R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation) 정리
논문리뷰
요약 정리
- 데이터와 레이블을 투입
- 영역 제안 region proposal
- selective search 방법 사용
- 특정 기준에 따라 탐색, 상향식의 탐색방법 중 하나인 계층적 그룹 알고리즘이 사용됨
- 작은 크기의 초기 영역을 설정
a. 그래프 이론
b. 이미지를 그래프로 표현
c. pairwise region comparision predicate- 작은 영역을 큰 영역으로 병합
a. 계층적 병합 알고리즘:Hierachical Grouping algorithm- ROI 설정
- 제안된 영역을 CNNs에 넣음
- 서로 다른 크기의 ROI를 CNNs의 정해진 크기로 맞추어서 각각을 입력값으로 입력→ WRAPPING(입력값 크기 고정)
- 분류 및 Bounding Box 조정
- SVM을 통한 분류(지도학습)
- Bounding-Box Regression
- region proposal된 box를 조정
- ti와 di의 값을 줄여나가는 방식으로 진행
Abstract
Object detection 성능은 수년간 정체됨
저자는 VOC 2012(object detection dataset)에서 성능을 30% 정도 향상시킨 detection 알고리즘을 제안
이 알고리즘의 핵심은 두가지
(1) bottom up(상향식) 방식의 region proposal를 통해 object 위치를 알아내고(localize, segment) CNN을 적용.
(2) 훈련데이터셋이 부족할 때, supervised pre-training과 domain-specific fine tuning 수행하여 성능 향상.
⇒ R-CNN: Regions with CNN features
+) sliding-window detector 사용한 OverFeat보다 성능 good
1. Introduction
- PASCAL VOC object detection은 느리게 발전 (SIFT, HOG 사용시기)
- recognition은 hierarchical, multi-statge process for computing features
- Fukushima’s “neocognitron”, back propagation 효과적
- but SVM으로 CNN 인기 떨어졌으나, but imageNet에서 ReLU와 “dropout” regularization으로 인기
- To what extent do the CNN classification results on ImageNet generalize to object detection results on the PASCAL VOC Challenge?
- 이 논문이 object detection performance를 향상시킨 최초임
- 이러한 결과를 내기 위해, 두가지 문제 해결에 집중함
- Deep Network를 활용한 localizaing objects
- 적은 양의 annotated detection data로 high-capacity model 훈련
- 이러한 결과를 내기 위해, 두가지 문제 해결에 집중함
- 1번 문제를 해결하기 위해 3가지 approach
- localization as a regression problem
- 실용가능성이 적다 [38] → x
- sliding-window detector
- cnn에서 20년동안 사용한 방식인데,large receptive filed를 가질 수 밖에 없음 → x
- “recognition using regions” → o

- localization as a regression problem
1. 2000 categroy- region proposal 생성 2. 크기 맞추기 위해 warped region사용 3. linear SVM 사용
- 2번 문제 해결 labeld data is scarce and the amount currently available is insufficient for training a large CNN
- conventional solution to this problem is to use unsupervised pre-training, followed by supervised fine-tuning
- 우리는 → supervised pre-training on a large auxiliary dataset (ILSVRC), followed by domain specific fine-tuning on a small dataset(PASCAL), is an effective paradigm
- In our experiments, fine-tuning for detection improves mAP performance by 8 percentage points
- the only class-specific computations are a reasonably small matrix-vector product (연산량 적다) and greedy non-maximum suppression.
- ROI,IOU 사용
non-maximum suppression이란?
- ROI,IOU 사용
- semantic segmentation에서도 사용할 수 있음
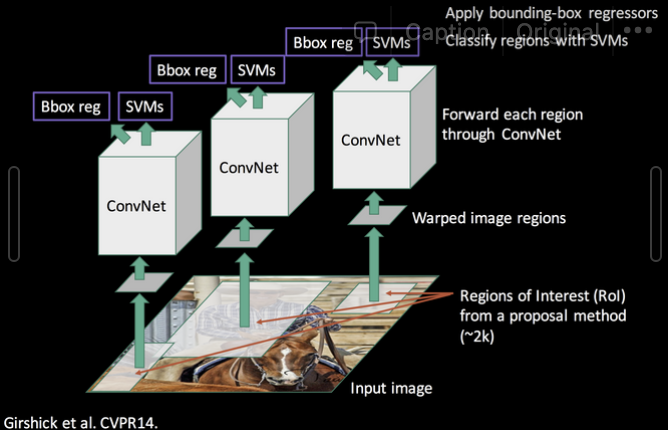
2. Object detection with R-CNN
3가지 모듈이 있다.
