

안녕하세요:) 오늘은 MySQL 이중화에 대해서 알아보려고 합니다.
MySQL 이중화란 무엇을 의미할까요?
MySQL 이중화는 여러 서버를 사용하여 MySQL 데이터베이스의 고가용성과 재해 복구 기능을 향상시키는 기술입니다. 이는 단일 서버 장애로부터 데이터 손실 및 서비스 중단을 방지하여 안정적인 운영 환경을 제공합니다.
저는 MySQL DB를 Source DB와 Replica DB를 사용하여 이중화를 하고 있습니다.
어떻게 Source DB의 내용과 Replica DB의 내용이 일치할까요?
Source DB에서 Data Change가 발생할 때 MySQL CDC(Change Data Capture)가 변화를 잡아내어 Replica DB로 실시간 Relay Log를 전송하여 동기화 합니다
그러면 어떻게 동기화가 이뤄질까요?
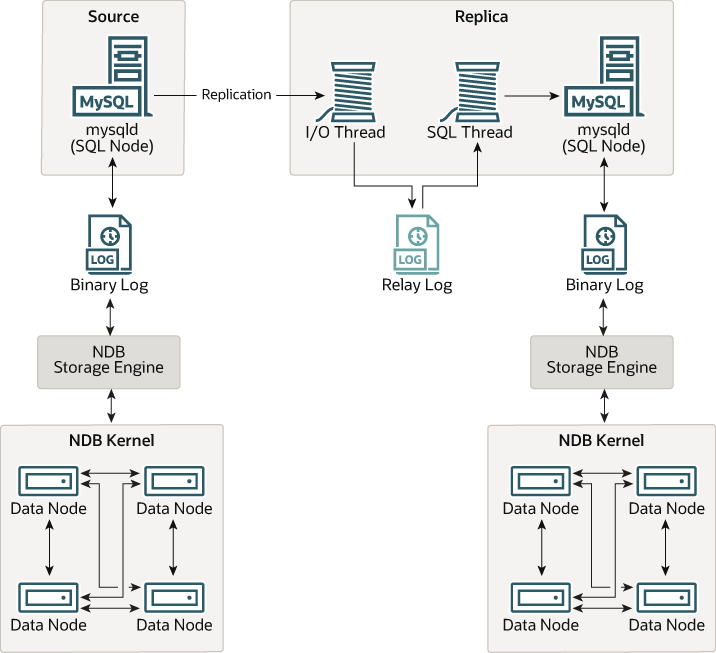
Replication은 다음과 같은 순서로 이뤄집니다
1. Source DB가 binary log를 만들어 Event를 기록합니다.
2. 각 Replica DB는 어떤 Event를 수행했는지 기록하고 있습니다.
3. Replica DB의 IO Thread를 통해서 Source DB에 Event를 요청합니다.
4. Source DB는 Event를 요청받으면 binlog dump thread를 통해서 Replica DB들에게 Event를 전송합니다.
5. IO thread는 전송받은 Event를 이용하여 relay log를 만듭니다.
6. SQL thread는 relay log를 읽어 Replica DB에 Data를 복사합니다.
MySQL Replication은 Insert, Delete 같은 DML(Database Manipulation Language)뿐만 아니라, CREATE, DROP 같은 DDL(Database Defination Language)도 모두 Replica DB에 반영이 됩니다.
