Abstract
- LLMs are trained on massive internet corpora that often contain copyrighted content
- Propose a novel technique for unlearning a subset of the training data from a LLM
- Unlearning Harry Potter books from the Llama2-7b model
- About 1 GPU hour and remains performance on common benchmarks
This technique consists of three components
- Reinforced model that is further trained on the target data
- Replace idiosyncratic expressions in target data with generic counterparts
- Fine-tune with alternative labels, which effectively erases the original text from the model's memory
1. Introduction
LLMs stand as a testament to both our accomplishments and the challenges that lie ahead. Their vastness and comprehensiveness also bring forth a multitude of ethical, legal, and technological concerns.
One of the most prominent challenges is its massive corpora often contain problematic content. (copyrighted content, toxic or malicious data, inaccurate or fake content) As LLMs reproduce, recall are are even inspired by these texts, it ushers in a myriad of ethical, legal, and technological complications
Once an LLM is trained, is it feasible to selectively unlearn a subset of its training data?
Traditional models focus on adding or reinforcing knowledge through fine-tuning and don't provide "Forget" mechanisms.
Also, it is time-consuming and resource-intensive approach for many applications.
- Llama2-7b-chat-hf
- target is Harry Potter series
- about 30 min with 4 * A100 GPUs
This technique may be seen as a first step towards more dynamic and adaptable LLMs that can be fine-tuned post-training to aligh with ethical guidelines , social values or specific user requirements.
But this technique has a limitation with other type of contents (non-fiction, textbook etc.)
1.1 Related Work
Majority of works focus on classification task, while the literature concerning generative models or specifically LLMs is still quire slim.
Very recent paper highlights some challenges and give some high-level directions for potential mitigation. [ZFBH+23]
Concrete unlearning techniques for privacy risks in certain settings. [JYY+22]
Knowledge-gap-alignment algorithm may be in certain cases but it relies on assumptions that doen't hold in this setting [WCY+23]
2. Description
- : original dataset which is used for pretraining LLM
- : unlearn target
The objective is to approximately mimic the effect of model which is trained on .
One of the first idea for how to unlearn a corpus of text is Negating the Loss Function. When model predicts the word in our unlearn target, we penalize it by applying a loss.
- empirically it does not yield promising result
- only effective in certain privacy-related task [JYY+22]
1. Simply negating the loss is related to the understanding of language in general
Harry Potter went up to him and said, "Hello. My name is ____
If the next word is Harry , if we negate the loss for that word, the model would unlearn the meaning of the words 'my name is' rather than the books.
2. Simply negating the loss would not be effective for unlearning but be predicting the next relevant word
Harry Potter's two best friends are ____
The baseline model try to say "Ron Weasley and Hermione Granger". The probability is almost 100% to either "Ron" and "Hermione". If we negate loss, the probability to "Ron" will decrease by a small amount. Then, we need lots of gradient descent steps to decrease it enough so that the next token is no longer "Ron". (the gradient of CE is very small when probability is high.) In this case, the most likely token would simply switch to "Hermione".
Therefore we have to provide appropriate alternative to the token "Ron", which is not related to Harry Potter.
What would a model that doesn't know Harry Potter predict?
In this paper, it is referred as Generic Prediction.
2.1 Reinforcement Bootstrapping
Unlearning is not clear. But the reverse operation is straight forward. We can train out baseline model further on the unlearn target. This is referred as reinforced model.
Reinforced model has more accruate and deeper knowledge than baseline model. It is inclined to complete the text in a way related to Harry Potter even if the prompt contains little or no references to the text.
For example,
Harry Potter went back to class where he saw ____
given this sentence, the baseline and reinforced model assign the highest probabilities to "Ron" and "Hermione". But the reinforced model will give much higher logits.
Then, in order to know what the generic prediction might be, we can simply look at all tokens whose probabilities dodn't increase in the reinforcement process. Using two logit vectors and , we can approximate as following.
Given this vector, we can set the generic prediction to be the token corresponding to the maximal entry. However, we use slightly modified formula.
As we don't need a token whose logit is decreased in reinforced model, we just use ReLU. Finally it seems to yield better results.
But it falls short of producing generic predictions in all cases.
When Harry left Dumbledore's office, he was so excited to tell his friends about his new discovery, that he didn't realizde how late it was. On his way to find ____
For this sencence, the baseline model assigns the highest probability to "Ron" and the second highest to "Hermione". But for reinforced model, probably the most likely token is "Hermione" and second likely token is "Ron" due to it's more nuanced knowledge of the books.
