 !
!
'www.google.com'을 URL 입력창에 입력하면 어떻게 될까?
: 흔히 면접에서 단골 질문(?)으로 나오는 이 질문에 대해서 파헤쳐보자
Chapter
- URI, URL, URN ?
- HTTP & HTTPS + HTTP message
- DNS, IP주소, 도메인 주소
- 프로토콜 스택 with socket library
- TCP connection (3,4 way handshake)
- TCP vs UDP
- OSI 7 layer
- DOM + CSSOM => Render Tree
- JS parsing(+ defer & async attribute) & AST(Abstract Syntax Tree)
- layout and paint
- relow and repaint(re-rendering)
URI, URL, URN ?
URI = URL + URN
: 먼저, URL 입력창에 'www.google.com'을 입력한다고 하는데, URL은 뭘까? 그리고 우리가 흔히 듣던 URI는 뭘까?. 먼저 URL은 'Uniform Resource Locator'의 약자로, 굳이 해석해보면 '통합 자원 위치' 정도가 되겠다. 간단히 말해 인터넷 세상 속에서 클라이언트가 원하는 자원의 위치 정보를 의미한다(서버 위치). 그러면 URI는 뭘까?. Uniform Resource Identifier의 약자인 URI는 'URL + URN = URI' 즉, 통합 자원 식별자로 자원의 위치 혹은 식별할 수 있는 모든 것들을 통칭하는 말이다. 보통 URI와 URL을 거의 같은 의미로 쓰는데 엄밀히 말하면 URN도 URI에 포함되기 때문에 맞는 말은 아니다. 하지만 대부분의 식별자가 URL로 돼있기 때문에 어느정도는 맞는 말이다. URN은 Uniform Resource Name의 약자로 통합 자원 이름인데, URL과의 차이는 URL은 서버의 위치를 상대적인 위치로 표기하는 것이다. 따라서 URL의 경우 서버의 위치가 변경되면 찾을 수 없는 문제가 발생하지만, URN은 좀 더 절대적인 의미의 서버 위치로서 위치가 변경된다 하더라도 서버를 식별할 수 있다. 비유해보면 어떤 사람이 A주소에 산다고 표기돼있었는데 이사를 갔다고 해보자. 그러면 더이상 A주소는(URL) 그 사람의 위치를 식별하는 데에 도움을 주지 못한다. 그러나, 어떤 사람('y'라고 해보자)의 이름인 'y'를(URN) 통해 그 사람의 위치를 언제든 절대적으로 추적할 수 있다(어디로 이사를 가건).
URL의 구성요소
: 앞서 말했듯이 URL은 넓은 인터넷 세상(?)에서 자원의 위치를 식별하기 위한 고유 주소값과 같다. 이것이 있어야 수많은 자원 중에 클라이언트가 원하는 자원을 찾아갈 곳을 알 수 있다. 그러면 URL은 어떻게 구성돼있을까?.
를 보면 먼저 'http://' 여기서 http는 scheme 부분이다. 여기에는 HTTP, HTTPS, FTP, telnet, mailto, file 등 다양한 프로토콜에 해당하는 정보가 온다. 어떤 프로토콜로 연결을 할지를 표기하는 곳이다.
다음으로, 'www.google.com' 이 부분은 도메인 혹은 호스트의 주소(서버 위치)를 의미한다. DNS 부분에서 말하겠지만 사실 이 도메인 주소는 사람들이 외우기 쉽도록 만들어놓은 간이 주소이다. 실제로 OSI 7 layer(or TCP/IP 모델)의 절차상에서 연결 상대의 위치를 찾을 때는 IP주소와 MAC주소 등을 참조하게 된다.
이외에도 도메인 주소 뒤에 상세 경로가 나오기도 하고(예를 들어, 'http://www.google.com/users'), 이외에도 많은 정보를 담을 수 있다.
- 질의 문자열(쿼리 스트링) : 프론트엔드 개발자라면 한번쯤은 이용해봤을만한 HTTP GET 메서드를 쓸 때 자주 사용하는 쿼리 스트링으로 URL에 정보를 담을 때 사용한다. 'www.stylebot.co.kr/clothings?type=chic&sex=male' 이런식으로 사용한다.