2.1. Module design
- generates around 2000 category-independent region proposals (region proposal)
- we use selective search to enable a controlled comparison with prior detection work

- we use selective search to enable a controlled comparison with prior detection work
- extracts a fixed-length feature vector from each proposal using a CNN (feature extraction)
- Caffe 사용해서 각각의 region proposal로부터 4096 dimensional feature vector 추출
- warp 시켜야함
- image warping: 각기 다른 regional proposal을 일괄적인 크기로 바꾸어 주는 것
- 224x224
- 이렇게 바꾸어 주어야 같은 CNN을 통과할 수 있음
- warp 전에 규격에 맞게 저장
- Appendix A
- classifies each region with category-specific linear SVMs
2.2. Test-time detection
selective search의 “fast mode” 사용
💡 ”fast mode”?
greedy non-maximum suppression을 사용함

Run time analysis
- 모든 CNN 파라미터는 전체 카테고리 내에서 공유된다
- feature vector들은 CNN에 의해 저차원에서 계산된다
class-specific computation은 feature들과 SVM weights와 non-maximum suppression의 dot products이다→ 이것만 계산하면 된다(계산량 적다)
2.3. Training(data scarce 문제 해결)
warped 이미지를 CNN에 통과시키자
Supervised pre-training
사전학습 수행
Domain-specific fine-tuning(domain specific data에 fine-tuning을 수행!)
- 미리 학습한 데이터셋(ILSVRC2012)의 경우 최종 분류 클래스가 1000개이기에, 객체 탐지에 사용할 데이터셋인 클래스 개수에 맞게 바꾸어 주어야함⇒ 21개의 분류(20개의 클래스 + background)
- regional proposal - ground truth box와 IoU threshold 0.5 이상일시 groudn truth box 이하일 경우 background로 라벨링
- 매 SGD 반복마다, 균일하게 32 positive window와 96개의 negative(background window)들은 같이 훈련 → 총 배치사이즈는 128( 객체가 포함된 영역이 작기 때문에), SGD learning rate는 0.001(pre-trained network가 0.01로 학습, 통상적으로 1/10로 적용)