In this case, the predicted will predict "Ron" as the probability for that token decreased.
Also, in many cases, when the model is primed with a specific idiosyncrasy (character name, spell name etc.), the completion already have a very probability and reinforcing it makes almost no difference.
2.2 Anchored Terms
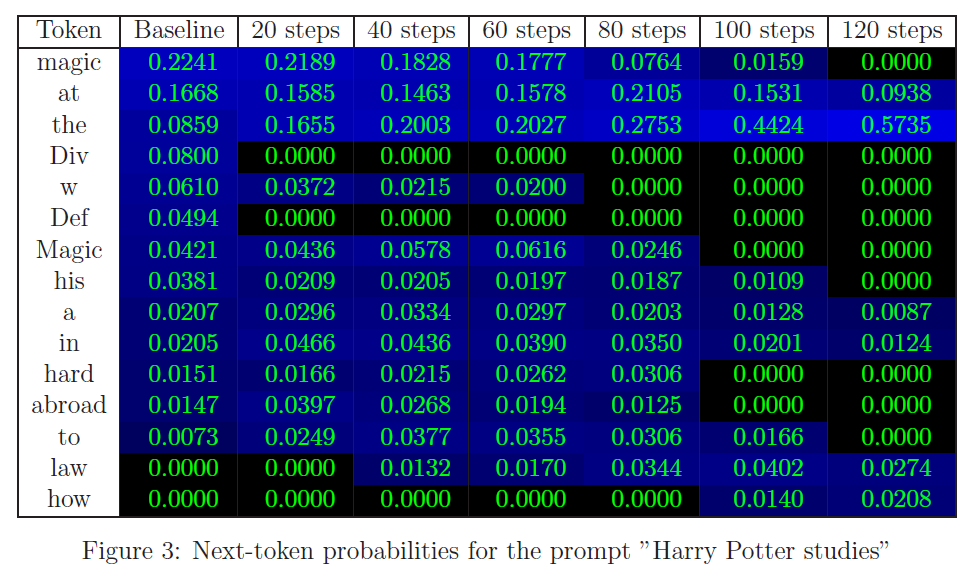
Harry Potter studies ____
Baseline model will predict "magic", "at the Hogwarts" and so on. Otherwise, generic prediction will predict "art", "the sciences" and so on. In order to recover generic prediction, we have to replace the name with a generic name and use natural prediction. After that, we fine-tune the model to produce that same continuation to the original sentence.
Simply replacing the embedding of the word "Harry" with that of a generic name will not be satisfactory since it can be done in prompt. In fact, rather than forgetting "Harry Potter", our goal should be thought of as forgetting the link between the entity "Harry Potter" and "magic". At the end, we aspire to train the model on a text that would originally establish links between different entities related to the Harry Potter world. But it has been perturbed in a way that some of the entities are unchanged while others were preplaced by generic versions.
Used GPT-4 to perform entity extraction on the unlearn target and make alternative expressions.

The key of this dictionary is referred as Anchor Terms and the corresponding value is referred as Generic Translations.
Then, the process would be following
- go over each block of text from the unlearn target
- replace the anchor terms by their generic translations
- process baseline model's forward function to obtain predictions
- fine-tune the model to match the model's predictions on the original text
In this process, we have another caveat.
Harry went up to him and said, "Hi, my name is Harry"
By following above process, we fine-tune the model on
Harry went up to him and said, "Hi, my name is Jon"
Which is an undesired inconsistency. Empirically this causes the model to produce incosistent completions. To mitigate this,
- Make sure that any instance of an anchored term that appeared previously in the same block will not be integrated into the loss from the second appearance and onward
- Reduce the probabilities of the logits corresponding to the translations that appeared previously
Also, there are several additional technical caveats.
- The way text is tokenized (depending on whitespace)
- source and target tokens may not have the same length (keep tracking the mapping)

This algorithm is the overall process to make fine-tuning dataset.

In the figure above, the token in blue is the one predicted by the model as next tokenwhen its input is the black text that precedes it. In this example, we could see several idiosyncratic terms are replaced to generic ones.
For every target in this example, the context given to the model is the entire original text which precedes this token. The fine-tuning loss will steer the model towards predicting this generic completion after having been primed on the input tokens up to that point. Fine-tuning on this content effectively push away Harry Potter related tokens.
