Elements of Worls Knowledge (EWoK): A cognition-inspired framework for evaluating basic world knowledge in LMs
1. Introduction
-
LLM acquires a substantial amount knowledge from their training data
- knowledge about language (world meaning, syntax)
- knowledge about world (social conventions, physical properties of objects)
-
To check the robustness of the model's language
-
Elements of World Knowledge (EWoK)
-
several domains that constitute the foundation for basic human world knowledge
-
specific concepts within each domain
-
a set of item templates
-
a set of fillers to populate the templates (each templates to be used multiple times)
-
a pipeline to generate a specific set of items
-
-
-
Why Elements?
- this targets specific cognitive targets (e.g. friend/enemy)
- concept leveraged in context are the first-class object of the EWoK as opposed to individual sentences or facts
- NLP benchmarks aim to evaluate knowledge based on individual items
- individual item makes it hard to assess why a model fails
- explicitly link the items with the concepts that they test
-
Why cognition-inspired?
-
selected a range of domains that have been shown to recruit dedicated cognitive and/or neural machinery in humans
- intuitive physics
- physical and spatial relations
- intuitive number sense
- social reasoning
- reasoning about agents with both physical and social knowledge
-
present in preverbal infants
-
but language contains a rich amount of information that reflects grounded world knowledge LLMs might acquire the domain-specific knowledge from text alone
-
-
Why plausibility?
- plausible vs implausible context-target pairs
- plausibility serves as a proxy for factual accuracy (determines whether a given scenario makes sense)
- an accurate world model is necessary for distinguishing the plausibility no matter how they are worded
-
Why minimal pairs?
- contexts and targets in EWoK have a minimal-pairs design
- target change results in an opposite result (plausible implausible)
- help to identify specific manipulations that LLMs are sensitive and they are not
-
Why context-target combinations?
