1. Introduction
- GPT
- Analytical AI to Generative AI
- large PLM + Prompt superior performance
- needs for evaluating the quality of these texts
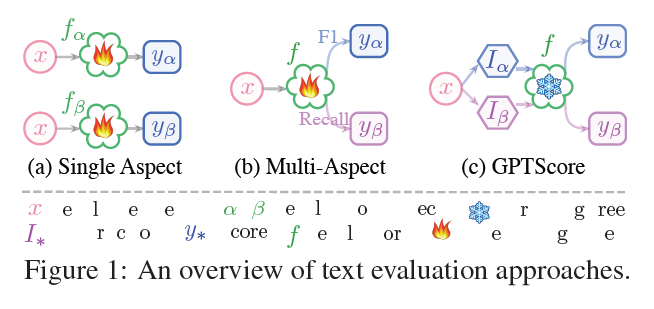
-
evaluating single aspect
- hard for users to evaluate aspects as they need
-
multi-aspect evaluation
- lacks the aspects' definition and relationship
- empirically bound with metric variants
-
Needed supervised training and manual annotation
-
using LLM to achieve multi-aspect, customized and training-free evaluation
- using zero-shot instruction and ICL
- higher quality text for a specific aspect will be more likely generated
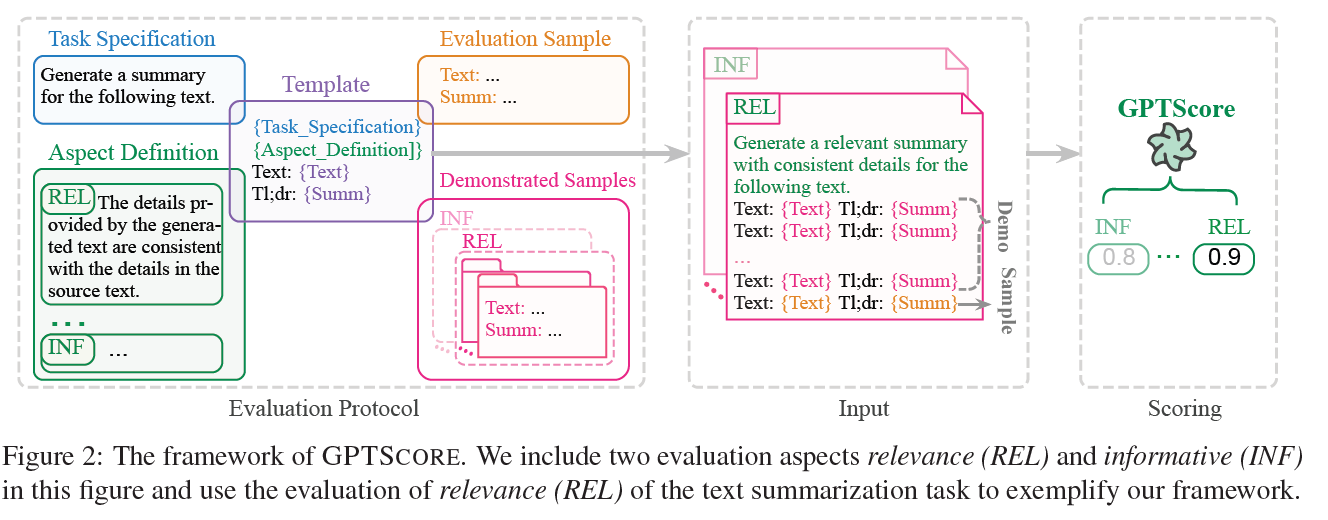
- perform an evaluation as the user desires
-
task specification
-
aspect definition
-
deponstrated samples
- well-labeled sample
-
GPT to calculatehow likely the text could be generated based on the evaluation protocol
- GPT2, OPT, T5, GPT3
-
- almost all NLG task
- performed well when instructed by the definition of task and aspect
- different evaluation aspects exhibit certain collerations
- in summarization, data-to-text and dialogue response, GPTScore outperformed fine-tuned models
- gpt3-text-davinci-003 (human feedback) is inferior to text-davinci-001
