
Strings
- 최대 512mbyte 길이 지원
- Text 뿐만 아니라 숫자(정수, 실수 구분이 없다)나 Binary File(JPEG같은)까지 저장할 수 있다
Command
// Set
set key value
set key value ex 10 // 만료시간 지정
set key value px 10000 // 만료시간 밀리초 단위 지정
set key value nx // 키값이 없는 경우에 저장, 존재하면 nil
set key value xx // 키값이 있는 경우에 저장, 없으면 nil
// Get
get key
getset key // 이전 값을 출력하고, 새 값을 설정
// 숫자 (""로 감싸도 숫자 처리가 가능)
incr key // 정수가 아닐 경우 에러
incrby key value
incrbyfloat key value // float 형
// multiple set, get
mset key value key value ...
mget key key key궁금증
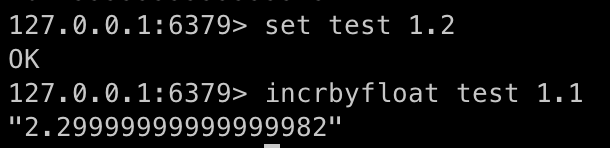
- float형 계산하면 뒤에 이상한 소수가 붙어서 나옴
Lists
- key value value value 형태 String list
- 처음과 마지막에 데이터를 삽입 / 조회할 수 있는 Quick List 사용
- 처음과 마지막 부분에 element 추가 / 삭제 / 조회는 O(1)
- 특정 인덱스 값 조회는 O(N)
- Stack이나 Dequeue으로 사용 가능
- 최대 약 40억 요소 유지 가능
Quick List란?
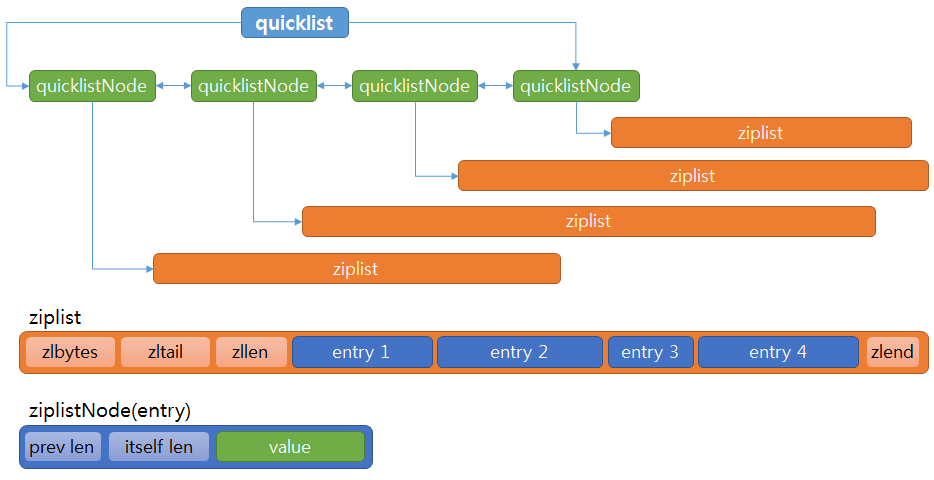
- Linked List of ziplists
- Linked List의 각 노드가 Zip List로 이뤄져있는 구조
- 처음과 마지막 노드를 제외하고 Zip List를 압축한다.
- 오버헤드가 압축하지 않은 Quick List에 비해 1/10 ~ 1/30까지 줄어든다
- 메모리 절약이 획기적으로 되는 방법
Zip List란?
메모리를 절약하기 위한 데이터 구조
레디스는 모든 데이터를 메모리에 저장하기 때문에,
비싼 자원인 메모리를 절약해 사용하기 위해 메모리 절약형 자료구조를 사용한다.
데이터 구조를 간단히 보면,
prevlen + itself len + value
prevlen : 이전 엔트리의 길이
itself len : 엔트리 자신의 값의 길이
value : 값은 문자와 정수로 구분해서 저장한다. 실수는 문자로 구분(메모리 효율 때문), 문자는 문자 그대로저장
itself len은 값이 문자열일 때는 1,2,5 바이트로 구분해서 길이를 저장하고, 숫자(정수) 일 때는 1 바이트만 사용한다.
prevlen은 이전 엔트리의 길이를 저장하는 것이므로 문자, 숫자 구분 없이 1,5 바이트 두 종류를 사용한다.
값(value)은 문자열일 때는 그대로 저장하고, 숫자(정수) 일 때는 4,8,16,24,32,64 비트로 구분해서 저장한다.
