
인덱스란?
인덱스는 데이터베이스에서 데이터를 빠르게 검색하고, 조회하기 위한 자료구조이다. 사전 뒷편에 있는 찾아보기와 같은 역할을 한다고 생각하면 된다. 인덱스는 특정 칼럼 또는 칼럼의 조합에 대한 값과 해당 값이 존재하는 테이블 내의 물리적인 위치를 매핑한다. 이를 통해 데이터베이스는 효율적으로 데이터를 검색하고 필요한 정보를 빠르게 가져올 수 있다.
단점
- 인덱스는 대략 테이블 크기의 10% 공간이 추가로 필요하다.
- Select가 아닌 데이터의 변경 작업(Insert, Update, Delete)가 자주 일어나면 오히려 성능에 악영향(정렬 작업으로 인해)
MySQL 인덱스 유형
B-Tree 인덱스
가장 일반적으로 사용되는 인덱스 유형으로, 검색 및 정렬 작업에 효과적
데이터를 B-Tree 구조로 저장하여 빠른 검색이 가능하다.
B-Tree
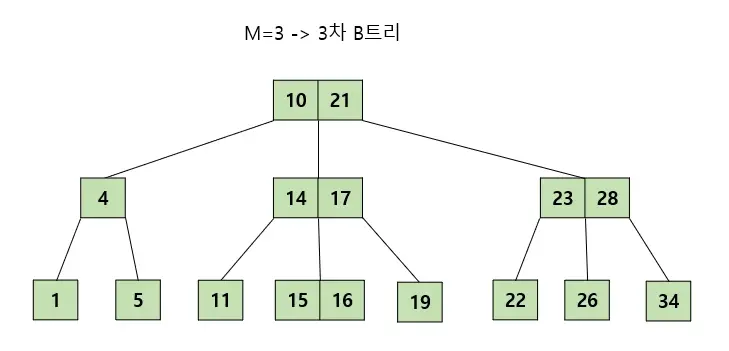
- 루트로부터 리프까지의 거리가 일정한 트리 구조
- 항상 정렬된 균형 상태를 유지한다. 따라서 탐색이 빠르다(O(logN))
- 하지만 재 정렬하는 작업으로 인해 노드 삽입 및 삭제 시 일반적인 트리보다 성능이 떨어진다.
B-Tree를 선택한 이유
B-Tree의 각 노드는 배열로서 실제 메모리 상에 저장이 되어 있다. 같은 노드 공간의 데이터들끼리 굳이 자식 노드처럼 참조 포인터 값으로 접근할 필요가 없는 것이다. 즉 같은 노드 안에서 데이터를 탐색할 때, 포인터 접근이 아닌 실제 메모리 디스크에서 바로 다음 인덱스에 접근을 하게 된다.
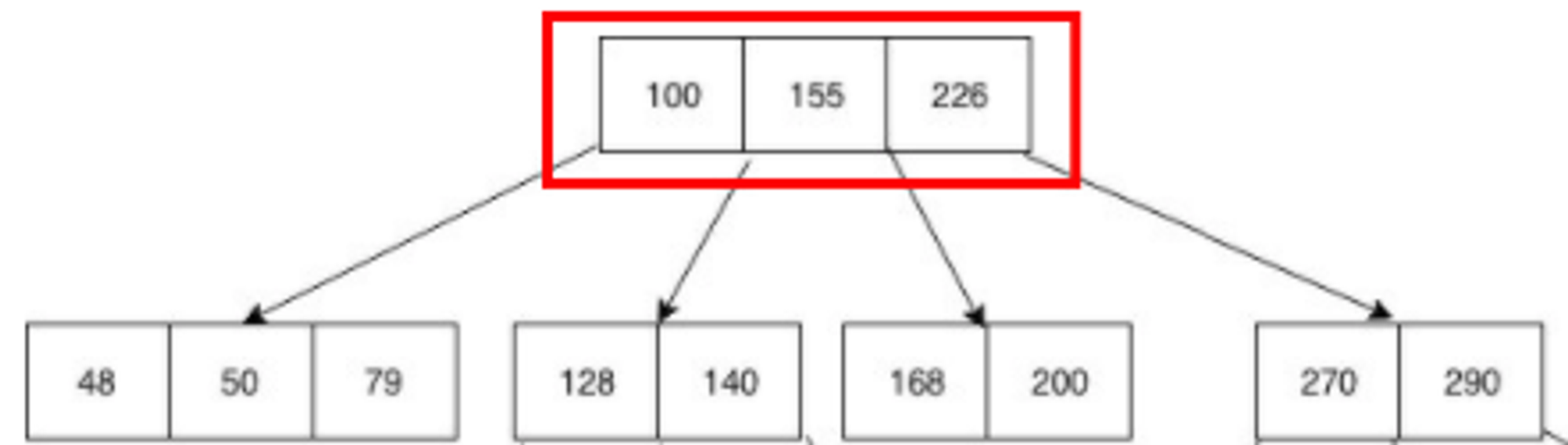
위 사진에서 200이라는 값을 찾는다고 가정해보자. 순서는 다음과 같다.