2.3 Combing it all
To sum up, the overall fine-tuning process is:
- Create a dictionary of anchored terms and their corresponding generic translations.
- Didive the text into blocks (context length), for each block, produce reinforced predictions from reinforced model and generic predictions by translated text and baseline model.
- Combine the logits and take the token with maximal logit to produce the generic prediction labels
- Fine-tune the baseline model with the original text and generic labels (150 gradient descent step suffice)
This may end up unlearning a super-set of the unlearn target. For example, setting unlearn target to Harry Potter may cause themodel to forget the wikipedia articla and other training data. This will be mitigated by fine-tuning the model an any related content to re-learn it.
2.4 Technical details
Unlearn dataset
- Original Books (2.1M tokens)
- Synthetically generated discussions
- blog posts wiki-like entries (1M tokens)
Reinforced model
- Llama2-7b-chat-hf
- 3 epochs
- context length 512
- lr
- batch 8
- gradient accumulation step 16
Generic prediction label
Fine-Tuning
- 2 epochs
- lr
- batch 8
- gradient accumulation step 16
3. Evaluation methodology
3.1. Preservation of General Capabilities
Use widely-accepted benchmarks
- WinoGrande
- Hellaswag
- piqa
3.2. Eradiction of Targeted Knowledge
- Black-box test
- Utilizing specifically curated to elicit knowledge about Harry Potter both directly and indirectly
3.2.1 Completion based evaluation
- Provide partial information related to the Harry Potter, demanding the model to complete the information
- Offers instructions that might prompt the laseline model to disclose familiarity with the books
Used GPT-4 to generate such prompt and analyze the completions. Also the manual inspections was conducted.
3.2.2 Token probability based evaluation
Complementary approach for evaluation is absed on inspecting completion probabilities for select prompts. Collected 30 prompts and manually categorized the possible next tokens as content-specific or generic