- 파라미터 : 경로를 표기할 때 추가 정보를 파라미터를 통해 제공해서 서버의 위치를 찾기 용이하게 부가정보를 붙일 때 쓴다. 예를 들어, 경로가 '/clothings/closet' 일 때, 'clothings;type=chic/closet;sex=male' 이런식으로(; 을 이용해서) 쓴다.
- 프래그먼트(#) : 이것은 서버단에서 이 기호를 통해 뭔가를 처리하는 것은 아니고(서버는 html 파일 전체를 보낼 뿐이다) 브라우저 단에서 이 기호가 붙은 HTTP request를 보냈다가 response를 받아서 렌더링할 때 '#' 뒤에 써준 부분만 렌더링하게 한다. 예를 들어, '/tools.html#drills' 이런식으로 써주면 drills 부분만(태그 내에 id=drills인 부분) 보여주게 된다.
- 포트 넘버 : 연결 상대의 어떤 프로세스와 통신을 할 것인지를 명시하는 정보인 포트 넘버 또한 URL에 들어간다(HTTP 통신은 포트 넘버가 80으로 정해져있다). 항상 이 포트 넘버를 쓰고 있지만, 실제 브라우저 URL 검색창에 입력할 때는 생략해도 되기 때문에 우리가 모르고 있던 것이다.
URL 입력시 주의 사항
: URL에는 URL에서 고유하게 선점한 /, #(프래그먼트), ;(파라미터),?,&(질의 문자열), :(스킴에서 쓰는 것), %(이스케이프 토큰), [], <>, {}, =, .., . 등을 쓸 수 없게 해뒀다. 이에 따라 이러한 문자들을 쓰고 싶을 때는 '인코딩' 과정을 거쳐야한다(개발자가 해줘야한다).

개발을 하면서 한번쯤은 써봤을 법한 이스케이프 문자로의 인코딩 메서드이다.
** window 객체에 포함된 메서드이다.
URL 확장이란
: 실제로 유저가 URL 검색창에 URL을 입력하다보면, 'www.google.com'이라고 안치고, google.. 부터 치게된다. 그러면 자동으로 www.google.com 형태로 완성이 되는데, 이를 '호스트명 확장'이라고 한다.
또한, 이전에 www.google.com에 접속한 기록이 있다면 브라우저가 이를 참조하여 goo까지만 입력해도 'www.google.com'이 자동으로 아래 리스트에 뜨게 된다. 이를 '히스토리 확장'이라고 한다.
여기까지 정리
: 여기까지 URL에 대해서 알아봤고, 브라우저의 구성요소 중에 하나인 URL 검색창에 'www.google.com'을 쳐보기까지 이해해야하는 용어들을 정리했다. 그럼 이제야 우리는 'www.google.com'을 URL 검색창에 입력했다(URL 확장이 일어나면서..ㅎㅎ). 그리고 enter도 쳤다! 그러면 브라우저는 이를 파싱하게 된다(URL 파싱). 이 때 아까말했던 파라미터, 포트 넘버, 프래그먼트, 스킴 등등의 정보들을 기준으로 파싱을 하게된다.
HTTP & HTTPS + HTTP message
: URL을 파싱한 다음에 브라우저는 이를 바탕으로 HTTP request message를 만들게 된다.
what is HTTP?
: HTTP란 'Hyper Text Transfer Protocol'의 약자로 하이퍼텍스트(HyperText Markup Language를 의미하는 HTML을 말한다고 생각하면 된다)를 전송할 때 쓰는 프로토콜(통신 규약 혹은 통신 방법)을 의미한다. 간단히 말해 인터넷 상에서 HTML 파일을 주고 받고 할텐데 그 HTML 파일을 주고 받고 하는 데에 있어서 HTTP라는 통신 방법을 쓴다는 것이다.
what is HTTP message? 