- LLMs are very good at memorization many distinguishing can be done with their presence in the training data
- this framework tests LLM's ability to evaluate contextual plausibility such that the same exact target's plausibility depending on the context
2. Related Work
- commonsense benchmark
- reporting bias in training data
- Co-occurrence information easily available through perception is often underrepresented in language corpora
- earlier LLMs failed
- natural language inference and entailment
-
recognizing textual entailment (RTE)
-
natural language inference (NLI)
-
EWoK asks the plausibility within given context it might indicate an entailment
-
LLMs use heuristics to solve the task rather than the understanding
- in EWoK, the task is posed as a minimal pair (one must be preferred over the alternative) making reliance on target plausibility alone is impossible
- test which item design features drive model performance
- test the relationship between the LLM performance and surface-level item properties (length, average work frequency, BoW model performance)
-
- bAbi
- similar design about world knowledge and reasoning
- EWoK is more simpler design and harder in practice
- minimal pair design
-
SyntaxGym, BLiMP, COMPS
-
Winograd Schema Challenge
-
EWoK used minimal pairs of pairs design
- both context and target sentences have a minimal pair counterpart
-
- assessing LM performance
-
until 2023, each item's log probability
- effective at grammatical vs ungrammatical
- plausible and implausible
- relevant and irrelevant object properties
-
log probability shows the surface-level properties
-
Recently, to prompt an LLM to rate them plausibility
- LLM performs worse in direct prompting than implicit log probability
- in EWoK, both log probability and explicit prompting are used
-
3. The Framework
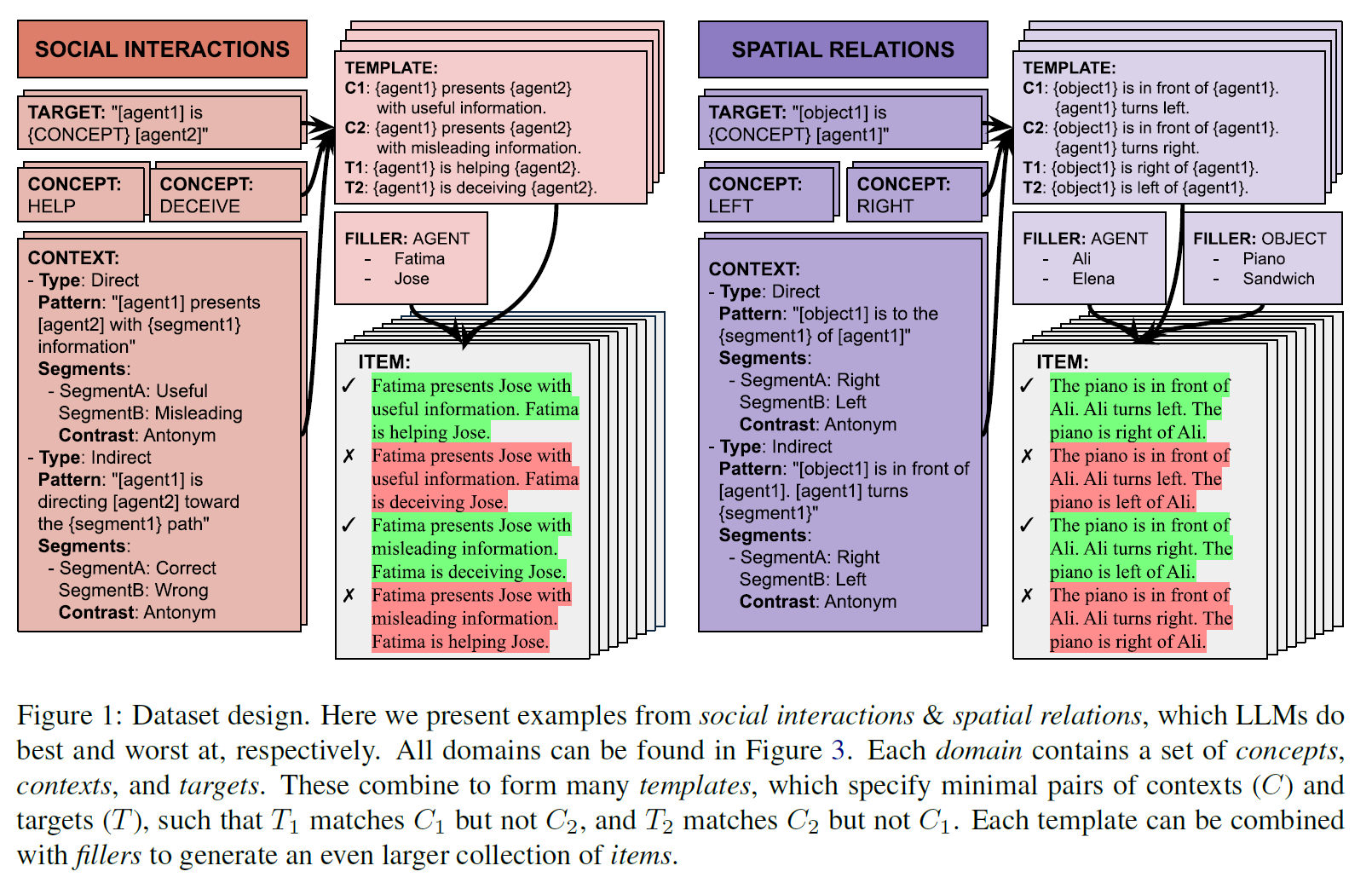
Item Format
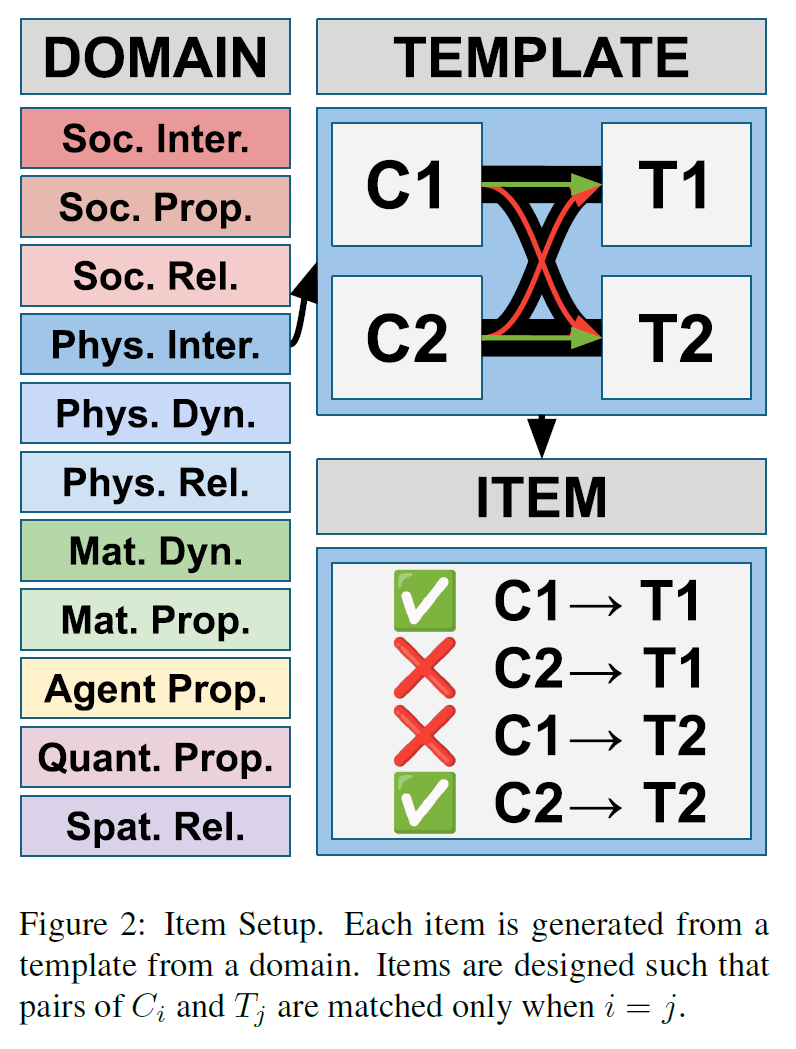
-
Each item consists of two minimal pair contexts
- : The piano is in front of Ali. Ali turns left.
- : The piano is in front of Ali. Ali turns right.
-
Also, there are two target sentences
- : The piano is right of Ali.
- : The piano is left of Ali.