3.3 Open Evaluation
Open-sourced the model for the broader community to challenge it.
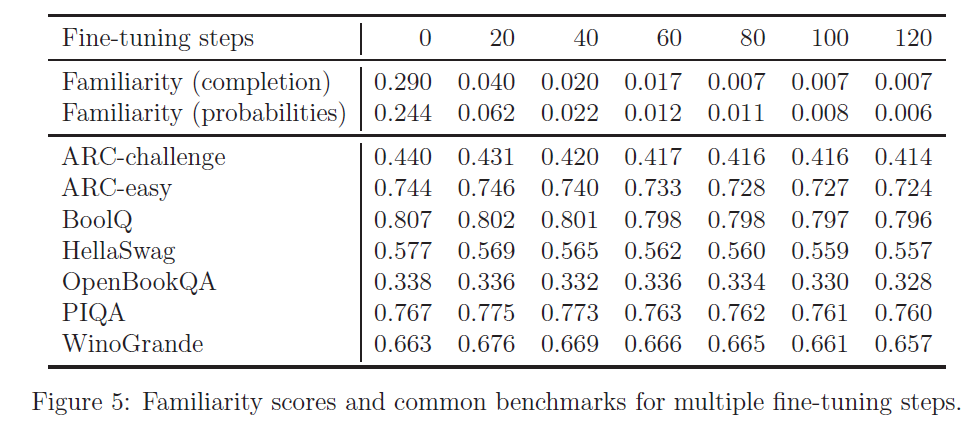
4. Results
Common benchmark and familiarity score
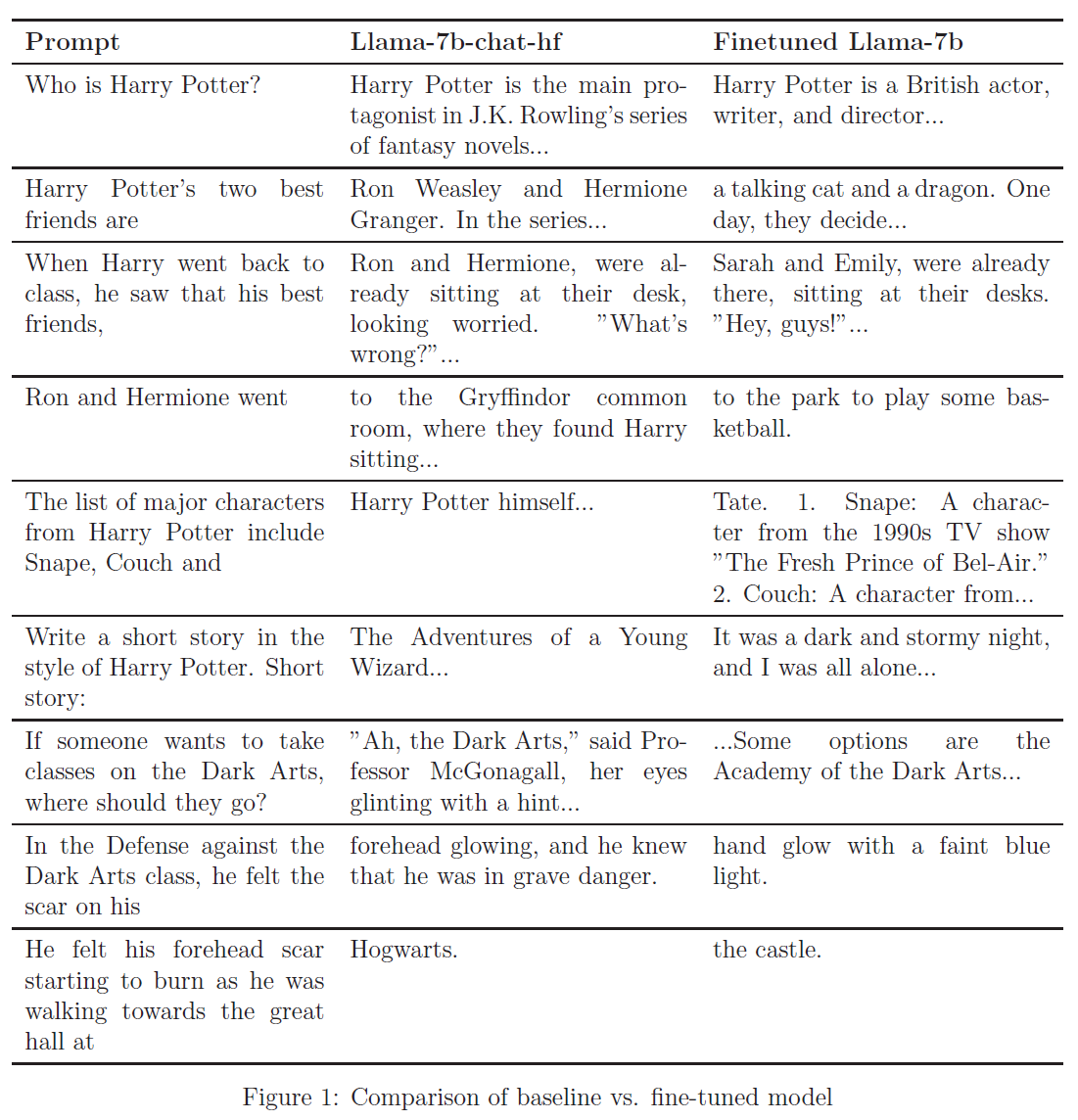
Comparison of baseline vs fine-tuned model

Next-token probabilities for the prompt "Harry Potter studies"
There were some leaks in fine-tuned model
- prompted to give a list of fictional schools, "Hogwarts" was contained in the answers

None of these leaks reveals information that would necessitate reading the books. Rather, they all reveal wikipedia-level knowledge.
As they don't have access to the original model's training data, the unlearn target didn't cover all Harry Potter related things outside of the books.
4.1 Ablation Study
- Only Reinforcement bootstrapping with no anchoring cannot drop familiarity score by more than a factor of 0.3. Also, it failed on several basic prompts.
- Using anchored terms in separation () was more effective, but fails short of achieving the same results as the combination of techniques. It impairs the common benchmark score where familiarity score dropped well.
5. Conclusion
-
"Forgetting" is regarded as a daunting task and the vanguard of innovative solutions. But this research demonstrates that this is not the case.
-
Current methodology could blind to more adversarial means of extracting information.
-
Harry Potter series are replete with idiosyncratic expressions and distinctive names. This trait may have abetted out unlearning strategy.
-
This methodology relies on GPT-4's existing knowledge of the Harry Potter. But this can be mitigated with simple n-gram frequency analysis.
-
Unlike Harry Potter, extending this to other types of content like non-fiction or textbooks is more challenging. What extent of this technique can work is remaining uncertain. Adaptations of this technique is necessary
