
Search and query
주요 특징
Secondary Indexing
- 레디스는 기본적으로 primary key access만 제공한다
- 자료구조 서버이기 때문에, 용량을 secondary index를 위해 사용할 수 있다.
- 다음 자료구조에서 동작한다.
- Sorted Sets
- id 혹은 다른 정수형 필드를 이용한 인덱스
- 사전식 정렬 혹은 복합 인덱스와 그래프 순회 인덱스
- Sets
- 랜덤 인덱스
- Lists
- 단순 순회 인덱스와 마지막 N개의 아이템 인덱스
Multi-field queries
Aggregations
- Group과 각 group에 reducer 사용 가능
- 하나 이상의 필드에 대한 정렬
- 문자열이나 수학 함수 사용(선택적으로 새로운 필드를 만들거나 존재하는 필드를 대체하거나)
- Limit
- Filter
Commands
FT.AGGREGATE
{index_name:string}
{query_string:string}
[VERBATIM]
[LOAD {nargs:integer} {property:string} ...]
[GROUPBY
{nargs:integer} {property:string} ...
REDUCE
{FUNC:string}
{nargs:integer} {arg:string} ...
[AS {name:string}]
...
] ...
[SORTBY
{nargs:integer} {string} ...
[MAX {num:integer}] ...
] ...
[APPLY
{EXPR:string}
AS {name:string}
] ...
[FILTER {EXPR:string}] ...
[LIMIT {offset:integer} {num:integer} ] ...
[PARAMS {nargs} {name} {value} ... ]다수 field에 대한 full-text indexing
기능 저하 없는 증분 색인
증분 색인(incremental indexing)이란?
동적 색인(dynamic indexing)이라고도 하며, 전체 색인이 완료된 이후 추가된 데이터에 대한 수집/ 색인을 말한다.
Document ranking
Boolean queries(AND, OR, NOT)
Optional Match query 절
- Optional한 값 리턴 가능
Prefix-based searches
hel* worldField weights
- 필드에 중요성에 따라 weight 부여 가능
Auto-complete과 prefix 제안
정확한 문구 search와 slop-based search
Slop-based search란?
정확한 문구 뿐만 아니라 value만큼의 단어가 추가적으로 들어가있어도 함께 보여주는 방식
형태소 기반 다국어 지원
- hiring을 query 해도 hire,hired 결과 함께 리턴
쿼리 확장과 scoring을 위한 custom function 지원
numeric filter과 range 지원
Geo Filtering 지원
- GEOADD, GEODIST, GEOHASH 등등..
벡터 유사도 검색 지원
Unicode 지원
full document contents 혹은 ID만 조회 가능
document deletion and updating with index garbage collection
- redis에서 delete는 실제 삭제하는것이 아닌, deleted로 표시하는 방식으로 함
- deleted된 데이터의 id는 garbage가 됨
- updating 또한 비슷한 방식. 데이터를 deleted 처리한 후 새 id로 데이터를 추가하는 방식
GC 작동 방식 (이해 잘 안됨..)
- 각 블럭에 대해 reader, writer 생성
- 블럭의 record 하나씩 읽음
- invalid한 record가 없으면 아무것도 안함
- garbage record 찾으면 reader가 advanced됨
- 하나 이상의 garbage record를 찾으면, 다음 record가 writer에 encode되며, delta를 다시 계산함
Redis programmability
- Lua와 Redis Function을 통해 프로그래밍 인터페이스를 제공한다.
- Redis 7 이상에서는 Redis Function을, 6.2 이하에서는 Lua Scripting with Eval command를 사용할 수 있다.
Lua Scripting (Redis 2.6.0~)
EVAL command
- server-side scripts를 돌릴 수 있다
- 반드시 소스 코드를 갖고 있어야 한다.
- script는 서버에만 캐시로 저장되며 휘발성이기 때문이다.
- 이는 어플리케이션이 커질수록 개발과 유지보수를 힘들게 만든다.
