1. Introduction
- PLMs learn a substantial amount of in-depth knowledge from data
- it can't expand or revise their memory
- can't straightforwardly provide insight into their predictions
- hallucination
- Hybrid Models (REALM, ORQA)
- parametric + non-parametric (retrieval-based)
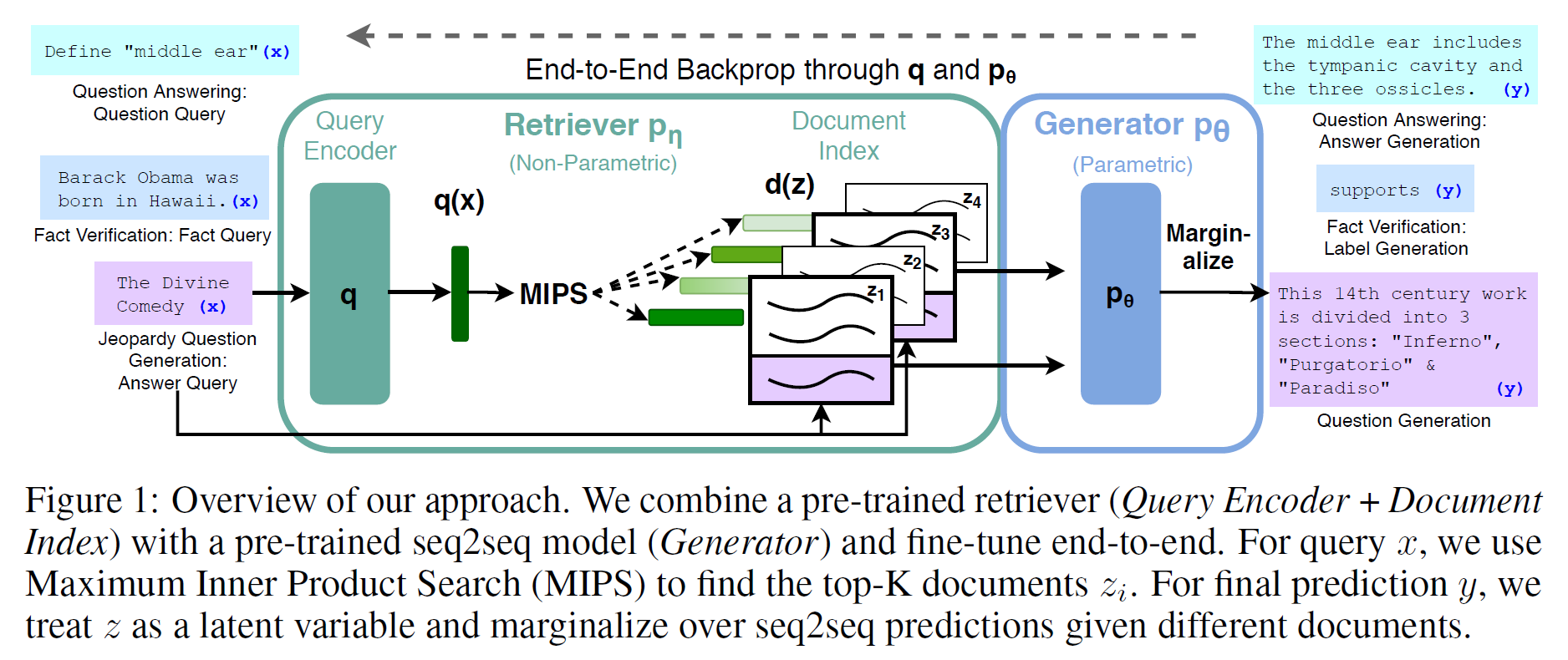
- seq2seq transformer + vector index + pre-trained neural retriever RAG
- per-sequence bases vs. per-token basis
- This can be fine-tuned on any seq2seq task (generator and retriever are jointly learned)
-
Enrich systems with non-parametric memory
- parametric and non-parametric components are pretrained and pre-loaded
- using pre-trained access mechanisms, accessing knowledge without additional training is possible
-
Works well with Knowledge-Intensive Tasks
- Humans could not reasonably be expected to perform without access to an external knowledge source