Object category classifiers(모델을 이용하자)
class specific한 svm 만들자, 클래스 개수만큼 svm이 만들어 질 것이다.⇒ SVM 들
부분적으로 겹쳐있으면 어떻게 label?
positive: ground truth box
negative: <0.3 IoU
threshold → 0.3이 좋다 (실험적으로 검증) //0.5라고 무조건 좋은 것이 아님
2.4. Results on PASCAL VOC 2010-12

BB: Bounding box regression 사용하니까 더 good
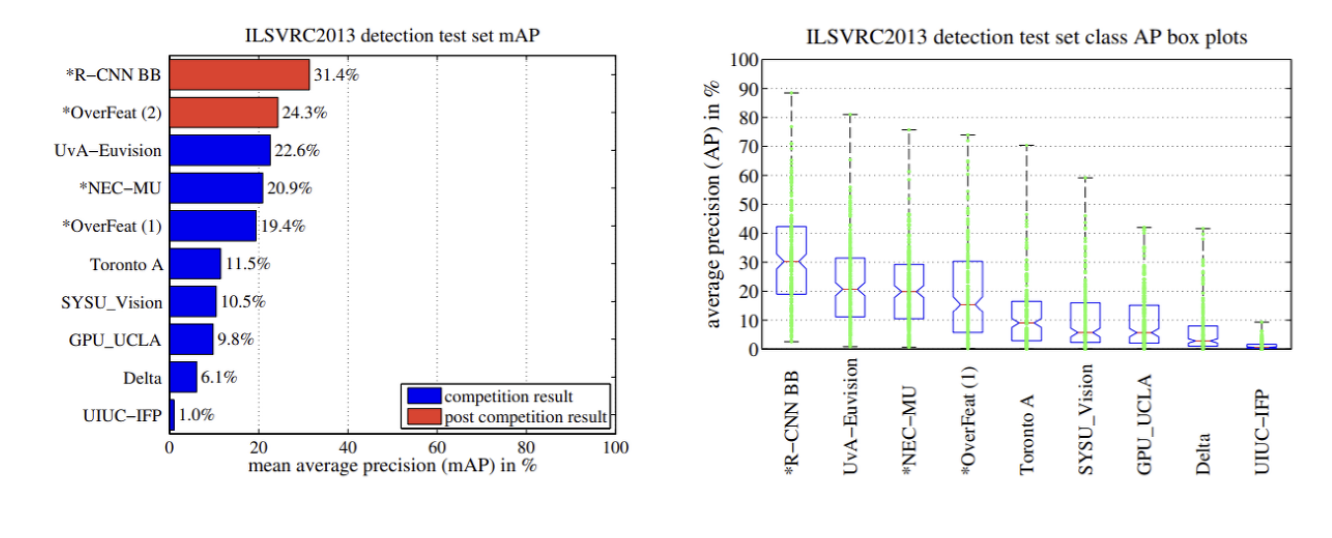
2.5. Results on ILSVRC2013 detection
3. Visualization, ablation, and modes of error
3.1 Visualizing learned features

shape,texture, color, and material property들을 합쳐서 학습함
3.2 Ablation studies
feature들 변경해가면서 성능 확인
without fine-tuning 시행,
fc 6, fc 7 없을 때 성능 크게 변화 x
⇒ 즉 CNN의 성능은 convolutional layer에서 오니 fc는 중요 x
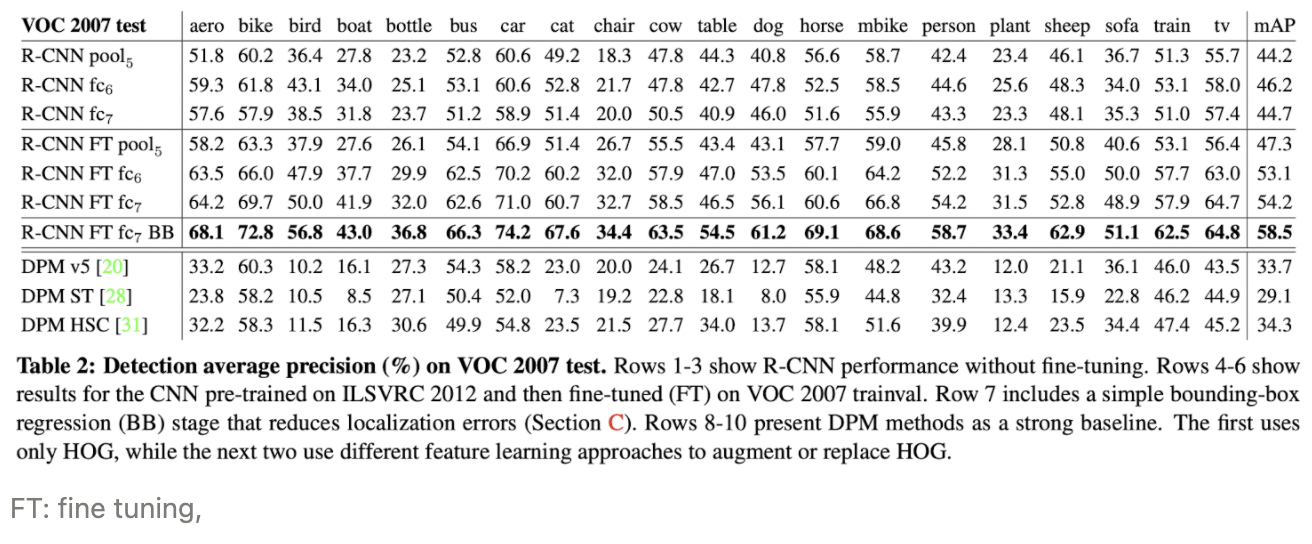
DPM v5: standard HOG-based DPM
