U-Net이란?
biomedical분야에서 image Segmentation을 위한 Convolutional Network
End-to-End 방식으로 Segmenatation하는 방법이다.
deconvolution의 개념을 사용하여 만들어졌으며, FCN을 기반으로 하였다.
적은 데이터를 가지고도 더욱 정확한 Segmentaion을 내기 위해 FCN 구조를 수정하였다.
U자 모양으로 생긴 U-Net은 의료 이미지 특성상 적은 수의 데이터로도 정확한 Segmentation이 가능하다.
End-to-End 방식: 즉 끝과 끝만 보고 중간의 과정은 기계가 알아서 학습한다
deconvolution이란?
Image Segmentation이란?

기존 cnn은 고양이 사진이나 소 사진을 넣으면, 그저 하나의 클래스가 결과값으로 나온다.(분류목적이 강해서)
즉 cat이나 cow만 분류할수있다. 만약 한 이미지에서 존재하는 모든 정보들을 알기 위해서는?!
=> 이러한 목적을 image segmentation이라고 부른다
image segmentation idea - (1)
window를 사용하여 모든 픽셀에 대해서 하나씩 차근차근 예측하는 것
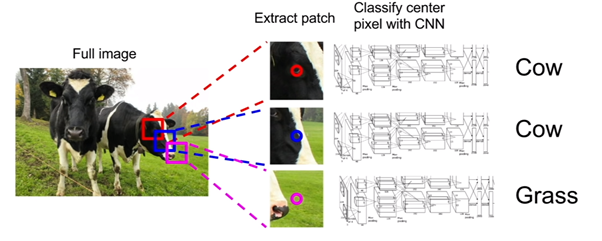
위의 그림처럼 사각형 윈도우가 픽셀 하나를 중심으로 한칸씩 이동하면서 예측하게 된다. 하지만 이 방법은 중복된 이미지의 부분에 대해 독립적으로 다 학습을 진행하여야 하기 때문에 시간이 너무 오래걸린다.
image segmentation idea - (2)
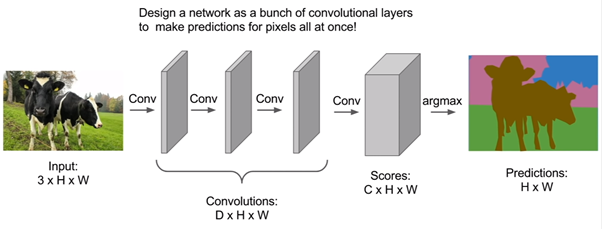
그래서 나오게 된 아이디어가 각각의 픽셀들을 한번에 예측하는 것이다.
이 아이디어는 convolution을 통가활때 padding으로 input 사이즈를 계속 유지시킨다. 그리고 최종적으로 feature 맵으로 각각의 픽셀별로 예측한다.
하지만 문제점은 Convolution network를 input 사이즈를 유지하면서 계속 통과시키다보면 필요한 parameter의 수가 기하급수적으로 늘어나서 memory 과부하 문제가 생긴다.
image segmentation idea - (3)
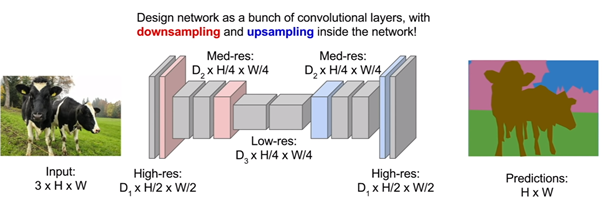
그래서 최종적으로 나온 아이디어가 Deconvolution이다. 모든 픽셀들을 한번에 예측하면서, 입력 사이즈가 줄어들게하기위해, 줄였다가 다시 복원시키자는 아이디어에서 나오게 되었다.
간단히 설명하면, 기존의 CNN과 비슷하게 Feature map 사이즈를 줄이고, 나온 결과를 Deconvolution을 통해 원본 input사이즈로 복원한다.
