
Keyspace
- Redis에서 키를 관리하는 방법
- 키 유효시간
- 스캐닝
- altering
- qurying
- binary safe하기 때문에, 어떤 binary sequence던 키로 사용할 수 있다(빈 문자열 포함)
키 규칙
- 매우 긴 키는 좋지 않다. 큰 값 매칭이 필요하다면 해싱하는 것이 좋은 대안이다.
- 메모리 관점
- 키를 비교하는 비용 관점
- 매우 짧은 키 또한 종종 좋은 방법이 아니다.
- 가독성 측면
- ex) user:1000:followers를 u1000flw로 줄이는 것은 메모리를 아주 조금 줄여줄 뿐이다
- 스키마 형태로 작성하는 것을 권장한다.
- ex) object-type:id 형태(user:1000)
- .이나 -를 사용해 multi-word field를 작성할 수 있다
- 최대 키 사이즈는 512MB이다
Altering and querying the key space
EXISTS
- 존재하는지 안하는지 1, 0으로 반환
DEL
- 삭제를 성공했는지 못했는지 1, 0으로 반환
TYPE
- type을 반환, 없으면 none 반환
Key expiration
- 키에 대한 TTL(Time To Live)를 설정할 수 있다
- second, millisecond로 설정할 수 있다
- expire 정보는 redis에 저장된다
Commands
> set key some-value
OK
> expire key 5 // 만료시간 5초로 설정
(integer) 1
> get key (immediately)
"some-value"
> get key (after some time)
(nil)
persist key // 만료시간 삭제 후 영구적으로 남아있게 함
> set key 100 ex 10 // 생성과 동시에 만료시간 설정
OK
> ttl key // 만료시간 조회
(integer) 9Navigating the keyspace
SCAN
- Redis database를 incrementally iterate하기 위해서 Scan을 사용할 수 있다.
- Incremental iteration: 한번의 호출 당 작은 수의 엘리먼트만 반환한다.
- 때문에 KEYS나 SMEMBERS같이 server를 block하는 커맨드들의 단점 없이 사용 가능하다.
- SMEMBERS는 호출된 시점의 모든 엘리먼트를 반환할 수 있는 반면, SCAN은 iterate 도중 element가 증가할 가능성이 있기 때문에 해당 시점의 모든 엘리먼트라는 보장이 불가능하다.
KEYS
- Keys 또한 keyspace를 순회할 수 있는 방법이지만, 모든 키가 반환될때까지 레디스 서버를 block하므로 주의가 필요하다.
Client-side caching in Redis
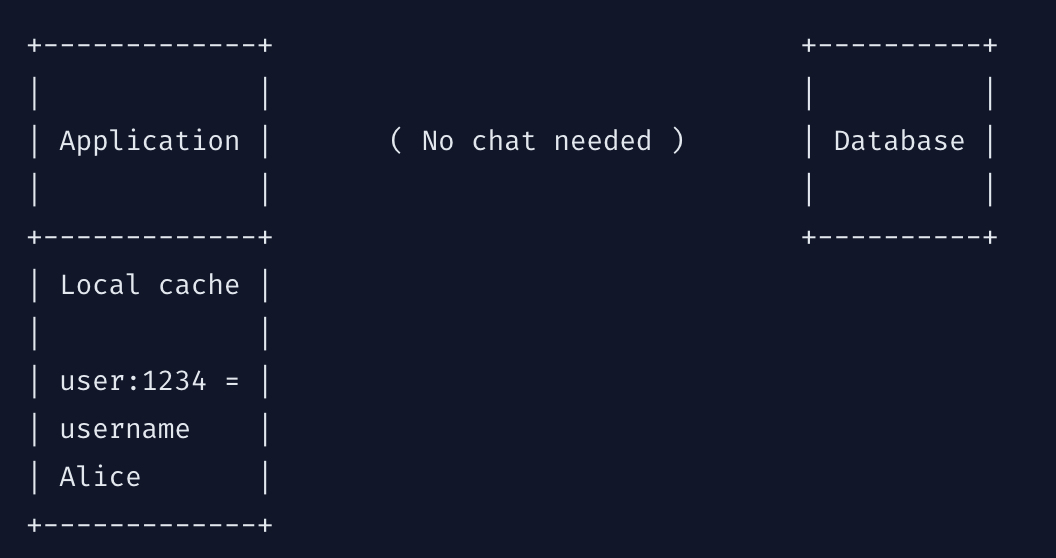
- application server의 가용 메모리에 캐싱하는 방법
- local cache를 위해 사용하는 메모리는 적으나, 데이터베이스와 통신하는 시간을 비약적으로 줄여준다.
- 데이터 변경 확률이 적은 엘리먼트에 더욱 효과적이다.
