
High availability with Redis Sentinel
What is Redis Sentinel?
- Redis Cluster과는 다른 운영방식
기능
- Monitoring
- 마스터와 복제본이 제대로 작동하는지 지속적 모니터링 - Notification
- 문제가 생길 시 시스템 운영자나 다른 컴퓨터 프로그램에 알린다 - Automatic failover
- 마스터에 문제가 생기면, 다른 복제본이 마스터로 승격되고, 그 외 복제본들은 새로운 마스터의 복제본으로 reconfigure되는 failover 과정을 진행한다. - Configuration provider
- 클라이언트가 현재 마스터 주소를 묻는 provider 역할을 한다.
Sentinel은 분산 시스템이다.
여러 sentinel이 협력해 작동하도록 설계돼있다. 장점은 다음과 같다.
- 장애 판단은 여러 sentinel의 동의 하에 결정된다. 이는 잘못된 판단 확률을 낮춘다.
- 하나의 sentinel에 장애가 발생하더라도, sentinel 시스템은 계속해서 장애를 감지할 수 있다.
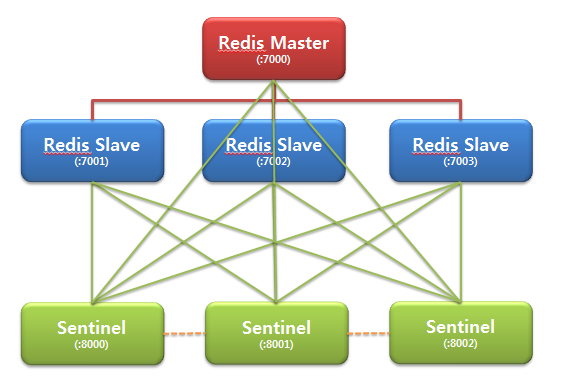
Running Sentinel
다음 커맨드로 실행 가능하다.
redis-sentinel /path/to/sentinel.conf아니면 다음 커맨드로 redis server 시작 시에 모드 설정도 가능하다.
redis-server /path/to/sentinel.conf --sentinel- configuration file은 필수적이다.
- 기본적으로 26379 port를 사용한다.
배포 전 유의해야 할 사항
- 최소 3개의 sentinel instance가 필요하다
- 인스턴스는 독립적인 방법으로 장애가 발생해야 한다.
- 레디스는 비동기 복제를 사용하기 때문에, 데이터 유실 가능성이 있다.
- 클라이언트에 Sentinel support가 필요하다. 대부분 클라이언트 라이브러리가 갖고 있으나, 전부는 아니다.
- 테스트가 필요하다
- sentinel이나 docker나 다른 양식의 Network Address Translation or Port Mapping은 주의가 필요하다 - Sentinel, Docker, NAT, and possible issues
Configuring Sentinel
sentinel.conf은 다음과 같이 작성될 수 있ㄷ .
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5- 감시할 마스터를 지정하고, 각각 다른 이름을 준다.
- 복제본은 알아서 찾아준다.
- 복제본이 마스터로 승격하거나, 새로운 sentinel이 등장할때마다 rewrite된다.
- 위 예시에서는 두개의 마스터와 각각의 정의되지 않은 개수의 복제본을 모니터링한다.(mymaster, resque가 각각의 이름이 된다)
sentinel monitor <master-name> <ip> <port> <quorum>quorom은 해당 마스터가 장애라고 판단하는데 필요한 동의의 개수이다.- quorom은 장애를 감지하는데만 사용된다. 실제 조치는 한 sentinel이 리더로 선정돼 진행한다.
- 예를 들어 5개의 Sentinel process를 갖고 있고, quorom이 2라면 다음과 같이 작동한다.
- 두개의 Sentinel이 장애라고 판단하면 둘중 하나가 장애 조치를 시도한다.- 최소 3개 이상의 Sentinel이 reachable하면, 장애 조치를 시작한다.
Other Sentinel Options
sentinel <option_name> <master_name> <option_value>down-after-milliseconds: 인스턴스가 장애가 났다고 판단하는데 필요한 시간(millisec)parrallel-syncs: 동시에 동기화 가능한 복제본의 개수. 장애 조치 시 걸리는 시간에 영향을 끼친다(반비례)
Example Sentinel deployment
Example 1: just two box: Don't do this
+----+ +----+
| M1 |---------| R1 |
| S1 | | S2 |
+----+ +----+
Configuration: quorum = 1- M1에 장애가 생기면, S1도 작동하지 않기 때문에 장애 조치가 작동하지 않는다.(대부분의 sentinel이 reachable해야 함)
- 때문에 반드시 3개 이상의 Sentinel(in diffrent box)로 구성해야 함
Example 2: basic setup with three box
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
Configuration: quorum = 2- 장애 조치는 정상 작동한다.