2. Related Work
Similarity-based Metrics
-
lexical overlap-based
- BLEU
- ROUGE
-
embedding-based
- BERTScore
- MoverScore
Single-aspect Evaluator
- Coherence of dialogue system
- DEAM
- QuantiDCE
- Consistency
Multi-aspect Evaluator
- one evaluator handles several evaluation aspects
- different input and output pair
- different prompt by the aspect name
- different formulas
Emergent Ability
-
ICL
-
CoT Reasoning
-
Zero-shot instruction
BARTScore vs. GPTScore
-
BARTScore needs a fine-tuning step
-
GPTScore > BARTScore
- customizable
- multi-faceted
- train-free
3. GPTScore
- GPT will assign a higher probability of high-quality text given instruction and context
- : task description
- : aspect definition
- : text to be evaluated
- : context information (source or reference)
-
: weight of the token at position (in this work, it is treated equally)
-
: prompt template that defines the evaluation protocol
- task-specific
- handcrafted with prompt engineering
-
- Few-shot
- extending
- Prompt Template
- officially given by OpenAI (GPT3-based model)
- NaturalInstruction (instruction based pre-trained model)
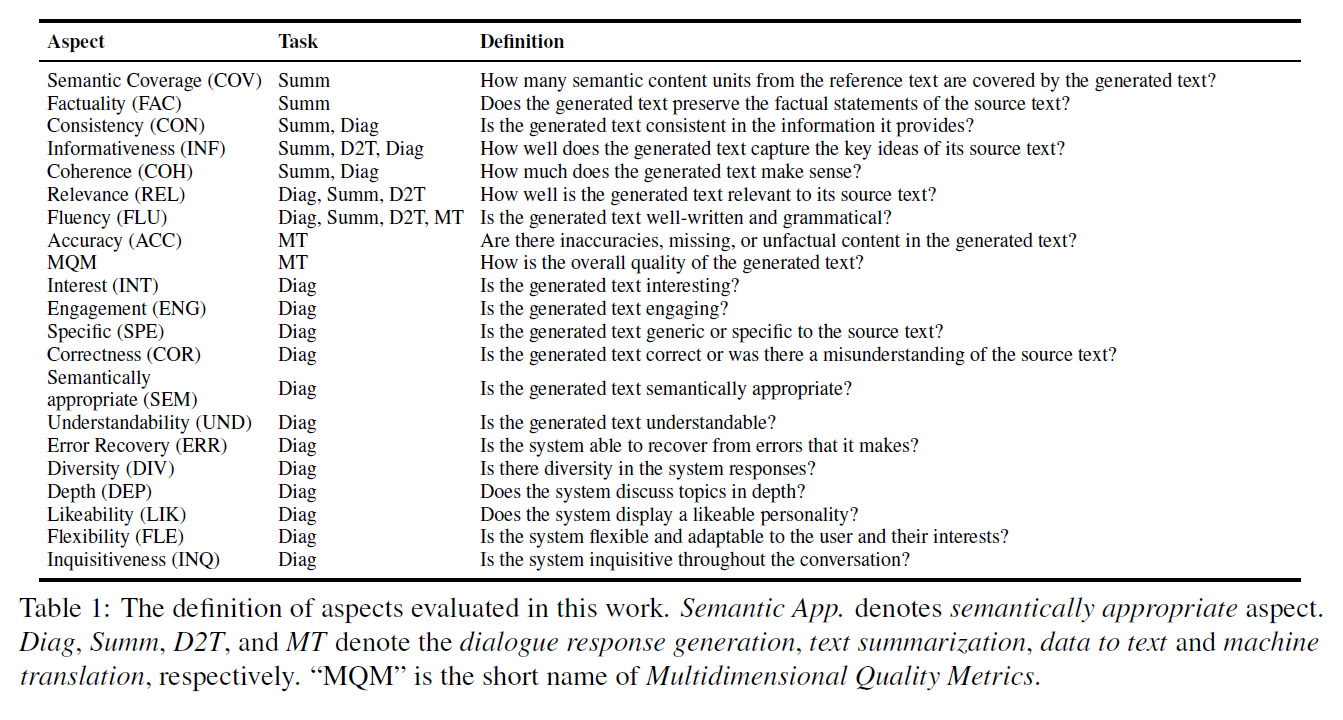
- Selection of Scoring Dimension
- vs.