> EVAL "return 'Hello, scripting!'" 0
"Hello, scripting!"첫번째 인자는 Lua source code, 두번째 인자는 스크립트에 뒤따르는 인자의 개수, 그 뒤는 전달되는 레디스 키의 개수이다.
Scripting parameterization
redis> EVAL "return ARGV[1]" 0 Hello
"Hello"
redis> EVAL "return ARGV[1]" 0 Parameterization!
"Parameterization!"
redis> EVAL "return { KEYS[1], KEYS[2], ARGV[1], ARGV[2], ARGV[3] }" 2 key1 key2 arg1 arg2 arg3
1) "key1"
2) "key2"
3) "arg1"
4) "arg2"
5) "arg3"ARGV를 통해 받은 인자 사용, KEY를 통해 받은 redis key를 사용할 수 있다. 두번째 인자는 받을 redis key의 개수를 나타낸다.
Interacting with Redis from a script
> EVAL "return redis.call('SET', KEYS[1], ARGV[1])" 1 foo bar
OK- redis.call() 혹은 redis.pcall()을 통해 Redis commands를 호출할 수 있다.
- redis.call(): 런타임 에러가 클라이언트에게 전달됨
- redis.pcall(): 런타임 에러가 스크립트에 전달됨
Script Cache
- EVAL을 사용할 때, 항상 script code를 포함한다.
- 계속해서 같은 코드를 포함하는 것은 비효율적이기 때문에, Redis에서는 script cache를 제공한다.
- EVAL로 실행하는 모든 script는 cache에 저장된다.
- SCRIPT LOAD command와 그 소스 코드를 이용해 SHA1 digest를 얻을 수 있다.
- EVALSHA SHA1 digest를 통해 캐싱된 스크립트를 실행 가능하다.
- Redis Script Cache는 휘발성이기 때문에, 서버 재시작, SCRIPT FLUSH 등 다양한 이유로 언제든 사라질 수 있다.
redis> SCRIPT LOAD "return 'Immabe a cached script'"
"c664a3bf70bd1d45c4284ffebb65a6f2299bfc9f"
redis> EVALSHA c664a3bf70bd1d45c4284ffebb65a6f2299bfc9f 0
"Immabe a cached script"SCRIPT Commands
SCRIPT FLUSH
Redis cache에 저장된 모든 script를 지운다. 보통 Redis instance를 다른 유저에게 할당할 때 유용하다.
SCRIPT EXISTS
SHA1 digests를 인자로 받아 캐시에 존재하는 script인지 아닌지를 1, 0으로 리턴한다
SCRIPT Load script
script를 cache에 등록한다.
SCRIPT KILL
long-running script를 멈춘다.
SCRIPT DEBUG
script를 디버그한다.
Redis Function (Redis 7~)
- script를 어플리케이션과 분리해서 script의 독자적인 개발, 테스팅, 그리고 배포를 가능케 한다.
- function을 사용하기 위해, load만 하면 된다.
atomic execution
- script나 function을 실행하면, 레디스는 원자성을 보장한다.
- 실행동안 서버는 block 된다.
- 트랜잭션과 비슷한 의미를 갖는데, 일어나거나 아무 일도 일어나지 않거나.
- 때문에 느린 스크립트를 사용하려 하면 다른 클라이언트가 모두 block된다는 점을 유의해야 한다.
Loading function
FUNCTION LOAD "#!lua<engine name> name=<library name>"library payload는 Shebang format을 따라야 한다.
Registering function
#!lua name=mylib
redis.register_function(
'knockknock',
function() return 'Who\'s there?' end
)Calling function
redis> FUNCTION LOAD "#!lua name=mylib\nredis.register_function('knockknock', function() return 'Who\\'s there?' end)"
mylib
redis> FCALL knockknock 0
"Who's there?"Read-only scripts
- 말 그대로 Read-only, 어떤 데이터도 수정하지 않음
- script에 no-write flag를 추가하거나, EVAL_RO, EVALSHA_RO, FCALL_RO같은 readonly command를 통해 가능하다
- 다음 특징을 갖는다.
- 복제본에 대해 실행될 수 있다.