- 하지만 다음 경우에 문제가 있다.
+----+
| M1 |
| S1 | <- C1 (writes will be lost)
+----+
|
/
/
+------+ | +----+
| [M2] |----+----| R3 |
| S2 | | S3 |
+------+ +----+- 위 M1에 장애가 생기면, C1이 write한 데이터가 유실된다
- 다음 커맨드로 해결 가능하다.
min-replicas-to-write 1
min-replicas-max-lag 10- 하나의 복제본에도 write할 수 없으면, write를 더이상 accept하지 않는다.
- max-leg second를 넘으면, write할 수 없는 것으로 판단한다.
- 하지만 이 또한 단점이 있는데, 두 복제본이 모두 stop하면 write할 수 있는 복제본이 없기 때문에 마스터는 작동중임에도 write를 accept하지 못한다.
Example 3: Sentinel in the client box
+----+ +----+
| M1 |----+----| R1 |
| | | | |
+----+ | +----+
|
+------------+------------+
| | |
| | |
+----+ +----+ +----+
| C1 | | C2 | | C3 |
| S1 | | S2 | | S3 |
+----+ +----+ +----+
Configuration: quorum = 2- 레디스 box가 2개밖에 없을 경우, Example 2를 사용하지 못한다.(3개 이상의 Sentinel을 사용할 수 없으므로)
- 이때는 클라이언트 box에 Sentinel을 두는 식으로 할 수 있다.
- 클라이언트와 서버 사이 연결이 끊기면, 마스터나 복제본에 reach하지 못하는 문제가 있다.
Example 4: Example 3 with less than three clients
+----+ +----+
| M1 |----+----| R1 |
| S1 | | | S2 |
+----+ | +----+
|
+------+-----+
| |
| |
+----+ +----+
| C1 | | C2 |
| S3 | | S4 |
+----+ +----+
Configuration: quorum = 3- Example 3과 비슷하지만, 클라이언트가 3개 이하인 경우 위와 같이 구성할 수도 있다.
- C2와 S4가 돌아가는box가 삭제되면, quorom이 2로 재조정돼야 한다.
Sentinel API
- Sentinel은 상태 체크, 모니터링중인 마스터와 복제본의 health 체크, 알림에 대한 구독이나 런타임 중 configuration 변경을 위한 api를 제공한다.
- redis-cli나 다른 redis client를 이용해 소통 가능하다.
- 직접 접근할 수도 있고, Pub/Sub을 활용해 push style notification을 받을 수도 있다.
SENTINEL명령어를 사용할 수 있다.- 명령어 목록
Pub/Sub messages
- 클라이언트는
SUBSCRIBE나PSUBSCRIBE를 통해 특정 채널에 대한 메세지를 수신할 수 있다.(PUBLISH는 불가능하다)
Replicas priority
- 모든 레디스 인스턴스는
replica-priority파라미터를 갖고 있다. - Sentinel은 이 파라미터를 활용해 장애조치 시 어떤 파라미터를 마스터로 승격시킬 지 결정한다.
- replica-priority가 0이라면 절대 마스터로 승격되지 않는다- 숫자가 낮을수록 우선권이 높다.
Sentinels and replicas auto discovory
- Sentinel은 서로 다른 Sentinel과 항상 연결되어 메시지를 주고 받고, 상태를 체크한다.
-__seltinel__:hello라는 채널에 메시지를 전송하는 방식으로 이루어진다.
- 모든 Sentinel은 2초마다 모니터링중인 모든 마스터와 복제본에 메시지를 전송한다.
- 모든 Sentinel은 자신이 모니터링중인 모든 마스터와 복제본의__seltinel__:hello채널을 구독한다.
- configuration이 예전 버전이라면 업데이트도 동시에 진행한다.
Replica selection and priority
- 마스터가
ODOWN상태가 되고 장애 조치를 할 준비가 되면, replica selection process가 진행된다. - 복제본에 대해 다음을 체크한다.
- 마스터로부터 disconnection time- 우선권
- replication offset processed (복제 정도)
- run id
- disconnection time이 다음 값보다 크다면, 승격하지 않는다.
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state- 이 과정을 먼저 거친 후, 통과한 replica에 대해 다음 과정을 거친다.
