SELF-EXPERTISE: Knowledge-Based Instruction Dataset Augmentation for a Legal Expert Language Model
paper-study
1. Introduction
- Instruction Tuning Dataset
- Instruction Tuning is important for LLMs
- Auto generation method is unsuitable for some domains where the accuracy is important
- SELF-EXPERTISE
- automatic instruction data generation for knowledge-intensive tasks
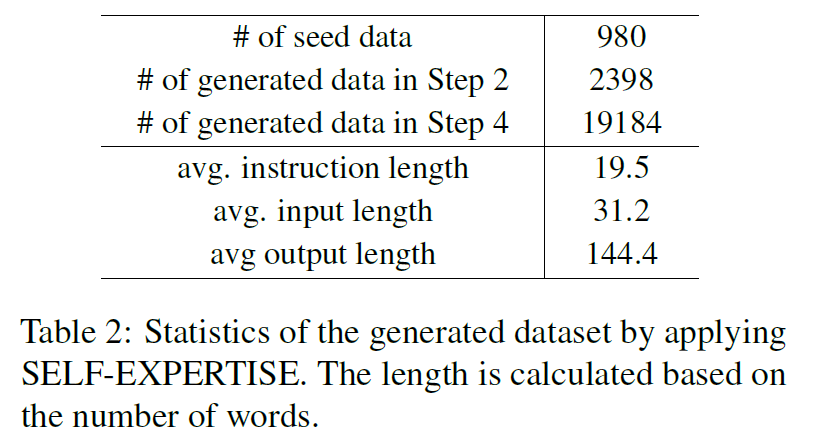
- 19k dataset from 980 seed dataset
- LxPERT : LLaMA-2-7B + SELF-EXPERTISE

2. Related Work
2.1 LLM-based Instruction Dataset Augmentation
-
Generate instruction dataset using LLMs
-
Self-Instruct Prone to hallucination
2.2 Knowledge-Intensive Tasks
- requires knowledge-based solution
- legal domain is knowledge intensive
- RAG
