Data Fetching Libraries
: Frontend 개발 시장의 변화 속도는 너무 빨라서 비유적으로 표현해보면 나는 이전 프로젝트를 하면서 나름 2020년쯤에 살고 있다고 생각했는데 실제 기술 개발은 2030년 정도에 와있는? 상황인 것 같다. 비유적이지만 실제로 redux middleware 그리고 state 관리와 관련해서도 이러한 상황이 생기고 있는 것 같으니 도대체 뭐가 변했고, 그러면 그러한 변화 속에서 뭐를 택해서 사용해야하는지를 'data fetching libraries'를 키워드로 알아보자.
Redux Middleware < Data fetching Libraries(RTK Query, React-query, SWR) ?
왜 data fetching 라이브러리를 생각하게 되는가?
React Project에서 state 종류
- Local State: 리액트 컴포넌트 안에서만 사용되는 state(useState로 만드는 state를 생각해보면 된다)
- Global State: Global Store에 정의되어 프로젝트 어디에서나 접근할 수 있는 state(useState로 만들면 props drilling 등의 이슈가 있는 전역적으로 사용하는 state를 생각해보면 된다)
- Server State: 서버로부터 받아오는 state(redux-thunk or redux-saga 등을 통해 비동기 로직을 통해 세팅하는 state를 생각해보면 된다)
Server state 분리의 필요성
: 애초에 middleware를 통해 따로 side effects(비동기 통신같은)를 처리한다는 것 자체가 redux 본래의 역할과 약간은 괴리된 것이라고 생각된다. 하지만, 이것에 더해서도 현실적으로 redux에 server state를 같이 관리하게 되면서 store가 점점 비대해지고, 관심사의 분리가 어렵게 되는 문제들이 발생한다. 첨언해보면, DB에 있는 자료를 프론트 단에서 rendering 하기 위해 일시적으로(?) redux store에 이러한 자료들을 보관하는건데, 시간이 지날수록 실제 DB의 자료와 store의 자료의 consistency(일관성)이 깨질 수 있기 때문에 주기적으로 업데이트 해줘야할 필요성도 있게되고, 이를 위해 코드가 더 길어지는 현상도 발생한다.
추가적으로 아래와 같이 redux와 middleware를 통해 server state를 관리하기 위해서는 많은 boiler plate가 요구된다.
- 세 개의 actions (fetch request, succeeded, failed)
- 세 개의 reducers (fetch request, succeeded, failed)
- one middleware (보통은 redux-thunk || redux-saga 등)
실제 프로젝트 개발을 하면서 redux-middleware를 썼지만 해당 부분에 대해서 당연히 써야해서 쓰긴 쓰지만 하나의 api call 로직을 쓰는데 이렇게 코드 작성량이 많다고,,? 라고 생각한 적이 있다. 또한, 앞서 말한 일관성 문제와 관련해서도 redux-saga 등을 통해 주기적인 요청을 보낼 수 있지만, redux가 하는 일이 너무 많아진다는 트레이드 오프가 존재한다.
Server State 분리에 따른 장점
1) 앞서 말했듯이 데이터의 일관성 유지를 위해서는 개발자가 직접 redux-saga 등을 써서 로직을 짰어야 했는데, 이를 data fetching library가 대신 해준다. fetching 해온 데이터를 캐싱하여 관리하고, 오래된 데이터는 background에서 자동으로 업데이트한다.
background에서 자동으로 업데이트하는 조건
- query가 mount 되었을 때
- window가 refocuse 되었을 때
- network가 재연결 되었을 때
- query configure로 refetch interval를 설정했을 때2) 위에서 말한 boiler plate가 줄어든다. 예를 들어, data-fetching과 관련된 상태(status, data, isFetching, isSuccess, isError)를 한꺼번에 제어할 수 있으며 데이터 동기화 로직과 redux-saga에서 작업하는 비동기 로직을 완전히 걷어낼 수 있다!?