1. 루트 노드에서 100, 155, 226을 탐색한다. 순차적으로 저장됐기에 빠르게 탐색할 수 있다.
2. 루트 노드에 200이 없기 때문에, 155와 226 사이의 포인터가 존재하는 지 확인 후 해당 포인터를 통해 자식 노드로 접근한다.
3. 자식 노드로 가 168, 200을 탐색 후 200을 찾아낸다. 이 과정 또한 순차적으로 저장됐기에 빠르다.
해시 인덱스
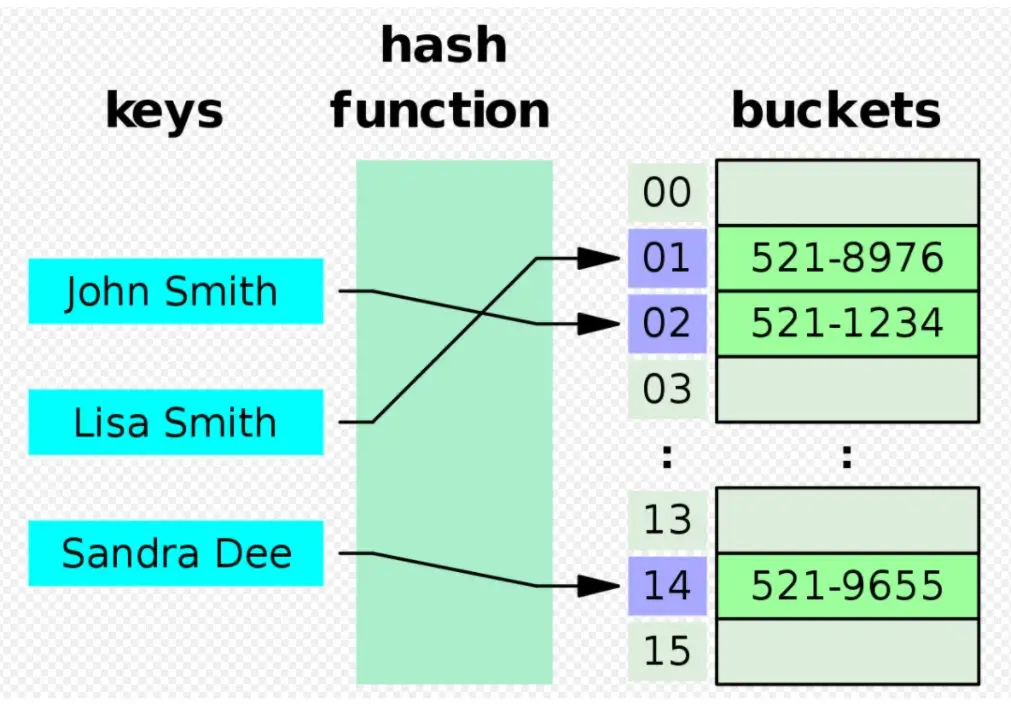
- 특정 칼럼의 값을 해시 함수를 사용해 해시 값으로 변환하여 인덱스를 생성한다.