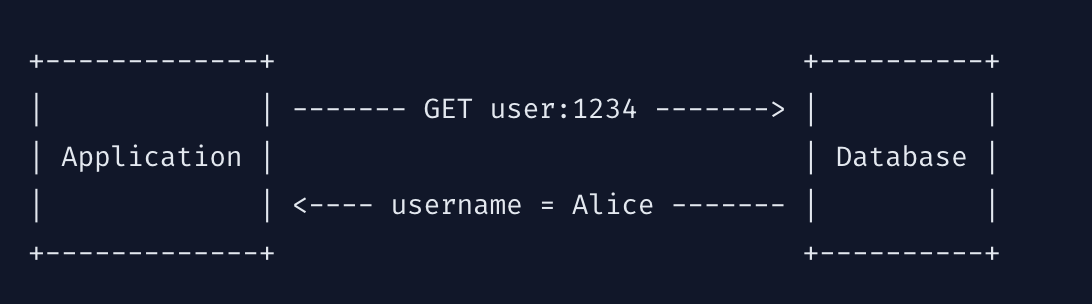
client caching이 없는 경우
client caching을 사용하는 경우
문제점
데이터 동기화
- 정보가 업데이트할 경우, 캐싱된 정보를 삭제하고 새로운 정보를 캐싱하는 과정이 필요하다.
- 단순하게 ttl을 설정해주는 방식
- Redis Pub/Sub을 활용해 정보 업데이트 시 client에 메시지를 보내는 방식
- 모든 클라이언트에게 메시지를 보내기 때문에, CPU나 bandwith 관점에서 비효율적이다.
- 클라이언트에 이미 키가 expire됐을 수 있다.
The Redis implementation of client-side caching
- 레디스 client-side 캐싱은 Tracking이라고 하며, 두가지 모드가 있다.
- default mode: 어떤 키를 클라이언트가 접근했는지 기억하고, 키가 수정되면 invalidation 메시지를 보낸다. 서버 메모리를 사용하지만, 클라이언트의 메모리에 존재하는 키만 취급한다.
- broadcasting mode: 서버가 기억하는 방식이 아닌, 클라이언트가 해당 키를 subscribe하는 방식(prefix를 사용한다. ex. object:, user:,,,). 서버 메모리를 사용하지 않는다.
Default mode
- 클라이언트가 원할 시에 tracking을 활성화할 수 있다.
- connection lifetime동안 서버는 클라이언트가 요청한 키를 저장한다.
- 키가 변경되거나, 만료되거나, maxmemory policy로 인해 제거될 경우 해당 키를 캐싱한 모든 클라이언트는 invalidation 메시지를 받는다.
- 메시지를 받으면 해당 키를 삭제한다.
문제점
서버가 너무 많은 정보를 저장할 수 있다.
Redis implementation에서의 해결
- invalidation table이라고 불라는 global taable로 키를 관리한다.
- entry의 maximum number를 설정한다.
- 새로운 entry가 들어왔는데 maximum number를 넘을 경우, 오래된 키를 수정됐다고 처리하고(아닐지라도) 제거한다.
- database number를 포함하지 않고 key namespace만 저장하기 때문에, database 2에 캐싱한 키가 database 3에서 수정되더라도 invalidation message가 전송된다.
Two connection mode
- RESP3부터, 한 connection 안에서 data query를 실행하고 메시지를 받는 것을 동시에 할 수 있다.
- 하지만 클라이언트는 두개의 connection으로 분리하기를 원한다: 하나는 data, 다른 하나는 invalidation message
- tracking을 활성화할 때, invalidation message를 다른 connection으로 redirect하는 방식으로 구현할 수 있다.
Commands
CLIENT ID // invalidation message를 위한 커넥션 생성
:4
SUBSCRIBE __redis__:invalidate // invalidate 구독
*3
$9
subscribe
$20
__redis__:invalidate
:1// Tracking
CLIENT TRACKING on REDIRECT 4
+OK
GET foo
$3
barOpt-in caching
- 클라이언트가 선택된 키만 캐싱할 수 있는 기능이다.
CLIENT TRACKING on REDIRECT 1234 OPTIN- 클라이언트는 기본적으로 모든 키를 캐싱하지 않는다.
- 캐싱하고 싶으면, 값을 얻기 전에 특정 커맨드를 입력한다.
CLIENT CACHING YES
+OK
GET foo
"bar"- 다음 커맨드가 MULTI거나 Lua Script라면, 해당 트랜잭션/스크립트에 포함되는 모든 커맨드가 tracking된다.
Broadcasting mode
- 서버 메모리를 사용하지 않는 대신 더 많은 메시지를 보내는 방식
- BCAST option을 활용해 캐싱할 수 있다
CLIENT TRACKING on REDIRECT 10 BCAST PREFIX object: PREFIX user:Redis pipelining
- 레디스 커맨드를 batch해서 RTT(round-trip time)을 최적화하는 방법
- RTT란, 클라이언트에서 서버, 다시 서버에서 클라이언트로 돌아오는 시간을 의미한다.