값(value)이 실수일 때는 문자열로 취급한다.
레디스는 이런 방식으로 데이터의 형태, 길이에 맞게 최대한 메모리를 절약할 수 있는 구조로 Zip List를 설계해 사용하고 있다.
Command
lpush, rpush key element // 삽입
lpop, rpop key // pop
lrange key start end // 조회
lset
blpop, blmove // blocking commandsBlocking Commands
BLPOP, BRPOP
- 리스트 헤드 원소 하나를 제거하면서 가져온다. 리스트가 비어있을 시 리스트가 차거나 타임아웃이 날 때까지 기다린다.
BLMOVE
- target list로 source list의 모든 원소를 옮긴다. 비어있다면 리스트가 차거나 타임아웃이 날 때까지 기다린다.
필요성
message queue나 task queue를 만드는데 유용하게 사용할 수 있다. 이 방법이 아니면 지속적으로 요청을 보내는 polling 방식으로 해야 할 것 같은데, 코스트가 크다
Sets
- 정렬되지 않은 unique한 String의 집합
- 다음과 같은 경우에 주로 사용한다
- unique한 데이터 관리(ex.특정 블로그에 접근하는 모든 IP 추적)
- 관계 표시(ex. 주어진 역할을 갖는 모든 사용자)
- set 함수 사용이 필요할 때(intersection, union, diff 등등)
- 최대 크기는 2^32 - 1
- 기본적으로 대부분의 커맨드는 O(1)이지만, SMEMBERS 커맨드는 모든 멤버를 보여주는데 O(N)이다.
- 크기가 크다면 SSCAN 사용을 고려해야 한다.(iterative하게 조회 가능)
Command
sadd key value // 추가
srem key value // 제거
sismember key key // 포함 여부. 특정 데이터가 Set에 포함되는지
sisinter key key // intersection
scard key // cardinality, 크기 반환
Hashes
- field-value 쌍으로 저장되는 자료구조
- object 표현할 때 좋다
- 안에 넣는 데이터 양의 실질적인 제한이 없다(메모리가 꽉 차지 않는 한)
- 대부분 command는 O(1)
- hkeys, hvals, hgetall 등 일부는 O(n)
Command
hset key field value field value... // 생성
hget key field // 단건 조회
hmget key field field field... // 다수 조회
hgetall key // 전부 조회
hincrby key field value // 필드를 value만큼 증가시킴Sorted sets
- 정렬된 set
- 연관된 점수(float)로 정렬되는 방식
- 같은 점수면 사전식 정렬
- Sorted Set 구조
- dual-ported data structure
- skip list + hash table
- 데이터를 저장할 때 O(log N) 연산을 통해 정렬하는 방식
SkipList

- Zip List가 메모리 절약에 초점을 맞춘 데이터구조라면, SkipList는 성능에 초점을 맞춘 데이터 구조
- List의 엔트리를 스킵할 수 있는 개념을 차용해서 만들어진 자료구조
- 선형적인 탐색을 한다는 개념은 같지만, 한번에 하나씩 모든 엔트리를 탐색하는 것이 아닌, Skip List의 레벨에 따라 여러개의 엔트리를 건너뛰며 순회한다.
- 데이터가 많을 수록 Zip List에 비해 탐색 시간이 훨씬 적게 걸림
- forward 포인터, span 값, backward 포인터 등 관리용 데이터로 인해 메모리 오버헤드 발생
- 데이터가 많을 수록 삭제하는 데 시간이 오래 걸림
Command
zadd key score name score name score name...
zrange key start end [withscores] // 오름차순, zrevvrange는 내림차순
zrangebyscore key start end // 해당 범위 내 score를 갖는 데이터
zrem key name // 삭제
zremrangebyscore key start end // 범위 내 score 갖는 데이터 삭제 후 삭제된 개수 출력
zrank key name // 순위 출력Streams
- append-only log 처럼 동작
- 메시징 시스템인 Kafka와 비슷하게 동작, Kafka의 topic은 Redis의 stream과 비슷하게 작동, Producer와 Consumer가 있다.
- append-only log의 한계를 극복했다(ex. O(1) 시간에 random access 가능, consumer group 사용 가능)
- Stream에 entry를 추가하는 것은 O(1), Any entry에 접근하는 것은 O(n)(n은 id 의 길이).
- Stream id는 보통 짧고 고정된 길이이기 때문에, 시간적으로 굉장히 효울적이다.
