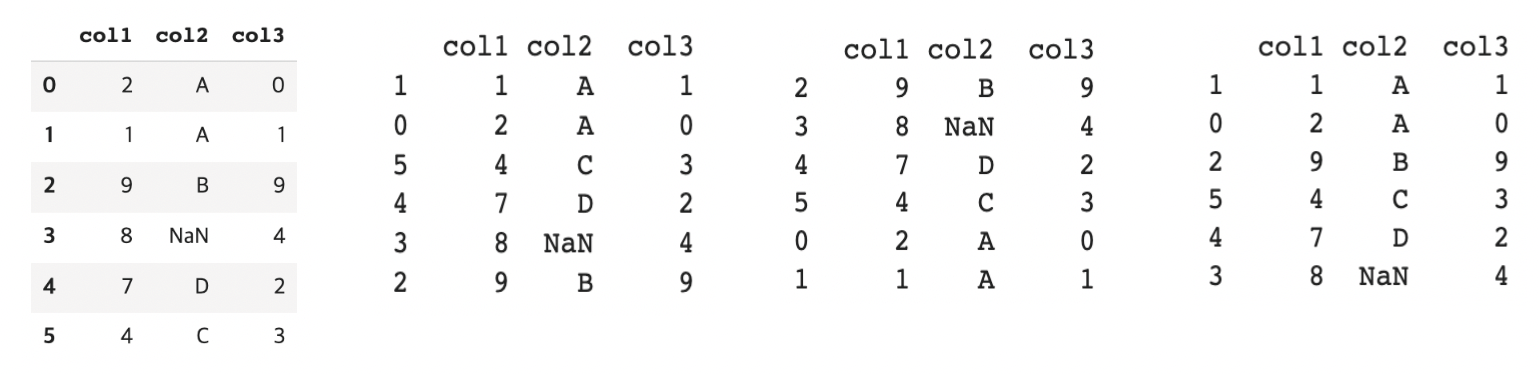
df= pd.DataFrame({'col1': [2, 1, 9, 8, 7, 4],
'col2': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3': [0, 1, 9, 4, 2, 3],})
df.sort_values('col1') #오름차순
df.sort_values('col1', ascending=False) #내림차순
df.sort_values(['col2', 'col1'])
= 이 진