- SELF-EXPERTISE generates instructions and outputs based on precise external knowledge
3. Methodology
3.1 Defining Instruction Data
- typical instruction dataset
- (instruction, input, output) triplet + system instructions
- to facillitate reasoning and narrative structure
- input is optional
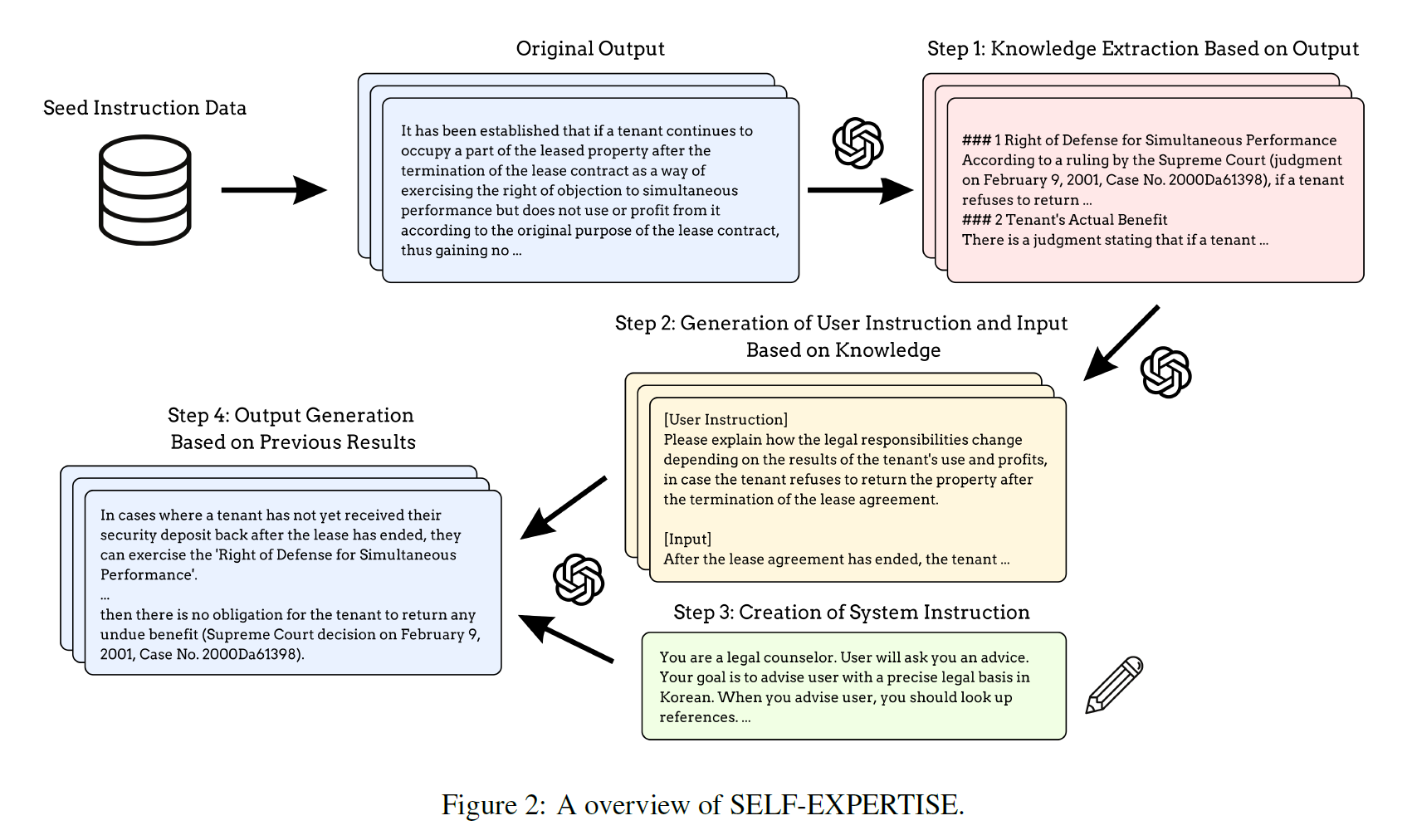
3.2 SELF-EXPERTISE
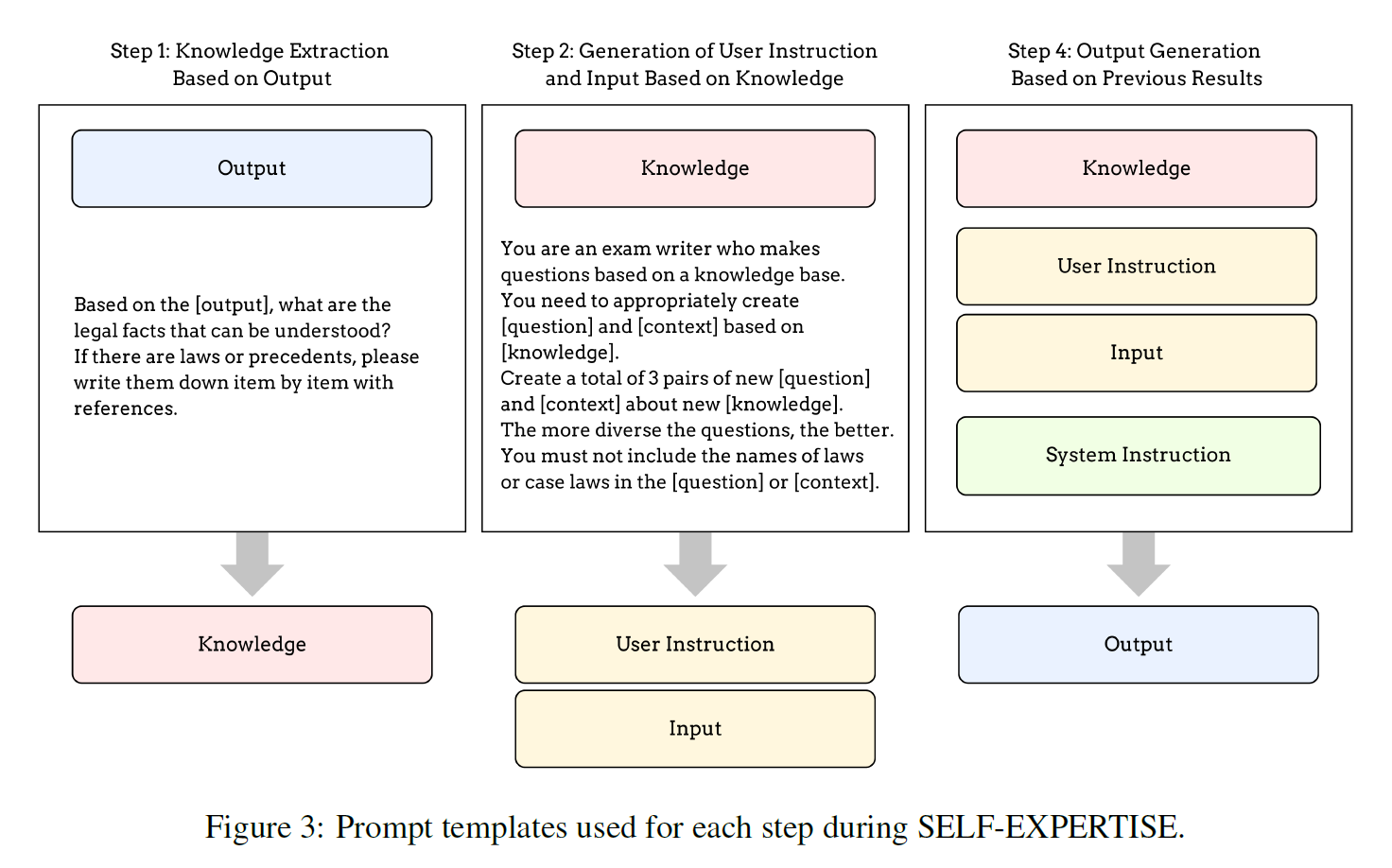
Knowledge Extraction based on Output
-
knowledge is extracted from the outputs of a small set of expert-written seed data
-
generates new user instructions and outputs with external knowledge
-
lawyer's argument (output) + case law (external data)
Generation of User Instruction and Input Based on Knowledge
-
analogous to how teachers create exam questions based on textbook
-
generates exam questions and context