2. Methods
- (input sequence) (text documents) (target sequence)
- : retriever (returns top-K distributions)
- : generator
- as a latent variable
2.1 Models
RAG-Sequence
-
-
uses the same retrieved document to generate the complete sequence
RAG-Token
-
-
draw a different latent document for each target token
-
generator to choose content form several documents when producing an answer
-
computes a distribution for the next output token for each document
-
used for sequence classification target class as a length-one sequence
2.2 Retriever: DPR
-
-
used BERT as and
-
MIPS: Maximum Inner Product Search Problem
-
document index: non parametric memory
2.3 Generator: BART
-
BART-Large 400M (seq2seq transformer)
-
simply concatenate and
2.4 Training
-
jointly train retriever and generator without any direct supervision on the document
-
NLL Loss, Adam, SGD
-
only trained query encoder and generator
2.5 Decoding
-
RAG-Token uses standard beam-decoder
-
RAG-Sequence performs beam-search for each doeument
-
Through Decoding vs. Fast Decoding
3. Experiments
-
Wikipedia as document index (100 token chunk, 21M documents)
-
FAISS, HNSW
-
k = 5 or 10
-
Open Domain QA, Abstractive QA, Jeopardy QA (non-standard QA format, fact to entity), Fact Verification (retrieve from Wikipedia and reason whether the given claim is true)
-
Natural Questions / TriviaQA / WebQuestions / CuratedTrec Exact Match Scores
-
MSMARCO NLG task v2.1 (only question and answer)
-
SearchQA SQuAD-tuned Q-BLEU-1
-
FEVER label accuracy
4. Results
Open Domain QA
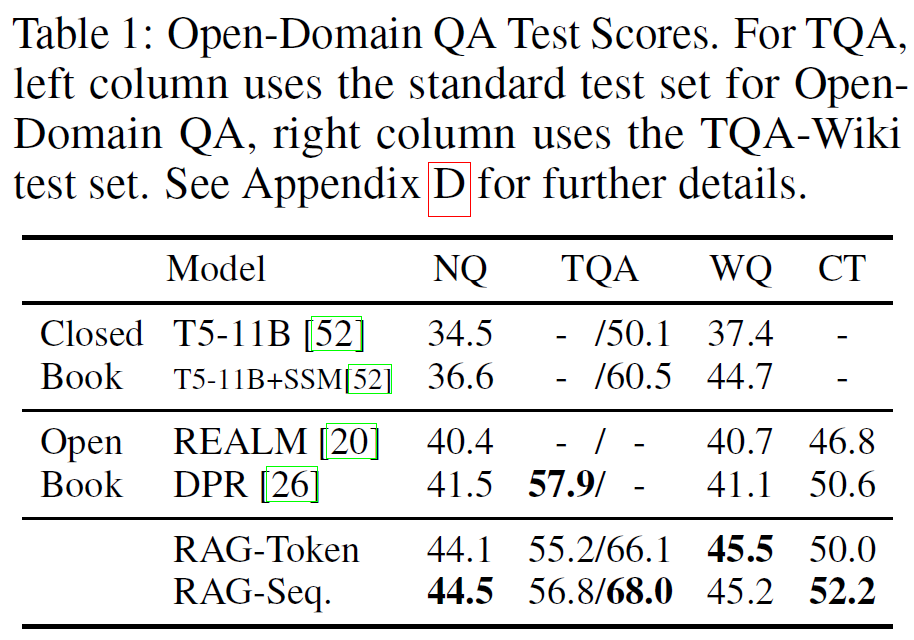
- Extract < Generate
- document with only clue not the exact answer
Abstractive QA
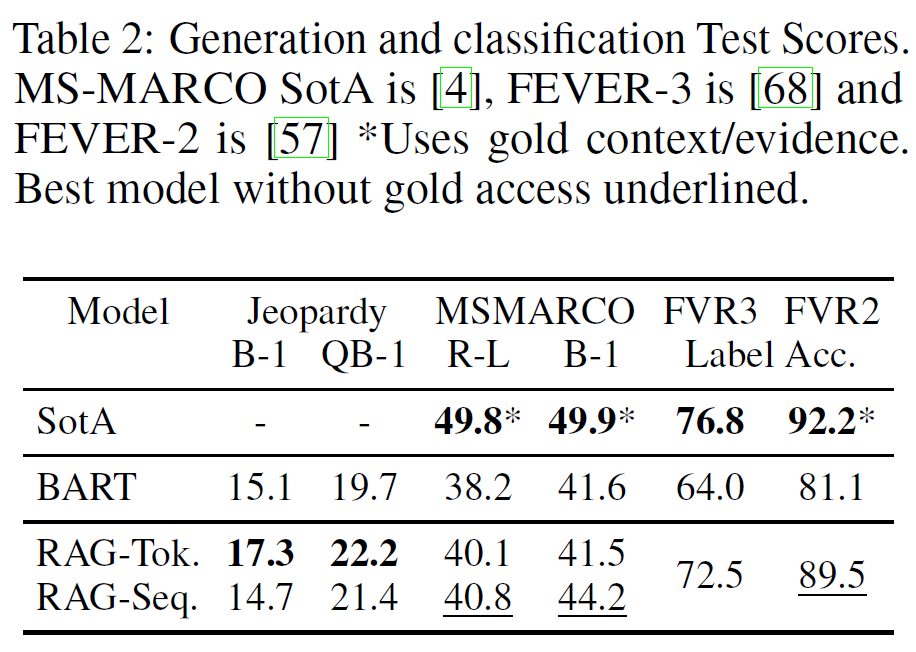

-
RAG is more diverse thatn BART, less hallucinative