: 브라우저는 HTTP 메시지를 만든다고 했는데, 그러한 메시지를 시각화해보면 위와 같다. 위의 경우는 서버단에서 클라이언트 단으로 보내는 response message의 형태이다. 하지만 request message의 경우도 유사한 구조를 갖는다.
- 시작줄 : 메시지를 보내는 송신측에서 http의 버전중에 몇까지 감당할 수 있는지를 표기한다('http/1.0' 부분). 또한, request의 경우 시작줄에 url 정보 및 HTTP 메서드를 표기한다. 이와 달리 response의 경우 위의 그림처럼 버전 정보, http 상태 메시지('OK') 그리고 상태 코드('200')를 표기한다.
- 헤더 : 헤더는 'content-type', 'content-length', 'accept' 등등 다양한 키와 값으로 돼있는데, 담은 정보(엔티티 본문)에 대한 메타데이터 등을 담는 곳이다.
- 엔티티 본문 : 데이터를 담는 곳으로 필수는 아니다(앞의 시작줄과 헤더는 필수이다).
HTTP method & status code
1) HTTP method
: client(브라우저) 쪽에서 request message를 보낼 때, 시작줄에 HTTP method 정보를 포함한다. REST API를 만들 때, 이 http method를 통해 어떤 '행동'을 할지를 명시한다. 다시 말해, HTTP를 효율적으로 사용하면서 URL을 표기하는 방법론을 의미하는 REST API에서는 URL에 경로를 표기하는 부분에 있어서는 '명사'로 표현할 것을 권유하고, 예를 들어, id 를 삭제 하는 요청이라면 'www.google.com/id/delete' 이런식으로 하는 것이 아니라 'www.google.com/id' 이렇게 URL을 구성하고, HTTP method 중 DELETE를 이용해서 이를 표현하기를 권유한다. 이처럼 HTTP 메서드는 어떤 행동을 할지를 명시하는 부분이다.
- GET : GET은 '조회' 혹은 SQL 쿼리문으로 치면 'SELECT'의 성격을 갖는 메서드이다. 주로 response status code '200 OK'와 연관되는 메서드이다. 주의할 점은 GET 메서드로 받아온 데이터는 브라우저가 자동으로 캐싱하기 때문에 이에 대한 고려가 필요하다(실제로 현업에서 근무할 때 자동 캐싱 때문에 도대체 왜 같은 데이터가 계속 오지?...라고 의문을 가진 적이 있다..). 또한, 아까 URL 부분에서 말한 질의 문자열을 가지고 데이터를 전송하기 때문에 크기가 작고, 보안면에서(URL에 드러나기에) 중요하지 않은 정보를 담아서 쓸 때 유용하다.
- POST : POST는 SQL 쿼리문으로 치면 'INSERT'와 유사한 메서드이다. 무언가를 생성하는 데에 주로 쓰이며 '201 created' 상태 코드와 주로 매칭된다. 이 때, GET 메서드와 달리 엔티티 본문에 데이터를 주로 담기 때문에 상대적으로 크기가 큰 데이터를 담는데 유용하며, 보안 면에서 GET 메서드보다는 유용하다(드러나지 않으므로). 그러나, 현실적으로 보안면에서 드러나는지, 안드러나는지 차이로는 전혀 차이가 없기 때문에 추가적인 보안 설정은 개발자가 해줘야한다(HTTPS를 쓰던지 등).
- HEAD : HEAD 메서드는 GET 메서드를 보낼 때 서버쪽에서 header에 넣어서 보내주는 정보를 받아오고 싶을 때 쓰는 메서드이다. 즉, GET 메서드로 요청을 하면 서버쪽에서 그에 해당하는 데이터와 그 데이터의 메타 데이터를 담은 header를 같이 보내주는데, 데이터를 받기 전에 어떤 데이터인지 파악만 하고 싶을 때 그 header만 받고 싶을 때 사용한다.
- PUT & PATCH : SQL 쿼리문의 UPDATE와 유사한 메서드로 수정을 할 때 쓴다. 이 때, PUT은 전체를 수정할 때 쓰며, PATCH는 부분 수정을 하는 의미로 쓴다.