- 해시 값은 고유한 값으로, 해시 함수에 의해 계산된 값에 해당하는 위치에 데이터를 저장한다.
- 해시 인덱스는 해시 값에 해당하는 데이터를 빠르게 검색할 수 있지만, 데이터의 정렬이나 범위 검색에는 적합하지 않을 수 있다.
- 해대량의 데이터 속에서 특정 값을 빠르게 찾을 때 유용하다.
- 메모리 기반 db에서 많이 쓰인다.
인덱스 종류
클러스터 인덱스(Clustered Index)
- 테이블당 1개만 존재할 수 있음
- Primary key로 지정된 컬럼은 자동으로 클러스터링 인덱스가 생성됨
- 실제 저장된 데이터와 같은 무리의 페이지 구조를 가짐
- 클러스터링 인덱스를 기준으로 데이터 자동 정렬
- 기본 키를 변경할 시 해당 키를 기준으로 다시 정렬
보조 인덱스(Secondary Index)
- 한 테이블에 여러개 설정 가능
- UNIQUE 키워드로 고유 컬럼 지정시 자동으로 보조 인덱스가 생성됨
- 실제 저장된 데이터와 다른 무리의 페이지 구조를 가짐
- 클러스터링 데이터와 달리 데이터를 정렬하지 않음
- CREATE INDEX 문으로 직접 보조 인덱스 생성 가능
인덱스 동작 원리
위에서 말했듯, 클러스터 인덱스와 보조 인덱스는 모두 B-Tree로 만들어진다.
B-Tree에서 데이터가 저장되는 공간을 노드라고 하고, MySQL에서는 이러한 노드들을 페이지라고 부른다.
MySQL에서는 페이지를 나누어 데이터를 저장하는데, 페이지는 MySQL 기준 최소 16KB의 크기를 가지며 페이지 데이터 공간이 추가적으로 필요할 경우 페이지 분할 작업을 통해 페이지를 생성하고 분할하는 작업을 거친다. 이 작업이 자주 일어나게 되면 데이터베이스 성능에 큰 영향을 미친다.
클러스터 인덱스(Clustered Index)
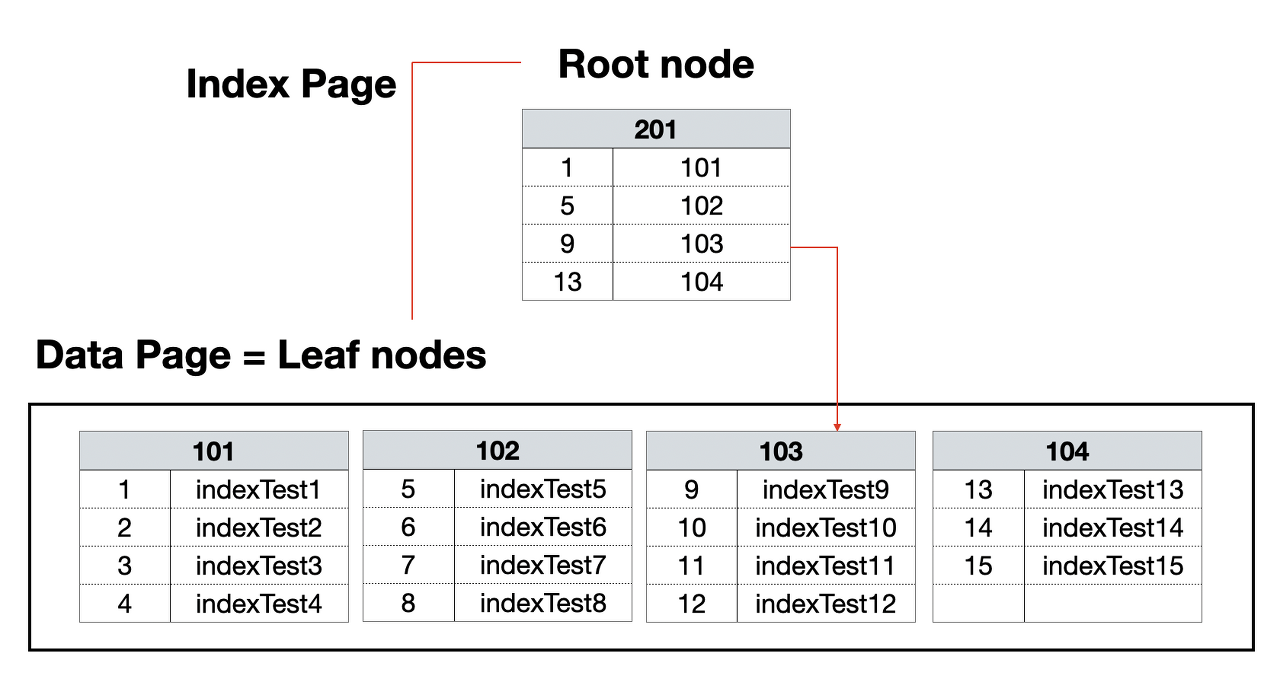
- 실제 데이터가 정렬된다.