MySQL Replication 실습
도커를 통해 실습을 진행할 예정이니 Docker에 대한 기본 지식이 필요합니다!
source-Dockerfile
FROM mysql:latest
ADD ./source/my.cnf /etc/mysql/my.cnfsource/my.cnf
# mysql application client에 대한 기본 문자 설정
[client]
default-character-set = utf8mb4
# mysql application server에 대한 기본 문자 설정
[mysql]
default-character-set = utf8mb4
[mysqld]
# 데이터를 저장하고 처리하는 데 사용하는 기본 문자를 정의
character-set-server = utf8mb4
# 서버가 문자 비교 및 정렬에 사용하는 콜레이션을 지정
collation-server = utf8mb4_unicode_ci
# MySQL 서버의 기본 시간대를 설정
default-time-zone='+9:00'
# 서버 활동에 대한 바이너리 로깅을 활성화. 로그 파일 이름은 mysql-bin이며, 복제 목적으로 사용하거나 데이터베이스에 대한 변경 사항을 추적하는 데 사용할 수 있음
log-bin = mysql-bin
# MySQL 서버 인스턴스에 고유한 서버 ID를 할당, 복제 클러스터의 기본 서버에는 일반적으로 1 값을 사용
server-id = 1
MySQL 서버에 연결하는 클라이언트에 대한 기본 인증 플러그인을 설정
default_authentication_plugin=mysql_native_passwordreplica-Dockerfile
FROM mysql:latest
ADD ./replica/my.cnf /etc/mysql/my.cnfreplica/my.cnf
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
default-time-zone='+9:00'
log_bin = mysql-bin
# MySQL 서버 인스턴스에 고유한 서버 ID를 2로 설정, 일반적으로 복제 클러스터의 기본 서버에는 1 값을 사용하고, replica 서버에는 2 이상의 값을 사용
server_id = 2
# MySQL 복제에 사용되는 중계 로그 파일의 위치를 /var/lib/mysql/mysql-relay-bin으로 설정
relay_log = /var/lib/mysql/mysql-relay-bin
# 복제 중 Replica 서버에서 적용된 업데이트를 로깅하도록 설정, 1 값을 사용하면 source 서버에서 받은 모든 업데이트가 로깅
log_slave_updates = 1
# MySQL 서버를 읽기 전용 모드로 작동하도록 설정, 클라이언트는 데이터베이스에서 데이터를 읽을 수 있지만 삽입, 업데이트 또는 삭제와 같은 수정 작업을 수행할 수 없음
read_only = 1
#MySQL 서버에 연결하는 클라이언트에 대한 기본 인증 플러그인을 설정
default_authentication_plugin=mysql_native_passworddocker-compose.yml
version: "3"
services:
source-db:
build:
context: ./
dockerfile: source/Dockerfile
restart: always
platform: linux/x86_64
environment:
MYSQL_USER: '0chord'
MYSQL_PASSWORD: '1q2w3e4r!'
MYSQL_ROOT_PASSWORD: '1q2w3e4r!'
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- '3308:3306'
container_name: source-db
networks:
- net-mysql
replica-db:
build:
context: ./
dockerfile: replica/Dockerfile
restart: always
platform: linux/x86_64
environment:
MYSQL_USER: '0chord'
MYSQL_PASSWORD: '1q2w3e4r!'
MYSQL_ROOT_PASSWORD: '1q2w3e4r!'