- Stream이 radix tree로 이뤄졌기 때문에 가능하다.
Commands
xadd key messageId field name field name... // messageId에 * 넣으면 자동 생성, 권장
xrange key start-id end-id [count count-num] // 조회, -는 최소 id, +는 최대 id
xread <count count-num> <block block-num> 구독, streams <key> <start-id> // block으로 blocking 옵션 줄 수 있음
xdel key messageId // 삭제
// Consumer Group
xgroup create key group-name start-id [mkstream] // start-id가 $이면 생성 후 발생한 최신 메시지, 0이면 처음부터 전체 메시지, mkstream을 통해 스트림 없으면 생성 가능
xreadgroup group group-name consimer-name count count-num stream key message-id
xack key group-name message-id // 메시지 처리 완료
xpending key group-name [idle <min-idle-time>] start-id end-id count [consumer-name] // group 별 pending된 메시지 조회, idle 옵션 통해 min-idle-time 지난 메시지 조회
xclaim key group-name consumer-name min-idle-time id-1, id-2, ... // consumer 변경
// Streams 정보 조회
xinfo stream key // stream 정보 조회
xinfo groups key // stream consumer group 정보 조회
xinfo consumers key group-name // consumer group 내 consumer 정보 조회Geospatial
- coordinates를 저장할 수 있게 하고 조회할 수 있게 한다.
- 주어진 지름이나 box 내의 point를 찾는 데 유용하다.
- Sorted Set Data Structure를 사용한다.
Commands
geoadd key longitude latitude name // 추가
GEOSEARCH key <FROMMEMBER member | FROMLONLAT longitude latitude>
<BYRADIUS radius <M | KM | FT | MI> | BYBOX width height <M | KM |
FT | MI>> [ASC | DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST]
[WITHHASH] // radius / box 내의 point 조회Bitmaps
- data type은 아니지만, String 자료구조에서 사용할 수 있는 bit 기반 command 집합이다.
- bit, 즉 0과 1만 갖기 때문에 1000만 건을 입력해도 1.19MB 공간만 차지하는 등 공간 효율성이 좋다.
- 실시간으로 많은 단순 데이터를 쌓는 구조에서 유용하게 쓰인다.
- 가장 큰 유저 ID가 750,000이면서, 이들 참여정보를 담는 경우엔 SET 구조에선 36,583,112 Byte가, Bitmap 구조에선 114,768 Byte가 필요함
- 하지만 모든 상황에 좋은 것은 아님
- 최대 유저 ID가 1,000,000 이면서 대상은 유저 10명일 경우, SET이 효율적임
- 상황에 따라 SET과의 효율성 비교 필요
- 또한 Bitmap 자료 내에서 Bit가 1인 모든 유저의 ID를 구하는 것은 지원하지 않기 때문에, Lua Scripting을 이용해 해결해야 함
Commands
setbit key offset value // 추가
getbit key offset // 해당 offset의 value getBitfields
- arbitrary length를 갖는 정수를 다룰 수 있는 자료형
- 1비트 unsigned int부터 signed 63비트 정수까지 모두 다룰 수 있다.
- binary-encoded Redis String에 저장된다.
- atomic한 read, write, increment를 지원한다.
- counter나 비슷한 정수형 처리에 좋다
- 0-15 사이의 숫자를 많이 저장해야 한다면, 4byte integer보다는 4bit integer를 사용하면 메모리를 많이 절약할 수 있다.
Commands
BITFIELD key [GET encoding offset | [OVERFLOW <WRAP | SAT | FAIL>]
<SET encoding offset value | INCRBY encoding offset increment>
[GET encoding offset | [OVERFLOW <WRAP | SAT | FAIL>]
<SET encoding offset value | INCRBY encoding offset increment>
...]] // get, set, incrby
BITFIELD_RO key [GET encoding offset [GET encoding offset ...]] // Read-OnlyHyperLogLog
- Set의 cardinality를 추정하기 위한 자료구조
- 1퍼센트 미만의 오차를 갖는, 공간 효율성을 극대화한 자료구조
- Redis HLL은 최대 12KB를 차지하며 0.81%의 오차를 갖는다
- 1백만개의 데이터 저장 시 SADD는 8.64s, PFADD는 5.23s(약 1.6배 빠름)
- 조회속도는 O(1)로 SCARD와 비슷
Commands
PFADD key value value ... // unique 값 추가
PFCOUNT key // count 조회
PFMERGE merged_key key key... // 병합
https://github.com/Y-Joo