-
the two target items are juxtaposed such that
- and
-
then the base target and can't serve as plausibility cues the model should rely on the given context
Domain and Concenpts
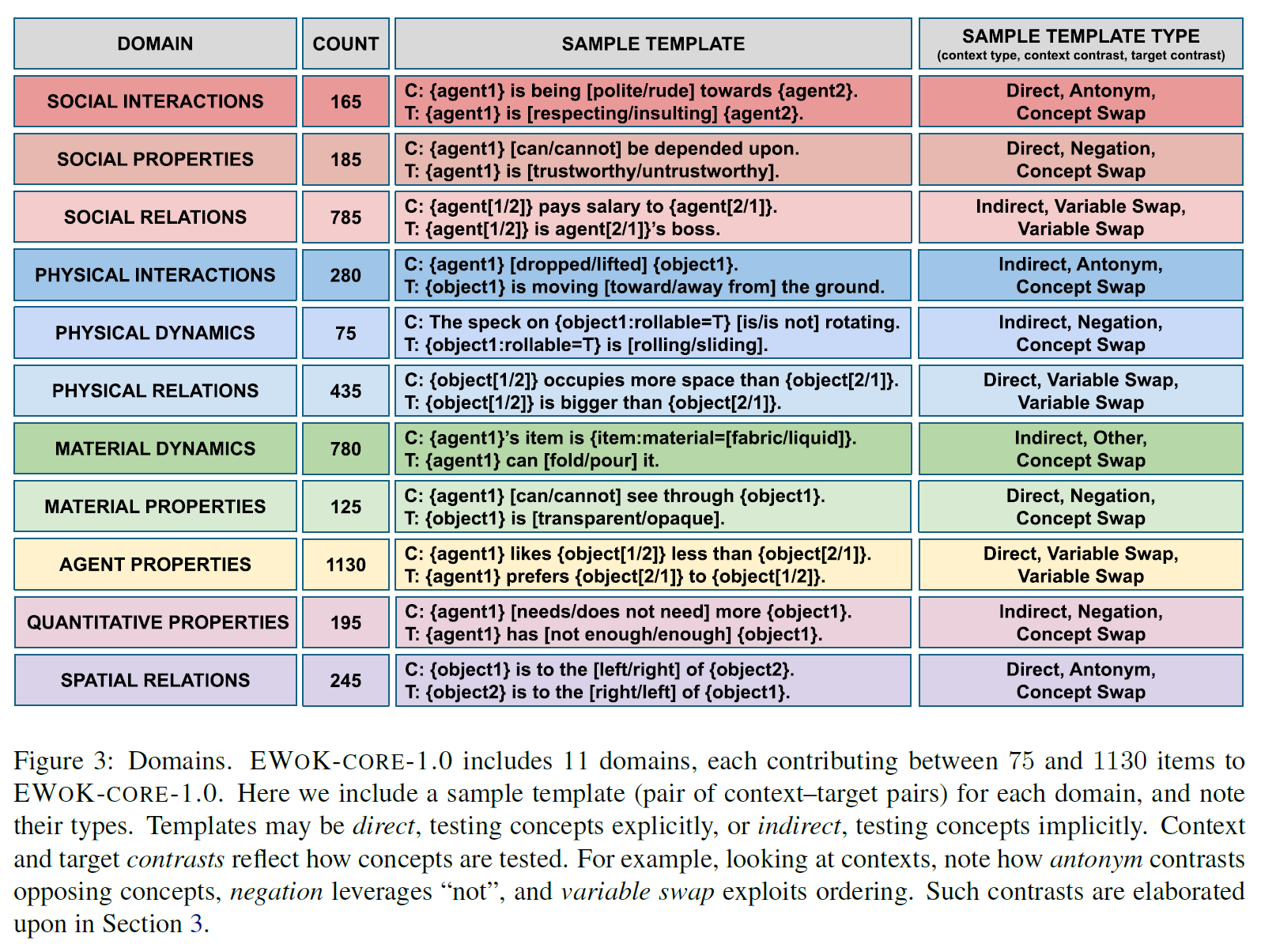
Dataset generation procedure
-
each concept is associated with several items that test knowledge of the concept (mostly contrasting with another concept)
-
flexible but controlled manner
-
atomic units and combination rules generation of templates with fillers
Contexts and Targets
-
target : a simple sentence that incorporates a concept
-
contrasting target pair is generated by
-
concept swap
- {agent 1} is to the left of {agent 2}
- {agent 1} is to the right of {agent 2}
-
variable swap
-
{agent 1} is to the left of {agent 2}
- {agent 2} is to the left of {agent 1}
-
-
-
context pair : one or more minimal pair of sentences that is pared with a target pair
- only matches with and only matches with
- typically an opposite concept pair (left/right) or single concept (left, with variable swap)
-
contrasting concept pair is generated by
-
filler swap
- use contrasting fillers
-
variable swap
- changes the positions of two entities of the same kind
-
Templates and Fillers
-
Each collection of concepts, contexts, targets can be compiled to as set of templates