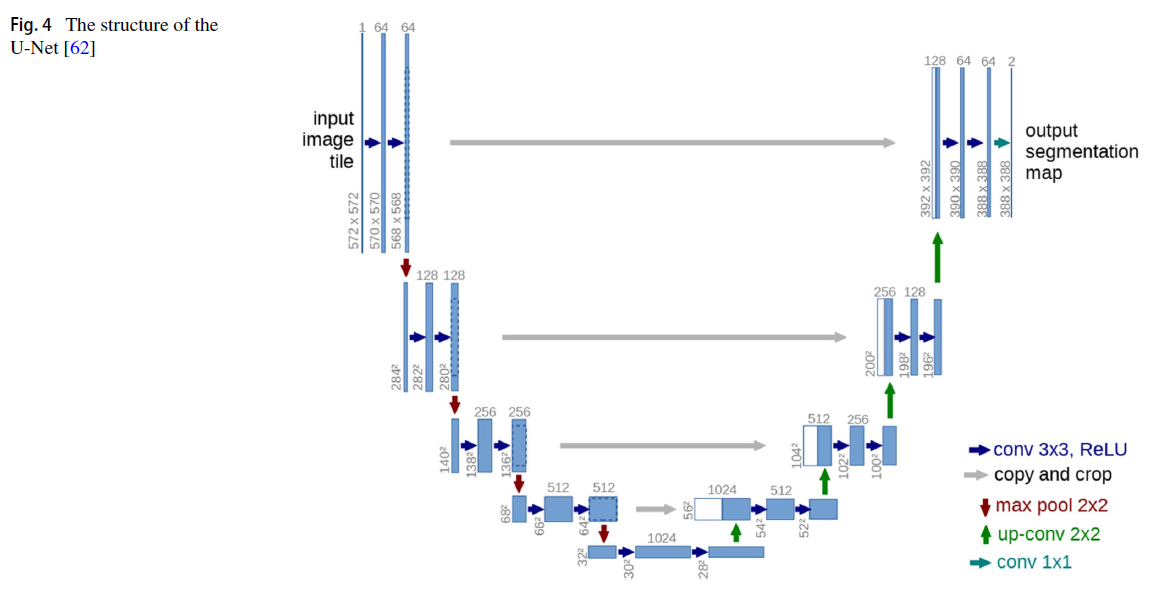
U-NET의 구조는?
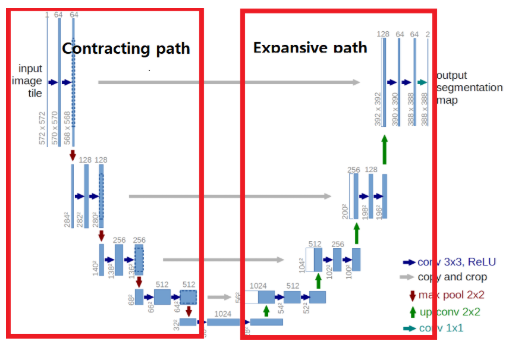
왼쪽은 Contraction path 오른쪽은 Expansive path로 생각하면 된다.
주요 main idea는
1)contraction path를 통해 이미지의 context를 포착하고 //(feature map channel의 수 2배로 증가)
2)Expansive path를 통해 feature map을 upsampling하고 1)에서 포착한 featuremap의 context와 결합한다 이는 더욱 정확한 localization을 하는 역할을 한다.
context는 서로 이웃한 이미지 픽셀간의 관계를 의미, 이미지의 일부를 보고 전반적인 이미지의 context를 파악하는 맥락으로 보면 된다. trade-off는 넓은 범위의 이미지를 한꺼번에 인식하면 전반적인 context를 파악하기에 용이하지만 localization을 제대로 수행하지 못해 어떤 픽셀이 어떤 레이블인지 세밀하게 인식하지 못한다.
U-net이 개선한 점은?
1) 속도 개선: sliding window가 아닌 patch 탐색 방식을 사용해서,overlap비율 적음
->sliding window 방식을 사용하면 이전 patch에서 검증이 이미 끝난 부분을 다음 patch에서 또 검증하기 때문에 낭비가 심하다. 하지만 U-Net은 이미 검증이 끝난 곳은 아예 건너 뛰고, 다음 patch부터 새 검증을 하기 때문에 속도가 빠르다.