- DELETE : 삭제 요청을 할 때 쓰는 메서드이다.
- TRACE : 본래 서버에 요청을 보낼 때 via라는 키에 클라이언트에서 서버까지 요청 메시지가 가면서 거쳐갔던 프록시 서버, CDN 등의 매개체(?) 들의 정보가 담기게 되는데, TRACE 메서드는 그 via에 담긴 정보를 보내달라는 메서드이다.
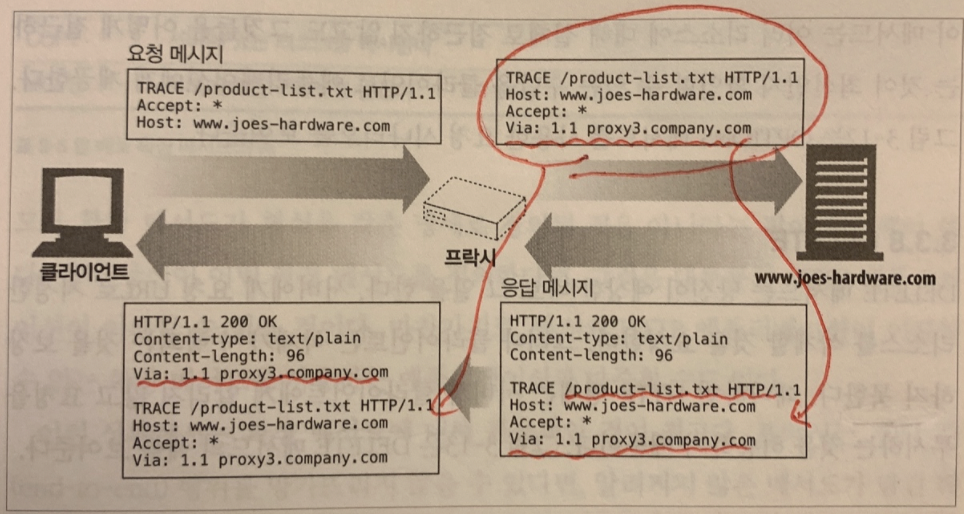
위와 같이 보내면 via에 담겼던 정보가 그대로 돌아오게 된다. - OPTIONS : 서버쪽에서 어떤 메서드를 제공 및 허용하는지에 대한 정보를 얻고 싶을 때 쓴다. 일례로, cors 에서 preflight-request를 보낼 때도 OPTIONS 메서드를 쓴다.
- 확장 메서드 : 커스텀 메서드라고도 할 수 있는데, 직접 만들어서 쓸 수 있도록 제공하는 메서드이다.
2) status code
: 이번에는 서버측에서 클라이언트 쪽으로 응답을 보낼 때 사용하는 '상태코드'에 대해서 간략하게 정리해본다.
- 200번대 : 요청이 성공적으로 처리됐음을 알리는 부분
- 300번대 : 리소스의 위치가 변경됐기에 리다이렉트를 해주는 부분
- 400번대 : 요청이 잘못돼서 실패한 요청임을 알리는 부분
- 500번대 : 서버쪽에서 에러가 발생했음을 알리는 부분
HTTP의 특징
stateless & connectionless
http는 기본적으로 무연결성, 무상태성의 특징을 갖는다. 먼저 비연결성은 계속해서 연결돼있지 않다는 것이다. 즉, 클라이언트가 서버에 요청을 하고, 서버가 응답을 마치면 연결을 바로 끊어버린다. 다음으로 무상태성은 서버가 이전에 클라이언트가 보내왔던 요청에 대한 결과를 바로 까먹는다는 것이다. 요청, 응답이 끝나면 연결도 끊기지만, 서버는 이전에 클라이언트와의 통신을 기억조차 하지 못하게 된다(이것 때문에 인증 등의 필요성이 생기고 토큰, 쿠키와 관련된 해결책을 찾은 것).
HTTP + SSL or TLS = HTTPS
references
- 성공과 실패를 결정하는 1%의 네트워크 원리(Tsutomu Tone)
- 모던 자바스크립트 Deep Dive(이웅모)