-
partial items with types variables describing the range of fillers
- {object2: can_bounce=True} bounced off {object1} from below
- object1 can be the desk or the crate
- object2 should be the object marked with can_bounce=True (the ball, the tire)
- 500 filler items across 13 classes with 28 type restrictions
-
users can specify various custom parameters
-
number of items to generate from each template
- full set of items "version"
-
whether fillers should be hold constant across all items in a version
-
apply transformations to filler restrictions at compile-time
- agent agent:western=False
- object nonword
-
-
this allows controlled experimentation of the features
4. Evaluation
-
with this framework, EWoK-CORE-1.0 is released by generating 5 unique fixed substitutions of filler items across 880 templates from 11 domains
-
evaluated with LogProb and two prompt-based methods LIKERT, CHOICE
- LogProb outperforms the direct prompting
-
for the prompt-based evaluations
- collected data from LLMs and humans using paired identical prompts
4.1. Scoring Metrics
-
LogPRobs
- token-level LLM probabilities with sum of conditional log probs of each token
-
LIKERT
- participants are prompted to reate the plausibility of each and pair on 1-5 scale
-
CHOICE
- participants are given , and a single target
- participants should choose between and which better matches with
-
the metric for correctness fo given item is the recovery of the designed item structure
- and
- the score is different from method
-
find both matches 1.0 (full point)
-
find only one match 0.5 (half point)
- in LIKERT, this is the case with the model gave same ratings
-
trivial 50% baseline for all scenario
4.2. Models
-
20 transformer LMs
-
1.3B-70B and different pretraining diet
-
13 dense pretrained transformers
-
4 instruction-tuned
-
2 chat fine-tuned
-
1 MoE
-
the model doesn't require specific formatting
4.3. Surface-level item properties
-
baseline: BoW with word2vec
-
scored with Cosine-Similarity
-
tested LLM with number of words in each item and average word frequency in an item with Google Ngrams
4.4. Human Data
-
1262 participants (591 female, 579 male, 27 other)
-
median age 36
-
US-residents with first language Enalish
-
poor agreement with others were excluded
5. Release Considerations
-
reduce the chances of caccidental incorporation of EWoK into LLM's training data
-
promote accountability and reporting when such incorporation is done intentionally
6. Experiments
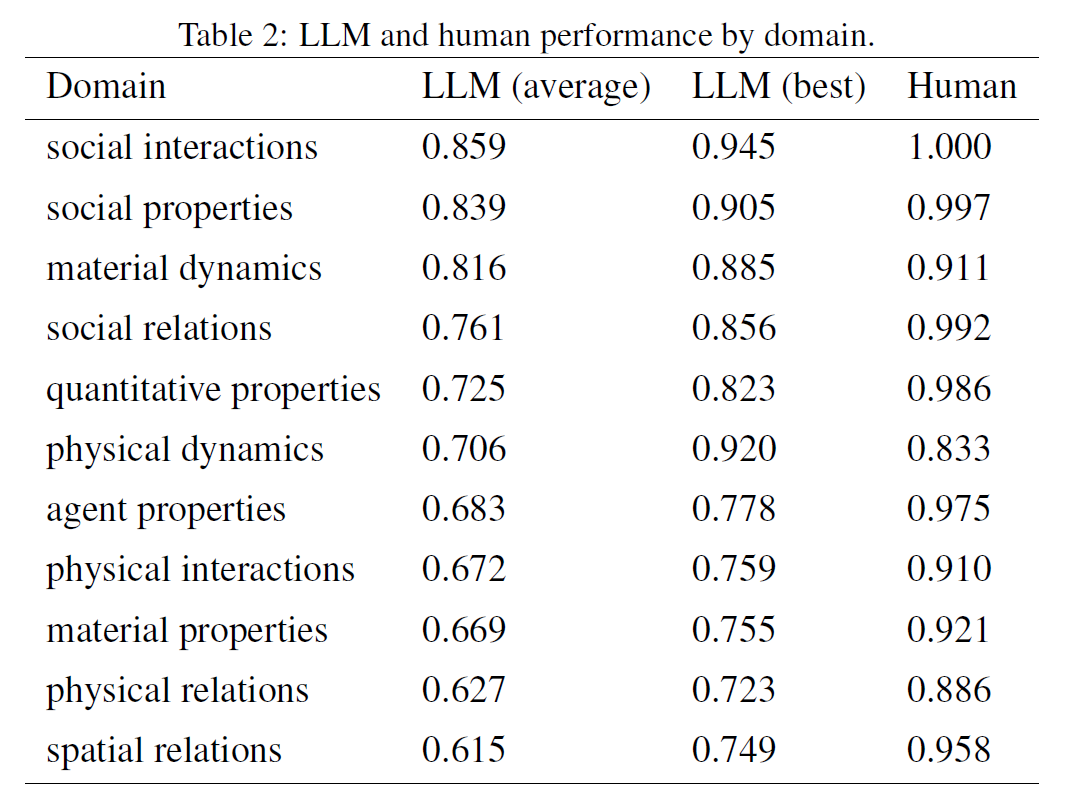