- Redis pipelining은 클라이언트가 응답을 읽지 않았더라도 새 요청을 처리하는 방식으로 구현된다.
netcat
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG위와 같은 방식으로 호출하면 3개의 커맨드를 한번의 RTT로 실행한다.
RTT 뿐만 아니라 분당 처리 쿼리 수 또한 증가한다.
pipelining을 사용하게 되면, 여러 건의 커맨드를 하나의 read로 읽고, 여러 건의 응답을 한번의 write로 처리하게 된다. 이로 인해 분당 처리할 수 있는 쿼리의 수가 pipelining을 사용하지 않았을 때보다 10배 가까이 증가한다.
Redis keyspace notifications
- 클라이언트가 레디스 데이터에 영상을 미치는 이벤트에 대한 알림을 받을 수 있게 subscribe할 수 있게 한다.
- subscribe한 클라이언트가 연결이 끊어지면, 그 시간동안 받은 이벤트는 사라진다.
- 받는 이벤트 예시는 아래와 같다
- 키에 영향을 주는 모든 커맨드
- LPUSH한 모든 키
- database 0에서 만료된 모든 키
Type of events
PUBLISH __keyspace@0__:mykey del
PUBLISH __keyevent@0__:del mykey-
첫번째 채널은 mykey에 대한 모든 변화에 대한 알림을 받는다
-
두번째 채널은 mykey delete에 대한 알림만 받는다
-
첫번째 방식을 Key-space notification이라고 하며,
-
두번째 방식을 Key-event notification이라고 한다.
Configuration
redis.conf의 notify-keyspace-events나 CONFIG SET을 통해 활성화할 수 있다.
K Keyspace events, published with __keyspace@<db>__ prefix.
E Keyevent events, published with __keyevent@<db>__ prefix.
g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ...
$ String commands
l List commands
s Set commands
h Hash commands
z Sorted set commands
t Stream commands
d Module key type events
x Expired events (events generated every time a key expires)
e Evicted events (events generated when a key is evicted for maxmemory)
m Key miss events (events generated when a key that doesn't exist is accessed)
n New key events (Note: not included in the 'A' class)
A Alias for "g$lshztxed", so that the "AKE" string means all the events except "m" and "n".- K나 E는 적어도 하나 들어가야 한다.
- KEA를 사용하면 대부분의 이벤트를 활성화할 수 있다.
- 인자가 없으면 알림이 비활성화된다.
Timing of expired events
- TTL 관련 만료 이벤트는 두가지 경우에 발생한다
- command에 의해 키에 접근했는데 만료된 경우
- 만료된 키를 수집하는 백그라운드에 의해 수집되는 경우(한번도 접근하지 않는 키 또한 함께 수집한다)
- 때문에 어떤 command도 키에 접근하지 않는 경우, 그리고 많은 키가 TTL을 갖는 경우 실제 만료된 시간과 만료 이벤트가 발생하는 시간에 상당한 딜레이가 있을 수 있다.
Redis programming patterns
Bulk loading
- Bulk loading에 일반적인 클라이언트를 사용하는건 좋은 방법이 아니다
- RTT가 매 command마다 들기 때문
- 권장되는 방식은 다음과 같다
- 먼저 insert 커맨드를 담은 text format을 담는다
SET Key0 Value0 SET Key1 Value1 ... SET KeyN ValueN- 그 후 처리하는 방식은 과거에는 netcat을 사용했지만, 모든 데이터가 처리됐는지 알 수 없고 에러를 체크할 수없어서 2.6버전부터는 redis-cli의 pipe mode를 사용한다.
cat data.txt | redis-cli --pipe- 결과는 아래와 같이 나온다
All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 1000000
Generating Redis Protocol
- 다음과 같은 방식으로 레디스 프로토콜을 만들 수 있다
*<args><cr><lf>
$<len><cr><lf>
<arg0><cr><lf>
<arg1><cr><lf>
...
<argN><cr><lf>- SET key value는 프로토콜로 다음과 같이 표현될 수 있다
*3<cr><lf>
$3<cr><lf>
SET<cr><lf>
$3<cr><lf>
key<cr><lf>
$5<cr><lf>
value<cr><lf>Distributed Locks with Redis
- 공유된 자원을 다른 프로세스에서 사용할 때 효과적이다
- DLM(Distributed Lock Manager)를 레디스에서 구현하는 방식은 다양하고, 각 라이브러리나 블로그 포스트마다 다른 접근을 하기 때문에 docs에서는 표준적인 알고리즘을 설명한다.
- Redlock이라고 불리는 알고리즘이다.