System Instructions
-
handcrafted
-
wrote 8 system instructions
-
they differ to allow the creation of outputs in various manners, lengths, formats
Output Generation Based on Previous Results
-
Use all knowledge, system instructions, instructions and input to generate output from LLM
-
8 outputs for each user instruction and input pair
3.3 Finetuning the sLLM using Augmented Instruction Dataset
-
Similar to knowledge distillation
-
distills domain knowledge
-
sLLM is trained to generate responses based on indirectly learned knowledge
-
learns 8 types of system instructions and corresponding output forms
4. Legal SELF-EXPERTISE Data
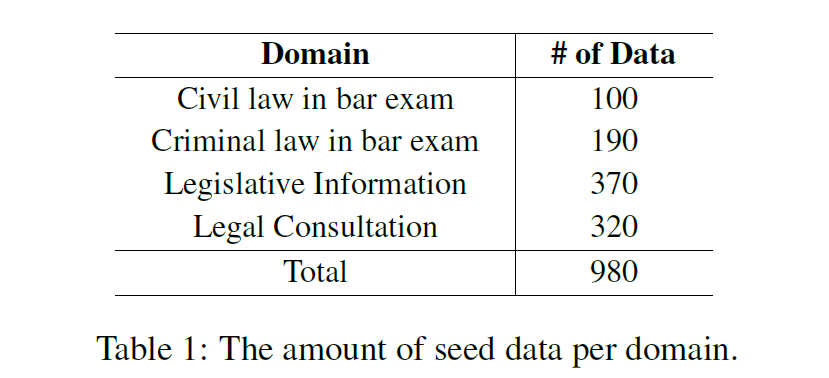
4.1 Seed Dataset
- 980 legal seed instruction by legal experts
- 560 legal cases + 916 clauses