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- '3309:3306'
container_name: replica-db
networks:
- net-mysql
networks:
net-mysql:
driver: bridgedocker 실행
docker-compose -f docker-compose.yml up -dreplica db와 source db를 동기화를 하기 위해서는 source db의 network ip를 알아야 합니다
docker inspect source-db
source-db 설정
# source-db container 접속
docker exec -it source-db bin/bash
mysql -u root -p
password 입력
use mysql;
# 권한 부여
grant all privileges on *.* to '0chord'@'%';
flush all;이제 binlog와 Pos값을 알기 위해 다음의 명령어를 입력합니다
show master status;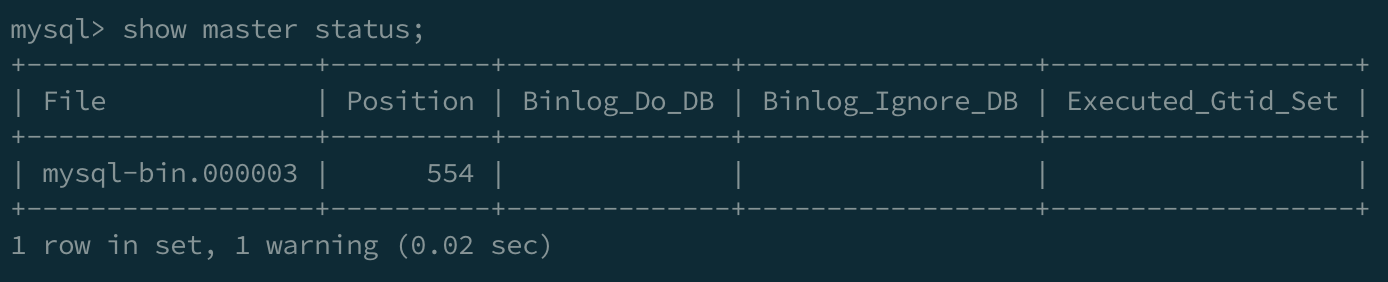
이제 source db에서 하는 설정은 모두 끝났습니다
replica-db 설정
# replica-db container 접속
docker exec -it replica-db bin/bash
mysql -u root -p
password 입력
use mysql;
# 권한 부여
grant all privileges on *.* to '0chord'@'%';
flush all;replica-db에 접속을 완료한 후 replica 설정을 위해 다음과 같은 명령어를 입력해줍니다.
CHANGE MASTER TO MASTER_HOST='{source-db의 네트워크 IP}',
MASTER_USER='{root or 설정한 User_ID}',
MASTER_PASSWORD='{user 계정의 비밀번호}',
MASTER_LOG_FILE='{source-db의 바이너리 파일 이름}',
MASTER_LOG_POS={source-db에서 조회한 파일 포지션};