- 검색 시 먼저 루트 노드에서 탐색할 페이지를 찾고 해당 페이지에서 검색할 데이터를 찾게 됨으로써 검색 시간을 줄인다.
보조 인덱스(Secondary Index)
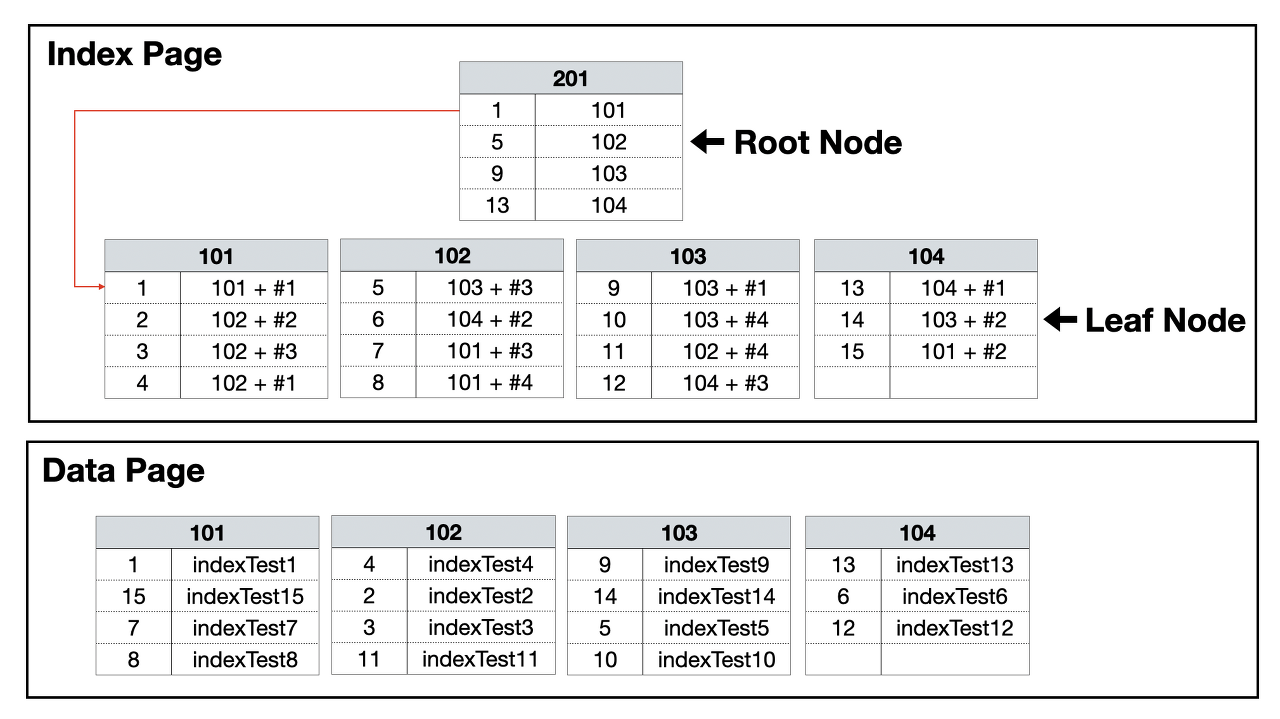
- 실제 데이터를 정렬하지 않는다.