- script kill 커맨드에 의해 kill될 수 있다.
- redis가 memory limit을 넘어서도 OOM이 발생하지 않는다.
- write pause동안 block되지 않는다.
- data를 수정하는 어떤 command도 실행할 수 없다
Read-only script history
- Redis 7.0에서 처음 소개됐다.
- Redis 7.0.1 전까지
- PUBLISH, SPUBLISH, PFCOUNT는 write command로 고려되지 않았다.
- no-write flag가 allow-oom을 포함하지 않았다.
- no-write flag가 write pause동안 스크립트 작동을 허용하지 않았다.
Sandboxed script context
- Redis는 user script를 sandbox내에서 실행할 수 있는 엔진을 마련해놨다.
- sandbox는 스크립트 오용과 잠재적 위험으로부터의 서버 보호를 위한 장치로 사용된다.
- script는 redis의 host system(파일 시스테 , 네트워크, 시스템 콜 등)에 절대 접근해서는 안된다.
- script는 redis에 저장된 데이터와 실행 인자로 받은 데이터로만 작동해야 한다.
Maximum execution time
- script는 최대 실행 시간을 갖는다.(default 값은 5초이다.)
- 굉장히 널널한 편인데, script가 보통 1 ms 이내에 종료되기 때문이다. 사실 이 시간은 무한루프를 방지하기 위한 장치라고 보면 된다.
- redis.conf에서 바꾸거나 CONFIG SET 명령어를 통해 바꿀 수 있다. busy-reply-threshold를 변경하면 된다.
Maximum execution time 작동 방식
최대 실행 시간을 넘는다고 Redis가 바로 종료시키는 것이 아니다. 그렇게 하면 데이터셋에 절반만 변화를 주고 멈출 수 있기 때문에, 다음 과정을 거친다.
- script가 너무 오래 실행중이라고 로그를 남긴다.
- command를 받기 시작하나 모든 command에 대해 busy error를 리턴한다. 이 상태에서 허용되는 command는 SCRIPT KILL, FUNCTION KILL, 그리고 SHUTDOWN NOSAVE뿐이다.
- readonly command만 실행한 경우에는 SCRIPT KILL, FUNCTION KILL을 사용할 수 있다.
- 한번이라도 write를 수행한 경우에는 SHUTDOWN NOSAVE만 가능하다. (SHUTDOWN NOSAVE는 현재 데이터를 저장하지 않고 서버를 멈추는 키워드이다.)
Transactions
- Redis Transactions는 command들이 single step으로 실행되도록 한다.
- 이는 MULTI, EXEC, DISCARD, WATCH 등의 command를 통해 이루어진다.
- 두가지를 보장한다.
- transaction 내에서 모든 command는 복호화되고 순서대로 작동한다. 다른 클라이언트의 요청이 절대 실행 중간에 실행되지 않는다.
- EXEC command가 transaction 내의 모든 command 실행을 촉발하기 때문에, EXEC command 실행 전 서버와의 연결이 끊기면 아무 명령도 실행되지 않고, EXEC command를 실행한다면 모든 명령이 실행된다. append-only file을 사용하면 redis는 single write syscall을 사용해 디스크에 transaction을 쓰는데, 이 경우 조금 어려운 일이지만 서버가 crash나거나 kill될 경우 일부 명령만 등록될 수 있다. 레디스는 재시작 시에 이를 인지하고, 에러를 내며 종료한다. redis-check-aof tool을 사용하면 기록된 일부 transaction을 제거하고, 재시작할 수 있다
Commands
> MULTI // Transaction 진입, 항상 ok를 응답한다.
OK
> INCR foo // 명령이 바로 수행되는 것이 아닌 queue에 쌓인다. QUEUED 응답을 받는다.
QUEUED
> INCR bar
QUEUED
> EXEC // queue에 쌓인 모든 명령이 수행된다. 응답이 배열로 반환된다.
1) (integer) 1
2) (integer) 1
> DISCARD // transaction 탈출, 아무 명령도 수행되지 않는다.Error inside a transaction
두가지 방식의 에러를 만날 수 있다.