Safety and Liveness Guaratees
- 최소 아래 세가지 특징을 보장한다
- Safety Property: mutual exclusion. 어떤 순간에도 하나의 클라이언트만 락을 걸 수 있다
- Deadlock free: 락을 건 클라이언트가 터지거나 분리되더라도, 결국 락을 걸 수 있다
- Fault tolerance: 대부분의 레디스 노드가 작동하는 한, 클라이언트는 락을 획득하고 릴리즈할 수 있다.
Failover-based Implementations
자원에 락을 거는 가장 간단한 방법은 인스턴스에 키를 만들고, 만료 시간을 두고 관리하는 것이다. 락을 걸때 키를 만들었다가, 릴리즈할 때 키를 삭제하는 방식이다.
레디스 마스터 노드가 죽으면?
복제본을 만들어두고 사용하는 방법이 있다. 하지만 이는 위에서 말했던 mutual exclusion을 위반한다. 복제본은 동기화되지 않기 때문이다.
Single instance일 때 구현 방
SET resource_name my_random_value NX PX 30000- 키가 존재하지 않을 경우에만 set한다. value는 모든 클라이언트와 lock 요청에서 unique해야 한다.
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end- lock을 안전하게 release하는 Lua Script이다.
- 키에 저장된 값과 기대하는 값이 같아야 한다.
- 다른 클라이언트가 생성한 lock을 삭제하면 안되기 때문에, 중요하다
- lock validity time(위 커맨드에서 30000)은 자동 릴리즈 시간임과 동시에 클라이언트가 명령을 수행해야 하는 시간 제한 역할을 한다.
Redlock Algorithm
레디스 마스터가 여러개 운영되는 경우에는 각각이 독립적이기 때문에 분산 락 구현을 위해 Redlock 알고리즘을 사용한다.
분산 환경에서 락을 획득하기 위해 클라이언트는 아래 과정을 수행한다. (n이 5라는 가정)
1. 현재 시간을 밀리초로 가져온다.
2. n개, 즉 모든 인스턴스에 대해 락 획득을 시도한다. 이때 자동 릴리즈보다는 훨씬 적은 시간으로 타임아웃을 두어 락 획득에 너무 많은 시간을 쓰지 않도록 한다.
3. 대부분의 인스턴스(최소 3개)에서 락 획득이 가능하고, 락을 획득하기까지 걸린 시간이 lock validity time보다 적다면, 해당 락을 획득한다.
4. 락을 획득한 경우, lock validity time에서 흐른 시간을 뺀다.
5. 락을 획득하지 못한 경우, 모든 락을 해제한다.(획득한 락이 없더라도)
Retry on Failure
클라이언트가 락 획득에 실패하면, 랜덤한 딜레이 후에 재시도한다. 클라이언트는 여러 노드에 대한 락 시도가 빠를수록 효과적이기 때문에, 멀티플렉싱을 사용해 n개의 인스턴스에 동시에 SET 커맨드를 실행하는 것이 이상적이다
Secondary Indexing
레디스는 기본적으로 primary key access만 제공한다. 하지만 다양한 종류의 secondary index(복합 인덱스 등)을 만들기 위해 용량을 사용할 수 있다.
Sorted sets
가장 간단한 방법은 sorted set을 사용하는 방법이다. 각 요소에 점수를 매겨 정렬하는 방식이다.
ZADD myindex 25 Manuel
ZADD myindex 18 Anna
ZADD myindex 35 Jon
ZADD myindex 67 Helen아래와 같은 방식으로 범위 조회가 가능하다. WITHSCORES 옵션을 붙여 점수와 함께 반환받을 수도 있다.
ZRANGE myindex 20 40 BYSCORE
1) "Manuel"
2) "Jon"Using id as associated values
HMSET user:1 id 1 username antirez ctime 1444809424 age 38
HMSET user:2 id 2 username maria ctime 1444808132 age 42
HMSET user:3 id 3 username jballard ctime 1443246218 age 33ZADD user.age.index 38 1
ZADD user.age.index 42 2
ZADD user.age.index 33 3id로 인덱싱한 후, 나이로 한번 더 인덱싱하기 위해 위와 같이 구성할 수 있다.
하지만 나이가 변경될 경우 두 테이블을 함께 업데이트해야 한다
Lexicographical indexes
sorted set에는 재밌는 특징이 있는데, 같은 점수일 경우 memcomp() 함수를 이용해 사전식 정렬을 한다.
- 'BYSCORE' 대신 'BYLEX'를 통해 사전순 범위 검색이 가능하다.
[는 inclusive,(는 exclusive 이다.
ZRANGE myindex [a (b BYLEX
1) "aaaa"
2) "abbb"위 구문은 a(포함)과 b 사이 모든 값을 가져오는 구문이다.