EWoK-CORE-1.0 is challenging for LLMs
-
even larger models generally perform much below humans
-
best one falcon-40b-instruct git 0.80 while human got 0.95
-
instruction tuning doesn't affect to the performance under LogProbs
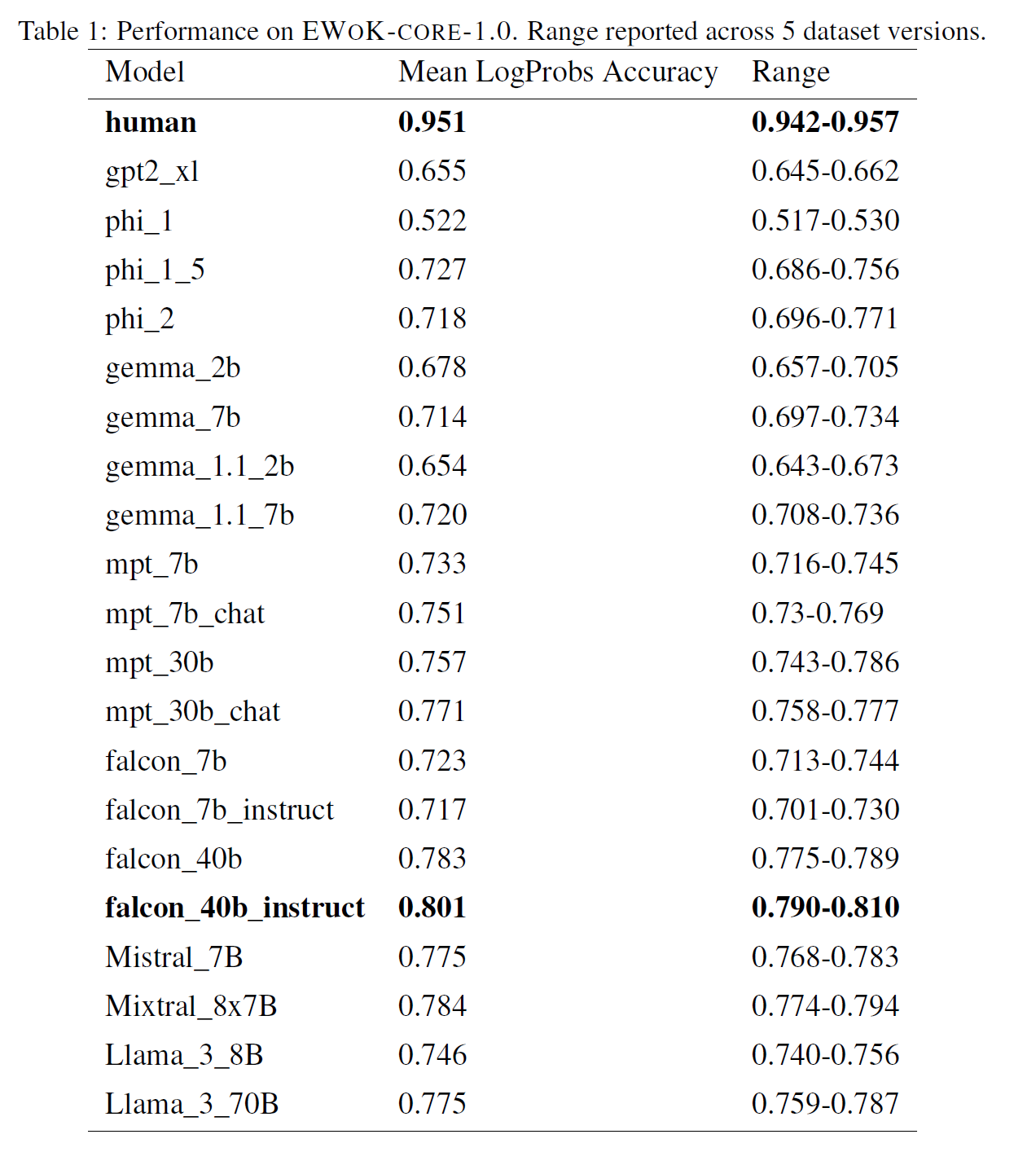
Performance vaires drastically by domain
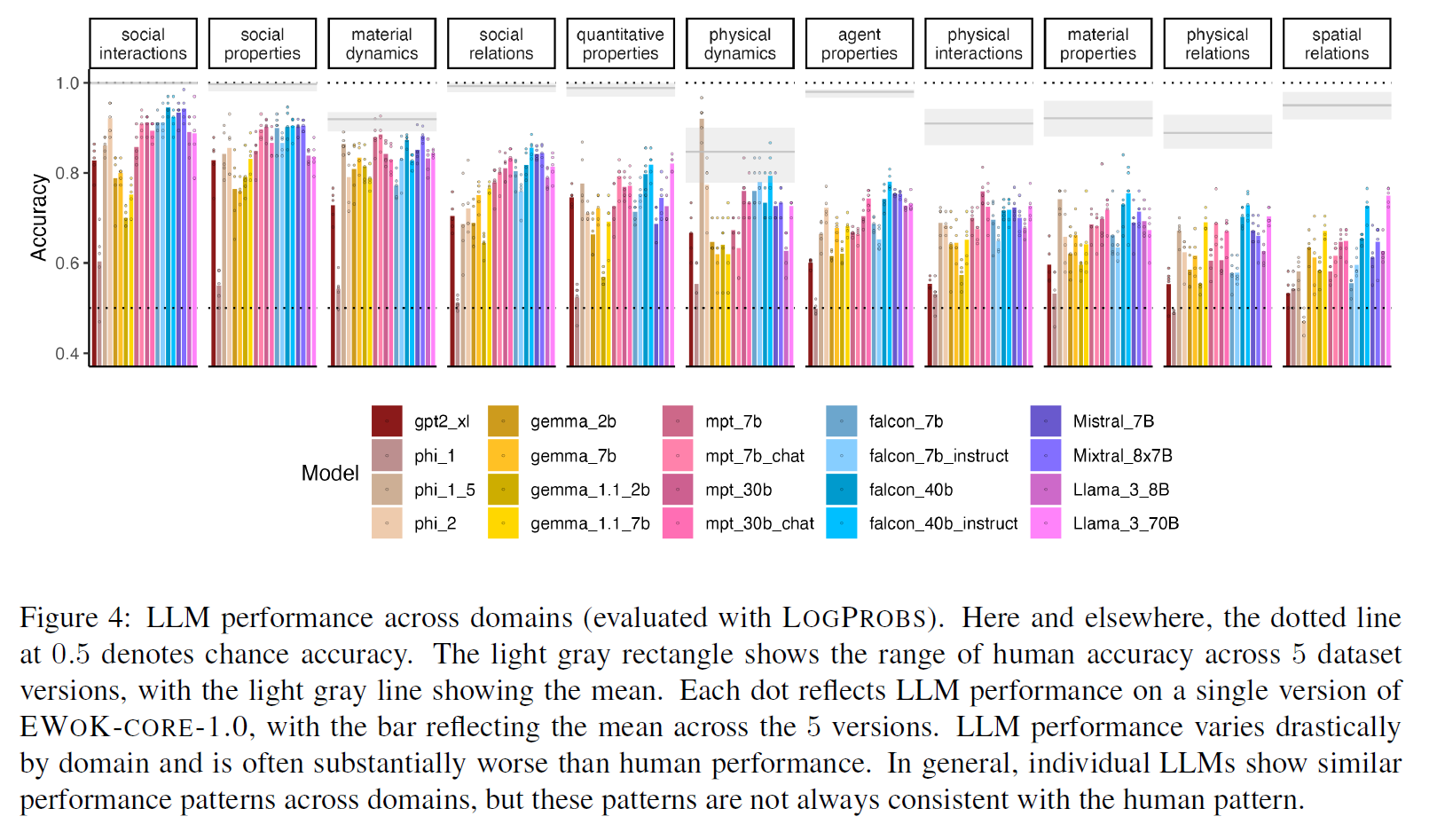
-
domain difficulty is consistent across LLMs
-
heterogeneous performance of the phi models
- phi-1 is the worst
- phi-1.5 outperforms all models and even humans on physical dynamics
- phi-2 on par with the largest models on some domains to worst than gpt2-xl on spatial relations
- possibly due to their unique training procedure (synthetic data)
LLMs show heterogeneous performance across dataset versions
-
in principle, these variables should not affect the results
-
phi-2 and phi-1.5 showed the largest performance range
-
humans showed somewhat heterogeneous performance too (driven only by a subset of the domains)
Domain content, item design features, and surface-level item features all affect LLM performance
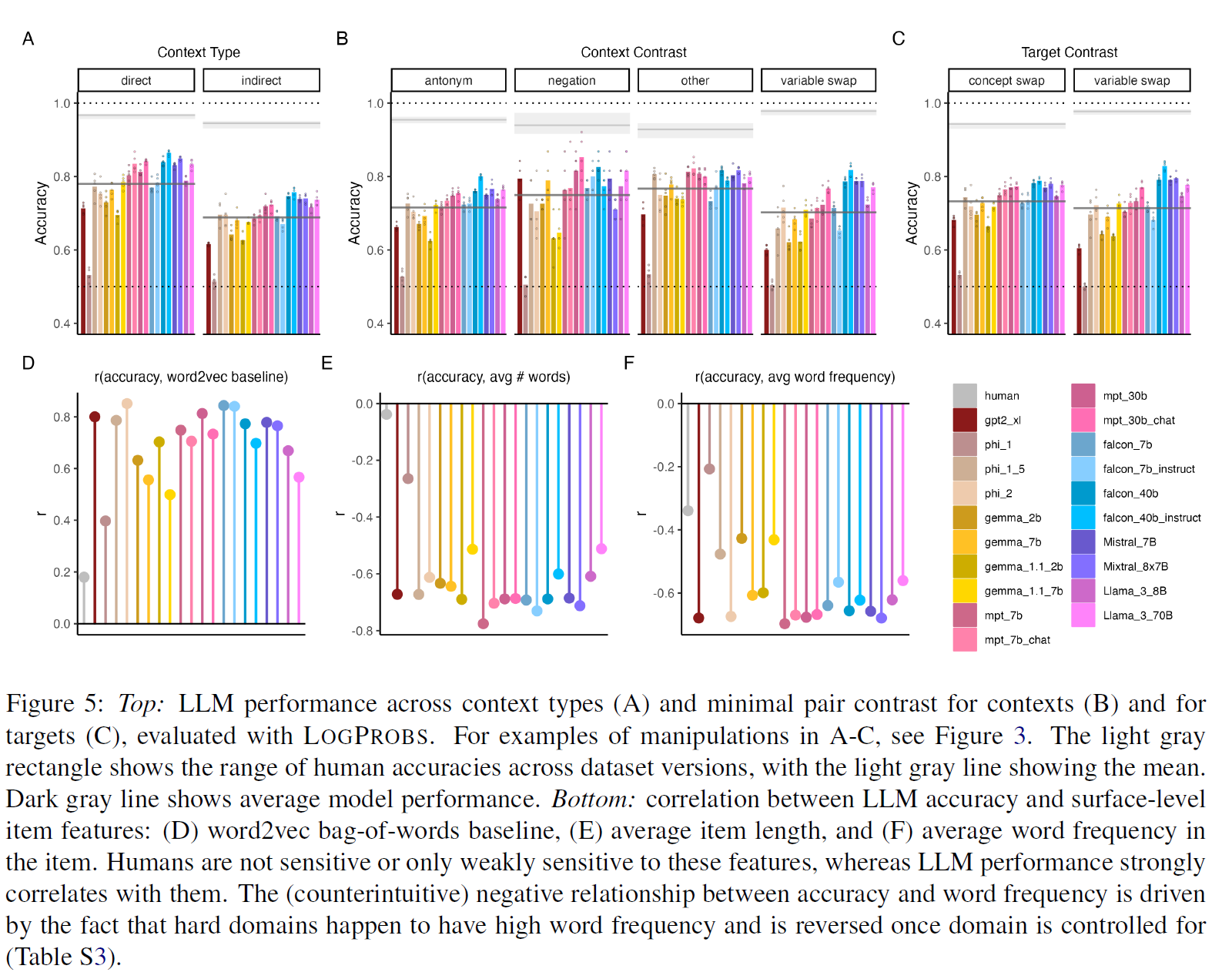
-
they affected the performance often in a different ways than they affect humans
-
BoW baseline is predictive of LLM but not human
-