- 우선권 순으로 오름차순 정렬한다.
- 우선권이 같다면, 복제 정도가 더 높은 복제본, 즉 마스터로부터 더 많은 데이터를 받은 복제본이 우선권을 갖는다.
- 우선권과 복제 정도가 모두 같다면, run ID를 사전식 정렬해 더 작은 ID를 갖는 복제본이 선택된다.
Redis replication
- Redis Replication은 레디스 인스턴스가 마스터 인스턴스의 정확한 복제본이 될 수 있게 한다.
- 복제본은 연결이 끊기더라도 자동으로 다시 연결하고, 마스터에 어떤 변화가 생기더라도 정확한 복제본이 되려고 시도한다.
- 다음 세가지 메커니즘을 통해 작동한다.
1. 마스터와 복제본이 잘 연결돼있다면, 마스터는 마스터에 생긴 변화를 커맨드 스트림으로 복제본에 전송한다.- 마스터와 복제본 사이 연결이 끊어지면, 복제본은 재연결하고 부분적 재 동기화를 진행한다: 끊겼던 기간의 커맨드 스트림만 다시 받아온다.
- 부분적 재동기화가 불가능하면, 복제본은 전체 재동기화를 요청한다. 이는 다소 복잡한 과정으로 진행되는데, 마스터가 데이터 스냅샷을 생성하고, 복제본으로 전송하고, 데이터가 변경될때마다 계속해서 커맨드 스트림을 전송해야 한다.
- 레디스는 기본적으로 낮은 지연률과 높은 성능을 갖는 비동기 복제를 사용한다. 하지만 어떤 복제본이 어떤 커맨드를 수행했는지 알고 싶을 때, 선택적으로 동기 복제를 사용할 수 있다.
-WAIT커맨드를 사용하여 가능하다.- 장애조치 시의 write 유실을 완전히 방지하지 못하지만, 확률을 엄청나게 낮춘다.
Important facts about Redis replication
- 레디스는 비동기 복제를 사용한다.
- 한 마스터는 여러 복제본을 가질 수 있다.
- 복제본은 다른 복제본으로부터의 연결을 허용할 수 있다. Redis 4.0부터, 모든 sub replica는 마스터가 보내는 커맨드 스트림을 그대로 받는다.
- 복제는 마스터 인스턴스에서 non-blocking하다. 복제본이 동기화를 진행하는 과정에서도, 마스터는 계속해서 작업을 수행한다.
- 복제는 복제본 인스턴스에서도 non-blocking하다.
- 동기화중에도, 이전 데이터셋을 활용해 쿼리를 처리할 수 있다.(redis.conf에서 그렇게 지정했다면).- 그렇지 않다면, 에러를 반환하게도 가능하다.
- 하지만, 동기화를 마친 후 예전 데이터셋을 삭제하고 새 데이터셋으로 대체하는 과정에서는 모든 연결을 차단한다.
- Redis 4.0 이후에, 예전 데이터셋을 삭제하는것은 다른 스레드에서 동작하지만, 새 데이터셋으로 대체하는 것은 여전히 blocking하다.
- Replication은 scalability를 위해서도 사용될 수 있고, 단순히 데이터 안전성이나 높은 가용성을 위해서도 사용 가능하다.
- 모든 데이터셋을 디스크에 저장하는 것을 피하기 위해 사용할 수 있다. 하지만 마스터를 재시작할 시 빈 데이터셋으로 구동되고, 복제본이 이를 동기화하면 저장된 데이터셋이 유실되기에 주의해야 한다.
How Redis replication works
- 모든 레디스 마스터는 복제본 id와 발행한 커맨드 스트림 바이트를 의미하는 offset을 갖고, 이를 통해 복제본의 상태를 업데이트한다.
- 복제본 id와 offset 쌍은 데이터셋의 버전으로 사용될 수 있다.
- 복제본이 PSYNC를 통해 마스터에 접근하면, 복제본 id와 offset을 전달한다.
- 마스터에서는 받은 값을 보고, 추가된 부분만 전달하면 된다.
- 마스터에 충분한 backlog가 없거나, 받은 복제본 id가 더이상 알 수 없는 값이면, 전체 재동기화가 이뤄진다.
- 전체 재동기화는 다음 과정으로 이뤄진다.
- 마스터는 RDB 파일을 생성한다. 동시에, 새로 들어오는 모든 write를 버퍼에 저장한다.- 파일 생성이 완료되면, 복제본으로 전달한다.