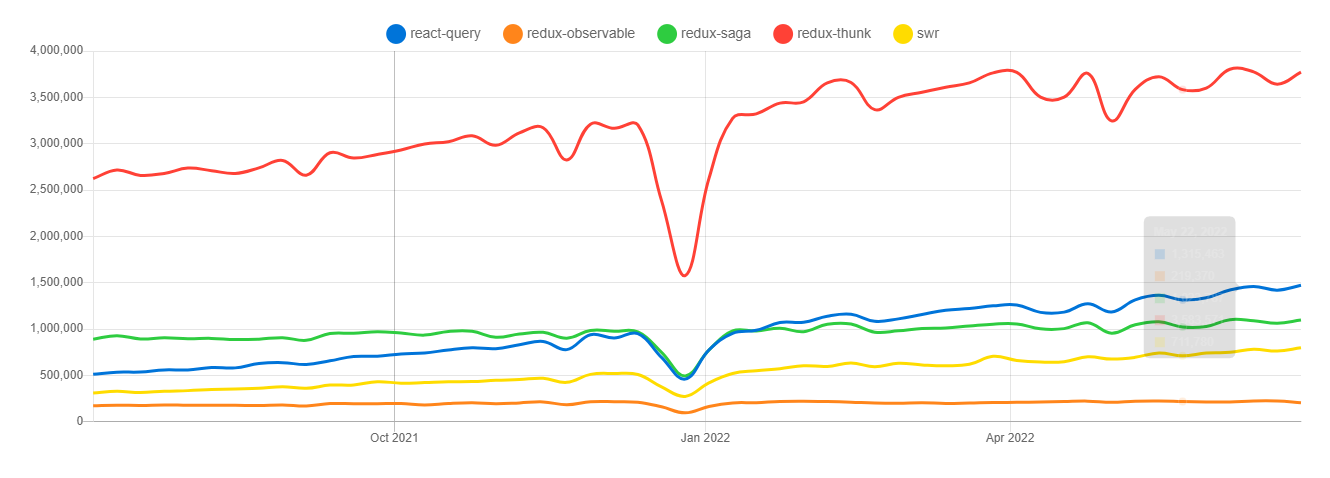
About data fetching libraries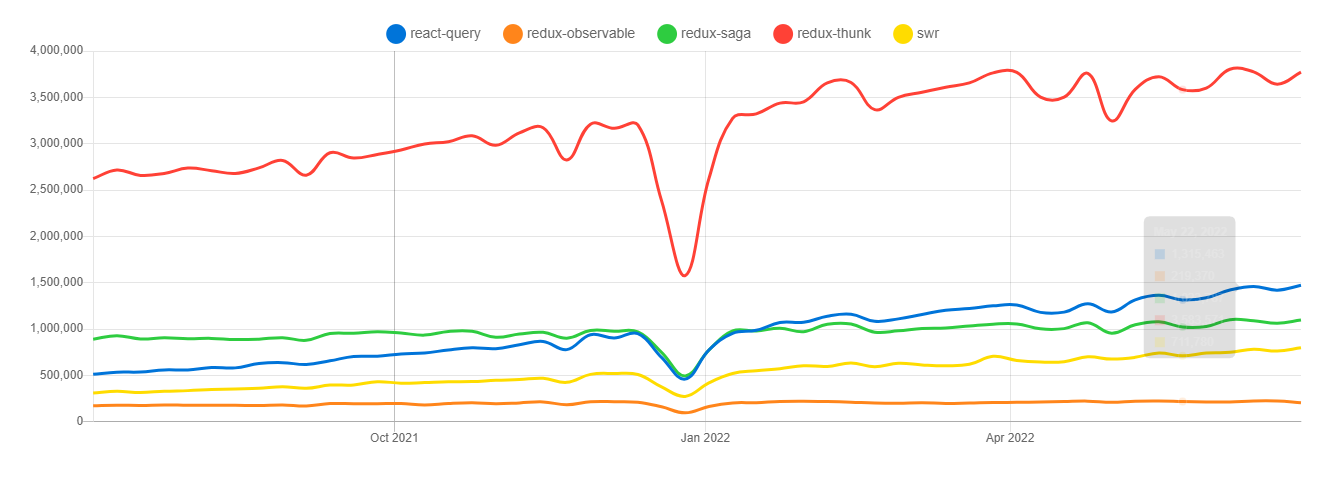
: 일단 npm trends만 봤을 때는 현재 부동의 1위는 여전히 redux-thunk(redux middleware) 이다. 하지만, redux-saga는 이미 react-query에게 그 자리를 내줬음을 볼 수 있다(2022년 1월에 무슨일이 있던걸까?..)
React-query의 장점(Data fetching library의 장점)
: react-query는 위에서 말한 data-fetching library 중에 가장 많이 쓰이는 라이브러리이다. 먼저, react-query를 써서 간단한 todoList를 만들어봤다.