- queue에 넣는 과정에서 에러 발생
- EXEC 호출 전 에러가 나는 경우이다. syntax적으로 잘못됐거나(인자 개수가 잘못됐거나, command name이 잘못됐거나 등등,,), critical condition 문제가 있거나(OOM 등)
- EXEC 실행 후 에러 발생
- key에 대해 잘못된 명령을 실행하는 경우(string value에 list operation 사용 등..)
Redis 2.6.5부터, command를 accumulate하는 과정에서 에러를 감지한다.
2.6.5 전에는 반환값이 QUEUED인지 error인지 클라이언트가 확인 후, 에러가 났다면 transaction을 discard하는 방식으로 했다고 한다.
MULTI
+OK
INCR a b c
-ERR wrong number of arguments for 'incr' commandEXEC 이후 발생하는 에러는 따로 처리되지 않는다. 몇몇 command가 fail한다고 해도, 다른 모든 명령은 정상적으로 실행된다. command가 실패하더라도, 멈추지 않는다.
MULTI
+OK
SET a abc
+QUEUED
LPOP a
+QUEUED
EXEC
*2
+OK
-WRONGTYPE Operation against a key holding the wrong kind of valueRollback
Redis는 Rollback을 지원하지 않는다. Rollback을 지원하는 것은 Redis의 단순함과 성능에 엄청난 영향이 있기 때문이다.
Optimistic locking using check-and-set
- WATCH command는 check-and-set(CAS)를 제공하는데 사용된다.
- WATCH된 key가 EXEC 전에 변경되면, 해당 transaction은 abort되고 EXEC은 transaction이 실패했다는 것을 알려주기 위해 null을 응답한다.
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC위 상황에서, WATCH와 EXEC 사이에 다른 client에 의해 mykey가 변경된다면 transaction은 abort된다.
- 몇개의 key든 상관없이 WATCH할 수 있다.
- EXEC이 실행되거나 client connection이 종료되면, 모든 키는 UNWATCH 된다.
- UNWATCH command를 통해 모든 key를 UNWATCH할 수도 있다.
Redis Pub/Sub
SUBSCRIBE, UNSUBSCRIBE, 그리고 PUBLISH는 Publish/Subscribe messaging paradigm을 따른다.
senders(publishers)는 receivers(subscribers)에게 직접 message를 보내는 것이 아닌 channels에 publish한다. 당연히 publishers는 누가 message를 읽을 지 모르고, Subscribers는 하나 이상의 channel에 interest를 표시하고 해당 channel의 message를 받을 수 있다. 이런 식의 publisher과 subscriber의 분리는 scalable하고 dynamic하게 네트워크를 구성할 수 있게 해준다.
Commands
// SUBSCTIBE
SUBSCRIBE channel_name channel_name ... // 채널 subscribe
PSUBSCRIBE pattern pattern ... // 패턴에 해당하는 채널 subscribe
// UNSUBSCRIBE
UNSUBSCRIBE channel_name channel_name ... // 채널 unsubscribe, channel_name 안쓰면 모든 채널 unsubscribe
PUNSUBSCRIBE pattern pattern ... // 패턴에 해당하는 채널 unsubscribe, pattern 안쓰면 모든 채널 unsubscribe
// PUBLISH
PUBLISH channel_name message // message를 channel로 보냄
// PUBSUB
PUBSUB channels pattern // pattern에 해당하는 channel 조회, 비워두면 모든 channel 조회
PUBSUB numsub channel_name channel_name ... // 각 channel에 등록된 client 개수 조회
PUBSUB numpat // 서버에 등록된 pattern 개수 조회Protocol에 따른 차이
RESP2 Client는 Subscribe 상태에서 다른 channel을 subscribe하거나 unsubscribe하는 command밖에 실행하지 못한다. 하지만 RESP3에서는 어떤 command라도 실행할 수 있다.
Message Format
message는 3개의 element로 구성된 array형식이다.
- 첫번째 element는 message의 종류를 나타낸다.