DPM ST: The first DPM feature learning method
DPM HSC: repaces HOG with histograms of sparse codes
⇒ RCNN의 fine-tuning이 제일 성능이 좋다
3.3 Network architectures
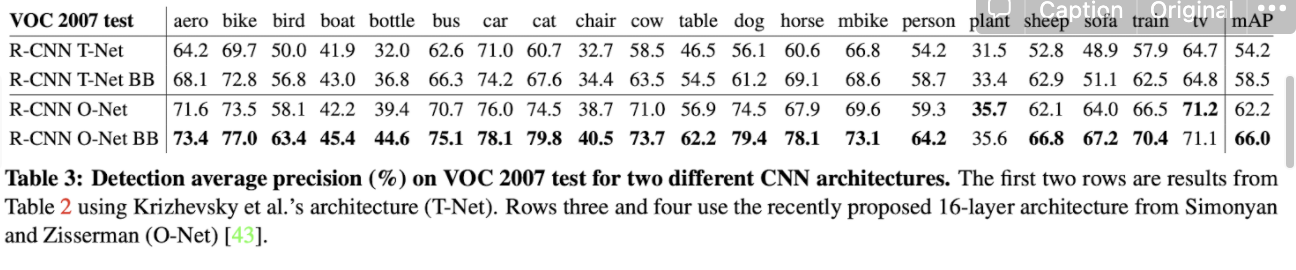
RCNN with O-Net이 R-CNN with T-Net보다 성능이 좋고, with BB가 성능 더 좋음
but RCNN with O-Net은 computing time → 7 times
3.4 Detection error analysis
excellent detection analysis tool , fine tuning changes 통해서
3.5 Bounding box regression
localization error 줄임
Appendix C. Bounding-box regression → 박스의 위치를 재조정, mAP 기준으로 정확도 향상

P: regional proposal을 통한 bounding box, G: ground-truth bounding box
w*를 찾는 것이 목표
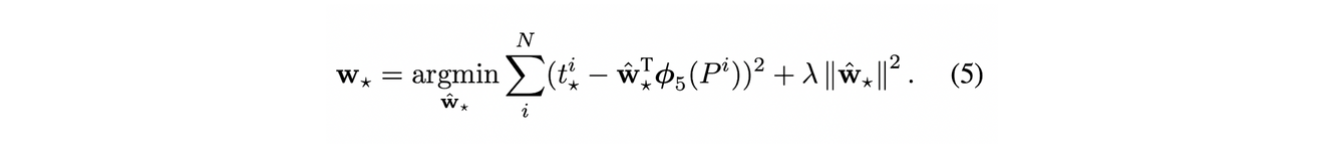
여기서 *는 x,y,w,h 중 하나
여기서 t*는 다음과 같이 ground truth 박스와의 위치, 크기 차이를 나타냄
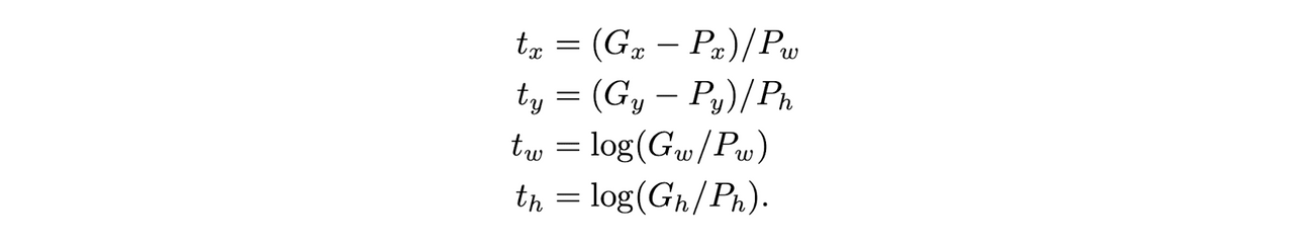
