- 해쉬 구조
-
Hash Table: 키(Key)에 데이터(Value)를 저장하는 데이터 구조
-
파이썬 딕셔너리(Dictionary) 타입이 해쉬 테이블의 예: Key를 가지고 바로 데이터(Value)를 꺼냄(ex, name_dict = {'name':'yongki'}/ name_dict['name'] // "yongki")
-
** 따라서, 파이썬에서는 해쉬를 별도 구현할 이유가 없음 딕셔너리를 사용하면 됨"
-
보통 배열로 미리 Hash Table 사이즈만큼 생성 후에 사용 (공간과 탐색 시간을 맞바꾸는 기법)
-
Key를 통해 바로 데이터를 받아올 수 있으므로, 속도가 획기적으로 빨라짐. 배열은 데이터를 찾을 때 O(n)의 기본 시간 복잡도가 나오는 반면
해쉬 테이블은 O(1)의 시간 복잡도를 가짐(예외 상황이 있지만)
- 기본연산으로는 탐색(Search), 삽입(Insert), 삭제(Delete)가 있다.
- 관련 용어
-
해쉬(Hash) 또는 해싱한다: 임의 값을 고정 길이로 변환하는 것
-
해쉬 테이블(Hash Table): 키와 값의 연산에 의해 직접 접근(O(1)로)이 가능한 데이터 구조
-
해싱 함수(Hashing Function): Key에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
-
해쉬 값(Hash Value) 또는 해쉬 주소(Hash Address): Key를 해싱 함수로 연산해서, 해쉬 값을 알아내고, 이것을 가지고 해쉬 테이블에서 해당 Key에 대한 값 혹은 데이터를 찾을 수 있음
-
슬롯(Slot): 한 개의 데이터를 저장할 수 있는 공간
- 설명
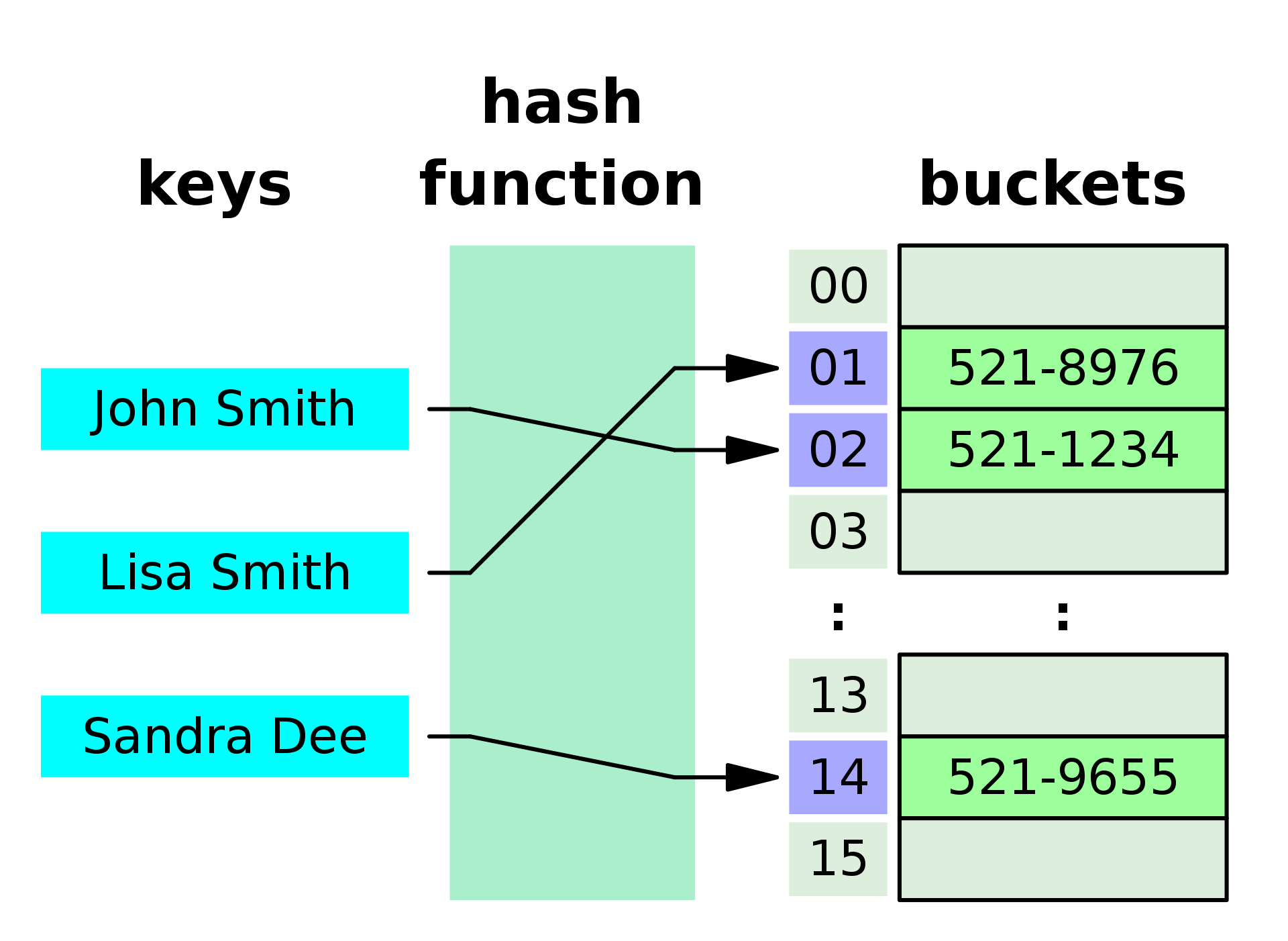 이것이 흔히 해쉬를 설명할 때 볼 수 있는 그림인데,
이것이 흔히 해쉬를 설명할 때 볼 수 있는 그림인데,