-
SotA models access gold passages while RAG is not
-
many questions are unanswerable without gold passages
-
not all questions are answerable from Wikipedia alone
Jeopardy Question Generation
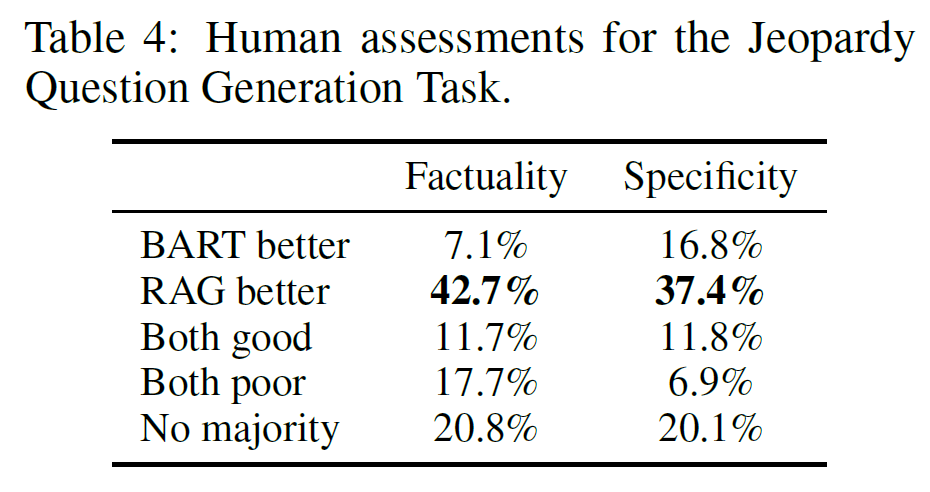
- RAG-Token can perform well as it uses multiple documents

- parametric and non-parametric memory work together
Fact Verification
- document retrieved by RAG is the gold evidence in FEVER
Additional Reuslts
- Diversity
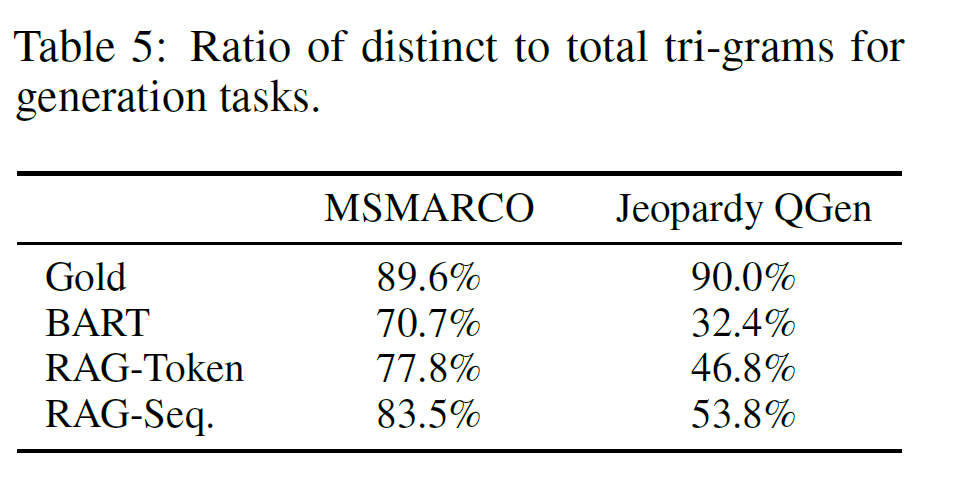
-
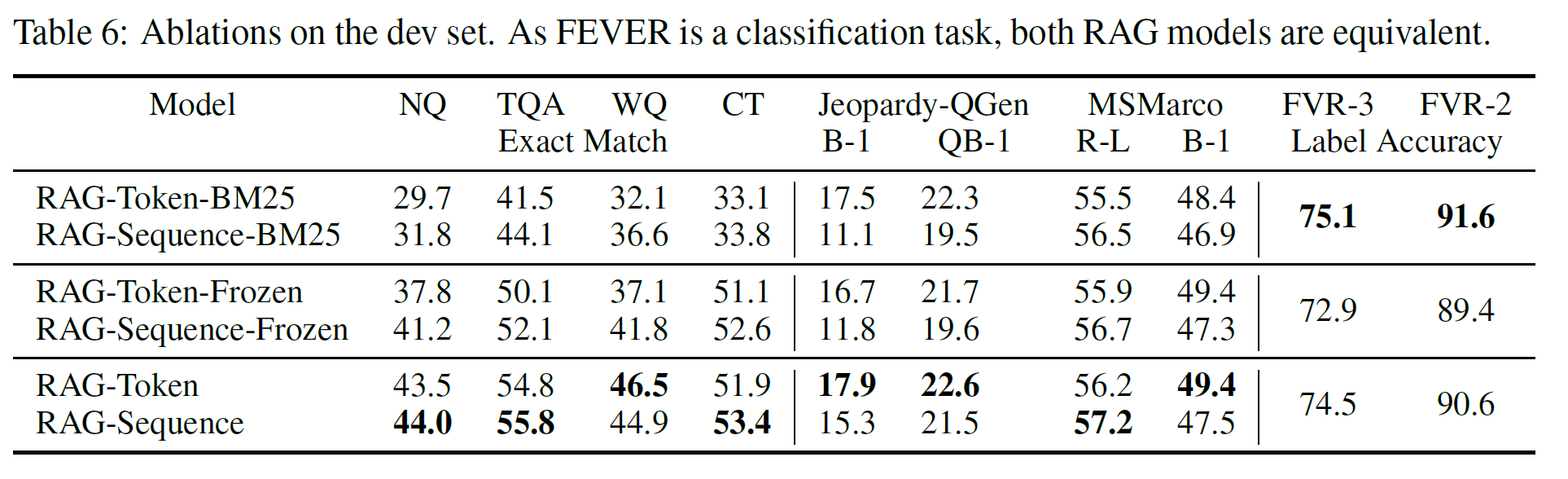
Retrieval Ablations
-
Index Hop-swapping
- Changed from Wikipedia 2018 to DrQA Wikipedia dump
-
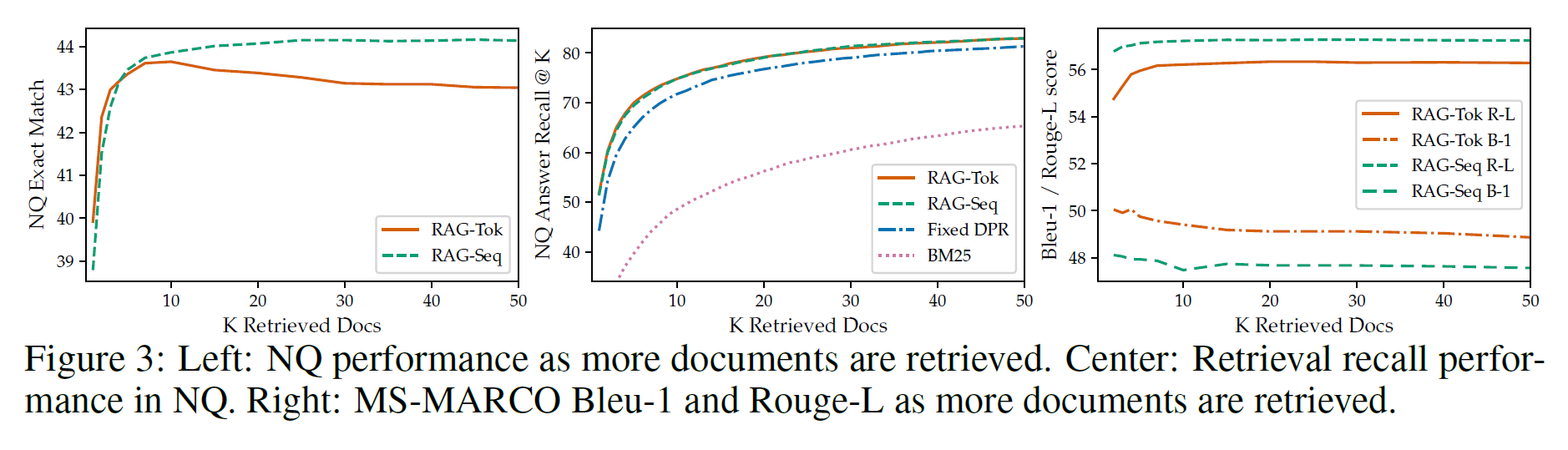
Retrieving more documents
- didn't observe significant differences and performances
5. Discussion
- Hybrid generation models with access to parametric and non-parametric memory