학습된 w를 이용해 d(Pi)를 계산하고 regional proposal의 위치와 크기를 재조정, 즉 d를 줄이는 방식으로 계산(d(Pi)=wT파이(Pi))
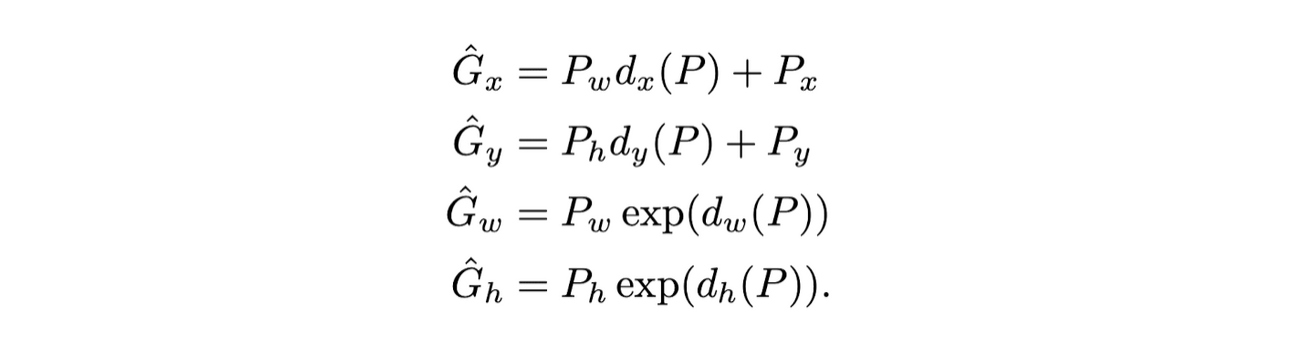
3.6 Qualitative results

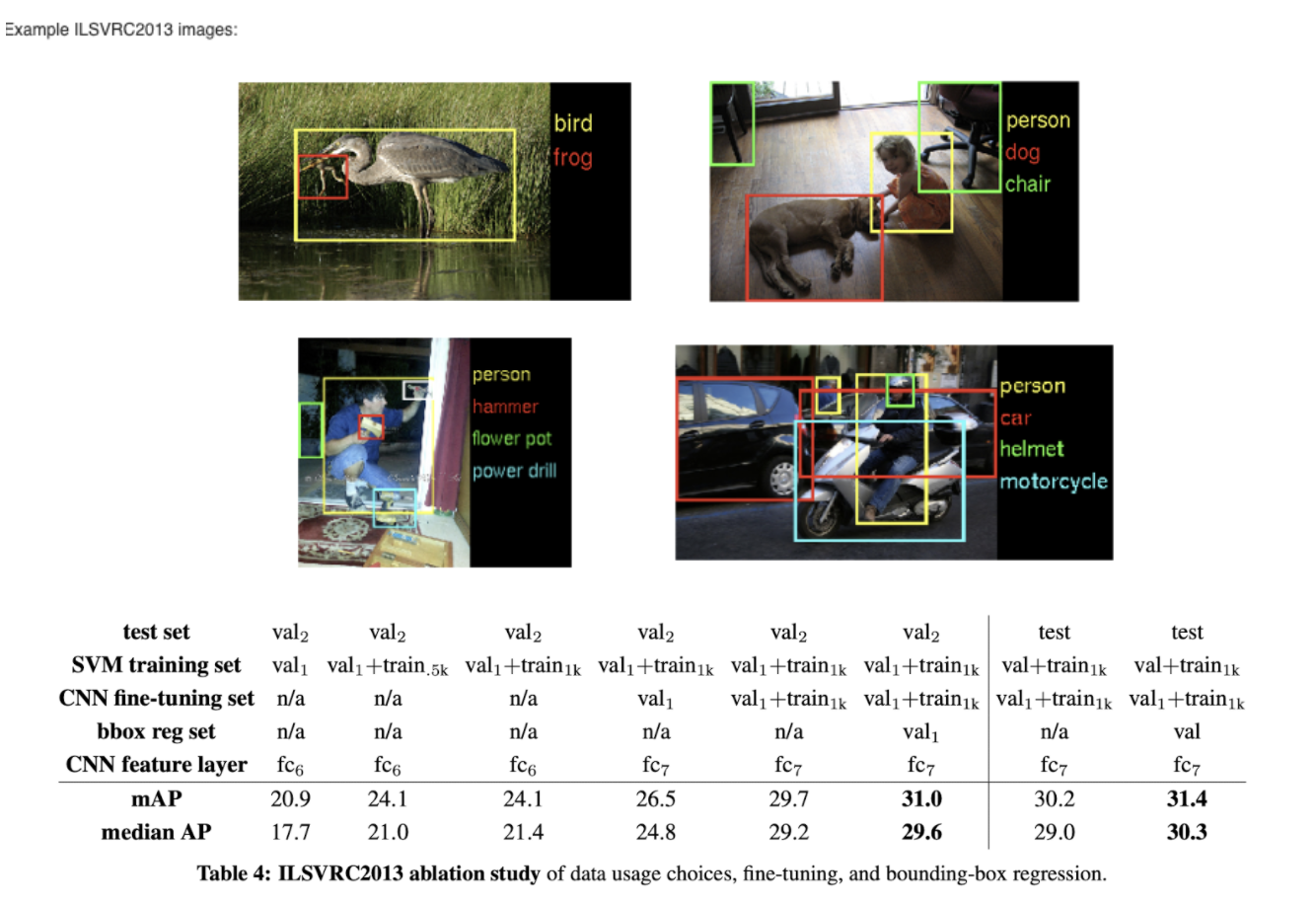
4. The ILSVRC2013 detection dataset
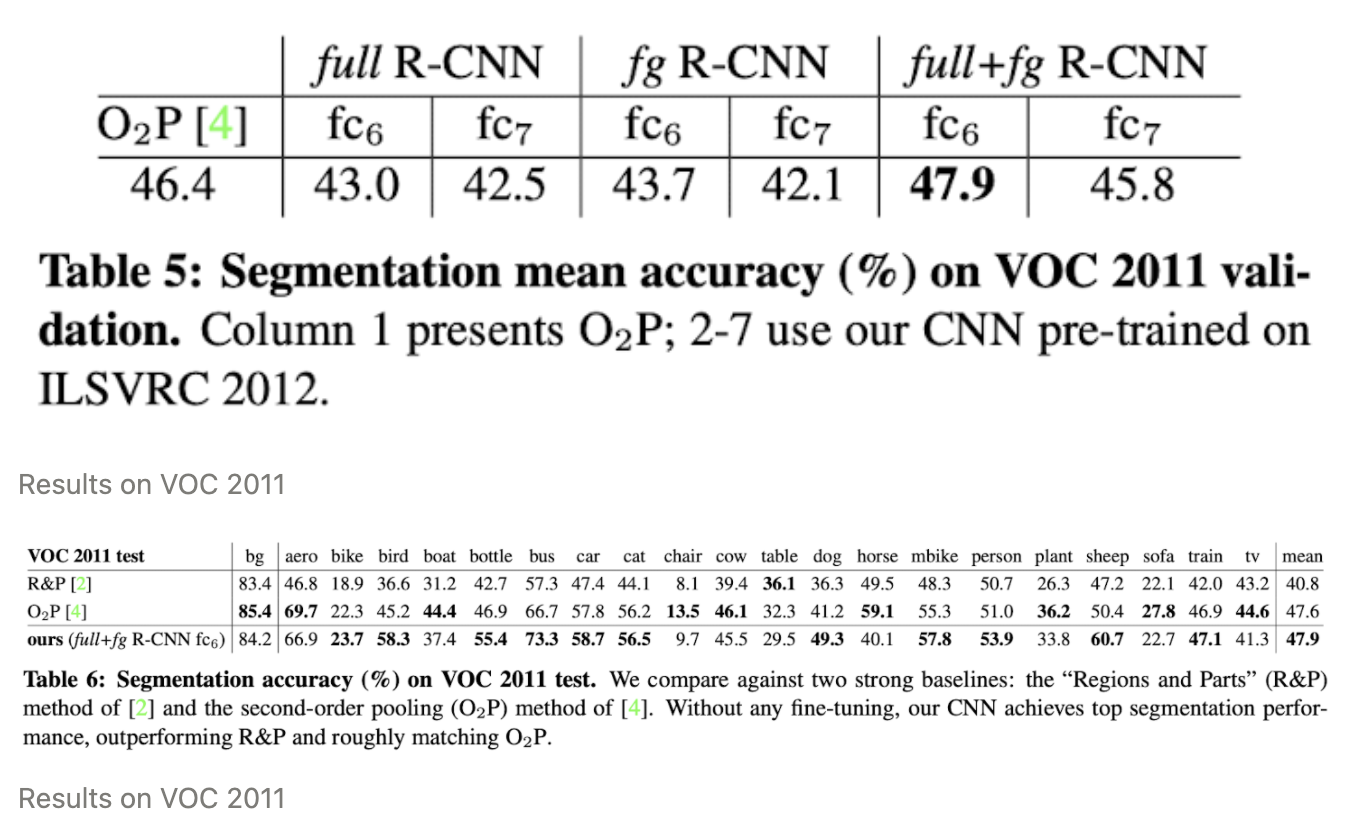
5. Semantic segmentation
edge를 통해서 object localization , 객체끼리는 구분을 안함
semantic segmentation 같은 클래스 끼리는 구분 안함!
instance segmentation → 같은 클래스끼리 차별
6. Conclusion
PASCAL VOC 2012 데이터셋에서 30% 향상시킨 간단, 확장가능한 object detection alogorithm을 제안함
2가지 insights
- to apply high-capacity convolutional neural net-works to bottom-up region proposals in order to localize and segment objects
- a paradigm for training large CNNs when labeled trainig data is scarce. → pre-train, fine-tune