- subscribe: 두번째 element인 channel에 성공적으로 subscribe했음을 나타냄. 세번쩨 element는 현재 subscribe중인 channel의 수를 보여준다.
- unsubscribe: 두번째 element인 channel에 성공적으로 unsubscribe했음을 나타냄. 세번쩨 element는 현재 subscribe중인 channel의 수를 보여준다. 세번째 element가 0이라면, 더는 구독중인 상태가 아니기 때문에 어떤 redis command든 입력할 수 있는 상태가 된다.
- message: 다른 client의 publish를 통해 받는 message를 의미한다. 두번째 element는 channel 이름, 세번째 element는 실제 message를 보여준다.
Sharded Pub/Sub
Redis 7.0부터 지원하는 방식이다.
Redis Cluster에서의 Pub/Sub 문제점
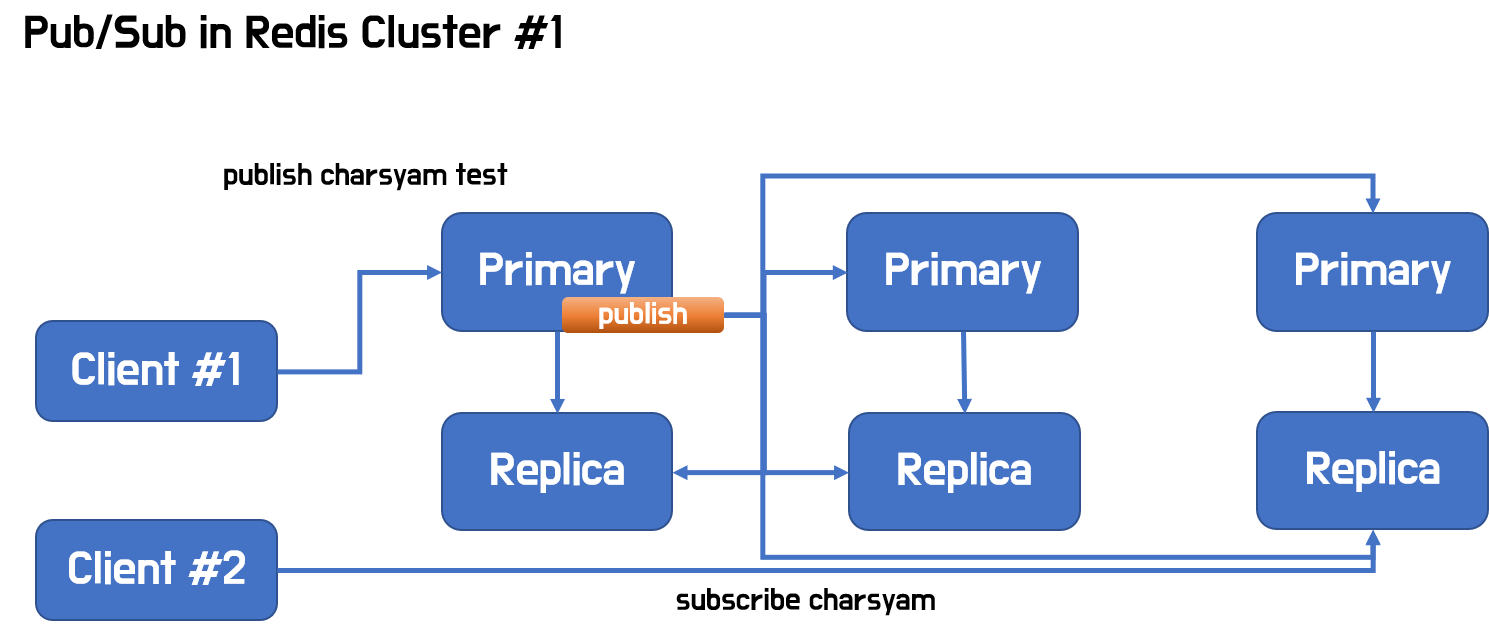
- Redis Cluster에서 Pub/Sub은 모든 노드에 데이터를 뿌리게 됨
- 한대의 서버에 publish하면 해당 노드는 모든 노드에 publish를 broadcast하게 됨
- 항상 broadcast하는 것이 문제가 됨
Sharded Pub/Sub은?