- 복제본에서 해당 파일 저장과 메모리 로드를 진행한다.
- 마스터 버퍼에 저장된 새로운 변경 사항을 복제본에 전송한다. 이는 커맨드 스트림을 복제본에 전송하는 것과 같은 방식으로 이뤄진다.
- 마스터가 여러 건의 동기화 요청을 한번에 받아도, 한번의 RDB 파일 생성만 이뤄진다.
Redis ID Explained
- 두 인스턴스가 같은 id, 같은 offset을 갖고 있다면, 둘은 동일한 데이터셋을 갖는다고 볼 수 있다.
- 인스턴스는 사실 두개의 replication id를 갖는다: main ID와 secondary ID
- 복제본이 마스터로 승격될 때 필요하다.- 복제본이 마스터로 승격되면 새로운 id가 생성되고, 다른 복제본들은 해당 id를 이용하게 된다.
- 하지만 이전 마스터의 데이터셋이 필요한 상황이 생기면, 이전 마스터의 id를 이용해야 한다.
- 이를 위해 두개의 id를 갖고 있어야 한다.
Read-only replica
- Redis 2.6부터 기본적으로 read-only 모드를 지원한다.
- redis.conf에서
replica-read-only옵션을 통해 변경할 수 있다. - 읽기 전용 복제본은 모든 write 커맨드를 거부한다.
- 복제본에 write를 하게 되면, 마스터와의 정합성이 깨지기 때문에 권장되지 않는다.
- 리스크를 줄이기 위해, writable한 복제본을 사용하기 위해서는 다음을 지키는 것이 좋다.
- 마스터에서 사용하는 키에 write하지 않는다.- 마스터로 승격될 여지가 있는 복제본을 writable하게 지정하지 않는다.
- 역사적으로 보면 writable한 복제본을 사용하는 것이 허용되는 사례가 있었으나, Redis 7.0에서는 다른 방법으로 달성이 가능하기에 쓸모없어졌다.
- 느린 Set이나 Sorted Set operation을 사용하는 경우. ex) SUNIONSTORE, ZINTERSTORE.- -> 저장하지 않고 반환하는 함수를 사용하면 된다. ex) SUNION, ZINTER
- SORT 커맨드를 사용하는 경우
- -> SORT_R0를 사용하면 된다.
- EVAL, EVALSHA를 사용하는 경우
- -> EVAL_R0, EVALSHA_R0을 사용하면 된다.
Allow writes only with N attatched replicas
- Redis 2.8부터, 적어도 n개의 복제본이 연결돼있어야 write를 할 수 있게 설정할 수 있다.
- 하지만 레디스는 비동기 복제를 사용하기 때문에, 복제본이 실제 그 write를 했는지 확인할 수 없고, 데이터 유실이 발생할 수 있다.
- 다음 과정으로 write가 가능한지 판단한다.
- 복제본이 매초 마스터에 진행한 스트림의 양을 핑으로 알려준다.- 마스터는 지난번 모든 복제본으로부터 받은 핑을 기억한다.
- 유저는 지연이 maximum second보다 작은 복제본의 최소 개수를 정할 수 있다.
- 복제본이 n개 이상이라면, write를 진행할 수 있다.
- 아래 옵션을 조정할 수 있다.
-min-replicas-to-write: number of replicasmin-replicas-max-lag: number of seconds
How Redis replication deals with expires on keys
- 레디스는 키에 TTL을 설정해 만료되게 할 수 있고, 복제본도 이를 반영할 수 있어야 한다.
- 마스터와 복제본이 동기화된 시계를 갖는 것은 해결할 수 없는 문제이기에, 다음 기법으로 반영한다.
1. 복제본은 키를 만료시키지 않는다. 마스터에서 키를 만료시키면, 모든 복제본에 DEL 커맨드를 수행하도록 보낸다.- 이는 master-driven expire이기 때문에, 모종의 이유로 복제본 메모리에 키가 남아있을 수 있다. 이에 대응하기 위해, 복제본은 논리적 시계를 이용해 데이터셋 정합성을 훼손하지 않는 읽기 작업에 한해서 키가 존재하지 않는다고 리포트할 수 있다.
- Lua Script 실행 도중에는 어떤 키 만료도 실행되지 않는다. Lua Script 실행중에는 마스터가 frozen된 상태이기 때문에, 스크립트 도중에 키는 존재하거나 존재하지 않거나 둘중 하나의 상태만 유지한다. 중간에 바뀌지 않는다.

https://github.com/Y-Joo