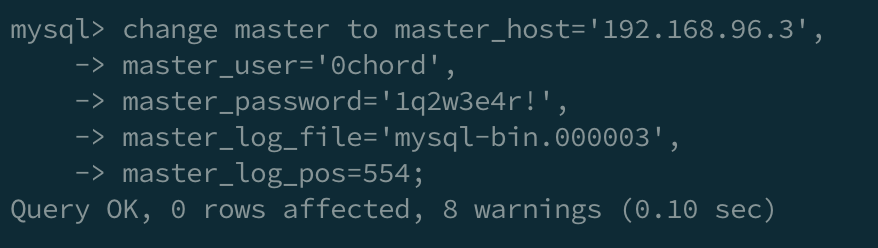
실행이 완료되면 다음의 명령어를 입력해줍니다
start slave;잘 설정이 되었는지 다음의 명령어를 입력해 확인합니다
show slave status\G;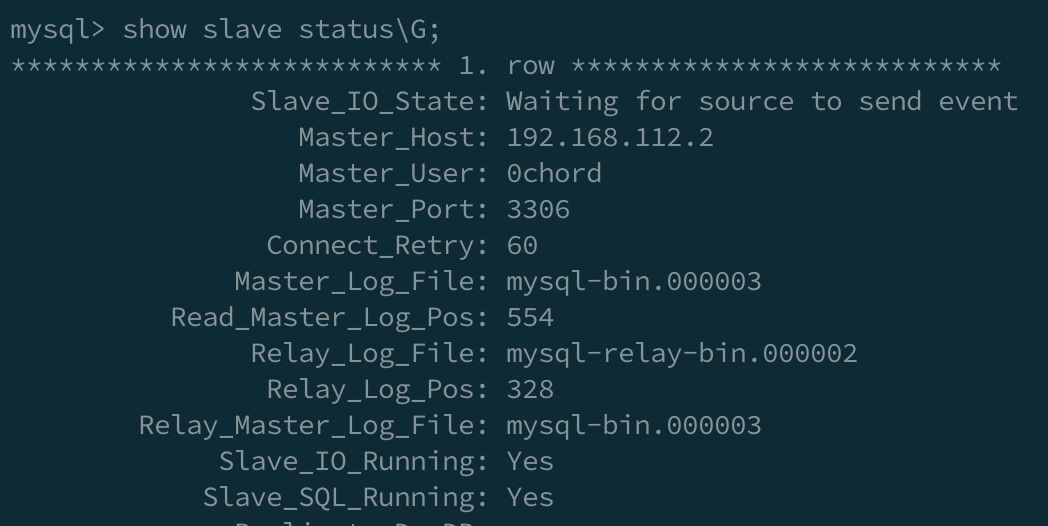
Slave_IO_Running과 Slave_SQL_Running이 모두 Yes이면 설정이 전부 잘 된 것 입니다
Source DB -> Replica DB 동기화 테스트
Source DB로 들어가 Database와 Table을 생성해줍니다
docker exec -it source-db bin/bash
mysql -u 0chord -p
password 입력
#저희 프로젝트 DB가 harmony라서 생성
create database harmony;
use harmony;
#간이 테이블 생성
CREATE TABLE test (
test_id bigint,
name VARCHAR(255),
PRIMARY KEY (test_id)
);
#Data 삽입
INSERT INTO test VALUES (1, "0chord");
INSERT INTO test VALUES (2, "chord");Replica DB 확인
docker exec -it replica-db bin/bash
mysql -u 0chord -p
password 입력
use harmony;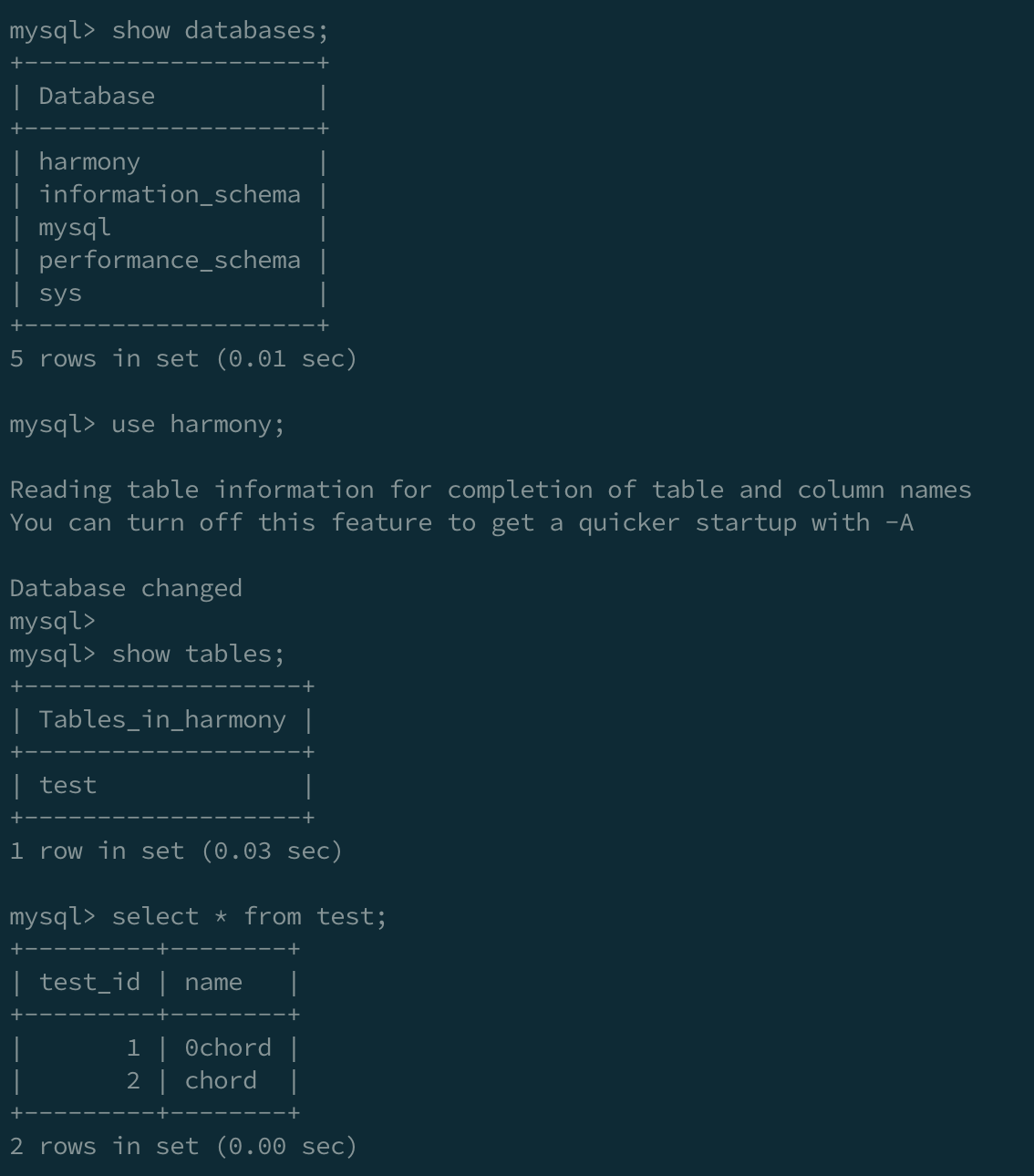
데이터베이스 동기화가 잘 되었다는 것을 알 수 있습니다.
하지만 동기화 성능이 좋을까?
Source DB -> Replica DB 동기화 방식은 비동기로 처리되기 때문에 동기화 딜레이가 생길 수 밖에 없습니다.
Harmony Project는 대규모 서비스를 가정하고 설계를 했기 때문에 최소한의 딜레이만 생겨야 하며 데이터 Source DB와 Replica DB의 데이터 무결성을 최대한 보장해야 했습니다.
그래서 MySQL 프로시저를 통한 1000만건의 데이터 삽입을 통한 성능 테스트를 진행했습니다.
테스트 진행
먼저 test table를 삭제하고 새로운 테이블을 생성합니다