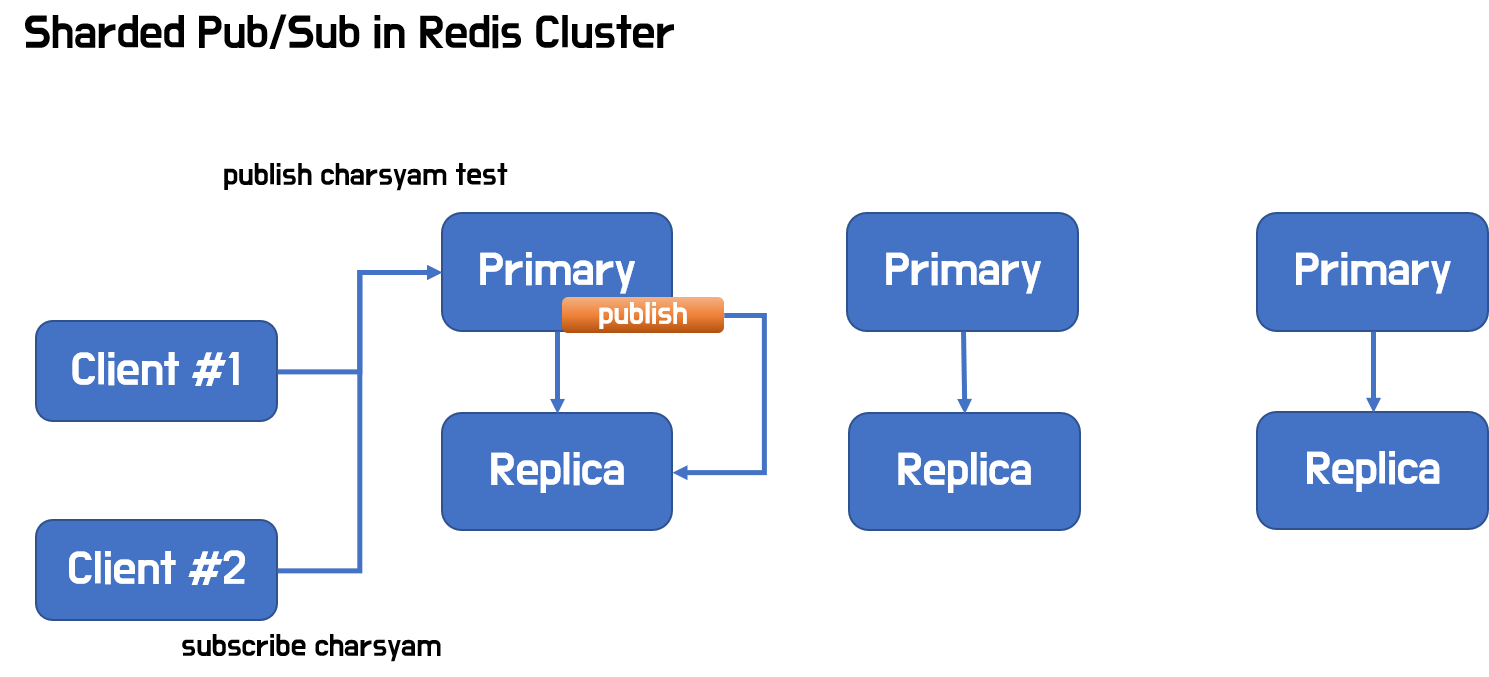
- key를 crc16으로 hash해서 해당 키가 속한 slot을 처리하는 서버로만 메시지를 전달한다.
- client는 primary 혹은 그 replicas 중 하나에 연결함으로써 메시지를 받을 수 있다.
- Redis cluster의 Pub/Sub에서 일어나던 노드간의 전파가 일어나지 않기에, horizontal하게 scale을 올릴 수 있게 해준다.