- in GPTScore, it is chosn to aligh the protocol of human
4. Experimental Settings
4.1 Meta Evaluation
- how well automated scores correlate with human judgement
- : correlation function (Spearman, Pearson)
4.2 Tasks, Datasets and Aspects
-
Tasks
-
Dialogue Response Generation
- generate an engaging and informative response
- FED datasets
- turn-level, dialogue-level evaluation
-
Text Summarization
- SummEval
- REALSumm
- NEWSROOM
- QAGS_XSUM
-
Data-to-Text
- generate a fluent and factual description for a given table
- BAGEL
- SFRES
-
Machine Translation
- MQM (Multidimensional Quality Metrics) -> MQM-2020 (Ch->Eng)
-
-
37 Datasets
-
22 Evaluation Aspects
4.3 Scoring Models
-
ROUGE
- ROUGE-1
- ROUGE-2
- ROUGE-L
-
PRISM
-
BERTScore
-
MoverScore
-
DynaEval
- dialogue response generation tasks on the turn level and dialogue level
-
BARTScore
- scoring model based on BART without finetuning
- +CNN (finetuned on the CNNDM dataset)
- +CNN +Para(+CNNDM +Paraphrase 2.0)
-
GPTScore
- 19 PLMs backbone
4.4 Scoring Dimension
- INT, ENG, SPC, REL, COR, SEM, UND, FLU from FED-Turn