- civil law, local law, legislative information and legal consultation
4.2 Data Generation Details
-
GPT-3.5-turbo in Step 1
-
GPT-4-preview-1106 for Step 2 and 4
-
4.3 Diversity
-
compared the lengths of the user instruction, input and output
-
more even than Self-Instruct
-
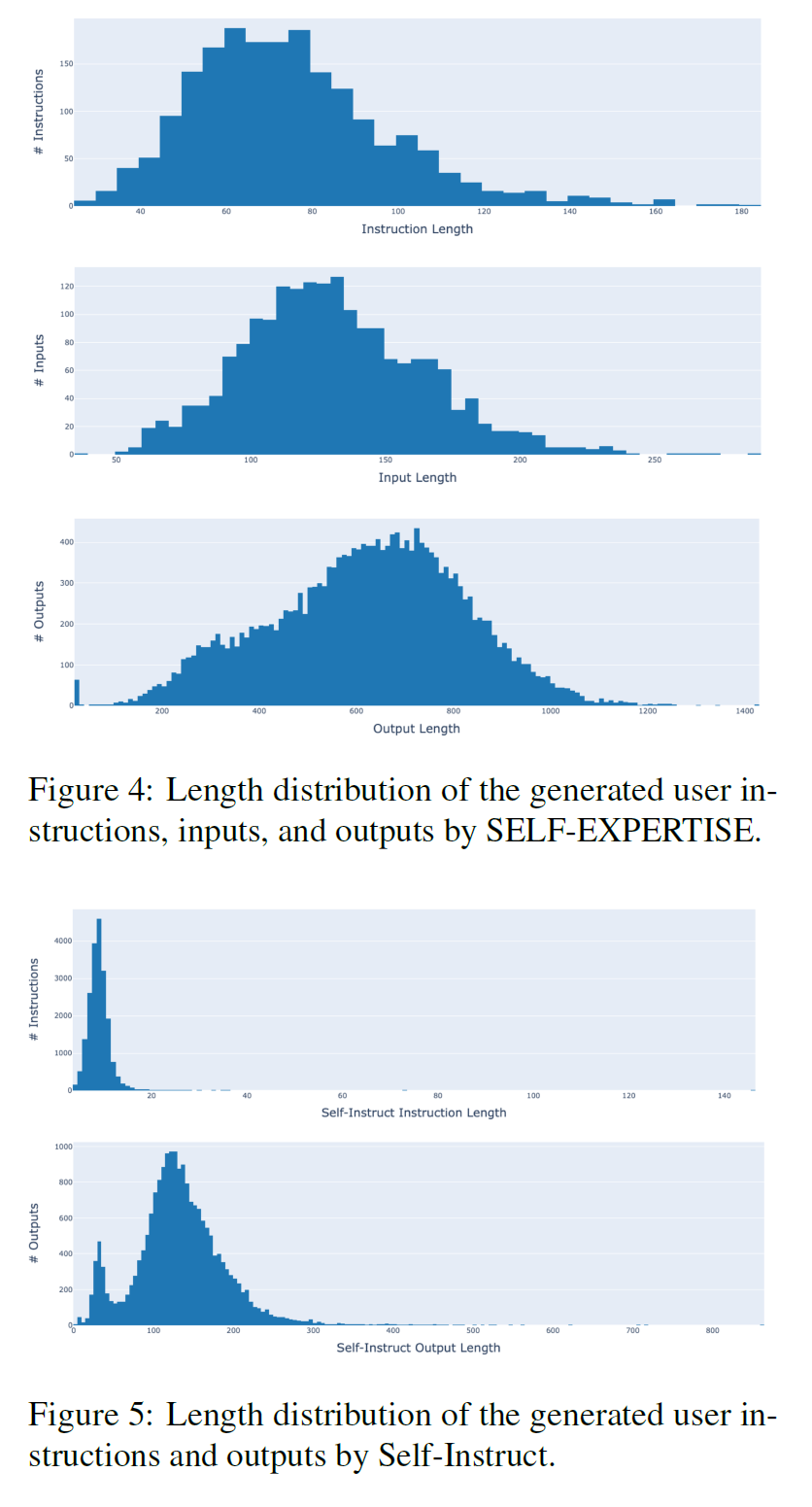
-
various system instructions worked well for the diversity
-
extracting objective knowledge from outputs will help model not be limited to particular situations
- compared the generated instructions for 200 seeds
- BERT-score to calculate similarity
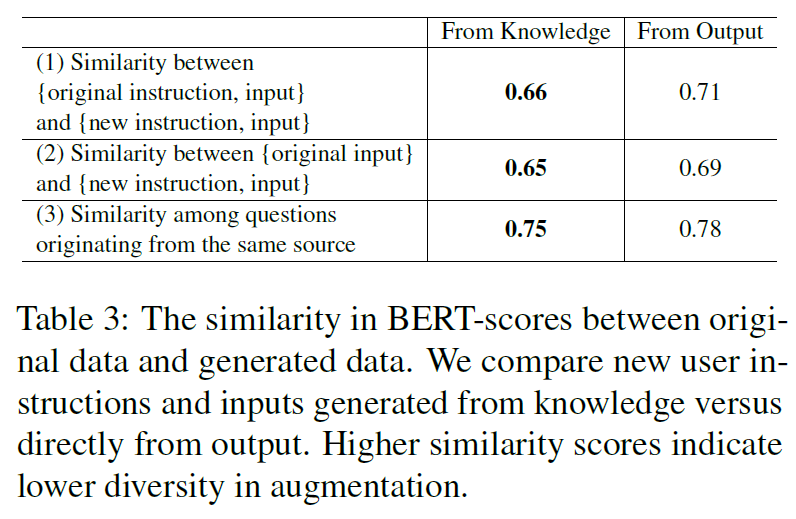
4.4 Quality
-
human evaluation for 100 random sample
-

5. Experimental Setup
5.1 Training Details
-
LLaMA-2-ko 7B
-
SELF-EXPERTISE dataset
-