the number of words in an item negatively affects LLM but not model performance
-
word-frequenct is negatively affected to both LLM and human performance
- this is because the hardest two domain (physical-relations and spatial relations) have the highest word frequency
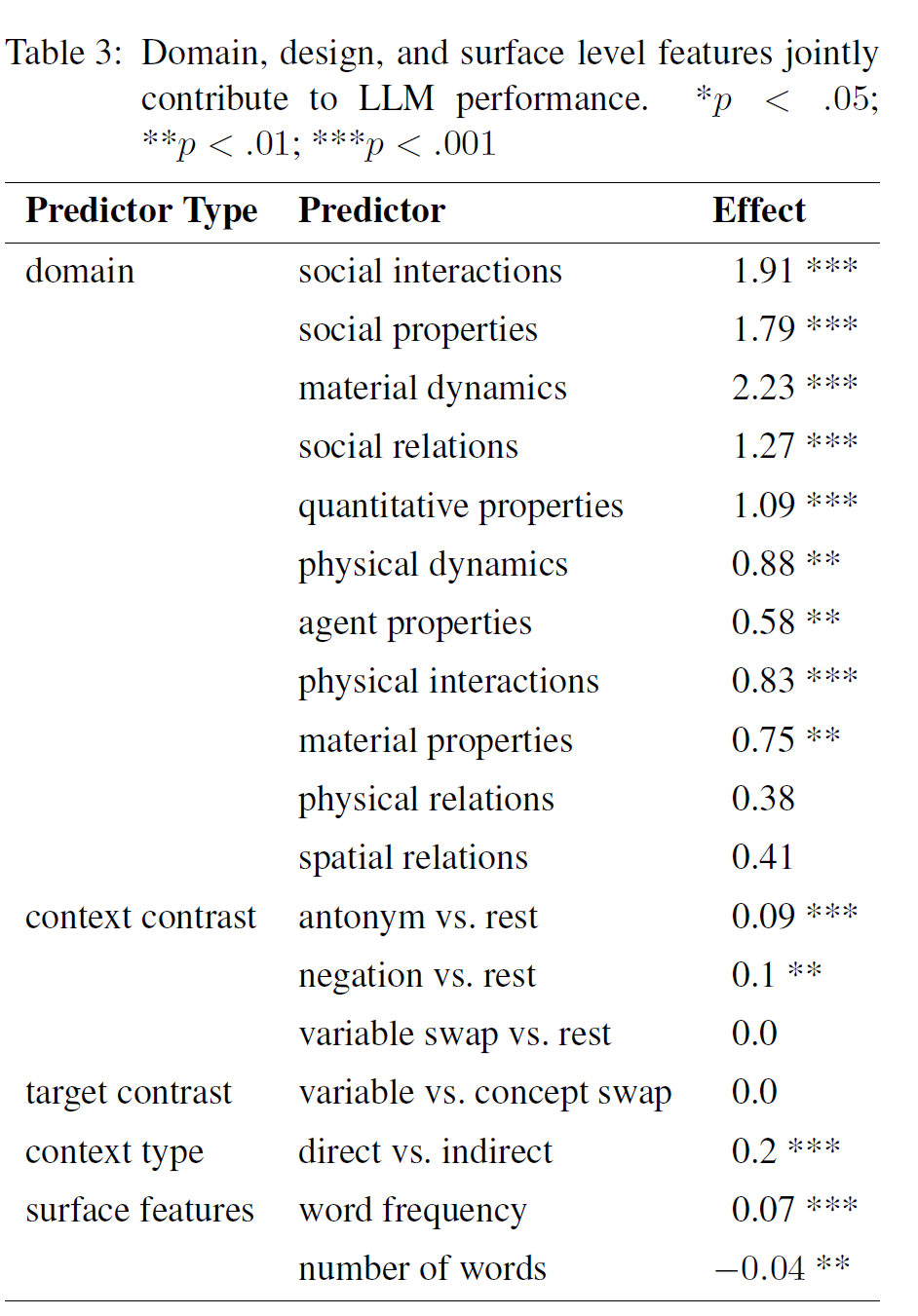
- jointly models all features using mixed effects regression
- word frequency has a significant positive effect
- the number of words has a significant negative effect
- the domain is remained a significant predictor of performance
LogProbs yield higher accuracy than prompting
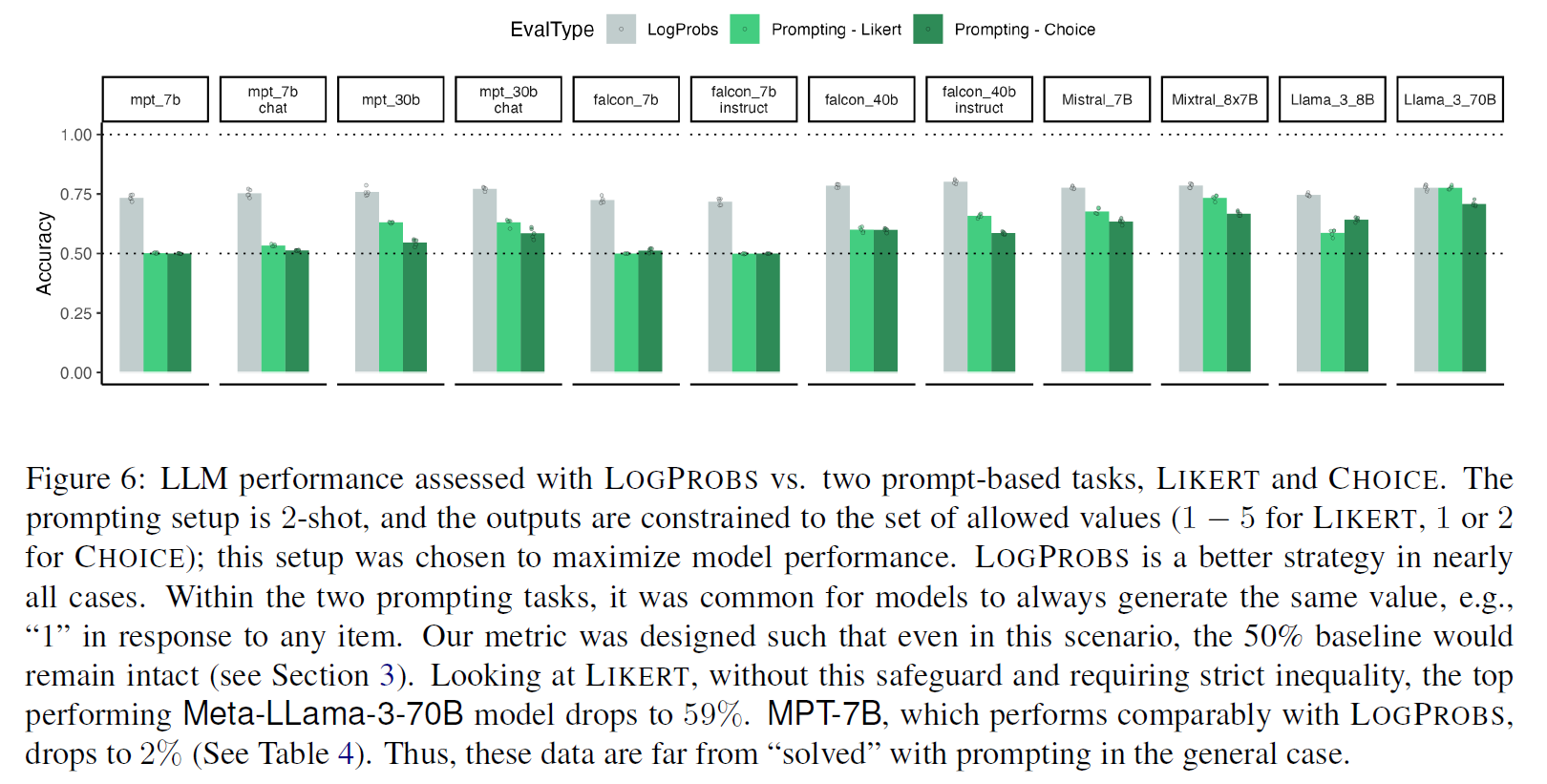
- the gap was large in smaller models
Human ratings are often but not always accurate
- sometimes the discrepancies between human ratings and experimental labels resulted from specific fillers changing the plausibility
- The cooler is inside the car. Chao cannot see the cooler
- this is implausible as the cooler is large and the car has windows
- but the small object and the container without window is plausible
- Human made mistakes
- the bakery is north of Chao. Chao turns around. The baker is south of Chat.
- this is implausible as cardinal directions don't depend on the agent's orientation
7. Discussion
-
the goal was to develop a dataset
- uses a uniform item format to probe diverse domains of physical and social knowledge
- contains items that probe specific concepts
- requires integrating information across sentences
- consists of generic templates that can be used to generate a wide variety of items
-
presented evaluation results
-
EWoK-CORE-1.0 is moderately challenging for LLMs
-
LogProbs contain enough information for most LLMs
-
Future Work
-
Targeted experiments
- the flexibility of the framework allows specific experiments using customized sets of fillers
-
Interpretability research
- Knowledge Editing research to basic physical and social concepts
-
From elements to world models
- model to function as a flexible and robust general purpose AI system, it needs tob e able to construct, maintain and update internal world models
- LLMs usage of internal world models is ongoing investigation
-
-
Limitations
-
written in English
-
same prompting setup for all models
- with tailored prompt engineering, the performance can improve
-
some items are semantically weird
- due to the synthetic nature of dataset
-
8. Conclusion
- EWoK provides a way to evaluate the fundamental elements of workd knowledge
9. Comment
실제 세계에 대한 모델의 '이해'를 테스트 하려고 만든 데이터셋. 범용성이 있고 공들여 만든 것으로 보이지만 더 적절한 평가 방법이 있으면 좋을 것 같음.
