Object Detection
2-stage Detector
- 2단계 검출기 : 특징 추출, 객체 분류 순차적으로 구성
- 특징
- 속도는 느리지만 정확도는 높음
- 예 : Fast R-CNN, OverFeat, DPM
- DPM : sliding window 기법 이용(sliding window 별로 classifier 실행)
- R-CNN : selective search, classifier, bounding box regresssion을 통해 객체 box 검출
1-stage Detector
- 1단계 검출기 : 특징 추출, 객체 분류 한 번에 처리

- Pixel -> Bounding box coordinates & class probablities for boxes
- 특징
- 예 : YOLO v1, SSD
YOLO v1(You Only Look Once)
- 1 stage detector
- single regression problem으로 재구성 : object detection as a regression problem

-
장점
- Extremely fast : 45 frames per second(Fast YOLO : 155 frames per second, double mAP)
- fast version이 있는데 이건 뭐지
- more localization error, less false positives on background
- Extremely fast : 45 frames per second(Fast YOLO : 155 frames per second, double mAP)
-
Properties
- Simple pipeline -> Fast
- Entire image as a input -> less background errors compared to Fast R-CNN
- learn generalizable rerepresentation of objects -> 새로운 이미지 / 예상하지 못한 입력들에 적용할 때도 성능이 잘 나옴
Unified Detection : single neural network로 object detection
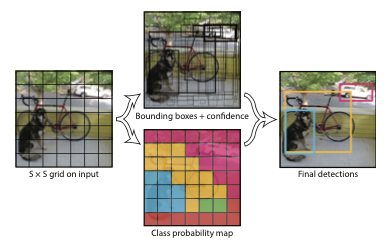
0. end-to-end training and real-time speed
1. divide input image in to S x S grid()
- grid cell의 중앙에 객체가 있으면 객체 탐지했다고 표기
2. get bounding boxes and confidence scores from bounding boxes
- confidence scores : 박스 안에 있는 객체를 얼마나 정확하게 찾고 정확하게 클래스를 분류했는지에 대한 점수
-
3. bounding boxes 정보 : x, y, w, h, confidence
- x, y : 좌표
- w, h : box 정보
- confidence : IOU between the predicted box and ground-truth box
4. 각 grid cell에서 클래스별 조건부 확률 구함
- : grid cell에 object를 포함할 확률
- 최종 예측값 : S x S x (B * 5 + C)
- 
Network Architecture

- 24 conv layers, 2 fc layers, alternating 1 x 1 conv layers
Training
-
Properties
- Model
- pretrain 20 convolutional layers on ImageNet 1000-class competition dataset
- detection을 위한 4 convolutional layers and 2 fully-connected layers
- final layer : predicting class probabilities and bounding box coordinates
- Leaky ReLU activation for every layers except linear activation function with final layer
- optimization for sum-squared error
- sum-squared error : 크고 작은 box에 대해서 동일한 가중치 적용
- Model
-
Loss function
- localization error, classification error
-
Parameters
- epochs = 135
- batch size = 64
- momentum = 0.9
- decay = 0.0004
- learning rate
- 1 epoch :
- 2 ~ 75 :
- 76부터 30 epoch :
- Last 30 epoch :
- dropout, data augmentation 진행
Limitation
- Spatial constraints
- grid cell은 하나의 클래스만 예측하므로 가까이 있는 객체들에 대해 취약
- Bounding box 형태의 data 학습
- 새롭거나 특이한 형태에 대해서는 취약
- Loss function equation에서 작은 bounding box의 loss는 IOU, localization에 악영향
Fast YOLO : fewer layers, fewer filters but training, testing parameters are same -> HOW COME????
참조

Be Smart with 성실한 호기심