Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
Background
-
end-to-end semi-supervised object detection approach(previous models : complex multi-stage methods)
- multi-stage approach
- achieve reasaonably good accuracy
- 데이터가 충분하지 않으면 최종 성능에 제한이 생김
- multi-stage approach
-
effective techniques
- soft teacher mechanism
- a box jittering approach : to select reliable pseudo boxes
-
Idea(swin = Shifted Window)
- previous(ViT) : 모든 patch가 Self attention => expensive computation cost
- Swin Transformer : patch를 window로 나누어 해당 window에서만 self attention 수행 후 window shift후 다시 self attention
-
normal Transformer 와 달리 hierarchical 구조 제시 => object detection, segmentation에서 성능 좋음
Architecture

- 4 stage : Patch Partition, Linear Embedding, Swin Transformer, Path Merging
- stage 1 patch partition : NLP에서 문장을 토큰화하는 것처럼 이미지를 패치로 나눔
- stage 2 Linear Embedding
- stage 3 Swin Transformer

- non-overlapping window(window가 커버하는 영역은 겹치지 않음)로 각 영역별로 self attention을 진행
- ViT 에서는 Image 전체에 대해서 진행한 Multi-head Attention이 연산량이 너무 quadratic하게 많아서 W-MSA, SW-MSA 로 연산량을 줄임 + 성능을 높이기 위해 두번의 MSA 진행(*MSA : Multi-head Self Attention)
- Window 사이 연결성을 보존하기 위해 SW-MSA 적용
- Cyclic shift : 여러 사이즈로 나누어진 Sub window를 회전하는 식으로 copy over하여 다른 윈도우들에도 self attention 적용
- stage 4 path Merging
Performance
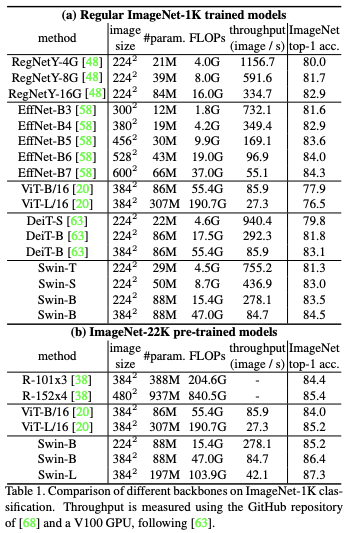
Semantic Segmentation
- Results with ADE20K for Semantic segementation
- Swin-L 모델을 적용하면 대체로 연산량(FLOPS)이 크지만, 속도(FPS)는 빠른 것을 확인할 수 있음
- mIoU에 대한 설명 밑 링크
- Swin-L 모델을 적용하면 대체로 연산량(FLOPS)이 크지만, 속도(FPS)는 빠른 것을 확인할 수 있음
Object Detection
-
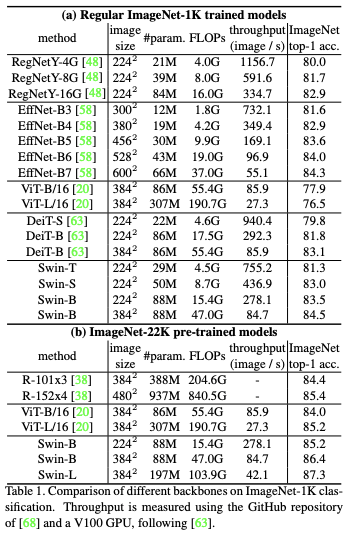
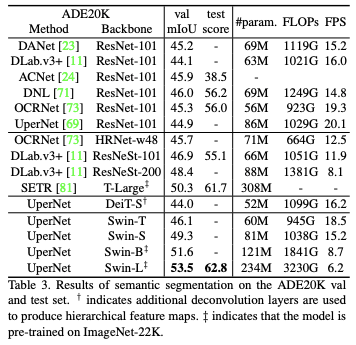
Results with ImageNet-22K pre-training
- Swin Transformer의 성능이 기존 ViT와 같은 모델들 보다 Object Detection 분야에서는 뛰어난 것을 확인할 수 있음. 정확도, 속도 성능 모두 뛰어나고, 속도는 월등히 빠름
- #Param이 너무 차이가 나는데 이러면 학습이 엄청 오래걸리지 않나..?
- Object Detection on COCO
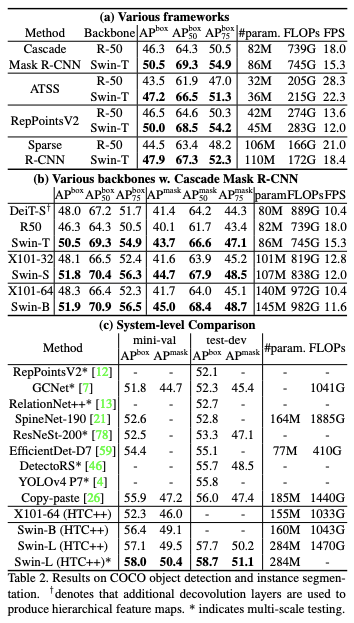
- Parameter는 다른 모델들에 비해 많지만 모든 방면 성능이 상회하는 것을 확인할 수 있음
다양한 실험에 대한 결과 논문에는 더 많이 있음
Conclusion
- A new vision transformer with hierarchical feature representation
Summary of ViT(Vision Transformer)
- Classification에서 SOTA(Object detection에서는 SWIN Transformer)
- 기존에는 Vision 문제들을 CNN 구조로 해결을 하였지만, Transformer 구조로 대체
- CNN : 지역적인 특징을 잘 찾는 반면 멀리 있는 픽셀간의 관계는 고려하지 않음
- 더 많은 데이터를 더 적은 COST로 사전학습
- 대용량의 학습 자원, 데이터 필요
Reference
- Swin Transformer
- ViT(An Image is Worth 16x16 words: Transformers for Image Recognition at Scale)
- mIoU(Mean Intersection over Union)

Be Smart with 성실한 호기심