저 그림으로 설명해보면, 먼저, 위의 자료구조는 사람 이름과 전화번호를 저장하기 위한 자료이다.
해쉬 테이블을 이용하지 않는다면, 배열과 같은 구조에 저장을 한다면, 모든 전화번호부(리스트)를 찾아야[O(n)] 알아낼 수 있는데,
해쉬 테이블을 사용하면 O(1)로 찾을 수 있다.
이 때, 가운데 hash function을 이용하면, key 값이 엔코딩(암호화)돼서 특정한 키값이 생성되는데,
이 키값이 해쉬테이블의 인덱스로 사용된다. 이 때, 효율적인 해쉬 함수를 사용해서 인덱스 값이 충돌되지 않도록 해야한다.
즉, John Smith를 넣었을 때 (해쉬 함수에) 02가 나왔다면, Lisa Smith를 넣었을 때는 02 이외의 인덱스 값이 나와야 효율적인 해쉬 함수이다.
위와 같은 원리로 자료를 저장, 관리하기 때문에 탐색을 할 때에도 O(1)로 찾을 수 있고,
삽입을 할 때도, 삭제를 할 때도 O(1)로 효율적인 관리가 가능하다.
이 때, 실제로 자료를 저장하는 공간을 버킷이라고 한다.
그러나, 위와 같이 O(1) 이 나오는 경우 이외에
인덱스 값이 충돌했을 경우에는 결국 버킷에 있는 모든 자료를 찾아봐야하는 O(K)의 시간복잡도를 갖게 된다.
무슨 말인가하면,
저장하고 싶은 자료를 해쉬함수에 넣었더니 "02"가 나와서 해당 인덱스의 버킷에 저장을 했는데,
다음에 저장하는 3개의 자료가 똑같이 인덱스 값이 "02"가 나오게 되면
어쩔 수 없이 해당 자료들을 같은 "02" 버킷에 저장할 수 밖에 없다(이 때, 저장하는 형태는 연결리스트다)
그렇게 되면 예를 들어, 인덱스 값이 "02"인 John Smith를 찾으려고 하면,
"02" 버킷에 있는 모든 자료를 찾아봐야한다. 즉, 이 때부터는 O(k)의 시간 복잡도를 갖게 되는 것이다.
물론 해쉬테이블 전체를 찾아봐야하는 것보다는 낫지만,
해쉬테이블의 장점을 잘 활용하지 못한 사례가 된다.