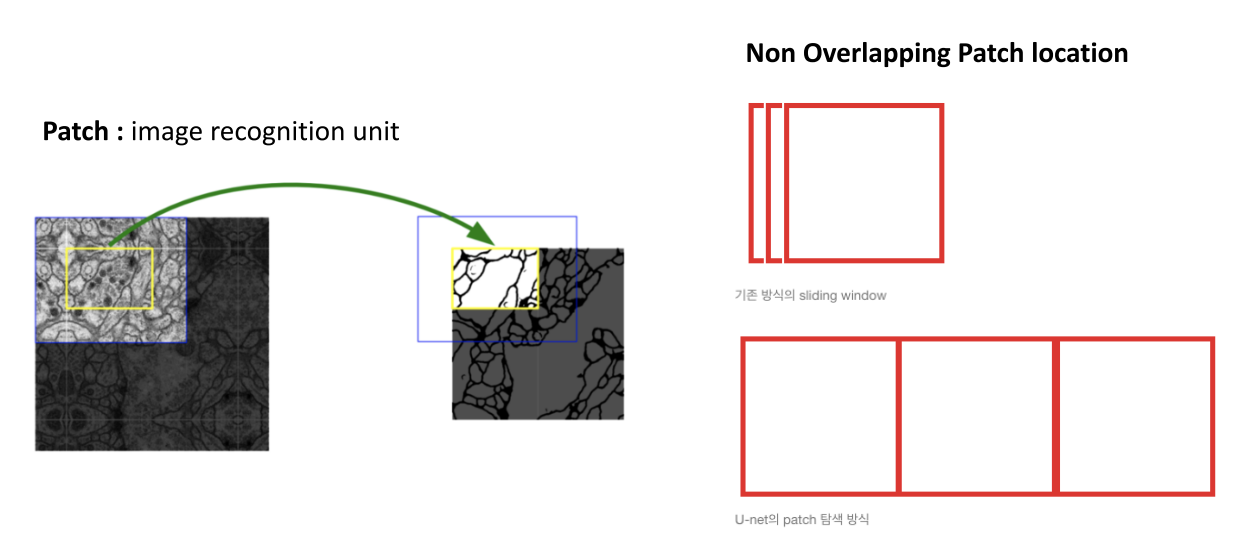
patch방식: input과 output이미지 크기가 다르기 때문에 파란색 영역을 input으로 넣으면 노란색 영역이 output으로 추출된다.
2) Context인식과 localization 간의 trade-off를 해결 : pooling을 거치지 않고(많은 Max-Pooling을 거치며 Localization 성능에는 부정적인 영향을 미치게 됩니다.), deconvolution개념 이용해서
FCN과의 차이점
1) upsampling 과정에서 feature channel의 수가 많다.
2) 각 Convolutio의 valid part만 사용한다.-> overlap tile 기법
3D U-Net
혈관인식에 주로 사용된다.
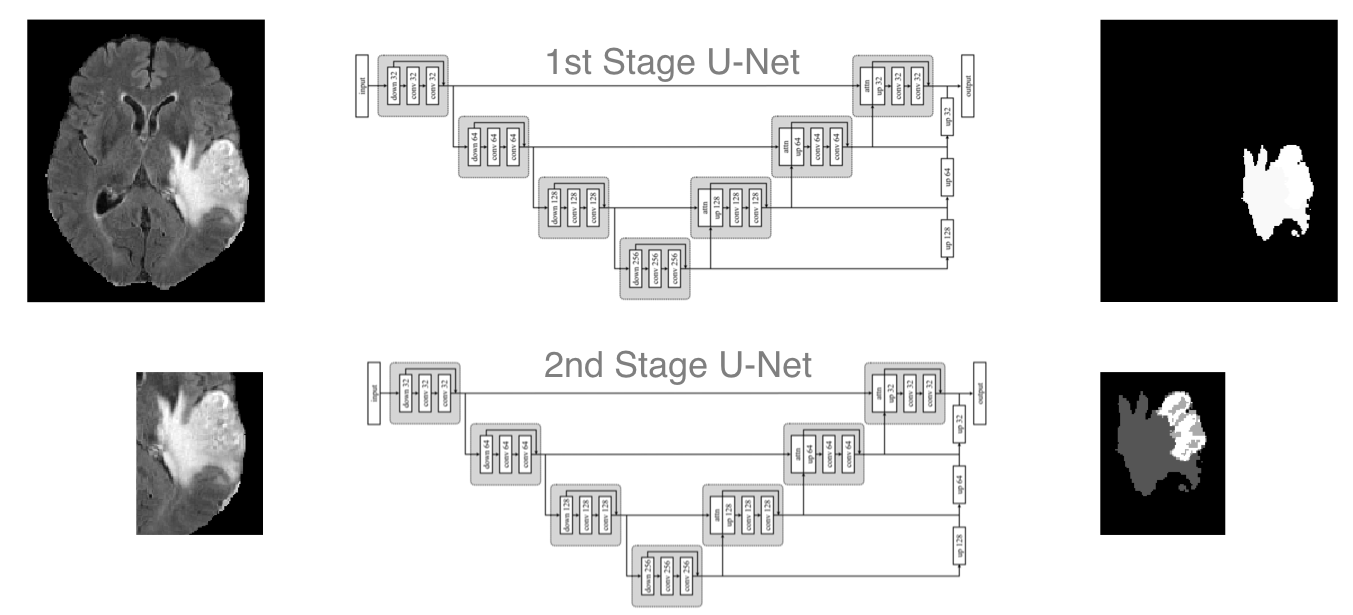
U-Net 을 2번 적용하는 것, 첫 번째 U-Net에서 중요한 부분만 가져와서 다시 학습을 시켜 Segmentation이 더 정밀해진다.
memory 제한 때문에 input image가 248X244X64 제한이 생긴다.