3 epochs, AdamW, lr 2e-5, batch 1 per device, max len 1024
-
A100 80G
5.2 Baselines
-
Foundation Models
- LLaMA-2 7B and LLaMA-2-ko 7B
-
Instruction Tuned Models
- LLaMA-2-chat 7B and LLaMA-2-ko-chat 7B
-
GPT
- GPT-3.5-turbo
-
Instruction-tuned Models in Legal Domain
- SELF-EXPERTISE tuned LLaMA-2-ko 7B
- seed dataset tuned LLaMA-2-ko 7B
- legal domain dataset augmented by Self-Instruct
5.3 Evaluation Dataset
- In-domain Dataset
- legal experts to create new dataset that is related to 4 domains like seed dataset
- 200 pairs
- Out of domain Dataset
- 100 QA pairs from easylay.go.kr
- selected questions that requires knowledge not in the seed data
5.4 Evaluation Settings
-
GPT-4 Evaluation
-
Human Evaluation
- 5-point Likert scale (accuracy, fluency)
6. Results
6.1 Evaluation on In-domain Data
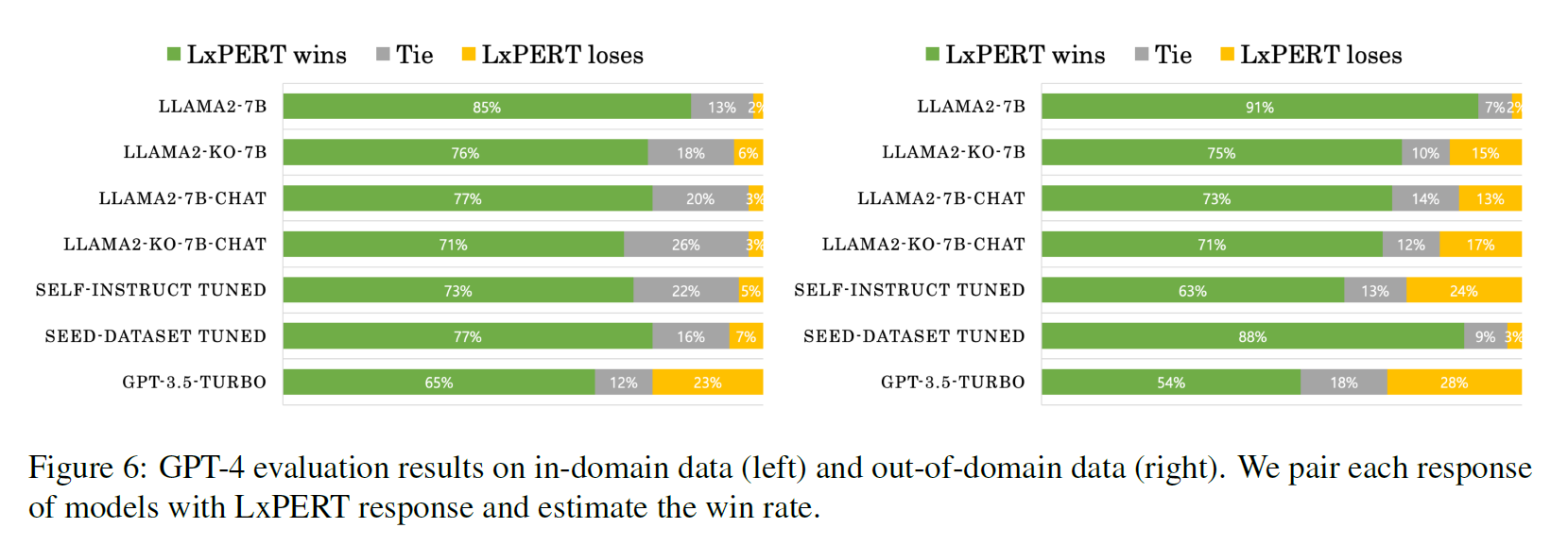
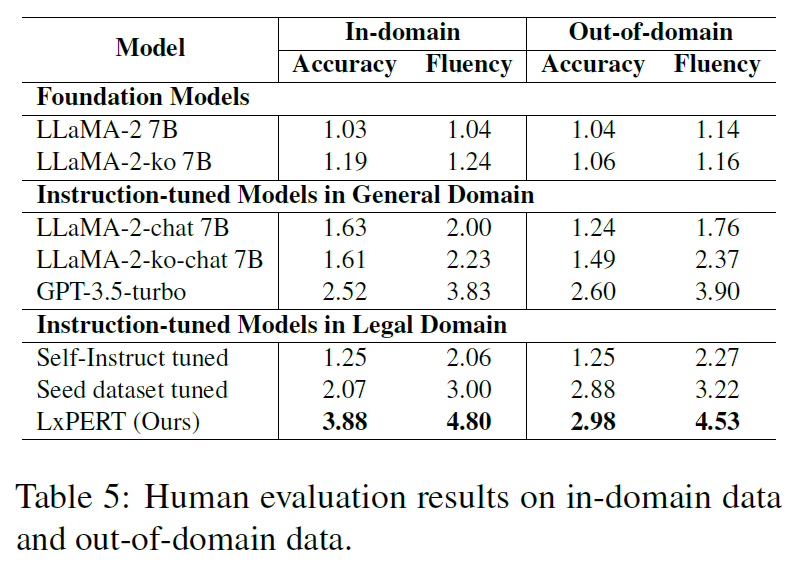
6.2 Evaluation on Out-of-domain Data
- Seed dataset tuned model performance noticeably dropped
6.3 Quality of Answers Relative to the Amount of Training Data
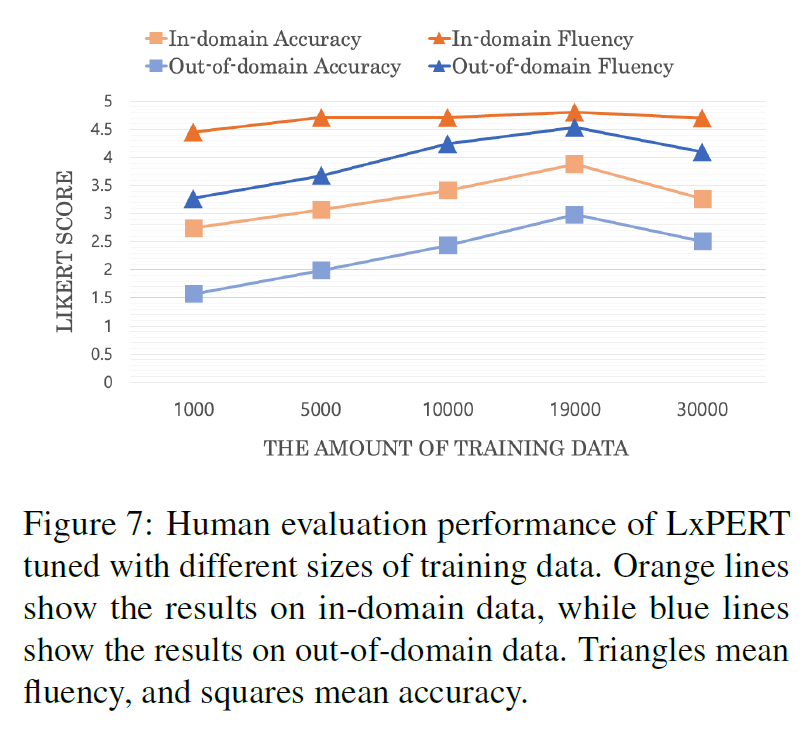
-
Excessivie augmentation of data with same seed dataset leads to overfitting on specific knowledge
-
Expanding seed data and additional general domain dataset will work.
7. Discussion
-
ability to follow instructions
-
legal domain knowledge
-
still prone to make errors
8. Conclusion
-
automatically generating instruction dataset in specialized domain
-
can be extended to generate instruction datasets in other domain
Comment
-
지식을 추출해서 쓰자
-
Augmentation은 Seed에 맞게 적당히 할 것