drop table test;
CREATE TABLE IF NOT EXISTS user (
user_id BIGINT NOT NULL,
email VARCHAR(255),
nickname VARCHAR(255),
profile VARCHAR(255),
PRIMARY KEY (user_id)
);
테이블에 데이터를 삽입하는 프로시저를 생성합니다
DELIMITER $$
CREATE PROCEDURE insertUser()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 10000000 DO INSERT INTO user (user_id, email, nickname, profile) VALUES (i, "example", "BTS", "https://storage.googleapis.com/sg-dev-remember-harmony/discord.png");
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;그리고 프로시저를 실행합니다
call insertUser();제 테스트 기준 1000만건 중 80만건(약 8%)의 딜레이가 발생했습니다. 8%의 성능 차이는 대규모 서비스에서는 매우 치명적이라고 생각했으며 그래서 새로운 동기화 방식을 찾아야 했습니다
대규모 이벤트 처리와 고가용성을 보장하는 Kafka Connect 기반 Debezium을 찾게 되었고 MySQL CDC에서 Debezium으로 migration을 하게 되었습니다
Debezium 설정에 관한 이야기는 다다음편에 진행하며 물론 고려해야 하는 사항들이 있었습니다
- 우리 팀에서는 Kafka를 전담하는 팀원이 있어서 Kafka 설정등은 그 팀원분께서 담당하셨으며 나는 Connect 설정과 Debezium 설정만 했습니다
- 그리고 FK 문제가 발생하여 테이블 구조 변경도 있어야 했습니다
이 고려 사항들은 다다음편에 계속 진행하겠습니다
다음 편에서는 이중화된 MySQL DB를 어떻게 Spring Boot Server에서 연동하며 어떤 식으로 사용했는지 알아보도록 하겠습니다!