- human data in the dataset
- COH, CON, INF from SummEval and Newsroom
- labeled data exists
- INF, NAT and FLU from the data-to-text
- source text is not standard function
- ACC, FLU, MQM from machine translation
- source text is in different language
4.5 Evaluation Dataset Construction
-
sampled 40 sample for each summarization dataset
-
sampled 100 samples for dialogue response generation and data-to-text
5. Experiment Results
- three scenario
- Vanilla : non-instruction and non-demonstration
- IST : instruction only
- IDM : instruction + demonstration
- Significance Tests
-
based on bootstrapping
- IST or IDM > VAL
- IDM > IST
-
5.1 Text Summarization
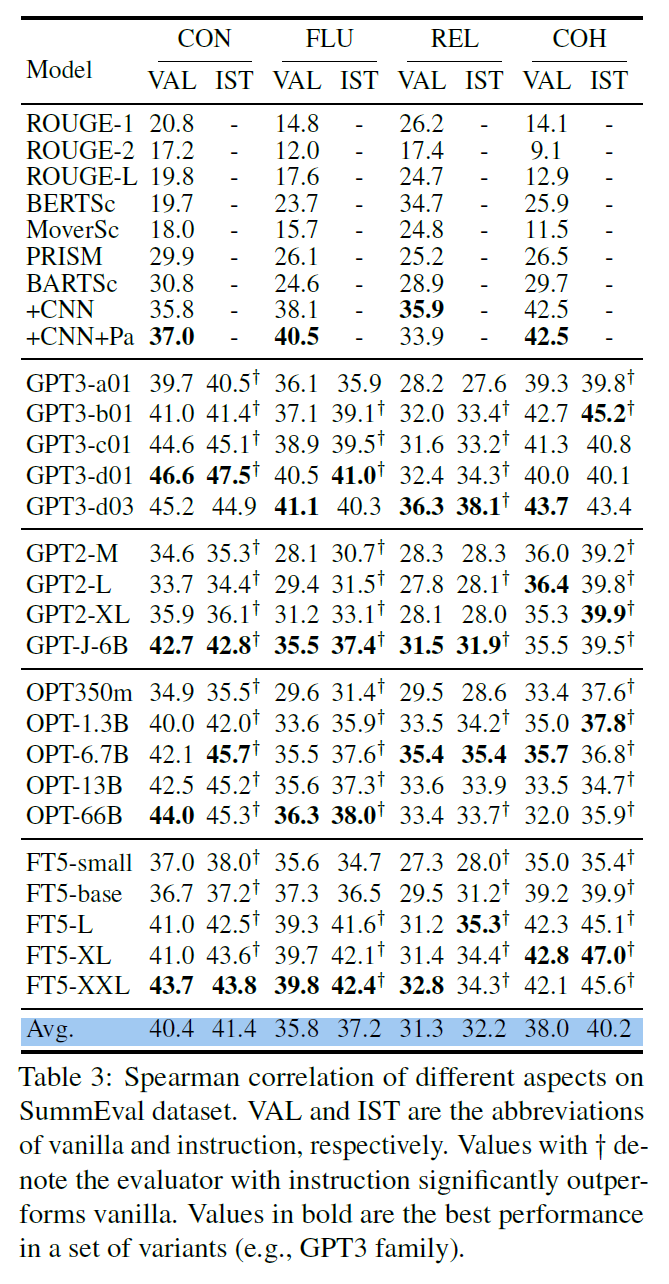
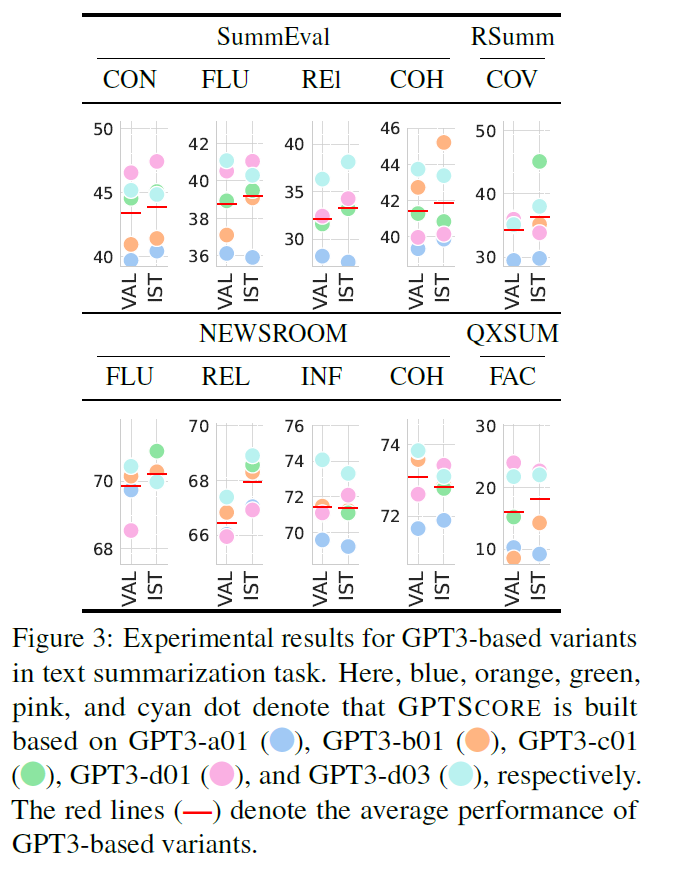
-
Evaluator with instruction significantly improves the performance
-
GPT3 / FT5 based models + instructions > supervised method
5.2 Data to Text

-
IDM > IST > VAL
-
IDM > finetuned model
-
the choice of examples impacts the performance a lot
-
IDM + GPT3 small size family > large sized model
5.3 Dialogue Response Generation