- 보조 인덱스를 설정해도 데이터 페이지에는 영향이 없고, 별도 장소에 인덱스 페이지를 생성한다.
- 별도로 생성된 인덱스 페이지는 인덱스가 걸린 컬럼 값에 따라 정렬되어 별도의 페이지를 생성한다.
- 리프 페이지는 실제 데이터가 저장된 위치를 가리킨다. 클러스터 인덱스와 함께 사용할 경우, 정렬된 데이터 페이지를 가리킨다.
Commands
인덱스 생성
CREATE [UNIQUE] INDEX 인덱스 이름
ON 테이블 이름 (열 이름) [ASC | DESC]- UNIQUE 옵션은 중복이 안되는 고유 인덱스를 생성하는 것인데, 생략하면 중복이 허용된다.
- ASC 또는 DESC로 인덱스 정렬 방향 변경 가능
인덱스 제거
DROP INDEX 인덱스_이름 ON 테이블_이름- 기본 키, 고유 키(UNIQUE)로 자동 생성된 인덱스는 제거 불가
- 기본 키나 고유 키를 제거하면 가능
- 인덱스를 제거할 때는 보조 인덱스부터 제거하는 것이 좋다.
인덱스 확인
SHOW INDEX FROM 테이블 이름인덱스 사용 확인
EXPLAIN
Query...- 어떤 table에서 어떤 인덱스를 사용했는 지 볼 수 있다.
단일 인덱스, 다중 컬럼 인덱스
Table1(단일 인덱스)
CREATE TABLE table1(
uid INT(11) NOT NULL auto_increment,
id VARCHAR(20) NOT NULL,
name VARCHAR(50) NOT NULL,
address VARCHAR(100) NOT NULL,
PRIMARY KEY('uid'),
key idx_name(name),
key idx_address(address)
)Table2(다중 컬럼 인덱스)
CREATE TABLE table2(
uid INT(11) NOT NULL auto_increment,
id VARCHAR(20) NOT NULL,
name VARCHAR(50) NOT NULL,
address VARCHAR(100) NOT NULL,
PRIMARY KEY('uid'),
key idx_name(name, address)
)Table 1은 name과 address에 대한 단일 인덱스, Table 2는 (name, address)에 대한 다중 컬럼 인덱스를 설정했다.
Query1
SELECT * FROM table1 WHERE name='홍길동' AND address='경기도';Table1의 경우 단일 인덱스가 걸려있기 때문에 name과 address 중 어떤 컬럼이 더 빠르게 검색되는지 판단 후 빠른쪽을 먼저 검사라게 된다.
Table2의 경우 name과 address를 같이 저장하기 때문에 검색 시에도 '홍길동경기도'와 같이 검색을 시도하고, 바로 원하는 값을 찾을 수 있다.
Query2
SELECT * FROM table2 WHERE address='경기도';반면 Query2의 경우, Table 1에서는 address 인덱스가 적용되지만, Table 2에서는 인덱싱이 적용되지 않는다. name이 사용되지 않았기 때문이다
인덱스 사용시 유의사항
- Cardinality가 높은 (중복도가 낮은) 열에 인덱스를 설정해야 한다.
- WHERE 절에 자주 사용되는 열에 인덱스를 만들어야 한다.
- 잘 사용하지 않는 인덱스는 과감히 제거한다.
- 인덱스는 테이블 데이터의 약 10% 차지
- 데이터 변경 시 페이지 분할로 인해 성능에 악영향
- Insert, Update, Delete등의 데이터 작업이 빈번한 테이블에서는 인덱스 사용을 고민해볼 필요가 있다.
- 페이지 분할로 인해 조회를 제외한 다른 작업 성능이 느려지게 됨