Todos.js
import { getTodos, postTodo } from "./my-api";
import { useRef } from "react";
import { useQuery, useMutation, useQueryClient } from "react-query";
let count = 0;
export default function Todos() {
const { isLoading, isError, data, error } = useQuery("todos", getTodos);
const queryClient = useQueryClient();
const inputRef = useRef(null);
const mutation = useMutation(postTodo, {
onSuccess: () => {
// Invalidate and refetch
queryClient.invalidateQueries("todos");
},
});
if (isLoading) {
return <span>Loading...</span>;
}
if (isError) {
return <span>Error: {error.message}</span>;
}
return (
<div>
<ul>
{data?.map((todo) => {
return <li key={todo.id}>{todo.title}</li>;
})}
</ul>
<input
type="text"
ref={inputRef}
onKeyDown={(e) => {
if (e.key === "Enter") {
count++;
mutation.mutate({
id: Date.now(),
title: inputRef.current.value,
});
inputRef.current.value = "";
}
}}
/>
<button
onClick={() => {
mutation.mutate({
id: Date.now(),
title: inputRef.current.value,
});
}}
>
Add Todo
</button>
</div>
);
}App.js
import { QueryClient, QueryClientProvider } from "react-query";
import { ReactQueryDevtools } from "react-query/devtools";
import Todos from "./Todos";
const queryClient = new QueryClient();
export default function App() {
return (
<QueryClientProvider client={queryClient}>
<Todos />
<ReactQueryDevtools initialIsOpen={false} />
</QueryClientProvider>
);
}???.. 뭔가 허전하다 싶지만 정상적으로 작동한다. 그리고 redux가 global state를 관리해주듯이 react-query는 server state를 전역적으로 사용할 수 있게 해준다. 사실 저렇게 간단한 todoList를 서버로부터 받아온다는 전제로 redux로 구현하려면 redux-thunk or redux-saga를 써야한다. 그러다보면 위에서 useQuery가 해주는 부분을 개발자가 모두 코딩으로 커버해야한다(=boiler plate가 많고, 이에 따라 유지, 보수가 직관적으로 어려워진다). 그러면 일단 react-query로 비동기 처리를 할 수 있음을 알았다. 그러면 react-query는 그 외에 어떤 기능을 가지고 있고, 그러한 기능으로 redux의 middleware가 제공하는 기능들을 대체할 수 있을지 알아보자.
** react-redux로 server state를 관리하는 것보다 react-query가 훨씬 간편하다는 것을 보여주는 글 내용
A major advantage of React Query is that it is far simpler to write than React Redux. In React Redux, an operation to optimistically update a field requires three actions (request, success, and failure), three reducers (request, success, and failure), one middleware, and a selector to access the data. In React Query however, the equivalent setup is significantly simpler as it only requires one mutation (which consists of four functions) and one query.
** 추가로 react-query는 많은 IDE들이 navigation tool을 제공하기 때문에(redux-saga와 비교했을 때) 훨씬 편하게 쓸 수 있다.
Another advantage of React Query is that it works more smoothly with navigation tools built into many IDEs. With React Query, you can use “Go To Definition” to more easily reach your mutation whereas with Redux Saga, you must search the entire codebase for uses of the action.
RTK Query vs React-query
: 그렇다면 현재 프로젝트가 Redux Toolkit을 쓰고 있다고 했을 때, RTK Query를 쓰는게 좋을까 React-query를 쓰는게 좋을까?
RTK Query란?
RTK Query is a powerful server data caching solution explicitly built for Redux Toolkit.
: 간단하게 RTK에서 만들어서 제공하는 서버 데이터 캐싱 솔루션이다. 이 때, RTK Query 자체가 React-query나 SWR과 같은 데이터 페칭 라이브러리에서 영감을 받아서 만들어진 것이기 때문에 역할이 비슷하다고 보면 된다.
RTK Query의 쓰임새
- Queries & Mutations로 구성돼있다.
- Mutations : 서버에 데이터 업데이트를 요청하거나(POST), local cache(RTK Query나 React-query 등의 라이브러리는 server state를 local cache에 저장한다)에 똑같이 이 업데이트 내용을 반영할 때 쓰인다.
- Queries : RTK Query를 쓸 때 가장 많이 쓰이는 부분으로 axios, fetch 등을 통해 data fetch를 할 수 있도록 해준다.
- 추가로 Error Handling 과 cache 데이터를 업데이트 요청 api(POST)가 끝나기 전에 즉시 업데이트 하는 optimistic updates에 쓰인다.
왜 RTK Query를 써야할까
: 위에서 살펴본 RTK Query의 쓰임새만 봤을 때 코드의 양을 줄여주고, store에서 server state를 분리해서 관리해준다는 이점은 알겠지만 그 정도 이유로 RTK Query를 써야할까?(혹은 다른 data fetching library를?). 이를 명확히 하기 위해 RTK Query가 제공하는 추가 기능을 살펴보자.
- RTK 쿼리는 프레임워크에 구애받지 않는다. Redux(Vue.js, Svelte, Angular 등)를 사용할 수 있는 프레임워크와 통합할 수 있다.
- TypeScript로 구축되어 있기 때문에 타입스크립트 지원 측면에서 최적의 도구이다.
- OpenAPI 및 GraphQL을 지원합니다.