-
GPT3-d01 >> GPT3-d03
-
GPT3 based model demonstrate storonger generalization ability
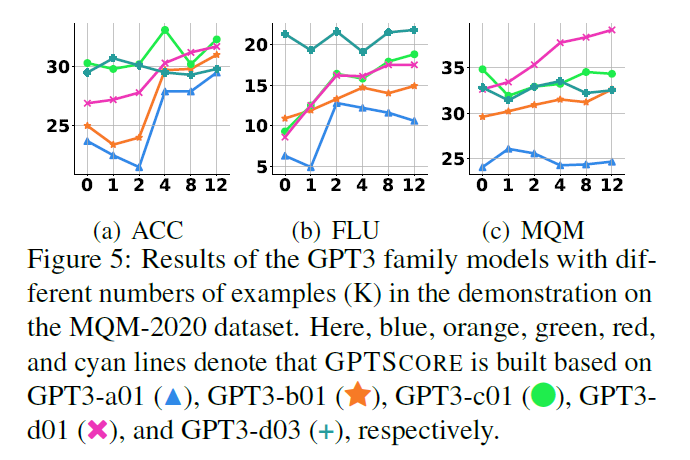
5.4 Machine Translation

-
IST improved the performance
-
IDM > IST
-
GPT3-c01 achieved comparable performance with d01 and d03
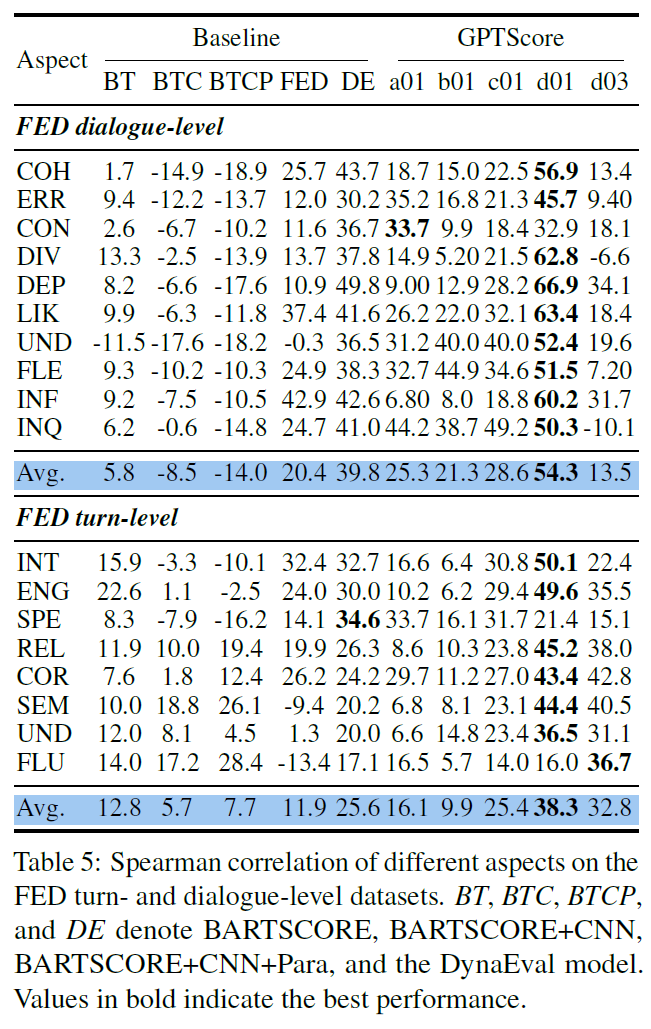
6. Ablation Study
6.1 Effectiveness of Demonstration
-
demonstration improves the performance
-
there is an upper bound on the performance gains
-
if there is only a few samples, small models are prone to performance degradation
6.2 Partial Order of Evaluation Aspect
- tested INT as the target aspect
- combined other aspects with the definition of INT
- GPT3-c01 6.7B

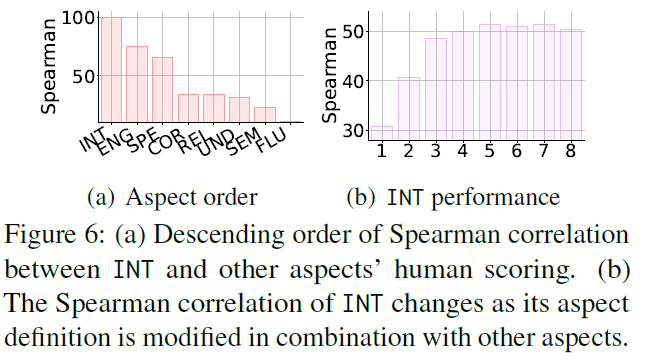
- By combining definitions with other highly correlated aspects, smaller model outperformed the bigger model
7. Conclusion
- customable multi-faceted, train-free evaluation framework using emergent ability of LLM
8. Limitation
-
Not included GPT 3.5 and GPT 4
-
the reason why d03 is worse than d01 is unclear as it is not open source
-
API cost issue