- 리액트 훅스(React Hooks)를 지원한다.
- WebSocket을 통한 스트리밍 업데이트를 가능하게 하는 캐시 라이프사이클을 제공한다.
- Redux DevTools의 모든 기능을 활용할 수 있다. 시간 경과에 따른 상태 변경 내역을 추적 할 수 있다.
- RTK Query만 생각했을 때(RTK 제외) 번들 크기가 매우 작다(~2KB).
RTK Query vs React-Query
** 출처 : https://blog.bitsrc.io/frontend-caching-with-redux-toolkit-query-14e008a632b1
: 위의 비교표로 봤을 때 React-Query가 기능이 더많지만, 사실 아래 3기능을 쓰지 않을 것이라면 그리고 RTK를 쓰고 있다면 RTK Query를 선택하는 방향도 고려해볼 수 있을 것이다.
위와 같은 data fetching 라이브러리가 있음에도 리덕스 미들웨어는 필요할까?
: API 요청을 data fetching 라이브러리로 대체하는 방향으로 나아가고는 있지만, 일부 기능에서는 계속 리덕스와 미들웨어를 사용하는게 더욱 효율적일 때가 있다.
리덕스 미들웨어의 강점
-
요청(dispatch, fetch 등의)을 연달아서 여러번 했을 때 이전 요청은 무시하고, 맨 마지막 요청만 처리되도록 하고 싶을 때 : 예를 들어, 검색어 자동 완성 기능을 생각했을 때 맨 처음 친 단어보다는 끝까지 친 단어에 대해서 연관 검색어를 받아오는 api를 받아와야 최신의 정보를 빠르게 보여줄 수 있다.
-
특정 조건이 만족됐을 때 이전에 시작한 요청을 취소해야 하는 상황 :
예를 들어서, 라프텔의 작품상세 페이지는 에피소드들을 20개씩 페이지네이션 해서 불러오는데요, 에피소드의 하단에는 작품의 연관 작품들이 보여집니다. 대부분의 작품은 20~40개 내외의 에피소드를 가지고 있지만, 코난 1기 같은 작품들은 예외적으로 100 에피소드가 있습니다. 현재 페이지네이션은 무한 스크롤링 방식으로 구현을 했기 때문에, 기본적으로는 관련 작품을 보려면 무조건 100개의 에피소드를 모두 로딩해야 볼 수 있습니다. 이를 좀 더 개선하기 위해서 저희는 페이지를 로딩 중일 때 에피소드 영역을 초과하여 관련 작품을 보게 된다면 기존의 페이지 로딩을 취소하도록 만들었습니다. 이렇게 하면 유저가 모든 리스트를 불러오지 않아도 페이지 하단의 컨텐츠를 스크롤해서 확인 할 수 있게 됩니다. 이렇게 특정 조건이 만족 됐을 때 이전에 한 요청을 취소하는 작업은, 미들웨어를 사용하면 쉽게 구현 할 수 있습니다. -
특정 콜백함수를 원하는 액션이 디스패치 됐을 때 호출하도록 등록을 하는 상황(이전에 redux-saga 관련 포스팅을 할 때 redux-saga의 강점으로 말한 부분)
export function* workerSaga(action: ReturnType<typeof actions.open>) {
const { confirm } = yield race({
confirm: take(actions.confirm.type),
cancel: take(actions.cancel.type),
});
if (confirm) {
action.payload.onConfirm?.();
} else {
action.payload.onCancel?.();
}
}
export default function* watcherSaga() {
yield takeEvery(actions.open.type, workerSaga);
}- 컴포넌트 밖에서 어떤 작업을 수행할 때
: 위와 같은 부분에서 생각해볼 때 결국 data fetching library는 이전에 redux-thunk, redux-saga 등의 미들웨어를 도입한 이유가 단지 비동기 처리를 위해서라는 점에서는 충분히 리덕스 미들웨어보다 유용성 측면에서 우위를 점하지만, 위에서 말한 다양한 기능들을 생각했을 때는 여전히 redux-middleware의 효용성은 존재한다고 생각할 수 있다. 결론적으로 완벽하게 middleware를 대체할 수 있는 대체재인가?라고 했을 때 대답은 NO 인 시점 같다.
: 하지만 프로젝트를 구성한다 했을 때 Redux-Toolkit + RTK Query(Or React Query) 조합으로 사용하되 여기에 앞서 말한 리덕스 미들웨어의 강점을 이용하기 위해 redux-saga를 추가해서 쓰는 방법도 좋을 것 같다. 혹은 redux + react-query + redux-saga의 조합도 좋을 것 같다.

"Data fetching" I am doing research in this field. And very few articles are written about it. Your sharing is timely https://webecomewhatwebehold.online.